Kingbest
用戶暫無簡介
Kingbest
想像自己把一切都做到對了……卻在熊市中仍然醒來時發現歸零。
你保護了你的資金,你使用了硬體錢包。但仍然不夠。
這種損失可能會導致嚴重憂鬱。
向所有受到 coldcard 駭客事件 ❤ 影響的人傳遞力量
查看原文你保護了你的資金,你使用了硬體錢包。但仍然不夠。
這種損失可能會導致嚴重憂鬱。
向所有受到 coldcard 駭客事件 ❤ 影響的人傳遞力量
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
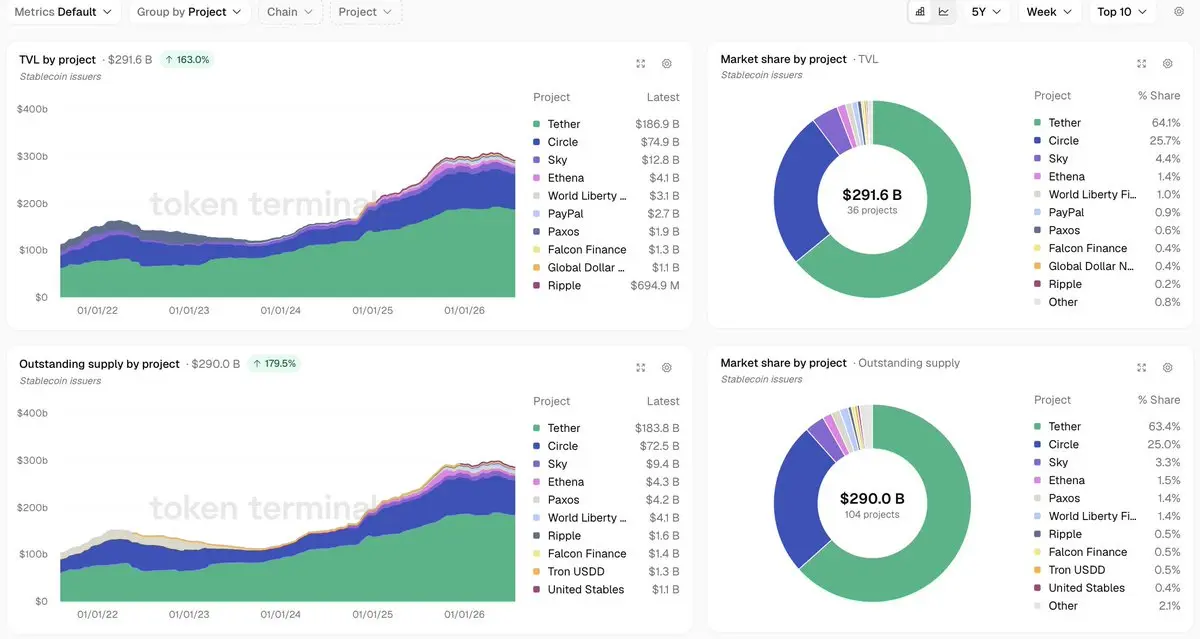
穩定幣排行榜正在改變。
> 市值:$307B → $291B
> 6 月:-77.7 億美元,2022 年以來最大的月度下滑
> 調整後結算量:1.79 萬億美元(歷史新高)
> 月環比 +63%,年同比 +125%
這些數字看起來只有在用我們當時交易周期的方式衡量穩定幣時才會顯得彼此矛盾。
當時,成長意味著更大的流通量在交易之間以鏈上形式存在。
而如今,同一筆美元資金在支付、結算與資本移動之間被更頻繁地重複使用。
以更小的流通量處理更多價值,是市場的另一個階段。
更好的問題並不是穩定幣的數量有多少。
而是每一枚穩定幣所支撐的經濟活動量有多少。
查看原文> 市值:$307B → $291B
> 6 月:-77.7 億美元,2022 年以來最大的月度下滑
> 調整後結算量:1.79 萬億美元(歷史新高)
> 月環比 +63%,年同比 +125%
這些數字看起來只有在用我們當時交易周期的方式衡量穩定幣時才會顯得彼此矛盾。
當時,成長意味著更大的流通量在交易之間以鏈上形式存在。
而如今,同一筆美元資金在支付、結算與資本移動之間被更頻繁地重複使用。
以更小的流通量處理更多價值,是市場的另一個階段。
更好的問題並不是穩定幣的數量有多少。
而是每一枚穩定幣所支撐的經濟活動量有多少。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
三週大。已經在每日使用者上超越 Base。
不是 TVL。不是交易量。是使用者。這個指標最難偽造、也最容易失去。
根據 Token Terminal:
> Robinhood Chain:254.3K DAU
> Base:186.3K DAU
> 上線後幾天內達到 100 萬週活躍地址
這就是為什麼它比看起來還更大:
