Compre cripto
Pagar com
USD
Compra e venda
HOT
Compre e venda cripto via transferência bancária (PIX), Apple Pay, cartões, Google Pay e muito mais
P2P
0 Fees
Taxa zero, mais de 400 opções de pagamento e compra e venda fácil de criptomoedas
Cartão da Gate
Cartão de pagamento com cripto permitindo transações globais descomplicadas.
Negociar
Tipo de negociação
Spot
Negocie criptomoedas livremente
Alpha
Pontos
Obtenha tokens promissores em uma negociação simplificada on-chain
Pré Venda
Negocie novos tokens antes que eles sejam oficialmente listados
Margem
Amplie seu lucro com alavancagem
Conversão e block trading
0 Fees
Negocie qualquer tamanho sem taxas e sem slippage
Tokens Alavancados
Exposição para posições alavancadas de forma simples
Futuros
Futuros
Pontos
Centenas de contratos liquidados em USDT ou BTC
Opções
HOT
Negocie opções vanilla no estilo europeu
Conta unificada
Maximize sua eficiência de capital
Negociação demo
Início em Futuros
Prepare-se para sua negociação de futuros
Eventos de futuros
Participe de eventos para ganhar recompensas generosas
Negociação demo
Use fundos virtuais para experimentar negociações sem riscos
Earn
Lançar
CandyDrop
Colete candies para ganhar airdrops
Launchpool
Staking rápido, ganhe novos tokens em potencial
HODLer Airdrop
Possua GT em hold e ganhe airdrops massivos de graça
Launchpad
Chegue cedo para o próximo grande projeto de token
Pontos Alpha
New
Negocie ativos on-chain e aproveite as recompensas em airdrops!
Pontos de futuros
New
Ganhe pontos de futuros e colete recompensas em airdrop
Investimento
Simple Earn
Ganhe juros com tokens ociosos
Autoinvestimento
Invista automaticamente regularmente
Investimento duplo
Compre na baixa e venda na alta para lucrar com as flutuações de preços
Soft Staking
Ganhe recompensas com stakings flexíveis
Empréstimo de criptomoedas
0 Fees
Penhore uma criptomoeda para pegar outra emprestado
Centro de empréstimos
Centro de empréstimos integrado
Centro de riqueza VIP
New
A gestão personalizada de patrimônio fortalece o crescimento de seus ativos
Gestão privada de patrimônio
Gestão de ativos personalizada para aumentar seus ativos digitais
Fundo Quantitativo
A melhor equipe de gerenciamento de ativos ajuda você a lucrar sem problemas
Apostar
Faça staking de criptomoedas para ganhar em produtos PoS
Staking de BTC
HOT
Faça stake de BTC e ganhe 10% de APR
Cunhagem de GUSD
New
Use USDT/USDC para cunhar GUSD por rendimentos a nível de tesouro
Mais


- TendênciasVer projetos
1.6K Popularidade
36.1K Popularidade
26.5K Popularidade
5.7K Popularidade
201.1K Popularidade
- Em alta na Gate FunVer projetos
- Cap. de M.:$687.9KHolders:10603
- Cap. de M.:$115.9KHolders:3265
- Cap. de M.:$776.2KHolders:7161
- Cap. de M.:$715.3KHolders:131
- Cap. de M.:$79.1KHolders:180
- Marcar
A Interrupção da AWS Derruba Aplicativos Populares Offline enquanto a Resiliência do Web3 Recebe Nova Atenção
Uma interrupção generalizada de serviço em 20 de outubro derrubou temporariamente várias plataformas importantes após uma falha significativa na infraestrutura da Amazon Web Services (AWS).
Aplicativos populares como Snapchat, Fortnite e Alexa tornaram-se inacessíveis por horas, expondo a medida em que grande parte da internet depende de alguns grandes provedores de nuvem.
A falha da AWS expôs os pontos fracos do Web2 e como os designs do Web3 acrescentam resiliência
O evento destacou a medida em que a internet global depende de um pequeno número de provedores de nuvem centralizados. Também renovou as discussões em torno de modelos alternativos, particularmente sistemas descentralizados promovidos sob o Web3, que visam reduzir a dependência de pontos únicos de falha.
Relatórios de problemas de conectividade começaram por volta das 3:11 a.m. ET, quando usuários em toda a Estados Unidos e partes da Europa notaram que vários aplicativos e sites tinham parado de funcionar.
A Amazon confirmou em breve que a sua região US-East-1, um dos seus centros de cloud mais críticos, estava a experimentar “taxas de erro elevadas” que afetavam serviços como API Gateway, Lambda e CloudFront.
Dentro de uma hora, as plataformas dependentes da hospedagem AWS, desde entretenimento a serviços empresariais, começaram a ficar fora do ar. A interrupção da AWS afetou operações essenciais em várias indústrias, incluindo e-commerce, jogos, comunicações e serviços financeiros.
Durante várias horas, os utilizadores não conseguiram aceder a funções de casa inteligente, fazer login em plataformas sociais ou completar transações online. As empresas que operam em ambientes baseados na AWS também enfrentaram paragens nos seus sistemas internos, interrompendo as operações diárias e os serviços ao cliente.
Causa Raiz da Interrupção da AWS: O que a Amazon Confirmou
Por volta do meio-dia, engenheiros da Amazon identificaram uma má configuração em uma atualização de rede como a causa raiz. O problema interrompeu a forma como os sistemas internos gerenciavam o roteamento e as operações de DNS, impedindo que os pedidos chegassem aos seus destinos. As equipes da AWS reverteram a atualização defeituosa, restaurando gradualmente o serviço completo até o final da tarde.
