Gate Ventures Research Insights: Третья война браузеров: Битва за вход в эпоху AI-агентов


TL;DR
Третья битва браузеров тихо разворачивается. Оглядываясь на историю, от Netscape и Internet Explorer от Microsoft в 1990-х до открытого Firefox и Chrome от Google, браузерная война всегда была концентрированным проявлением контроля платформ и технологических парадигм. Chrome обеспечил свою доминирующую позицию благодаря быстрой скорости обновлений и интегрированной экосистеме, в то время как Google, благодаря своему дуополии в поиске и браузерах, сформировал замкнутый круг доступа к информации.
Но сегодня этот ландшафт сотрясается. Появление крупных языковых моделей (LLM) позволяет всё большему числу пользователей выполнять задачи, не переходя на страницу результатов поиска, в то время как традиционные клики по веб-страницам снижаются. Тем временем слухи о том, что Apple намерена заменить поисковую систему по умолчанию в Safari, еще больше угрожают прибыльной базе Alphabet (материнской компании Google), и рынок начинает выражать беспокойство по поводу "ортодоксии поиска".
Браузер сам по себе также сталкивается с пересмотром своей роли. Он уже не просто инструмент для отображения веб-страниц, но и контейнер для множества возможностей, включая ввод данных, поведение пользователей и частную идентичность. Хотя агентам ИИ присуща мощь, они все еще зависят от границы доверия браузера и функционального песочницы для выполнения сложных взаимодействий на страницах, доступа к локальным данным идентичности и управления элементами веб-страниц. Браузеры эволюционируют от человеческих интерфейсов к платформам системных вызовов для агентов.
В этой статье мы исследуем, нужны ли браузеры все еще. Мы считаем, что то, что действительно может нарушить текущий ландшафт рынка браузеров, это не другой «лучший Chrome», а новая структура взаимодействия: не просто отображение информации, а вызов задач. Будущие браузеры должны быть спроектированы для ИИ-агентов — способных не только читать, но и писать и выполнять. Проекты, такие как Browser Use, пытаются семантизировать структуру страниц, трансформируя визуальные интерфейсы в структурированный текст, который можно вызывать с помощью LLM, сопоставляя страницы с командами и значительно снижая затраты на взаимодействие.
Крупные проекты уже тестируют возможности: Perplexity создает собственный браузер Comet, который заменяет традиционные результаты поиска на ИИ; Brave сочетает защиту конфиденциальности с локальным рассуждением, используя LLM для улучшения поиска и блокировки; а крипто-нативные проекты, такие как Donut, нацелены на новые точки входа для взаимодействия ИИ с ончейн-активами. Общей чертой этих проектов является их попытка изменить входной слой браузера, а не украшать его выходной слой.
Для предпринимателей возможности заключаются в треугольнике входных данных, структуры и доступа к агенту. В качестве интерфейса для будущего мира, основанного на агентах, браузер означает, что тот, кто может предоставить структурированные, вызываемые и надежные "возможности", станет компонентом платформы следующего поколения. От SEO до AEO (оптимизация движка агентов), от трафика страниц до вызова цепочек задач, форма продукта и дизайн мышления переосмысляются. Третья война браузеров происходит из-за "входных данных", а не "отображения". Победа больше не определяется тем, кто привлекает внимание пользователя, а тем, кто завоевывает доверие агента и получает доступ.
Краткая история разработки браузеров
В начале 1990-х годов, еще до того как интернет стал частью повседневной жизни, Netscape Navigator ворвался на сцену, как парусник, открывший дверь в цифровой мир для миллионов пользователей. Хотя это не был первый браузер, он стал первым, кто действительно достиг масс и сформировал интернет-опыт. Впервые люди могли легко просматривать веб через графический интерфейс, как будто весь мир внезапно стал доступным.
Тем не менее, слава часто недолговечна. Microsoft быстро осознала важность браузеров и решила принудительно объединить Internet Explorer с операционной системой Windows, сделав его браузером по умолчанию. Эта стратегия, настоящий "убийца платформы", напрямую подорвала рыночное господство Netscape. Многие пользователи не выбирали IE активно; скорее, они просто принимали его как браузер по умолчанию. Используя возможности распространения Windows, IE быстро стал лидером отрасли, в то время как Netscape пришел в упадок.

В разгар трудностей инженеры Netscape выбрали радикальный и идеалистичный путь — они открыли исходный код браузера и призвали сообщество с открытым исходным кодом. Это решение стало своего рода «македонской отставкой» в мире технологий, сигнализируя о конце старой эпохи и восходе новых сил. Этот код позже стал основой проекта браузера Mozilla, первоначально названного Phoenix (символизируя возрождение), но после нескольких споров по поводу товарного знака он был наконец переименован в Firefox.
Firefox не был простым клоном Netscape. Он совершил прорывы в пользовательском опыте, экосистемах плагинов и безопасности. Его появление ознаменовало победу духа открытого исходного кода и вдохнуло новую жизнь в целую индустрию. Некоторые описывали Firefox как "духовного наследника" Netscape, подобно тому, как Османская империя унаследовала угасшую славу Византии. Хотя сравнение и преувеличено, оно имеет смысл.
Однако, прежде чем Firefox был официально выпущен, Microsoft уже запустила шесть версий Internet Explorer. Используя свою раннюю тактику и стратегию системной упаковки, Firefox оказался в позиции догоняющего с самого начала, что обеспечило, что эта гонка никогда не была равной конкуренцией, начиная с одной линии.
В то же время на сцену тихо вышел еще один ранний игрок. В 1994 году в Норвегии появился браузер Opera, изначально представлявший собой экспериментальный проект. Но начиная с версии 7.0 в 2003 году, он представил собственно разработанный движок Presto, первыми внедрив поддержку CSS, адаптивные макеты, голосовое управление и кодировку Unicode. Хотя его пользовательская база была ограничена, он постоянно лидировал в технологическом плане, становясь «любимцем геeks».
В том же году Apple запустила браузер Safari — значительная веха. В то время Microsoft вложила 150 миллионов долларов в struggling Apple, чтобы сохранить видимость конкуренции и избежать антимонопольного контроля. Хотя поисковая система по умолчанию для Safari с самого начала была Google, эта связь с Microsoft символизировала сложные и тонкие отношения среди интернет-гигантов: сотрудничество и конкуренция, всегда переплетенные.
В 2007 году IE7 был выпущен одновременно с Windows Vista, но реакция рынка была прохладной. Firefox, с другой стороны, постепенно увеличивал свою долю на рынке до примерно 20%, благодаря более быстрым циклам обновления, более удобному механизму расширений и естественной привлекательности для разработчиков. Господство IE начало ослабевать, и ветер перемен дул в другую сторону.
Тем не менее, Google выбрала другой подход. Хотя компания планировала свой собственный браузер с 2001 года, ей потребовалось шесть лет, чтобы убедить генерального директора Эрика Шмидта утвердить проект. Chrome дебютировал в 2008 году, основанный на проекте с открытым исходным кодом Chromium и движке WebKit, используемом в Safari. Его высмеивали как «раздутый» браузер, но благодаря глубокому опыту Google в рекламе и построении брендов, он быстро набрал популярность.
Ключевым оружием Chrome были не его функции, а частота обновлений (каждые шесть недель) и единый кроссплатформенный опыт. В ноябре 2011 года Chrome впервые обошел Firefox, достигнув 27% доли рынка; через шесть месяцев он обошел IE, завершив свою трансформацию из конкурента в доминирующего лидера.
Тем временем в Китае формировалась собственная экосистема мобильного интернета. В начале 2010-х годов браузер UC компании Alibaba набрал популярность, особенно на развивающихся рынках, таких как Индия, Индонезия и Китай. Благодаря легкому дизайну и функциям сжатия данных, которые экономили трафик, он завоевал пользователей на устройствах начального уровня. К 2015 году его доля на глобальном рынке мобильных браузеров превысила 17%, а в Индии однажды достигла 46%. Но эта победа была недолговечной. Когда индийское правительство ужесточило проверку безопасности китайских приложений, браузер UC был вынужден покинуть ключевые рынки, постепенно теряя свою прежнюю славу.
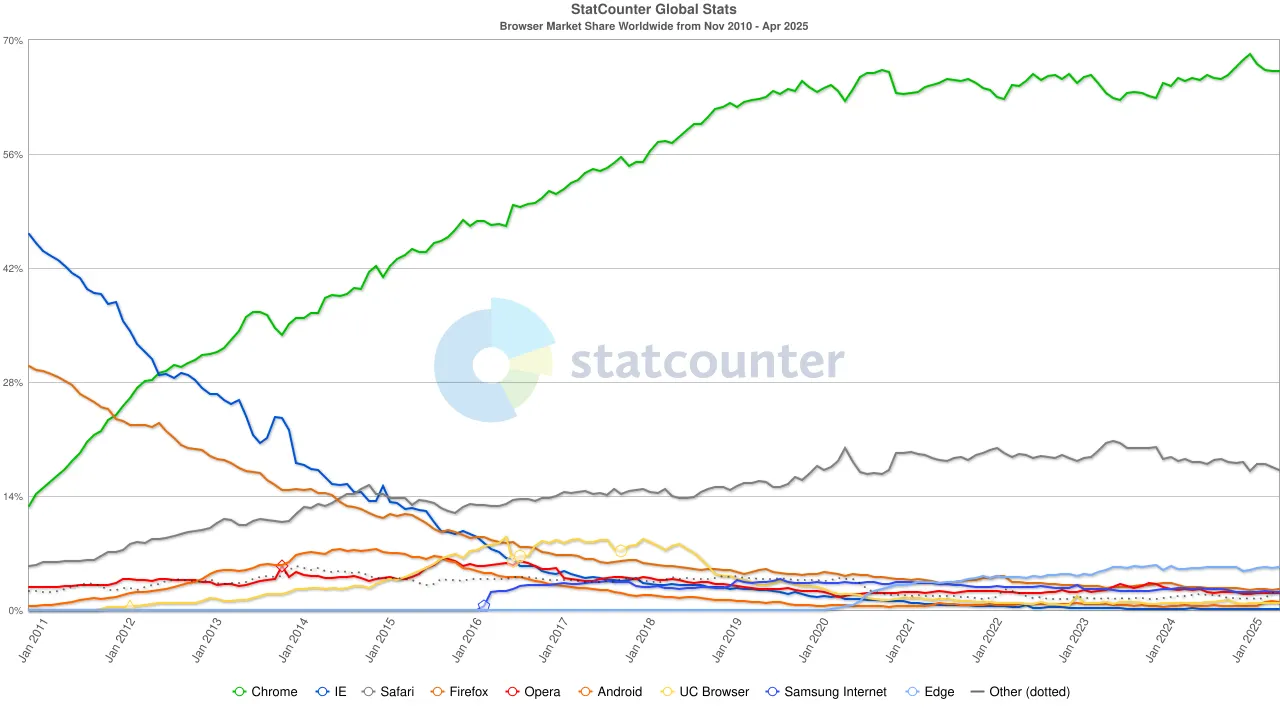
К 2020-м годам доминирование Chrome было твердо установлено, его доля на мировом рынке стабилизировалась на уровне около 65%. Примечательно, что, хотя поисковая система Google и браузер Chrome оба принадлежат Alphabet, с точки зрения рынка они представляют собой две независимые гегемонии — первая контролирует около 90% глобального поискового трафика, а последняя служит «первым окном», через которое большинство пользователей получает доступ к интернету.
Чтобы поддерживать эту двойную монополию, Google не жалеет расходов. В 2022 году Alphabet заплатила Apple около 20 миллиардов долларов только для того, чтобы сохранить Google в качестве поискового движка по умолчанию в Safari. Аналитики отмечали, что эти затраты составили около 36% от доходов от поисковой рекламы, которые Google заработал на трафике из Safari. Другими словами, Google фактически платил «защиту», чтобы защитить свою нишу.
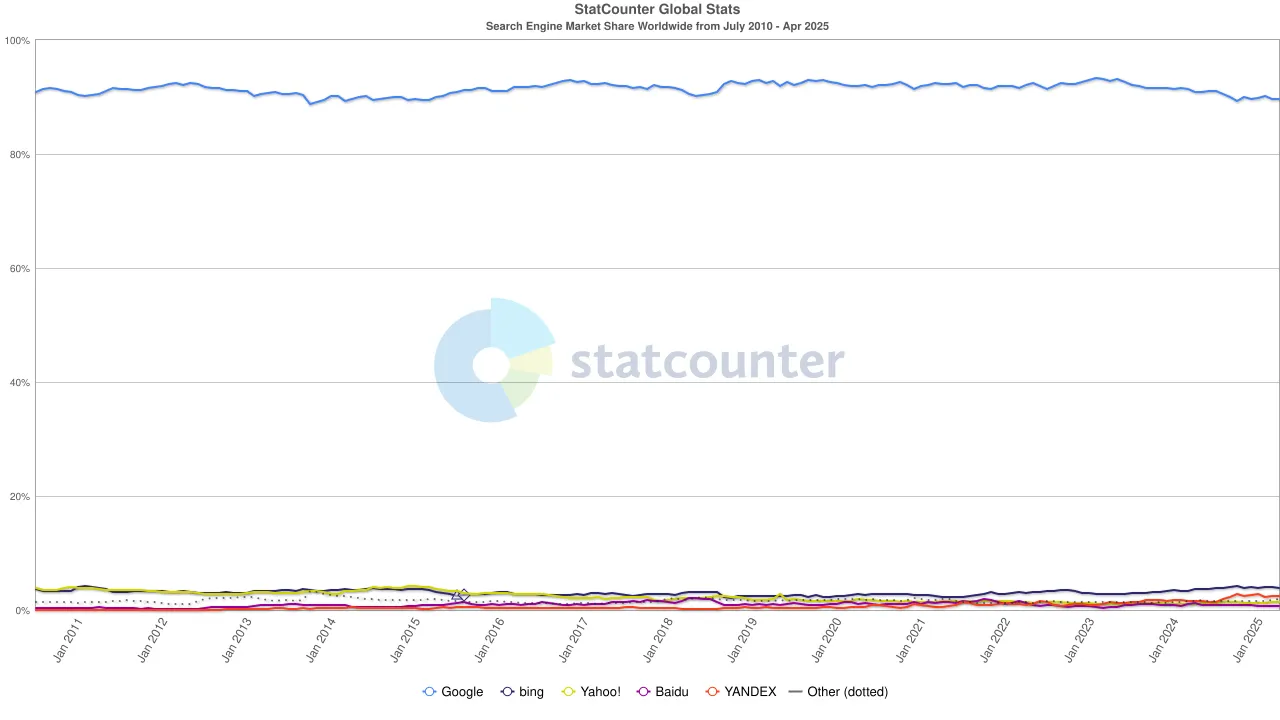
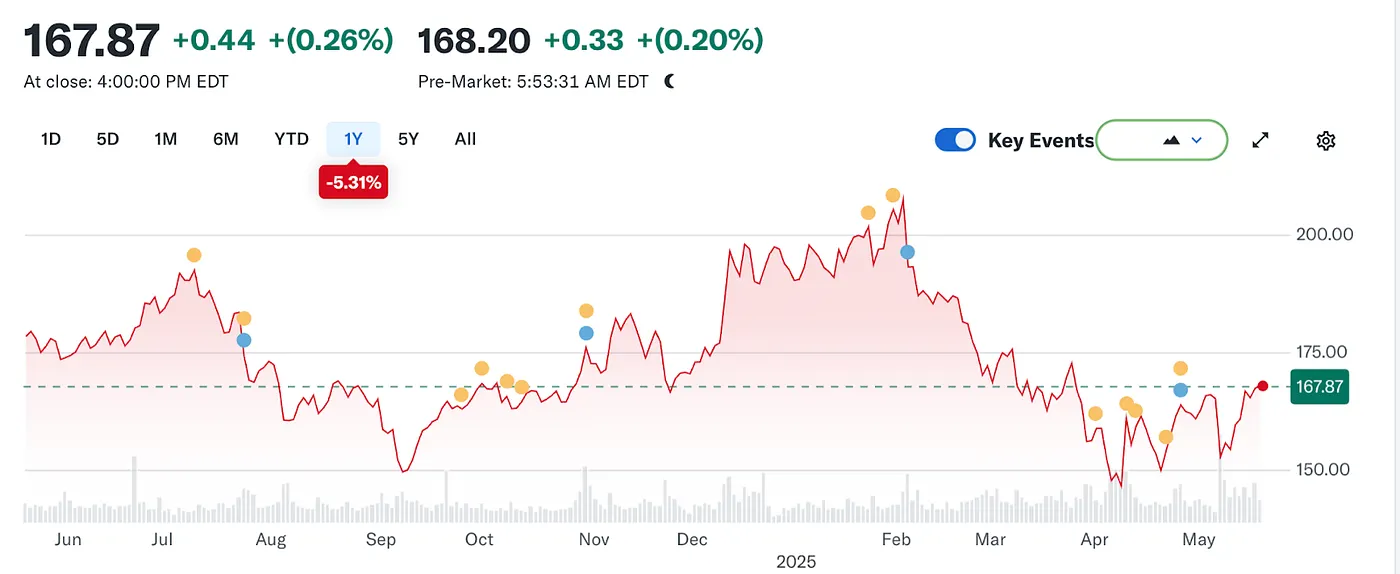
Но潮又一次发生了变化。随着大型语言模型(LLM)的崛起,传统搜索开始感受到影响。到2024年,谷歌在搜索市场的份额从93%降至89%。尽管它仍然占主导地位,但裂痕开始显现。更具颠覆性的是,有传言称苹果可能会推出自己的AI驱动的搜索引擎。如果Safari的默认搜索切换到苹果自己的生态系统,这不仅会重塑竞争格局,还可能动摇Alphabet利润的根基。市场迅速反应:Alphabet的股价从170美元跌至140美元,反映出投资者的恐慌以及对搜索时代未来走向的深刻不安。
От Навигатора до Chrome, от идеалов открытого исходного кода до коммерциализации, основанной на рекламе, от легковесных браузеров до AI-поисковых ассистентов, битва браузеров всегда была войной за технологии, платформы, контент и контроль. Поле битвы постоянно меняется, но суть никогда не менялась: кто контролирует Gateway, тот определяет будущее.
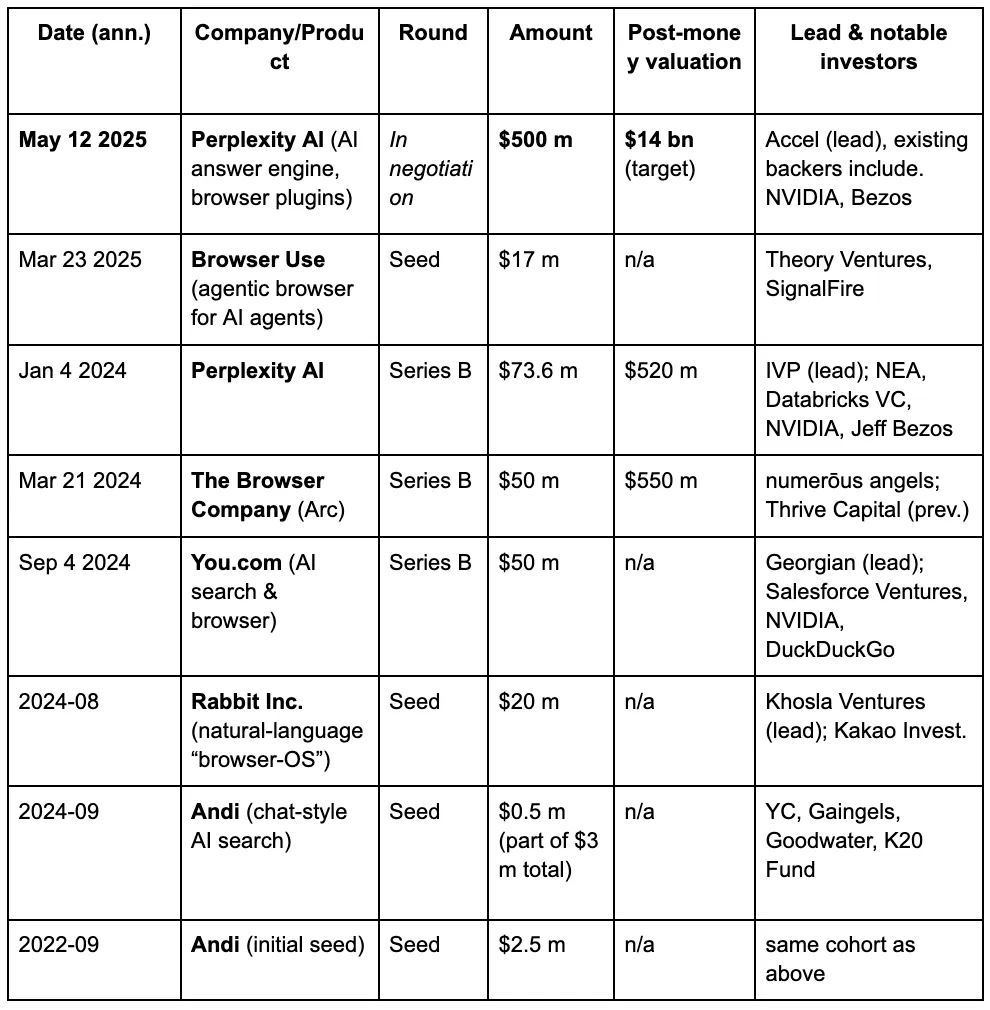
В глазах венчурных капиталистов третья война браузеров постепенно разворачивается, вызванная новыми требованиями, которые люди предъявляют к поисковым системам в эпоху LLM и ИИ. Ниже приведены детали финансирования некоторых известных проектов в области AI-браузеров.
Устаревшая архитектура современных браузеров
Когда дело доходит до архитектуры браузера, классическая традиционная структура показана на диаграмме ниже:
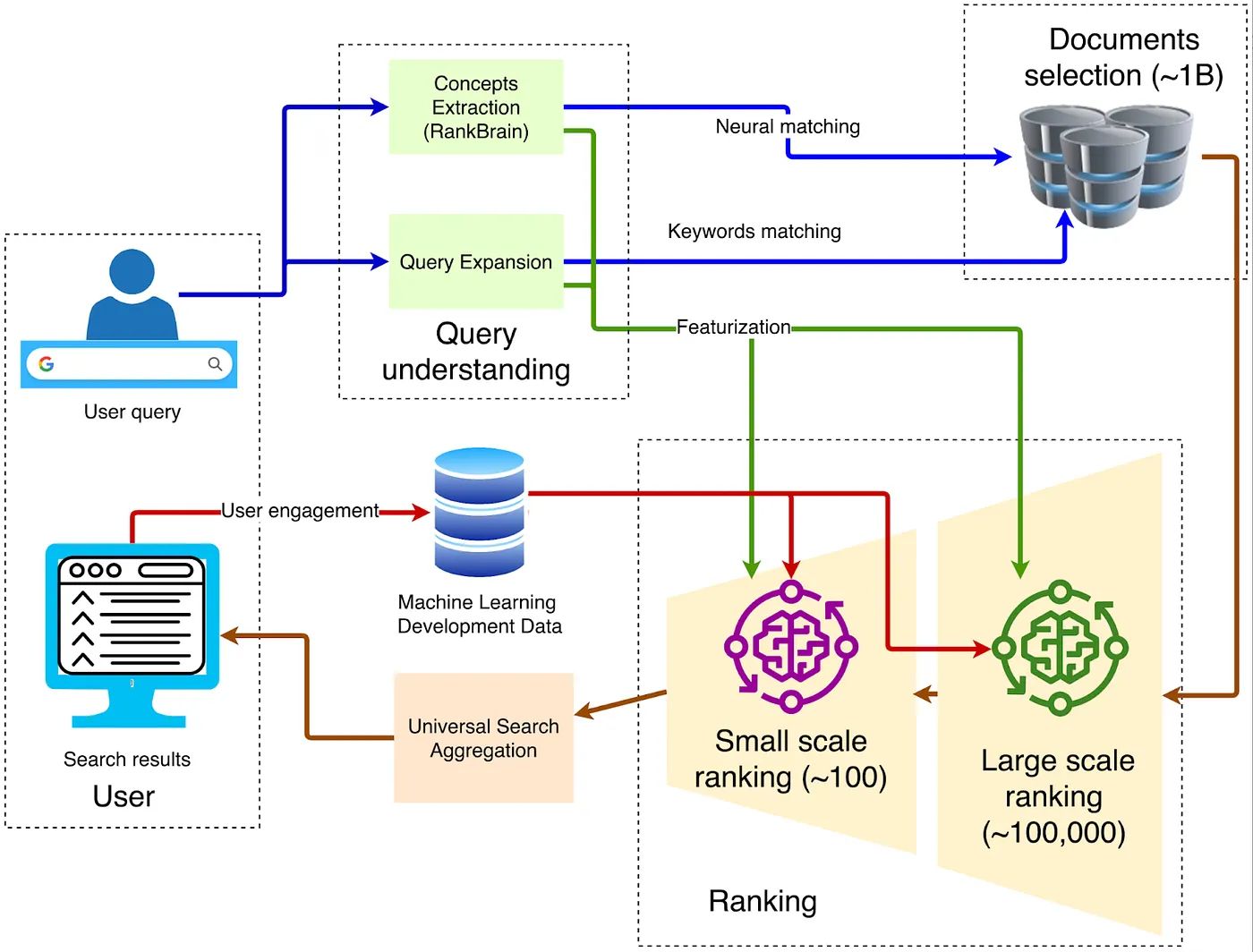
1. Клиент — Вход на клиентскую сторону
Запрос отправляется по HTTPS на ближайший Google Front End, где выполняется расшифровка TLS, выборка QoS и географическая маршрутизация. Если обнаруживается аномальный трафик (например, DDoS-атаки или автоматический скрапинг), на этом уровне могут быть применены ограничения скорости или проверки.
2. Понимание запроса
Интерфейс должен понимать значение слов, введенных пользователем. Это включает в себя три шага:
Нейронная коррекция орфографии, такая как преобразование «recpie» в «recipe».
Расширение синонимов, например, расширение «как починить велосипед» для включения «ремонт велосипеда».
Парсинг намерений, который определяет, является ли запрос информационным, навигационным или транзакционным, а затем назначает соответствующий вертикальный запрос.
3. Извлечение кандидатов
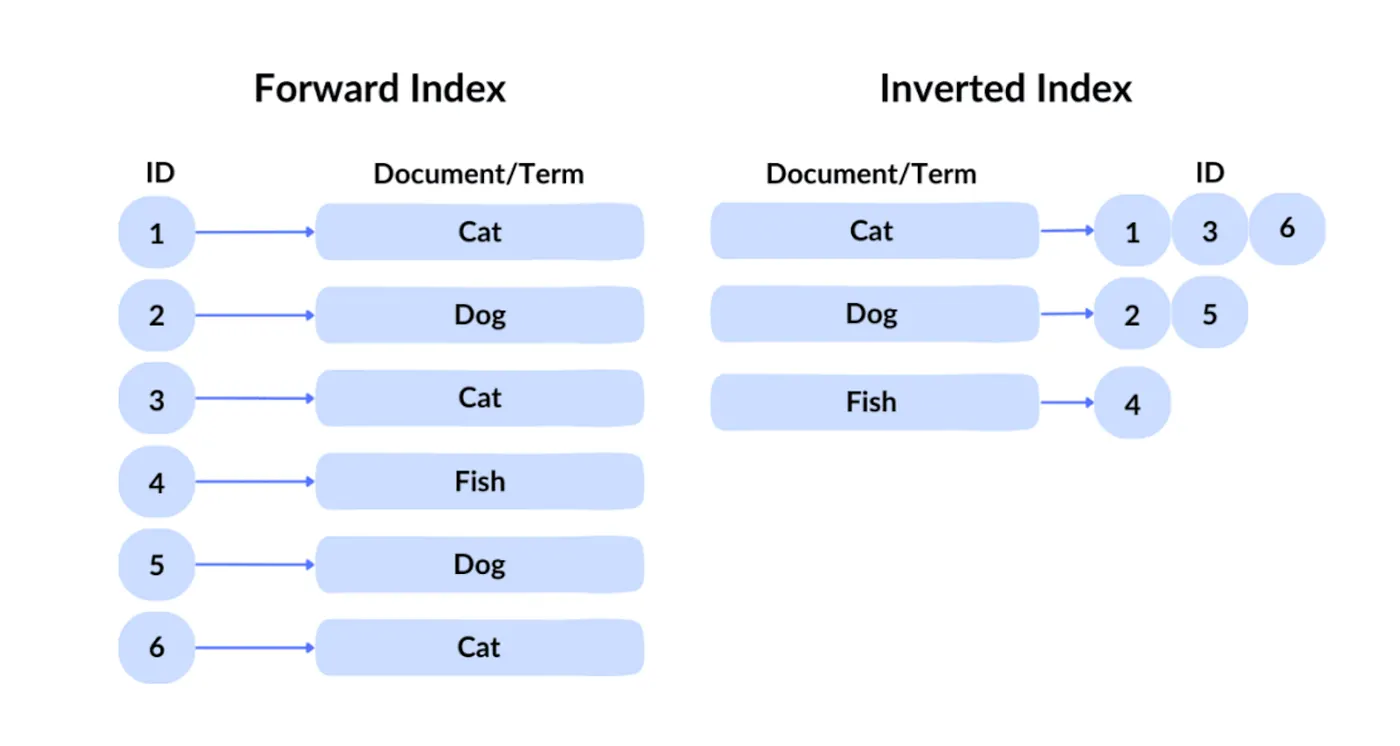
Технология запросов Google известна как инвертированный индекс. В прямом индексе вы получаете файл по его идентификатору. Однако, поскольку пользователи не могут знать идентификаторы желаемого контента среди сотен миллиардов файлов, Google использует традиционный инвертированный индекс, который запрашивает по содержимому, чтобы определить, какие файлы содержат соответствующие ключевые слова.
Затем Google применяет векторное индексирование для обработки семантического поиска — то есть для поиска контента, схожего по смыслу с запросом. Он преобразует текст, изображения и другой контент в высокоразмерные векторы (встраивания), а затем ищет на основе сходства между этими векторами. Например, если пользователь ищет "как сделать тесто для пиццы", поисковая система может вернуть результаты, связанные с "руководством по приготовлению теста для пиццы", поскольку эти два запроса семантически схожи.
С помощью инвертированного индексирования и векторного индексирования на начальном этапе фильтруется примерно несколько сотен тысяч веб-страниц.
4. Многоступенчатый рейтинг
Система обычно использует тысячи легковесных функций, таких как BM25, TF-IDF и оценки качества страниц, чтобы отфильтровать сотни тысяч страниц-кандидатов до примерно 1 000, формируя начальный набор кандидатов. Такие системы в совокупности называют рекомендательными системами. Они полагаются на огромные функции, полученные от различных сущностей, включая поведение пользователей, атрибуты страниц, намерение запроса и контекстные сигналы. Например, Google сочетает историю пользователей, отзывы от других пользователей, семантику страниц и значение запросов, одновременно учитывая контекстуальные элементы, такие как время (время суток, день недели) и внешние события, такие как срочные новости.
5. Глубокое обучение для первичной ранжировки
На начальном этапе извлечения Google использует технологии, такие как RankBrain и Neural Matching, чтобы понять семантику запросов и отфильтровать наиболее релевантные результаты из огромных коллекций документов.
RankBrain, введенный Google в 2015 году, является системой машинного обучения, разработанной для лучшего понимания значения пользовательских запросов, особенно запросов, которые никогда ранее не встречались. Она преобразует запросы и документы в векторные представления и вычисляет их сходство, чтобы найти наиболее релевантные результаты. Например, для запроса "как сделать тесто для пиццы", даже если ни один документ не содержит точного совпадения ключевого слова, RankBrain может идентифицировать контент, связанный с "основами пиццы" или "приготовлением теста."
Нейронное сопоставление, запущенное в 2018 году, было разработано для более глубокого захвата семантической связи между запросами и документами. Используя модели нейронных сетей, оно идентифицирует нечеткие отношения между словами для более точного сопоставления запросов с веб-контентом. Например, для запроса "почему мой вентилятор ноутбука так шумит" Нейронное сопоставление может понять, что пользователь может искать информацию по устранению неполадок, связанным с перегревом, накоплением пыли или высокой загрузкой ЦП, даже если эти термины не появляются явно в запросе.
6. Глубокая переоценка: Применение BERT
После первоначальной фильтрации соответствующих документов Google применяет BERT (двунаправленные представления кодировщиков из трансформеров), чтобы уточнить ранжирование и гарантировать, что наиболее релевантные результаты появляются вверху. BERT — это предварительно обученная языковая модель на основе трансформеров, которая может понимать контекстуальные отношения слов в пределах предложений.
В поиске BERT используется для повторной сортировки документов, извлеченных на предыдущих этапах. Он совместно кодирует запросы и документы, вычисляет их оценки релевантности, а затем переупорядочивает документы. Например, для запроса "парковка на холме без бордюра" BERT может правильно интерпретировать значение "без бордюра" и вернуть результаты, советующие водителям поворачивать свои колеса к обочине, а не неправильно интерпретировать это как ситуацию с бордюром.
Для SEO-инженеров это означает, что им необходимо тщательно изучать алгоритмы ранжирования и рекомендации машинного обучения Google, чтобы оптимизировать веб-контент целенаправленным образом, тем самым получая более высокую видимость в результатах поиска.
Почему ИИ изменит браузеры
Сначала нам нужно прояснить: почему браузер как форма все еще должен существовать? Существует ли третья парадигма помимо AI-агентов и браузеров?
Мы считаем, что существование подразумевает незаменимость. Почему искусственный интеллект может использовать браузеры, но не может полностью заменить их? Потому что браузер является универсальной платформой. Он не только точка входа для чтения данных, но и общий вход для ввода данных. Мир не может только потреблять информацию — он также должен производить данные и взаимодействовать с веб-сайтами. Поэтому браузеры, которые интегрируют персонализированную информацию пользователя, будут продолжать широко существовать.
Вот ключевой момент: в качестве универсального шлюза браузер предназначен не только для чтения данных; пользователям часто нужно взаимодействовать с данными. Сам браузер является отличным хранилищем для хранения отпечатков пользователей. Более сложные действия пользователей и автоматизированные действия должны выполняться через браузер. Браузер может хранить все отпечатки поведения пользователей, учетные данные и другую частную информацию, позволяя бездоверительно вызывать автоматизацию. Взаимодействие с данными может развиться в этот шаблон:
Пользователь → вызывает AI Агент → Браузер.
Другими словами, единственная часть, которую можно заменить, заключается в естественном направлении мира — к большей интеллектуальности, персонализации и автоматизации. Безусловно, эта часть может быть обработана агентами ИИ. Но сами агенты ИИ не очень подходят для передачи персонализированного пользовательского контента, поскольку они сталкиваются с множеством проблем, касающихся безопасности данных и удобства использования. В частности:
Браузер является хранилищем для персонализированного контента:
Большинство крупных моделей размещены в облаке, с контекстами сессий, зависящими от хранения на сервере, что затрудняет прямой доступ к локальным паролям, кошелькам, куки и другим конфиденциальным данным.
Отправка всех данных о просмотре и платежах третьим лицам требует повторного разрешения пользователя; Директива ЕС по цифровым рынкам (DMA) и законы о конфиденциальности на уровне штатов в США требуют минимизации данных через границы.
Автоматическое заполнение кодов двухфакторной аутентификации, вызов камер или использование GPU для вывода WebGPU должно происходить в песочнице браузера.
Контекст данных сильно зависит от браузера. Вкладки, куки, IndexedDB, кэш Service Worker, учетные данные ключа доступа и данные расширений все хранятся в браузере.
Глубокие изменения в формах взаимодействия
Возвращаясь к теме, с которой мы начали, наше поведение при использовании браузеров можно в целом разделить на три категории: чтение данных, ввод данных и взаимодействие с данными. Большие языковые модели (LLM) уже глубоко изменили эффективность и методы, с помощью которых мы читаем данные. Старая практика поиска пользователями веб-страниц по ключевым словам теперь кажется устаревшей и неэффективной.
Когда речь идет о эволюции поведения пользователей при поиске — будь то цель получения кратких ответов или перехода на веб-страницы — многие исследования уже проанализировали этот сдвиг.
Что касается паттернов поведения пользователей, то исследование 2024 года показало, что в США из каждых 1,000 запросов в Google только 374 завершались кликом на открытую веб-страницу. Другими словами, почти 63% были "нулевыми" поведениями. Пользователи привыкли получать информацию, такую как погода, курсы валют и карточки знаний, непосредственно со страницы результатов поиска.
Однако истинным триггером для массовой трансформации браузеров может стать слой взаимодействия с данными. В прошлом люди взаимодействовали с браузерами в основном, вводя ключевые слова — максимальный уровень понимания, который мог обрабатывать сам браузер. Теперь пользователи все чаще предпочитают использовать полный естественный язык для описания сложных задач, таких как:
“Найдите мне прямые рейсы из Нью-Йорка в Лос-Анджелес на определенный период.”
“Найди мне рейс из Нью-Йорка в Шанхай, а затем в Лос-Анджелес.”
Даже для людей такие задачи требуют много времени, чтобы посетить несколько веб-сайтов, собрать информацию и сравнить результаты. Но эти агентные задачи постепенно берутся на себя ИИ-агентами.
Это также соответствует траектории истории: автоматизация и интеллект. Люди стремятся освободить свои руки, и ИИ-агенты неизбежно будут глубоко интегрированы в браузеры. Будущие браузеры должны быть разработаны с учетом полной автоматизации, особенно учитывая:
Как сбалансировать читательский опыт для людей с интерпретируемостью для агентами ИИ.
Как обеспечить одностраничный веб-сайт для конечного пользователя и модели агента.
Только выполнив оба этих требования к дизайну, браузеры смогут стать стабильными носителями для ИИ-агентов, выполняющих задачи.
Далее мы сосредоточимся на пяти выдающихся проектах — Browser Use, Arc (The Browser Company), Perplexity, Brave и Donut. Эти проекты представляют собой будущие направления эволюции AI-браузеров, а также их потенциал для нативной интеграции в контексте Web3 и криптовалют.
С точки зрения психологии пользователей, опрос 2023 года показал, что 44% респондентов считают обычные органические результаты более надежными, чем выделенные фрагменты. Академические исследования также показали, что в случаях споров или отсутствия единой авторитетной правды пользователи предпочитают страницы результатов, содержащие ссылки от нескольких источников.
Другими словами, хотя часть пользователей не полностью доверяет резюмам, созданным ИИ, значительный процент поведения уже сместился к "нулевым кликам". Поэтому ИИ-браузеры все еще должны исследовать правильную парадигму взаимодействия — особенно в области чтения данных. Поскольку проблема галлюцинаций в больших моделях еще не решена полностью, многие пользователи все еще испытывают трудности с полным доверием к автоматически созданным резюмам контента. В этом отношении внедрение больших моделей в браузеры не требует разрушительной трансформации. Вместо этого это просто требует поэтапных улучшений в точности и управляемости — процесс, который уже underway.
Использование браузера
Это как раз и есть основная логика, стоящая за массовыми инвестициями, полученными Perplexity и Browser Use. В частности, Browser Use стал второй по многообещающей инновационной возможности начала 2025 года, обладая как определенностью, так и высоким потенциалом роста.

Использование браузера создало настоящий семантический слой, с основным вниманием на создание архитектуры семантического распознавания для следующего поколения браузеров.
Browser Use переосмысляет традиционное "DOM = древовидная структура для восприятия человеком" в "Семантический DOM = дерево инструкций для чтения LLM". Это позволяет агентам точно кликать, заполнять и загружать данные без полагания на "координаты пикселей". Вместо использования визуального OCR или основанного на координатах Selenium, этот подход идет по пути "структурированный текст → вызовы функций", что делает выполнение быстрее, экономит токены и снижает количество ошибок. TechCrunch описал это как "слой клея, который позволяет ИИ по-настоящему понимать веб-страницы". В марте Browser Use закрыл раунд посевного финансирования на сумму 17 миллионов долларов, делая ставку на эту основополагающую инновацию.
Вот как это работает:
После рендеринга HTML формируется стандартное дерево DOM. Затем браузер создает дерево доступности, которое предоставляет более богатые метки "ролей" и "состояний" для экранных читалок.
Каждый интерактивный элемент (кнопка, ввод и т.д.) абстрагирован в JSON-фрагмент с метаданными, такими как роль, видимость, координаты и выполняемые действия.
Вся страница переведена в плоский список семантических узлов, которые LLM может читать в одном системном запросе.
LLM выдает высокоуровневые инструкции (например, click(node_id="btn-Checkout")), которые затем воспроизводятся в реальном браузере.
Официальный блог описывает этот процесс как "превращение интерфейсов веб-сайтов в структурированный текст, который могут анализировать LLM".
Кроме того, если этот стандарт когда-либо будет принят W3C, это может значительно решить проблему ввода в браузере. Далее мы рассмотрим открытое письмо и примеры из компании The Browser Company, чтобы подробнее объяснить, почему их подход неудачен.
Арка
Компания Browser (родительская компания Arc) заявила в своем открытом письме, что браузер Arc перейдет в режим регулярного обслуживания, в то время как команда сосредоточит свои усилия на разработке DIA, браузера, полностью ориентированного на ИИ. В письме они также признали, что конкретный путь реализации DIA еще не определен. В то же время команда изложила несколько прогнозов о будущем рынка браузеров.
Основываясь на этих предсказаниях, мы также считаем, что если текущий ландшафт браузеров действительно должен быть нарушен, ключевым моментом является изменение выходной стороны взаимодействия.
Ниже приведены три предсказания о будущем рынка браузеров, которые поделилась команда Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
Во-первых, команда Arc считает, что веб-страницы больше не будут основным интерфейсом для взаимодействия. Признаем, это смелое и сложное утверждение, и это также основная причина, по которой мы остаемся скептически настроенными к размышлениям их основателя. На наш взгляд, эта точка зрения значительно недооценивает роль браузера и подчеркивает ключевую проблему, которую команда упустила, исследуя путь AI-браузера.
Большие модели отлично справляются с пониманием намерений, например, с пониманием инструкций вроде "помоги мне забронировать билет на самолет". Однако они остаются недостаточными, когда речь идет о плотности информации. Когда пользователю нужен что-то вроде панели управления, блокнота в стиле Bloomberg Terminal или визуального холста, как Figma, ничто не может превзойти точно настроенную веб-страницу с пиксельной точностью. Эргономика каждого продукта — графики, функция перетаскивания, горячие клавиши — не является поверхностным украшением, а необходимыми возможностями, которые сжимают когнитивные процессы. Эти возможности не могут быть воспроизведены простыми разговорными взаимодействиями. В качестве примера можно взять Gate.com: если пользователь хочет осуществить инвестиционное действие, полагаться исключительно на разговор с ИИ совершенно недостаточно, поскольку пользователи сильно зависят от структурированного ввода, точности и четкой презентации информации.
Дорожная карта команды Arc содержит фундаментальный недостаток: она не четко различает, что «взаимодействие» состоит из двух измерений — ввода и вывода. С точки зрения ввода, их мнение имеет определенную ценность в некоторых сценариях, поскольку ИИ действительно может повысить эффективность командных взаимодействий. Но с точки зрения вывода, их предположение явно несбалансировано, игнорируя основную роль браузера в представлении информации и персонализированных впечатлениях. Например, у Reddit есть своя уникальная компоновка и архитектура информации, в то время как AAVE имеет совершенно другой интерфейс и структуру. Будучи платформой, которая одновременно хранит высоко конфиденциальные данные и предоставляет разнообразные интерфейсы продуктов, браузер имеет ограниченную заменяемость со стороны ввода, в то время как его сложность и нестандартизированная природа со стороны вывода делают его еще более трудным для разрушения.
В отличие от этого, современные AI-браузеры в основном сосредоточены на слое «суммирования выходных данных»: суммирование страниц, извлечение информации, генерация выводов. Этого недостаточно, чтобы бросить фундаментальный вызов основным браузерам или поисковым системам, таким как Google — это всего лишь отнимает долю рынка у поисковых сводок.
Поэтому единственная технология, которая действительно могла бы подорвать 66% долю рынка Chrome, не предназначена для того, чтобы стать «следующим Chrome». Для достижения реального прорыва модель рендеринга браузеров должна быть принципиально перестроена, чтобы адаптироваться к потребностям взаимодействия эпохи ИИ-агентов, особенно в плане архитектуры дизайна входной стороны. Именно поэтому мы находим технический путь, выбранный Browser Use, гораздо более убедительным — он сосредоточен на структурных изменениях в базовом механизме браузеров. Как только любая система достигает «атомного» или «модульного» дизайна, программируемость и композируемость, вытекающие из этого, открывают прорывной потенциал. Именно в этом направлении сегодня движется Browser Use.
В заключение, работа AI-агентов по-прежнему сильно зависит от существования браузеров. Браузеры не только являются основными хранилищами сложных персонализированных данных, но и универсальными интерфейсами рендеринга для различных приложений, и, следовательно, будут продолжать служить основными воротами для взаимодействия в будущем. Поскольку AI-агенты становятся глубоко интегрированными в браузеры для выполнения фиксированных задач, они будут взаимодействовать с пользовательскими данными и конкретными приложениями в основном через входную сторону. По этой причине текущая модель рендеринга браузеров должна быть инновационной, чтобы добиться максимальной совместимости и адаптивности с AI-агентами — в конечном итоге позволяя им более эффективно захватывать приложения.
Сложность
Перплексити — это ИИ поисковая система, известная своей системой рекомендаций. Ее последняя оценка возросла до 14 миллиардов долларов, что почти в пять раз больше по сравнению с 3 миллиардами долларов в июне 2024 года. В настоящее время она обрабатывает более 400 миллионов поисковых запросов в месяц. В сентябре 2024 года она обработала около 250 миллионов запросов, что стало восьмикратным увеличением объема поисковых запросов пользователей по сравнению с прошлым годом, с более чем 30 миллионами активных пользователей в месяц.
Его основная функция заключается в том, чтобы в реальном времени суммировать страницы, что дает ему значительное преимущество в доступе к актуальной информации. Ранее в этом году Perplexity начала разработку собственного нативного браузера, Comet. Компания описывает Comet как браузер, который не только "отображает" веб-страницы, но и "думает" о них. Официально они утверждают, что он встроит движок ответов Perplexity глубоко в сам браузер, придерживаясь подхода "всей машины", напоминающего философию Стива Джобса: глубокая интеграция задач ИИ на базовом уровне браузера, а не просто создание плагинов для боковой панели.
С лаконичными ответами, подкреплёнными цитатами, Comet стремится заменить традиционные «десять синих ссылок» и конкурировать напрямую с Chrome.
Но Perplexity все еще необходимо решить две основные проблемы: высокие затраты на поиск и низкие прибыльные маржи от маргинальных пользователей. Хотя Perplexity в настоящее время лидирует в области ИИ-поиска, Google на своей конференции I/O 2025 объявила о масштабном интеллектуальном переосмыслении своих основных продуктов. Для браузеров Google запустила новый опыт вкладки браузера под названием AI Model, который интегрирует Обзор, Глубокое Исследование и будущие Агентные возможности. Вся инициатива называется "Проект Марино".
Google активно продвигает свою трансформацию в области ИИ, что означает, что поверхностное подражание функциям — таким как Обзор, Глубокие исследования или Агентность — вряд ли станет настоящей угрозой. То, что действительно могло бы установить новый порядок среди хаоса, это перестройка архитектуры браузера с нуля, глубокая интеграция больших языковых моделей (LLM) в ядро браузера и фундаментальное преобразование методов взаимодействия.
Браво
Brave является одним из самых ранних и успешных браузеров в криптоиндустрии. Построенный на архитектуре Chromium, он совместим с расширениями из Google Store. Brave привлекает пользователей моделью, основанной на конфиденциальности и заработке токенов через просмотр. Его путь разработки демонстрирует определенный потенциал роста. Однако, с точки зрения продукта, хотя конфиденциальность действительно важна, спрос по-прежнему сосредоточен в определенных группах пользователей. Для широкой публики осведомленность о конфиденциальности еще не стала основным фактором принятия решений. Поэтому попытки полагаться только на эту функцию для разрушения существующих гигантов вряд ли увенчаются успехом.
На данный момент Brave достиг 82,7 миллиона ежемесячных активных пользователей (MAU) и 35,6 миллиона ежедневно активных пользователей (DAU), занимая долю рынка около 1%–1,5%. Его пользовательская база демонстрирует стабильный рост: с 6 миллионов в июле 2019 года до 25 миллионов в январе 2021 года, до 57 миллионов в январе 2023 года, а к февралю 2025 года она превысила 82 миллиона. Его среднегодовой темп роста остается в двузначном числе.
Brave обрабатывает примерно 1,34 миллиарда поисковых запросов в месяц, что составляет около 0,3% от объема Google.
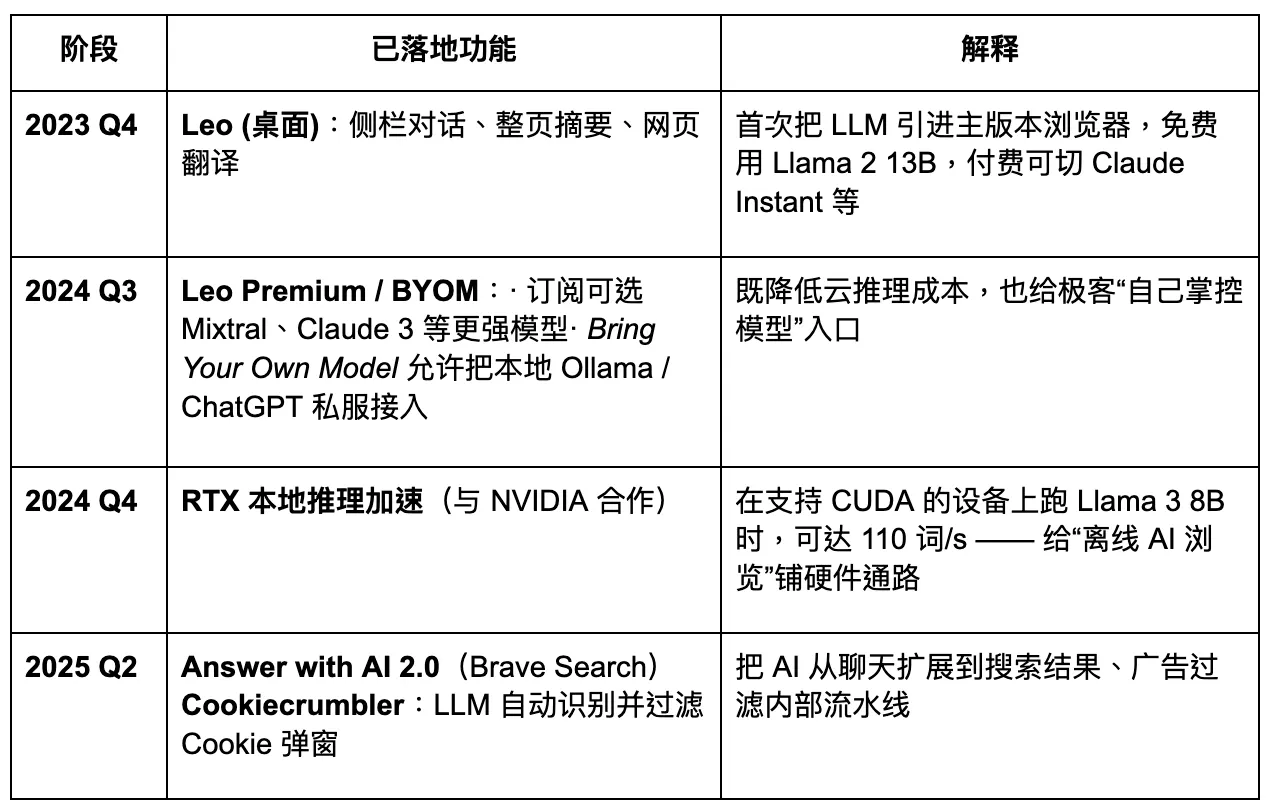
Brave планирует обновиться в браузер с акцентом на конфиденциальность и искусственный интеллект. Однако его ограниченный доступ к пользовательским данным снижает уровень возможной настройки для крупных моделей, что, в свою очередь, препятствует быстрой и точной итерации продукта. В эпоху нового браузера Agentic Brave может сохранить стабильную долю среди определенных групп пользователей, ориентированных на конфиденциальность, но ему будет трудно стать доминирующим игроком. Его AI-ассистент, Leo, функционирует больше как улучшение плагина — предлагает некоторые возможности по суммированию контента, но не имеет четкой стратегии для полного перехода к AI-агентам. Инновации в взаимодействии остаются недостаточными.
Пончик
Недавно криптоиндустрия также достигла успехов в области агентных браузеров. Проект начальной стадии Donut привлек 7 миллионов долларов в раунде предварительного финансирования, который возглавили Hongshan (Sequoia China), HackVC и Bitkraft Ventures. Проект все еще находится на ранней концептуальной стадии, с видением достижения «Поиск – Принятие решений – и Крипто-родное выполнение» как интегрированной способности.
Основное направление заключается в объединении путей автоматического выполнения, присущих криптовалютам. Как предсказал a16z, агенты могут заменить поисковые системы в качестве основного шлюза трафика в будущем. Предприниматели больше не будут конкурировать вокруг алгоритмов ранжирования Google, а будут бороться за трафик и конверсии, которые приходят от выполнения агентов. Индустрия уже назвала эту тенденцию «AEO» (Оптимизация Ответов / Агентных Действий), или даже дальше, «ATF» (Выполнение Агентных Задач) — где цель больше не заключается в оптимизации поисковых рангов, а в том, чтобы напрямую обслуживать интеллектуальные модели, которые могут выполнять задачи для пользователей, такие как размещение заказов, бронирование билетов или написание писем.
Для предпринимателей
Прежде всего, необходимо признать: браузер сам по себе остается крупнейшими не реконструированными «Gate» в мире интернета. С около 2,1 миллиарда пользователей настольных ПК и более 4,3 миллиарда мобильных пользователей по всему миру, он служит общим носителем для ввода данных, интерактивного поведения и хранения персонализированных отпечатков. Причина его устойчивости не в инерции, а в врожденной двойственной природе браузера: он является
Пригласить больше голосов
Как купить криптовалюту





Популярные криптовалюты



Глубокое исследование: Дорога вперед: Когда ФРС прекратит количественное ужесточение и что это может значить для Крипто-рынка?

Где купить Лабубу в Японии: лучшие магазины и интернет-магазины 2025 года
Рыночная капитализация Биткойна в 2025 году: анализ и тенденции для инвесторов

TerraClassicUSD (USTC) – Происхождение, Крах и Будет ли он снова привязан ?
Tron (TRX), BitTorrent (BTT) и Sun Token (SUN): Сможет ли криптоэкосистема Джастина Сана Лунить в 2025 году
Как купить ETF Биткоина напрямую в 2025 году

Ответ на ежедневный quiz Spur Protocol Сегодня 9 декабря 2025 года

Ответ ежедневной викторины Xenea 9 декабря 2025 года

Подробное руководство по изучению блокчейна Ethereum
Стандарт токенов BEP-2: полное руководство

Еженедельный крипто обзор Gate Ventures (8 декабря 2025)