Robinhood 從來沒有分發(distribution)問題。它早就擁有金融領域中最大的散戶受眾之一。上線並沒有創造新使用者。它只是重新導流了原本就存在的使用者。
因此,真正的問題就不是「他們怎麼做到的」,而是「他們會不會留下」。
迷因幣(Memecoin)資金流能讓一條鏈很快變熱。他們自己不會建立生態系。考驗在於這份關注是否會轉化為借貸、交易、支付、RWA,或是在敘事轉移後立刻離場。
每一條鏈都有兩次上線:
1. 分發
2. 留存
Robinhood 就是贏下第一個。贏得比幾乎任何人預期得更快。
第二個才是實際上真正重要的。
所以,講述故事的比較不該是 Robinhood Chain 對比 Base。
而是 Robinhood Chain:現在 vs. 六個月後的 Robinhood Chain。
不是 TVL。不是交易量。是使用者。這個指標最難偽造、也最容易失去。
根據 Token Terminal:
> Robinhood Chain:254.3K DAU
> Base:186.3K DAU
> 上線後幾天內達到 100 萬週活躍地址
這就是為什麼它比看起來還更大:
Robinhood 從來沒有分發(distribution)問題。它早就擁有金融領域中最大的散戶受眾之一。上線並沒有創造新使用者。它只是重新導流了原本就存在的使用者。
因此,真正的問題就不是「他們怎麼做到的」,而是「他們會不會留下」。
迷因幣(Memecoin)資金流能讓一條鏈很快變熱。他們自己不會建立生態系。考驗在於這份關注是否會轉化為借貸、交易、支付、RWA,或是在敘事轉移後立刻離場。
每一條鏈都有兩次上線:
1. 分發
2. 留存
Robinhood 就是贏下第一個。贏得比幾乎任何人預期得更快。
第二個才是實際上真正重要的。
所以,講述故事的比較不該是 Robinhood Chain 對比 Base。
而是 Robinhood Chain:現在 vs. 六個月後的 Robinhood Chain。
MEME-0.73%
- 打賞
- 1
- 1
- 轉發
- 分享
宝二爷的奶妈:
2026,最後一個萬倍級機會,我只押注 AIP。上一輪錯過 0.008U 的 ORDI,這次不再讓遺憾重演。 那些 8 個 0 的 SHIB 神話,只配留在夢境裡醒來,才是現實。
AI 浪潮已至,AIP 模式就是這輪行情的導火索。總量 2000 萬,認購 0.02U 起步
不再靠運氣,只靠趨勢翻身。
把過去虧掉的,統統拿回來。
AIP,這次我絕不缺席。
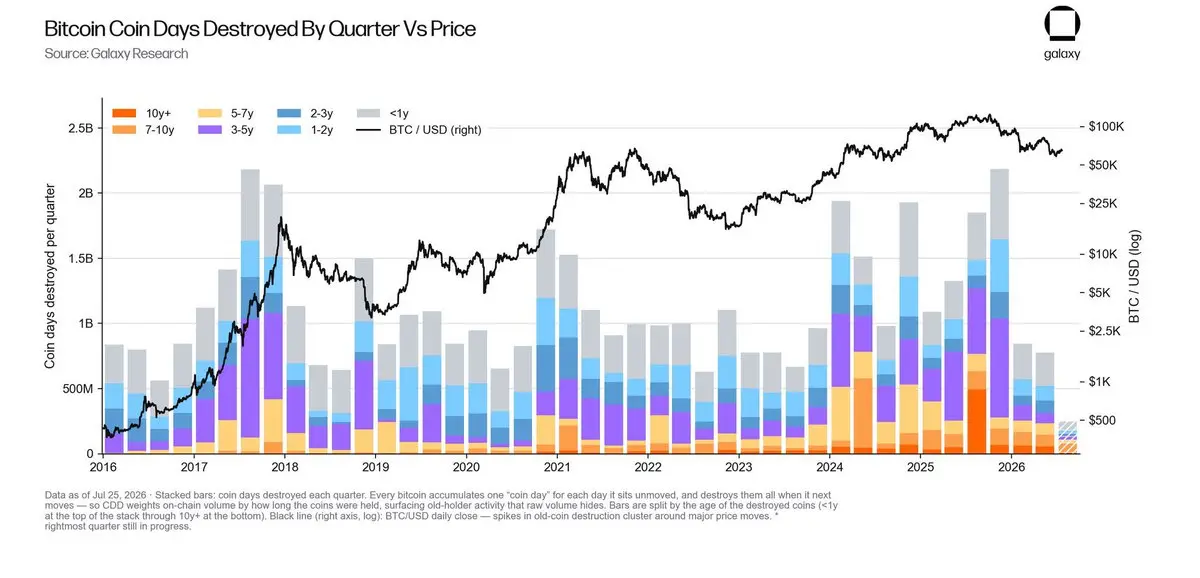
這一季較明顯的「乾淨信號」不在於移動了什麼。
而在於沒有移動什麼。
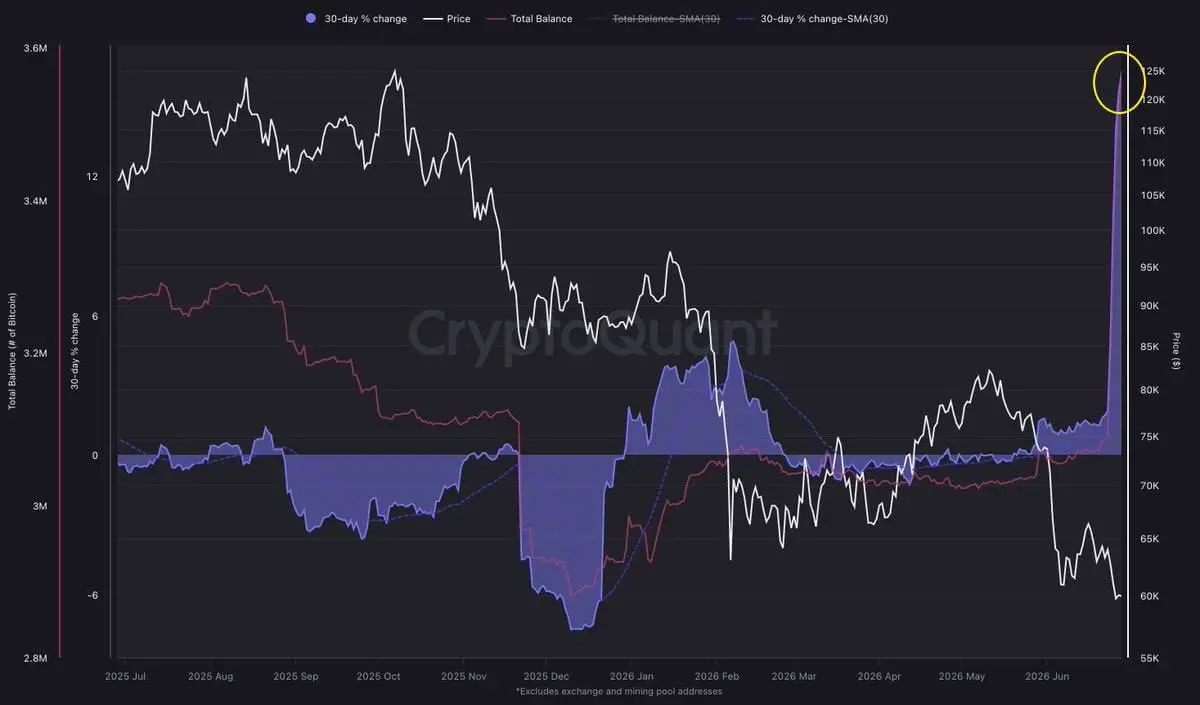
二季(Q2)裡,幾乎沉睡的比特幣(Bitcoin)幾乎沒被喚醒。
與 2024 年和 2025 年相比,先前長期持有的 BTC 回流到流通中的數量急劇下滑,達到自 2022 年第三季(Q3)以來的最低水平。
這改變了我對當前市場的想法。
> 老持幣者並沒有急著分散拋售。
> 長期信念看起來仍然完整。
> 新的需求正在吸收供給,而不必把沉睡的幣重新逼回流通。
當老持幣者開始在上漲走勢中出售時,市場通常會變得脆弱。
但這些圖表描述的環境並非如此。
沒有任何單一指標能講完全部故事。
然而,當在更高價格時沉睡供給仍保持安靜時,往往意味著信念仍勝過想要退出的誘惑。
而在於沒有移動什麼。
二季(Q2)裡,幾乎沉睡的比特幣(Bitcoin)幾乎沒被喚醒。
與 2024 年和 2025 年相比,先前長期持有的 BTC 回流到流通中的數量急劇下滑,達到自 2022 年第三季(Q3)以來的最低水平。
這改變了我對當前市場的想法。
> 老持幣者並沒有急著分散拋售。
> 長期信念看起來仍然完整。
> 新的需求正在吸收供給,而不必把沉睡的幣重新逼回流通。
當老持幣者開始在上漲走勢中出售時,市場通常會變得脆弱。
但這些圖表描述的環境並非如此。
沒有任何單一指標能講完全部故事。
然而,當在更高價格時沉睡供給仍保持安靜時,往往意味著信念仍勝過想要退出的誘惑。
BTC-0.24%
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
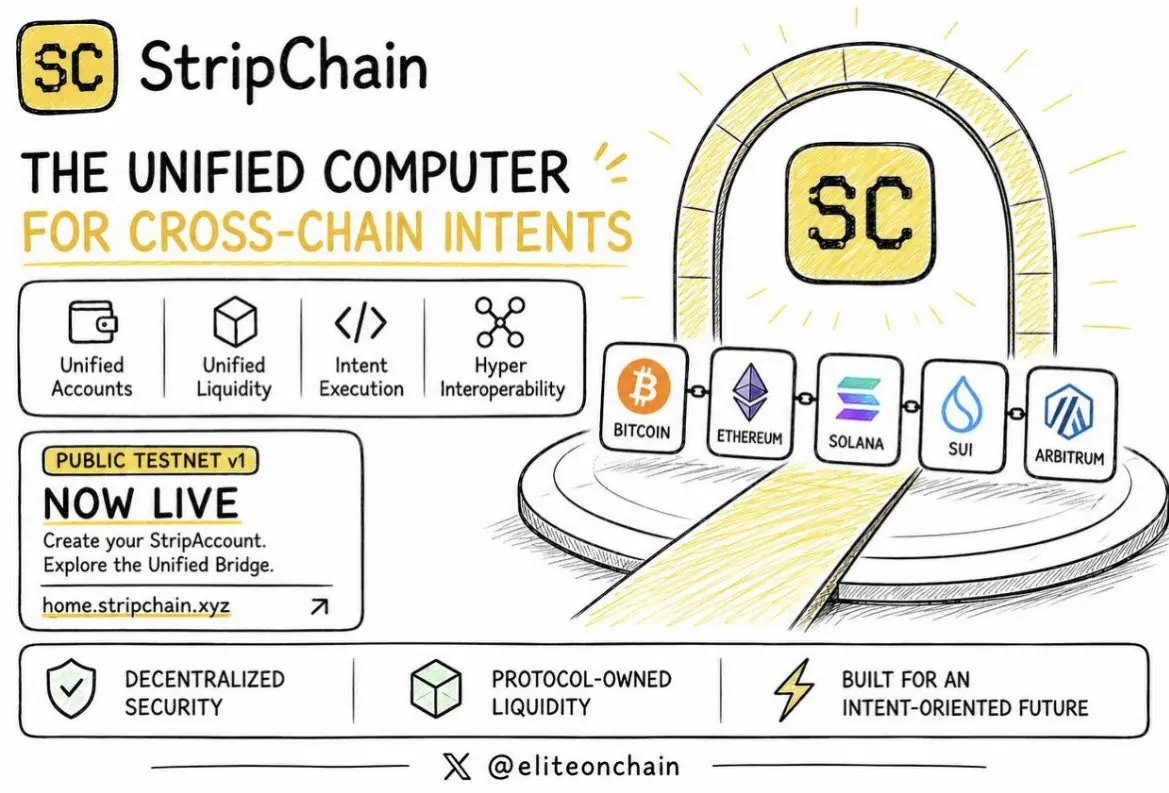
每一筆 DeFi 交易仍然是手動完成的。使用者逐步處理跨鏈、gas 與執行流程。
@Stripchain 想改變這一點。
它正在打造一台統一的電腦。使用者不再直接與合約互動,而是只需表達想要執行的內容。系統會自行判斷如何執行。
公開測試網已上線,並向所有人開放。這是對 Strip 架構的首次真正驗證,其中包含 StripIO 與能夠建立 StripAccounts 的驗證者。
在測試網上你可以:
• 建立帳戶並與測試網互動
• 鑄造並移動合成資產
• 測試跨鏈的動作與流程
如果以意圖為基礎的使用者體驗成為標準,StripChain 將位於多鏈 DeFi 的協調層。
以下是參與連結:
查看原文@Stripchain 想改變這一點。
它正在打造一台統一的電腦。使用者不再直接與合約互動,而是只需表達想要執行的內容。系統會自行判斷如何執行。
