Futures
Access hundreds of perpetual contracts
TradFi
Gold
One platform for global traditional assets
Options
Hot
Trade European-style vanilla options
Unified Account
Maximize your capital efficiency
Demo Trading
Introduction to Futures Trading
Learn the basics of futures trading
Futures Events
Join events to earn rewards
Demo Trading
Use virtual funds to practice risk-free trading
Launch
CandyDrop
Collect candies to earn airdrops
Launchpool
Quick staking, earn potential new tokens
HODLer Airdrop
Hold GT and get massive airdrops for free
Pre-IPOs
Unlock full access to global stock IPOs
Alpha Points
Trade on-chain assets and earn airdrops
Futures Points
Earn futures points and claim airdrop rewards
Promotions
AI
Gate AI
Your all-in-one conversational AI partner
Gate AI Bot
Use Gate AI directly in your social App
GateClaw
Gate Blue Lobster, ready to go
Gate for AI Agent
AI infrastructure, Gate MCP, Skills, and CLI
Gate Skills Hub
10K+ Skills
From office tasks to trading, the all-in-one skill hub makes AI even more useful.
GateRouter
Smartly choose from 40+ AI models, with 0% extra fees
Revealing the Transformer in the iPhone: Based on GPT-2 architecture, the word segmenter contains emoji, produced by MIT alumni
Original source: Qubits
The “secret” of Apple’s Transformer has been revealed by enthusiasts.
In the wave of large models, even if you are as conservative as Apple, you must mention “Transformer” at every press conference.
For example, at this year’s WWDC, Apple announced that new versions of iOS and macOS will have built-in Transformer language models to provide input methods with text prediction capabilities.
A guy named Jack Cook turned the macOS Sonoma beta upside down and found out a lot of fresh information:
Let’s take a look at more details.
Based on GPT-2 architecture
First, let’s review what functions Apple’s Transformer-based language model can implement on iPhone, MacBook and other devices.
Mainly reflected in the input method. Apple’s own input method, supported by the language model, can realize word prediction and error correction functions.
** **### △Source: Jack Cook blog post
**### △Source: Jack Cook blog post
The model sometimes predicts multiple upcoming words, but this is limited to situations where the semantics of the sentence are very obvious, similar to the auto-complete function in Gmail.
** **### △Source: Jack Cook blog post
**### △Source: Jack Cook blog post
So where exactly is this model installed? After some in-depth digging, Brother Cook determined:
Because:
Furthermore, based on the network structure described in unilm_joint_cpu, I speculated that the Apple model is based on the GPT-2 architecture:
It mainly includes token embeddings, position encoding, decoder block and output layer. Each decoder block has words like gpt2_transformer_layer_3d.
**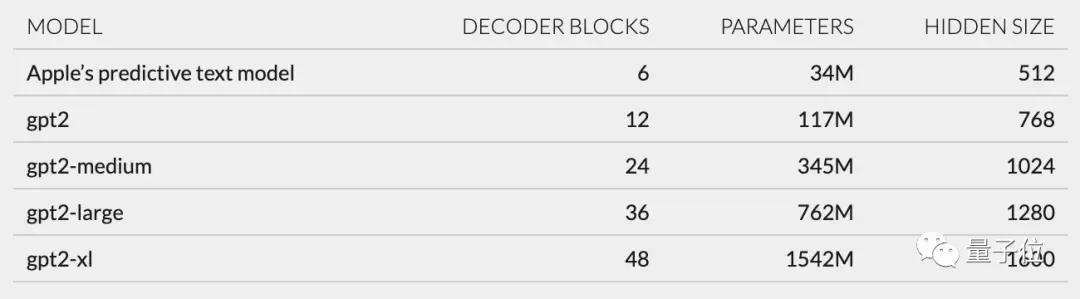 **### △Source: Jack Cook blog post
**### △Source: Jack Cook blog post
Based on the size of each layer, I also speculated that the Apple model has approximately 34 million parameters and the hidden layer size is 512. That is, it is smaller than the smallest version of GPT-2.
I believe this is mainly because Apple wants a model that consumes less power but can run quickly and frequently.
Apple’s official statement at WWDC is that “every time a key is clicked, the iPhone will run the model once.”
However, this also means that this text prediction model is not very good at continuing sentences or paragraphs completely.
** **### △Source: Jack Cook blog post
**### △Source: Jack Cook blog post
In addition to the model architecture, Cook also dug up information about the tokenizer.
He found a set of 15,000 tokens in unilm.bundle/sp.dat. It is worth noting that it contains 100 emoji.
Cook reveals Cook
Although this Cook is not a cook, my blog post still attracted a lot of attention as soon as it was published.
Previously, he interned at NVIDIA, focusing on the research of language models such as BERT. He is also a senior research and development engineer for natural language processing at The New York Times.
So, did his revelation also trigger some thoughts in you? Welcome to share your views in the comment area~
Original link: