As blockchain applications scale up, on-chain data has become a foundational resource for DeFi, on-chain analytics, AI Agents, and multi-chain applications. However, raw blockchain data typically exists as blocks, transactions, and event logs, forcing developers to go through complex extraction and processing pipelines before they can use it. Efficiently accessing on-chain data has therefore become a key challenge in Web3 infrastructure development.
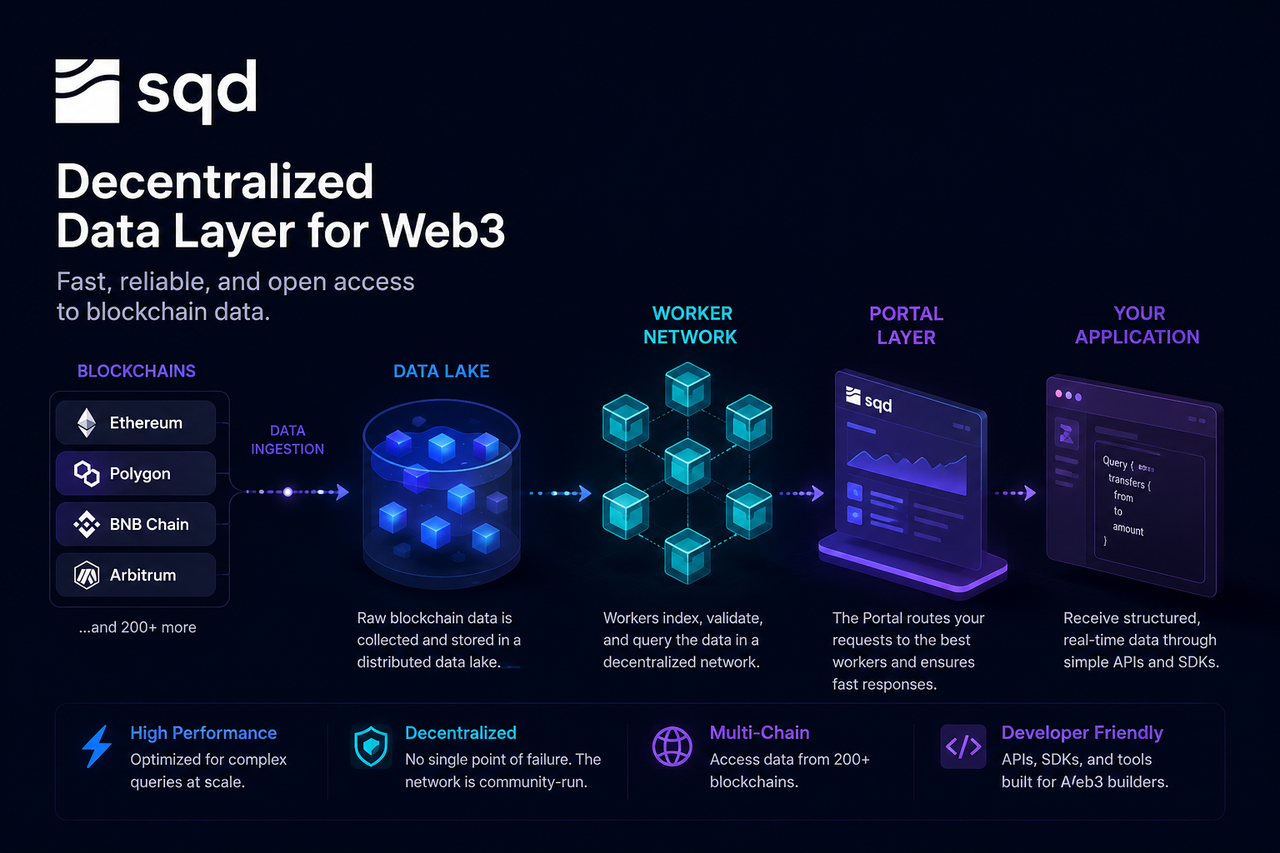
Subsquid (SQD) emerges as a decentralized data network designed to solve this problem. Unlike traditional RPC nodes that read blockchain state directly, SQD provides a data service architecture built around a data lake, Worker nodes, and a Portal query layer, allowing developers to access structured, indexed on-chain data through a unified interface.
What Is an SQD Data Query?
An SQD data query is the process by which developers retrieve on-chain data via the SQD Network. Instead of requesting data directly from blockchain nodes, SQD queries return data that has already been preprocessed and indexed, enabling fast responses to complex requests.
For example, a DeFi dashboard might need to aggregate trading volumes over the past several months, an AI Agent might need to read asset changes across multiple addresses, and an analytics platform might need to query the entire event history of a specific smart contract. All of these are typical data query scenarios.
SQD's core idea is to offload the heavy data processing upfront, so applications can access structured data directly without having to handle massive raw block data themselves.
How On-Chain Data Enters the SQD Network
The starting point of a query actually happens before the developer even sends the request.
As blockchain networks constantly generate new blocks, the SQD Network captures raw data — including blocks, transactions, log events, and smart contract state changes — in real time through its data collection system. This data is then standardized for later processing and storage.
Because SQD supports multiple blockchains, its data collection layer must continuously synchronize data streams from different ecosystems while ensuring data integrity and consistency. After standardization, the data is written to the network's storage layer.
The data lake is the core storage infrastructure in the SQD network.
Unlike traditional databases designed for structured data, a data lake can handle large amounts of raw and semi-structured data. Blockchain history, transaction data, event logs, and state snapshots are all stored in this layer.
The advantage of a data lake is that it preserves complete historical data while enabling flexible downstream processing and analysis. For applications that need to trace millions of transactions, this storage method is far more efficient than querying blockchain nodes directly.
The data lake acts as the long-term memory of the SQD Network, providing data for subsequent indexing and queries.
How Worker Nodes Handle Query Requests
Worker nodes are the execution layer in the SQD network.
When data enters the network, Worker nodes index, classify, and optimize it for fast retrieval. The indexing process is like creating a table of contents for a huge encyclopedia — no need to scan everything from scratch for each query.
Beyond building indexes, Worker nodes also execute query tasks. When a developer requests specific data, a Worker node quickly locates relevant records using the index, then filters, aggregates, and computes results.
Because multiple Worker nodes can run in parallel, the network can handle many queries simultaneously, boosting overall performance and scalability.
How Portal Receives Developer Requests
Portal is the unified entry point for developers to access the SQD Network.
Developers typically send queries via an API or SDK without connecting directly to the underlying nodes. When a request reaches Portal, the system parses the query and determines which Worker nodes are best suited to handle it.
Portal acts like a load balancer on the internet. Developers only interact with a single interface, while complex resource scheduling and node selection happen automatically behind the scenes.
This design simplifies development and improves the network's overall resource efficiency.
How Query Results Are Returned to Applications
Once Worker nodes finish processing, the results are sent back to the Portal layer.
Portal formats the results as needed and sends the final data to the application. Developers receive data that is already structured — for example, JSON objects or analytical results — ready for front-end display, business logic, or AI inference.
The entire process is usually transparent to end users. They simply see the page load or the analysis results appear, while behind the scenes, multiple steps from data collection to query execution have already taken place.
How Hotblocks Supports Real-Time Data Queries
In addition to historical queries, many applications need real-time on-chain information.
For instance, on-chain monitoring systems need to detect abnormal transactions, automated strategies need to listen to smart contract events, and AI Agents need to stay aware of the latest market conditions. These scenarios require data to be available as soon as a new block is produced.
Hotblocks is the real-time data layer that SQD provides, specifically designed for new blocks and live events. Compared to the historical data in the data lake, Hotblocks focuses on low latency and fast responses, enabling developers to build real-time applications.
How SQD Queries Differ from Traditional RPC Queries
Both methods can access on-chain data, but the underlying logic is very different.
Traditional RPC nodes are like directly querying a blockchain database. Each request must look up the corresponding data from the on-chain state or historical records. As the query scope grows, performance and cost pressure increase accordingly.
SQD, on the other hand, uses a pre-indexed architecture. Data is already organized and indexed when it enters the network, so queries don't need to scan all history again. For complex analysis, multi-chain data aggregation, and long-term historical statistics, SQD typically offers much higher efficiency.
| Dimension |
SQD |
Traditional RPC |
| Data Source |
Pre-indexed data |
Real-time on-chain reads |
| Query Efficiency |
High |
Medium |
| Historical Data Analysis |
Significant advantage |
More complex |
| Multi-Chain Support |
Strong |
Depends on multiple nodes |
| Infrastructure Cost |
Lower |
Higher |
| Real-Time State Reading |
Supported |
Supported |
How the SQD Query Process Matters for AI Agents
AI Agents are becoming a key application in Web3 infrastructure, and data access is fundamental to their operation.
If an AI Agent needs to analyze wallet behavior, track protocol states, or execute on-chain actions, it must continuously obtain accurate, structured data. Traditional RPC queries can provide raw data, but they usually require extra processing and transformation.
The unified data interface provided by SQD reduces the complexity for AI Agents to fetch on-chain information. With standardized query results, AI systems can devote more computing power to analysis and decision-making rather than data wrangling.
As AI and Web3 continue to converge, the importance of decentralized data layers will only grow.
Summary
An SQD data query is not just a simple data read — it is a complete workflow involving the data collection layer, data lake, Worker nodes, and Portal layer, all working together. Raw blockchain data is first collected and stored, then indexed and optimized, and finally delivered to developers through a unified interface.
This pre-indexed, distributed processing model allows SQD to deliver high efficiency for complex queries, multi-chain analysis, and real-time data access. As DeFi, on-chain analytics platforms, and AI Agents demand ever more data, the data layer architecture represented by SQD is becoming an essential part of Web3 infrastructure.
FAQs
What is the difference between an SQD data query and a regular API query?
A regular API is usually maintained by a centralized provider, whereas an SQD query runs on a decentralized data network. SQD data comes from on-chain collection and indexing systems, offering more open and verifiable data access.
Why is SQD query speed faster than some RPC requests?
SQD completes indexing and organization in advance, so queries don't need to rescan large amounts of block history. For complex analysis and historical data tasks, SQD is generally much faster.
What role do Worker nodes play in the query process?
Worker nodes handle indexing, filtering, aggregation, and computation. When Portal receives a query request, the relevant Worker nodes perform the actual data processing.
What is the difference between a data lake and a database?
A database typically stores structured data, while a data lake can store massive volumes of raw and semi-structured data. SQD uses a data lake to store complete on-chain history, supporting flexible queries and analysis.
Can Hotblocks replace historical data queries?
No. Hotblocks is designed for real-time data access; historical queries still rely on the data lake and indexing system. Together, they form SQD's full data service capability.
Which applications are best suited for SQD query services?
DeFi dashboards, blockchain explorers, on-chain analytics platforms, real-time monitoring systems, multi-chain applications, and AI Agents — any scenario that needs frequent on-chain data access — are ideal for SQD query services.