公開測試網已上線,並向所有人開放。這是對 Strip 架構的首次真正驗證,其中包含 StripIO 與能夠建立 StripAccounts 的驗證者。
在測試網上你可以:
• 建立帳戶並與測試網互動
• 鑄造並移動合成資產
• 測試跨鏈的動作與流程
如果以意圖為基礎的使用者體驗成為標準,StripChain 將位於多鏈 DeFi 的協調層。
以下是參與連結:
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
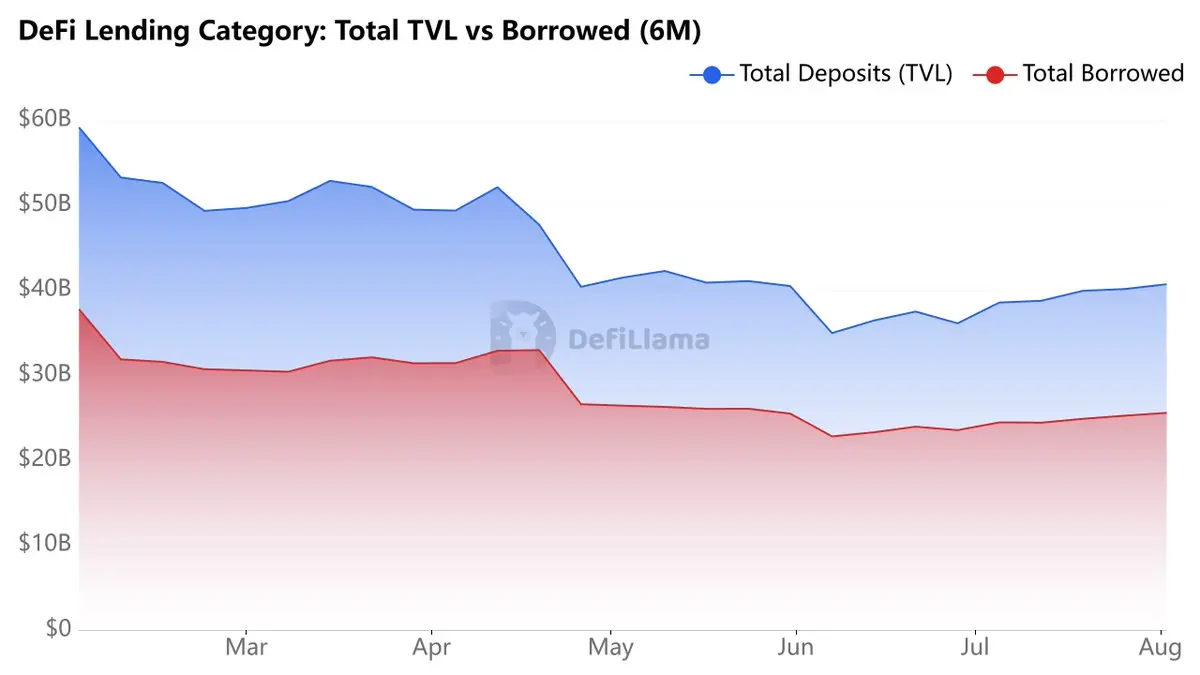
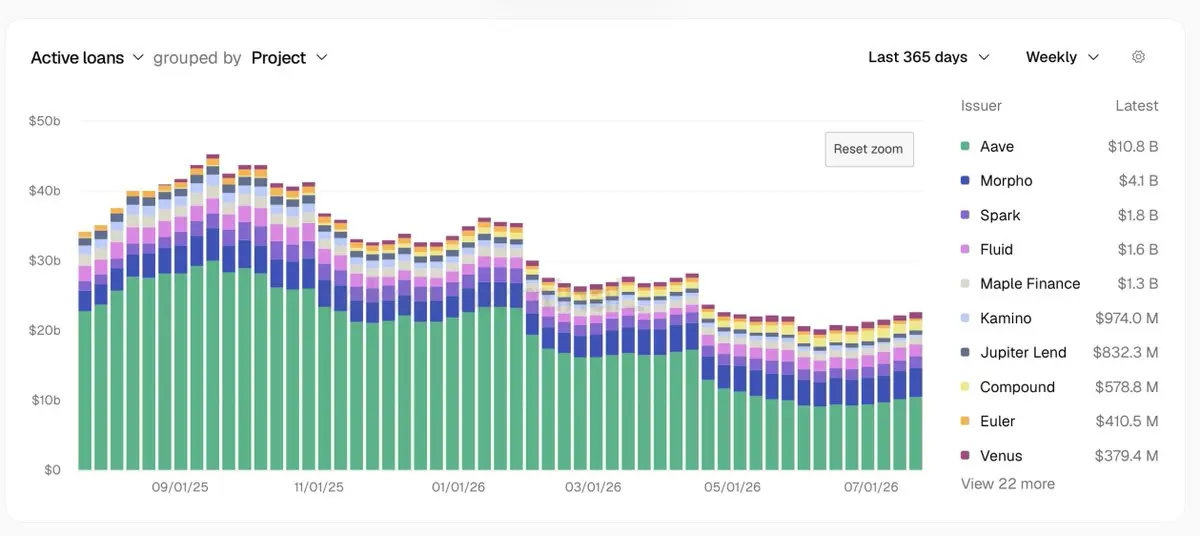
三個協議都被歸在同一個標籤之下。
它們正擴張到完全不同的市場。
數字如下:
> @Aave: 103 億美元的在貸款額
> @Morpho: 41 億美元的在貸款額
> @maplefinance: 13 億美元的在貸款額
只看借貸帳本會讓 Aave 看起來很主導。
但往下看,對比就會改變。
隨著更多抵押品上鏈,Aave 會成長。
隨著更多資金透過其借貸基礎設施流轉,Morpho 會成長。
隨著機構型借款人採用上鏈信用,Maple 會成長。
這些成長驅動因素並不互相競爭。
它們對應的是不同的市場。
Morpho 的 2.343 億美元年化費用,搭配 0 協議收入,反映出該協議仍把網路成長放在變現之前。
Maple 的貸款帳本只是 Aave 的一小部分。
但它的可觸及市場並非如此。
抵押品市場與信貸市場一直是不同的生意。
加密貨幣正在開始反映這種差異。
借貸這個類別本身沒有改變。
但支撐它的市場變了。
查看原文它們正擴張到完全不同的市場。
數字如下:
> @Aave: 103 億美元的在貸款額
> @Morpho: 41 億美元的在貸款額
> @maplefinance: 13 億美元的在貸款額
只看借貸帳本會讓 Aave 看起來很主導。
但往下看,對比就會改變。
隨著更多抵押品上鏈,Aave 會成長。
隨著更多資金透過其借貸基礎設施流轉,Morpho 會成長。
隨著機構型借款人採用上鏈信用,Maple 會成長。
這些成長驅動因素並不互相競爭。
它們對應的是不同的市場。
Morpho 的 2.343 億美元年化費用,搭配 0 協議收入,反映出該協議仍把網路成長放在變現之前。
Maple 的貸款帳本只是 Aave 的一小部分。
但它的可觸及市場並非如此。
抵押品市場與信貸市場一直是不同的生意。
加密貨幣正在開始反映這種差異。
借貸這個類別本身沒有改變。
但支撐它的市場變了。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
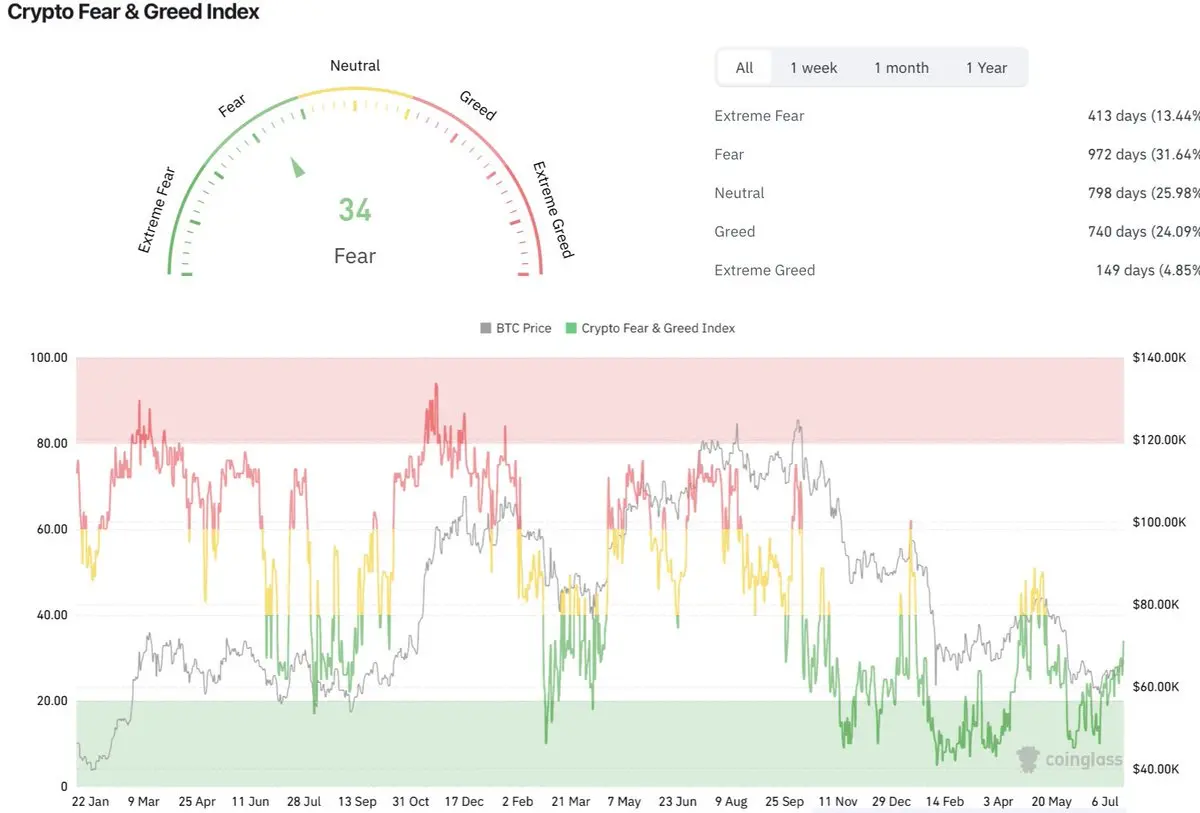
比特幣礦工正在開始關機。
不是因為他們預期比特幣會下跌。
而是因為其經濟性不再足以支撐每一台機器都持續線上運行。
這是一個重要的觀察因素。
礦工的獲利能力正在收緊。
Hashprice 告訴你原因。
…
α/ 壓力不是來自價格。
而是來自獲利能力。
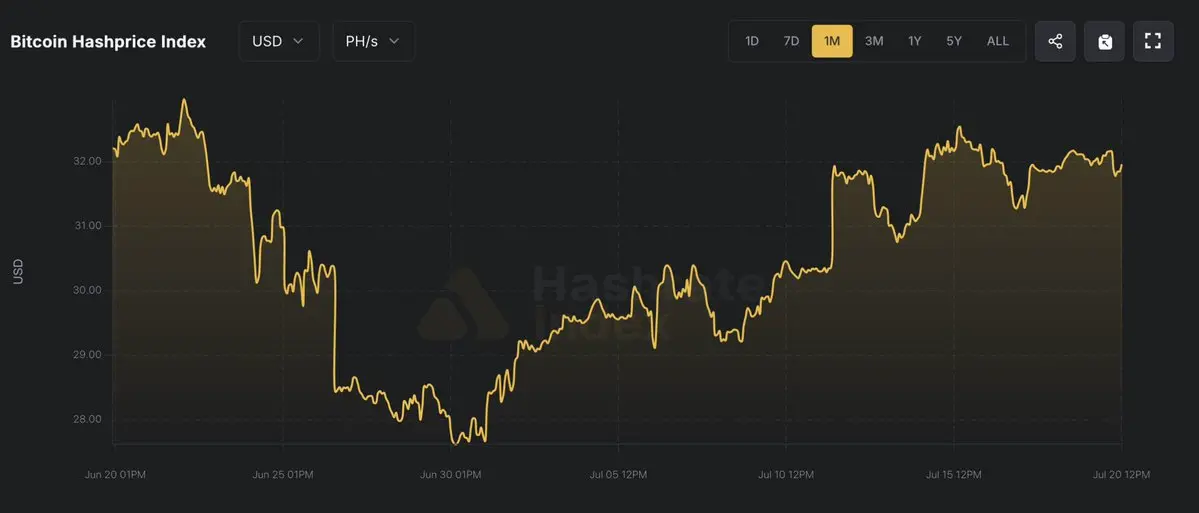
截至 7 月中旬,hashprice 每天為每 PH/s 報價 32.14 美元。
對於不斷增加的挖礦營運商而言,這幾乎等同於損益兩平。
當每單位算力的收入接近營運成本時,礦工不會立刻拋售比特幣。他們會理性化產能。
舊機器開始被切換關閉。
高成本場站變得不划算。
擴張計畫被延後。
網路似乎正是在為此定價。
…
α/ 哈希率與 Hashprice 正在印證同一個故事
單看任何一項指標,都無法呈現完整圖像。
但兩者結合,就會變得更難忽視。
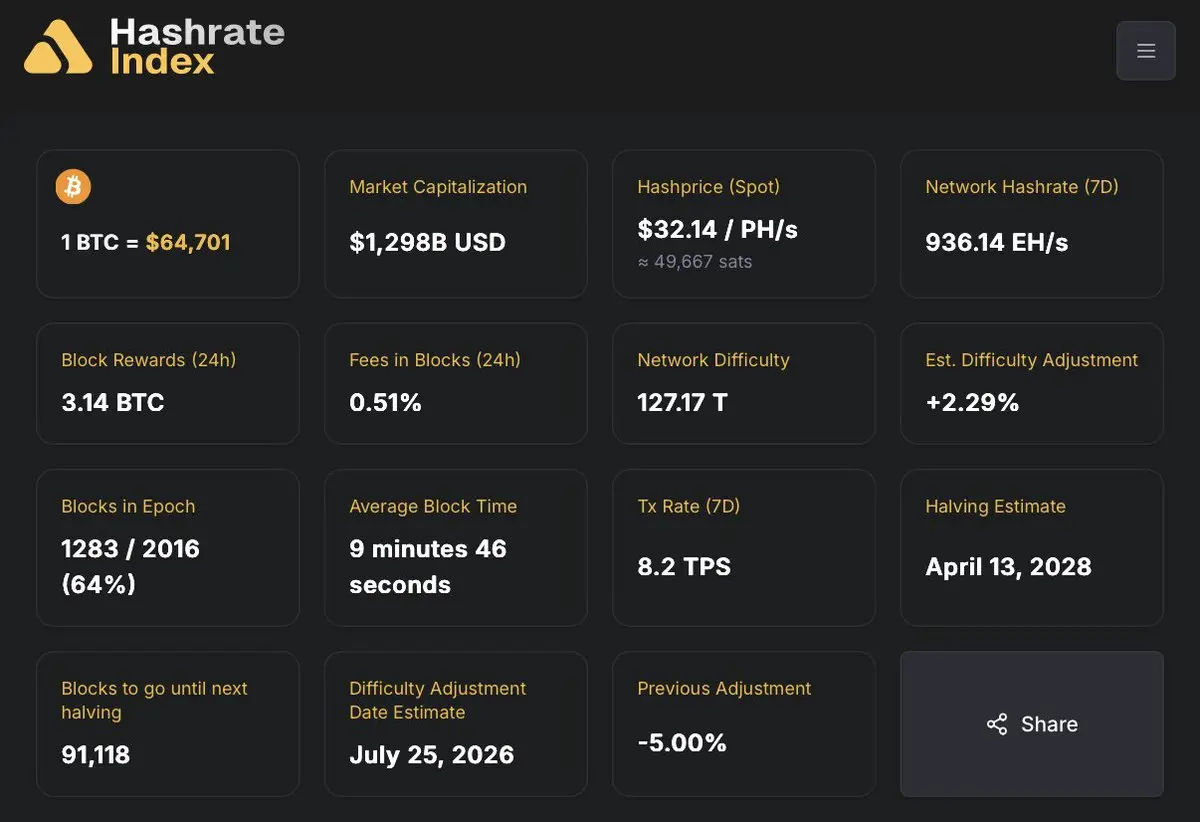
> 網路哈希率(7 日):936.14 EH/s(≈0.936 ZH/s)
> Hashprice(現貨):每天每 PH/s 32.14 美元
一個衡量的是計算能力。
另一個衡量的是這些計算能力能賺多少。
當獲利能力受到擠壓、同時網路成長開始放慢時,你通常看到的是利潤率壓力,而不是投機性的重新佈局。
這也是為什麼這套情境特別值得關注。
…
β/ 損益兩平方程式正在變得更緊
每一個挖礦事業最終都歸結於三個變數。
1. 車隊效率(J/TH)。
2. 電力成本。
3. Hashprice。
當其中一項惡化時,營
不是因為他們預期比特幣會下跌。
而是因為其經濟性不再足以支撐每一台機器都持續線上運行。
這是一個重要的觀察因素。
礦工的獲利能力正在收緊。
Hashprice 告訴你原因。
…
α/ 壓力不是來自價格。
而是來自獲利能力。
截至 7 月中旬,hashprice 每天為每 PH/s 報價 32.14 美元。
對於不斷增加的挖礦營運商而言,這幾乎等同於損益兩平。
當每單位算力的收入接近營運成本時,礦工不會立刻拋售比特幣。他們會理性化產能。
舊機器開始被切換關閉。
高成本場站變得不划算。
擴張計畫被延後。
網路似乎正是在為此定價。
…
α/ 哈希率與 Hashprice 正在印證同一個故事
單看任何一項指標,都無法呈現完整圖像。
但兩者結合,就會變得更難忽視。
> 網路哈希率(7 日):936.14 EH/s(≈0.936 ZH/s)
> Hashprice(現貨):每天每 PH/s 32.14 美元
一個衡量的是計算能力。
另一個衡量的是這些計算能力能賺多少。
當獲利能力受到擠壓、同時網路成長開始放慢時,你通常看到的是利潤率壓力,而不是投機性的重新佈局。
這也是為什麼這套情境特別值得關注。
…
β/ 損益兩平方程式正在變得更緊
每一個挖礦事業最終都歸結於三個變數。
1. 車隊效率(J/TH)。
2. 電力成本。
3. Hashprice。
當其中一項惡化時,營
BTC-0.24%
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
海耶斯說隱私是加密中最非對稱的交易,其實並不真的關乎隱私。
而是關乎需求。
兩條獨立的資金流正在落在同一個產業。
> 更廣泛的流動性擴張。抬升風險資產的同一個宏觀買盤。
> 隨著資本轉往鏈上,對金融保密性的需求上升。
這樣的情境比依賴單一催化劑更強。
但別犯每個市場在輪動時都會犯的錯誤。
產業的買盤不是專案的買盤。
貝塔讓你先搶到第一步。
執行決定是誰能保住它。
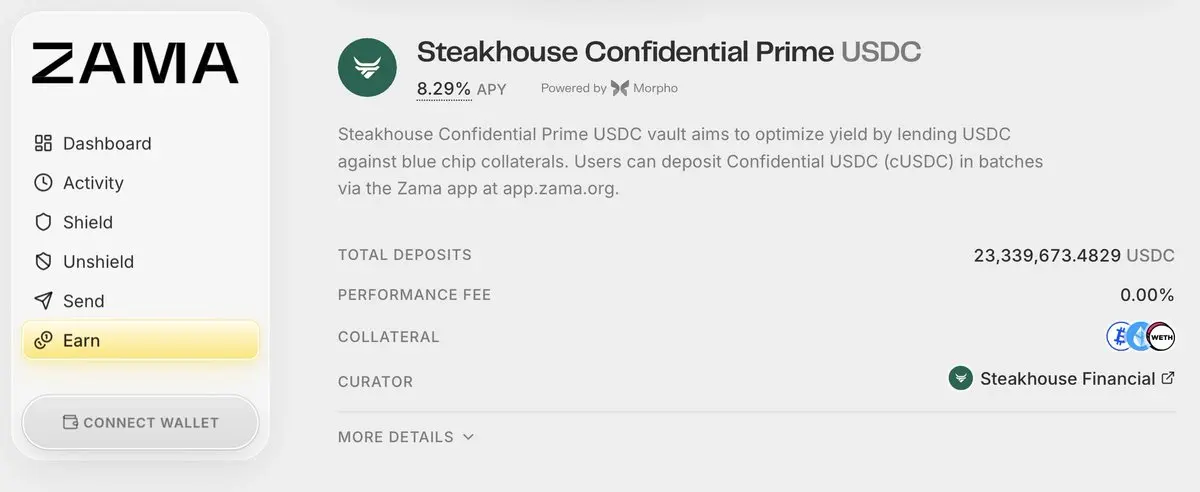
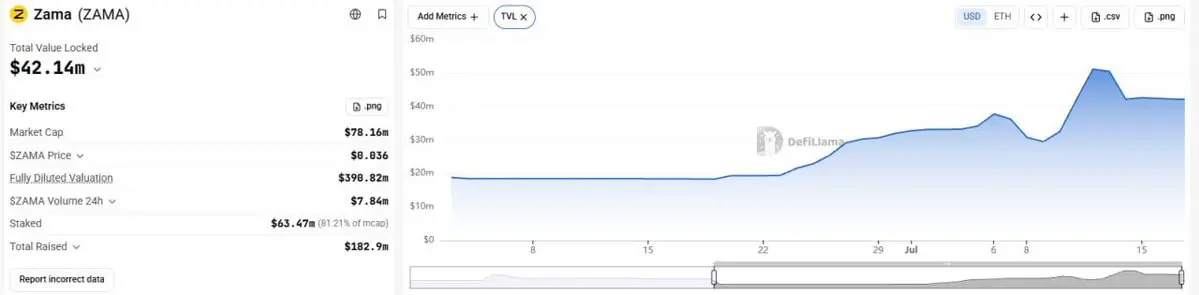
Zama 是該敘事中最早的真實測試案例之一。
一個接受保密型 USDC(cUSDC)的金庫,已經成長到約 23.3 萬美元,使其成為 Morpho 上最大型的 USDC 金庫之一。
這很有意義。
不是因為它證明保密性已經贏了。
而是因為它證明資本願意配置到保密型基礎設施,同時又不必離開它已經熟悉的那部分流動性。
這是一種比要求用戶遷移到新鏈更低摩擦的採用模式。
下一個里程碑不一樣。
TVL 證明人們願意嘗試它。
留存率證明他們想留下來。
市場最終為第二次付出的代價會比第一次高得多。
那裡才是真正的交易開始。
查看原文而是關乎需求。
兩條獨立的資金流正在落在同一個產業。
> 更廣泛的流動性擴張。抬升風險資產的同一個宏觀買盤。
> 隨著資本轉往鏈上,對金融保密性的需求上升。
這樣的情境比依賴單一催化劑更強。
但別犯每個市場在輪動時都會犯的錯誤。
產業的買盤不是專案的買盤。
貝塔讓你先搶到第一步。
執行決定是誰能保住它。
Zama 是該敘事中最早的真實測試案例之一。
一個接受保密型 USDC(cUSDC)的金庫,已經成長到約 23.3 萬美元,使其成為 Morpho 上最大型的 USDC 金庫之一。
這很有意義。
不是因為它證明保密性已經贏了。
而是因為它證明資本願意配置到保密型基礎設施,同時又不必離開它已經熟悉的那部分流動性。
這是一種比要求用戶遷移到新鏈更低摩擦的採用模式。
下一個里程碑不一樣。
TVL 證明人們願意嘗試它。
留存率證明他們想留下來。
市場最終為第二次付出的代價會比第一次高得多。
那裡才是真正的交易開始。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
2025 年,人人都想要一個數位資產金庫,因為光是公告本身就推動了股價。
即使是沒有任何經驗的公司也都急著建立數位資產金庫。
如今情況不同了。
他們多數都保持沉默。
查看原文即使是沒有任何經驗的公司也都急著建立數位資產金庫。
如今情況不同了。
他們多數都保持沉默。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
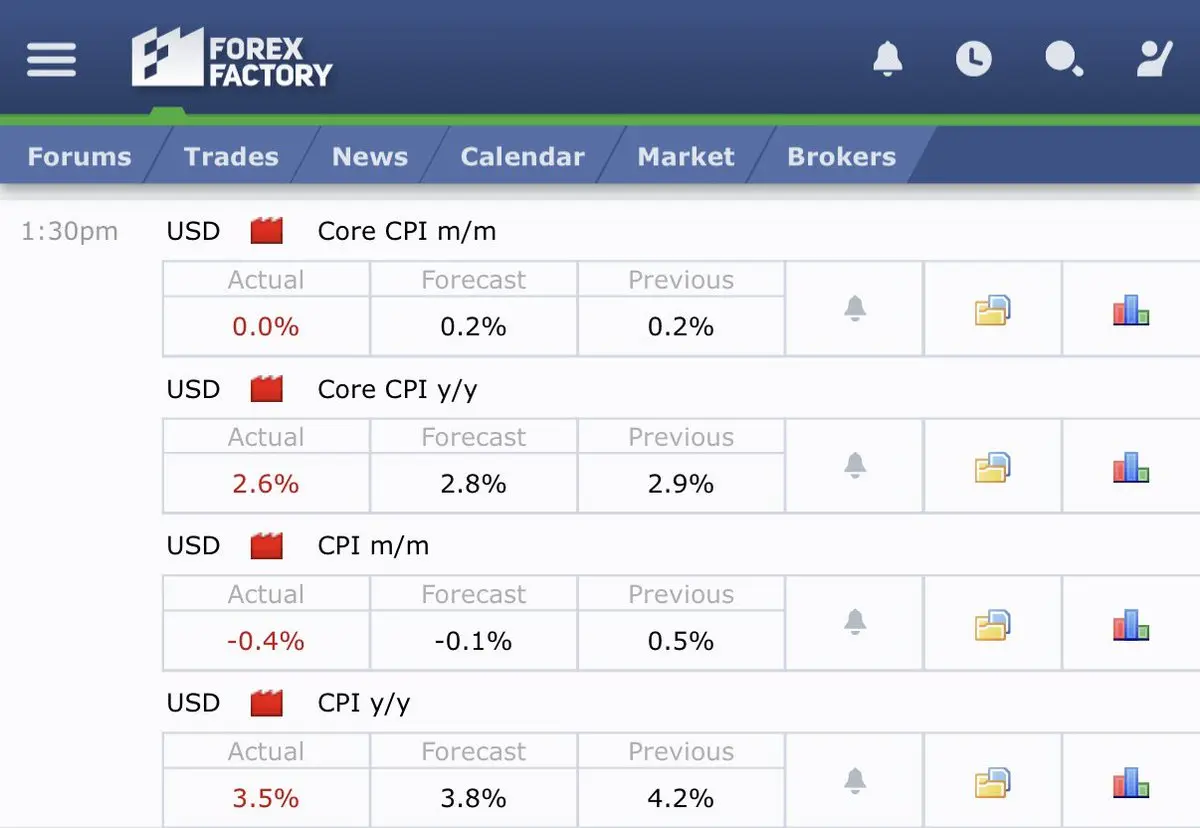
穩定幣已經贏了。
所有人都在看價格走勢圖。
大多數人不會。
他們只在意一件事:
我能不能花掉我的錢?
這就是為什麼加密貨幣支付卡可能會成為加密貨幣最重要的消費產品之一。
USDT 和 USDC 已經在流通中代表了數千億美元的規模。
挑戰不在於再做出一種新的穩定幣。
而是把人們已經持有的那些,變成能在日常生活中實際使用的穩定幣。
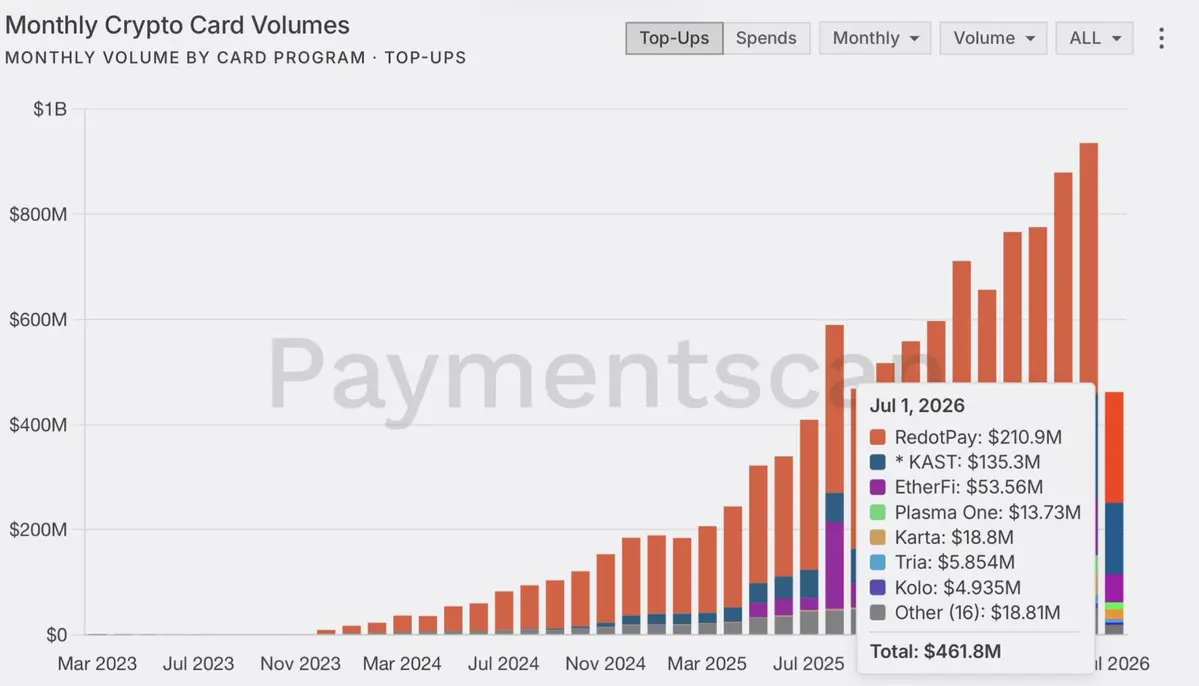
早期的領先者已經浮現:
> @RedotPay :每月進帳 2.1 億美元以上
> @KASTxyz :1.35 億美元以上
> @ether_fi 卡:5,300 萬美元以上
這些數字顯示,需求不是用在新資產上。
而是用在更好的支付通道。
這就是消費科技通常如何取勝的方法。
人們從沒因為理解 TCP/IP 而去採用網際網路。
他們採用了電子郵件、購物和串流。
基礎設施保持不顯眼。
加密貨幣很可能也會走同樣的路徑。
消費者不想要錢包、橋或燃氣費。
他們只想要一張能運作的卡。
如果穩定幣能在背景中完成支付結算,這就是產品。
機會不在於再多挖來更多加密貨幣用戶。
而是給數百萬名普通消費者一個理由,讓他們在不改變原本支付方式的情況下去消費數位美元。
區塊鏈是通道。
卡片是產品。
所有人都在看價格走勢圖。
大多數人不會。
他們只在意一件事:
我能不能花掉我的錢?
這就是為什麼加密貨幣支付卡可能會成為加密貨幣最重要的消費產品之一。
USDT 和 USDC 已經在流通中代表了數千億美元的規模。
挑戰不在於再做出一種新的穩定幣。
而是把人們已經持有的那些,變成能在日常生活中實際使用的穩定幣。
早期的領先者已經浮現:
> @RedotPay :每月進帳 2.1 億美元以上
> @KASTxyz :1.35 億美元以上
> @ether_fi 卡:5,300 萬美元以上
這些數字顯示,需求不是用在新資產上。
而是用在更好的支付通道。
這就是消費科技通常如何取勝的方法。
人們從沒因為理解 TCP/IP 而去採用網際網路。
他們採用了電子郵件、購物和串流。
基礎設施保持不顯眼。
加密貨幣很可能也會走同樣的路徑。
消費者不想要錢包、橋或燃氣費。
他們只想要一張能運作的卡。
如果穩定幣能在背景中完成支付結算,這就是產品。
機會不在於再多挖來更多加密貨幣用戶。
而是給數百萬名普通消費者一個理由,讓他們在不改變原本支付方式的情況下去消費數位美元。
區塊鏈是通道。
卡片是產品。
USDC0.01%
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
比特幣這週上漲 5%。
穿過伊朗的標題。
穿過總體經濟的雜訊。
穿過一切。
以下是實際在推動它的原因,並依照我們應該對每個解釋的把握程度排序。
…
1. 最清楚的那個:AI 和半導體正在走強。
美光(Micron)上漲 4.5%。SanDisk 上漲 7.6%。
當市場最火熱的板塊反彈時,整體風險偏好會打開,而比特幣往往也會跟著走。
這是對週內漲幅最直接、也最可追溯的解釋。
2. 更偏行為面的那個:其實沒有人真的賣出伊朗相關消息。
地緣政治標題引發影響。
市場看了它們。
市場決定不在意。
這不是分析。這只是事情真的發生了什麼。
當恐懼事件沒能製造恐懼,買盤就會進場,價格就會移動。
比特幣的受益點更多在於沒有出現拋售潮,而不是任何單一催化劑。
3. 最容易忽略的那個:日圓正在走弱。
日圓更軟,使得以美元計價的資產在當地貨幣口徑下看起來更強。
持有比特幣的日本以及更廣泛的亞洲投資人,會看到放大的報酬,這有助於即使西方市場情緒持平,買盤壓力仍維持在高位。
這個效果是真實的,但也是最難衡量的。
沒有任何一個原因能單獨解釋在這麼多雜訊之下仍出現 4.2% 的週漲幅。
但合在一起,可能就能解釋。
…
我的看法
比特幣這週的韌性並不是由一波新的信心浪潮推動。
而是由於沒有「理由去賣出」,再加上許多人忽略的總體經濟順風所強化。
這和結構性突破是完全不同的局面。
弄清兩者的差別,比把兩者都說成同一回
查看原文穿過伊朗的標題。
穿過總體經濟的雜訊。
穿過一切。
以下是實際在推動它的原因,並依照我們應該對每個解釋的把握程度排序。
…
1. 最清楚的那個:AI 和半導體正在走強。
美光(Micron)上漲 4.5%。SanDisk 上漲 7.6%。
當市場最火熱的板塊反彈時,整體風險偏好會打開,而比特幣往往也會跟著走。
這是對週內漲幅最直接、也最可追溯的解釋。
2. 更偏行為面的那個:其實沒有人真的賣出伊朗相關消息。
地緣政治標題引發影響。
市場看了它們。
市場決定不在意。
這不是分析。這只是事情真的發生了什麼。
當恐懼事件沒能製造恐懼,買盤就會進場,價格就會移動。
比特幣的受益點更多在於沒有出現拋售潮,而不是任何單一催化劑。
3. 最容易忽略的那個:日圓正在走弱。
日圓更軟,使得以美元計價的資產在當地貨幣口徑下看起來更強。
持有比特幣的日本以及更廣泛的亞洲投資人,會看到放大的報酬,這有助於即使西方市場情緒持平,買盤壓力仍維持在高位。
這個效果是真實的,但也是最難衡量的。
沒有任何一個原因能單獨解釋在這麼多雜訊之下仍出現 4.2% 的週漲幅。
但合在一起,可能就能解釋。
…
我的看法
比特幣這週的韌性並不是由一波新的信心浪潮推動。
而是由於沒有「理由去賣出」,再加上許多人忽略的總體經濟順風所強化。
這和結構性突破是完全不同的局面。
弄清兩者的差別,比把兩者都說成同一回
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
市場正在將這次拋售與2022年進行比較。
我認為這種比較忽略了一個最重要的差異。
兩個市場都經歷了急劇的下跌。
但只有其中一個經歷了信任的崩潰。
這是一個值得關注的區別。
2022年,加密貨幣不僅僅是在重新定價風險。
其核心基礎設施正在失效。
> Terra 的算法穩定幣脫鉤,抹去了約 400 億美元的價值。
> FTX 在發現客戶資金被不當處理後倒閉。
> 信心消失,因為用戶不再知道哪些平台實際上有償付能力。
那輪熊市是由結構性失敗驅動的。
今天的市場看起來不同。
比特幣已從 93,000 美元以上跌至 50,000 美元區間的高位。
現貨 ETF 出現持續資金流出。
許多山寨幣已跌去超過一半的價值。
然而,市場的基礎在很大程度上保持穩固。
> 主要交易所繼續正常運營。
> 領先的穩定幣維持了其掛鉤。
> 客戶提款沒有被大範圍凍結。
> 沒有出現系統重要性資產負債表失敗。
價格正在下跌。
但基礎設施沒有。
這改變了我對這個週期的看法。
當前的阻力主要來自宏觀層面。
ETF 需求疲軟。
資金輪動到人工智慧。
聯準會的不確定性使流動性保持緊張。
這些因素降低了對加密資產的需求。
它們並不會削弱人們對支撐生態系統的金融管道的信心。
這就是為什麼復甦路徑看起來不同。
2
查看原文我認為這種比較忽略了一個最重要的差異。
兩個市場都經歷了急劇的下跌。
但只有其中一個經歷了信任的崩潰。
這是一個值得關注的區別。
2022年,加密貨幣不僅僅是在重新定價風險。
其核心基礎設施正在失效。
> Terra 的算法穩定幣脫鉤,抹去了約 400 億美元的價值。
> FTX 在發現客戶資金被不當處理後倒閉。
> 信心消失,因為用戶不再知道哪些平台實際上有償付能力。
那輪熊市是由結構性失敗驅動的。
今天的市場看起來不同。
比特幣已從 93,000 美元以上跌至 50,000 美元區間的高位。
現貨 ETF 出現持續資金流出。
許多山寨幣已跌去超過一半的價值。
然而,市場的基礎在很大程度上保持穩固。
> 主要交易所繼續正常運營。
> 領先的穩定幣維持了其掛鉤。
> 客戶提款沒有被大範圍凍結。
> 沒有出現系統重要性資產負債表失敗。
價格正在下跌。
但基礎設施沒有。
這改變了我對這個週期的看法。
當前的阻力主要來自宏觀層面。
ETF 需求疲軟。
資金輪動到人工智慧。
聯準會的不確定性使流動性保持緊張。
這些因素降低了對加密資產的需求。
它們並不會削弱人們對支撐生態系統的金融管道的信心。
這就是為什麼復甦路徑看起來不同。
2
- 打賞
- 按讚
- 回覆
- 轉發
- 分享