A Amazon enfatizou que nenhum dado de cliente foi perdido ou comprometido, e que o problema foi contido a uma única região. Ainda assim, o tempo de inatividade destacou como até mesmo um problema localizado pode se espalhar pelo ecossistema global da web quando tantos serviços digitais dependem de uma única camada de infraestrutura.
Quais websites e aplicações ficaram fora do ar e por que o impacto se espalhou
Entre as interrupções mais visíveis estavam os próprios produtos de consumo da Amazon, incluindo Alexa e Ring. Os usuários relataram que os alto-falantes inteligentes falharam em processar comandos de voz, enquanto as câmaras e campainhas conectadas pararam de responder aos controles do aplicativo móvel.
No setor de entretenimento e jogos, títulos como Fortnite, Roblox e PUBG enfrentaram erros de login e falhas de matchmaking. Muitos desses jogos dependem da AWS para sincronização multiplayer em tempo real e entrega de conteúdo baseada na nuvem.
As plataformas sociais e de comunicação também foram afetadas. Os utilizadores do Snapchat encontraram dificuldades em enviar mensagens e carregar feeds durante o pico da interrupção. Além disso, o Slack, o Zoom e várias ferramentas de negócios construídas na infraestrutura da AWS relataram problemas de conectividade intermitentes que afetaram as operações de trabalho remoto.
Algumas aplicações financeiras e processadores de pagamento que utilizam os serviços de computação e armazenamento da AWS estiveram brevemente offline, causando falhas nas transações e atrasos nos pagamentos digitais. Websites de retalho e comércio eletrónico construídos na AWS também experimentaram paragens temporárias ou tempos de resposta mais lentos.
Por que a centralização ampliou o raio de explosão na web
O alcance do incidente mostrou quão profundamente a AWS está integrada nas funções diárias da internet. Uma única interrupção regional se estendeu além de sua geografia imediata, interrompendo sistemas de consumo, entretenimento e empresariais em múltiplos fusos horários.
Esta falha também destacou como as dependências de serviço, como APIs e integrações de terceiros, podem espalhar os efeitos de uma interrupção muito além da sua origem técnica.
De acordo com o relatório pós-incidente da Amazon, a interrupção resultou de uma alteração de configuração defeituosa implementada durante uma atualização de manutenção rotineira. A alteração alterou inadvertidamente a forma como os resolvedores de DNS internos direcionavam o tráfego, fazendo com que os sistemas parassem de processar pedidos.
Uma vez detectado, os engenheiros da Amazon iniciaram um retrocesso da atualização e redirecionaram o tráfego através de rotas de backup. A restauração começou região por região, com o status da interrupção do AWS mostrando uma recuperação gradual até ao final da tarde.
A empresa desde então introduziu salvaguardas adicionais para prevenir problemas semelhantes, incluindo controles de gestão de mudanças mais rigorosos e novos procedimentos automáticos de reversão para atualizações de rede.
Centralização vs. Descentralização: Uma Lição Mais Ampla
Este incidente reabriu o debate de longa data sobre os modelos Web2 vs Web3. No atual framework Web2, um punhado de corporações, incluindo Amazon, Google e Microsoft, alimenta a maioria do tráfego global da web através de servidores centralizados.
Esta estrutura oferece conveniência, eficiência de custos e escalabilidade, mas também concentra controle e vulnerabilidade. Quando um desses fornecedores sofre uma interrupção, os efeitos são imediatos e generalizados.
Analistas da indústria têm alertado há muito tempo que essa concentração de poder de hospedagem e gestão de dados cria um único ponto de falha para a internet. Embora a computação em nuvem ofereça escalabilidade e eficiência de custos, também centraliza o risco. Quando os sistemas de um fornecedor chave falham, os serviços dependentes têm pouco espaço para se recuperar de forma independente.
A queda da AWS também expôs outro desafio, que são as dependências interconectadas. Muitos serviços operam em arquiteturas em camadas onde a API ou o banco de dados de um provedor suporta várias plataformas a jusante. Esta estrutura amplifica o impacto de qualquer interrupção técnica.
Os especialistas sugerem que, embora a redundância e o despliegue em múltiplas regiões possam reduzir o risco, o problema fundamental reside na forma como a web está estruturada. Modelos de cloud centralizados consolidam o controlo e a capacidade em algumas redes, tornando as falhas mais impactantes e mais difíceis de isolar.
Porque os especialistas veem o Web3 como uma alternativa viável
O Web3 pretende mudar isso, distribuindo o poder computacional e o armazenamento de dados por redes descentralizadas de nós independentes. Ao contrário dos sistemas de nuvem centralizados, as arquiteturas descentralizadas não dependem do tempo de atividade de um único fornecedor. Se um nó ou cluster falhar, outros podem continuar a operar sem interrupção.
Para desenvolvedores e empresas, esta abordagem pode significar maior resiliência, transparência e segurança, embora aumentar a infraestrutura descentralizada para igualar a velocidade e a capacidade da Web2 continue a ser um desafio.
Projetos como Filecoin, Arweave e Akash Network são exemplos de soluções de infraestrutura descentralizada que visam fornecer armazenamento e poder de computação por meio de redes abertas. Esses sistemas utilizam mecanismos de incentivo para manter o tempo de atividade e a disponibilidade de dados sem supervisão centralizada.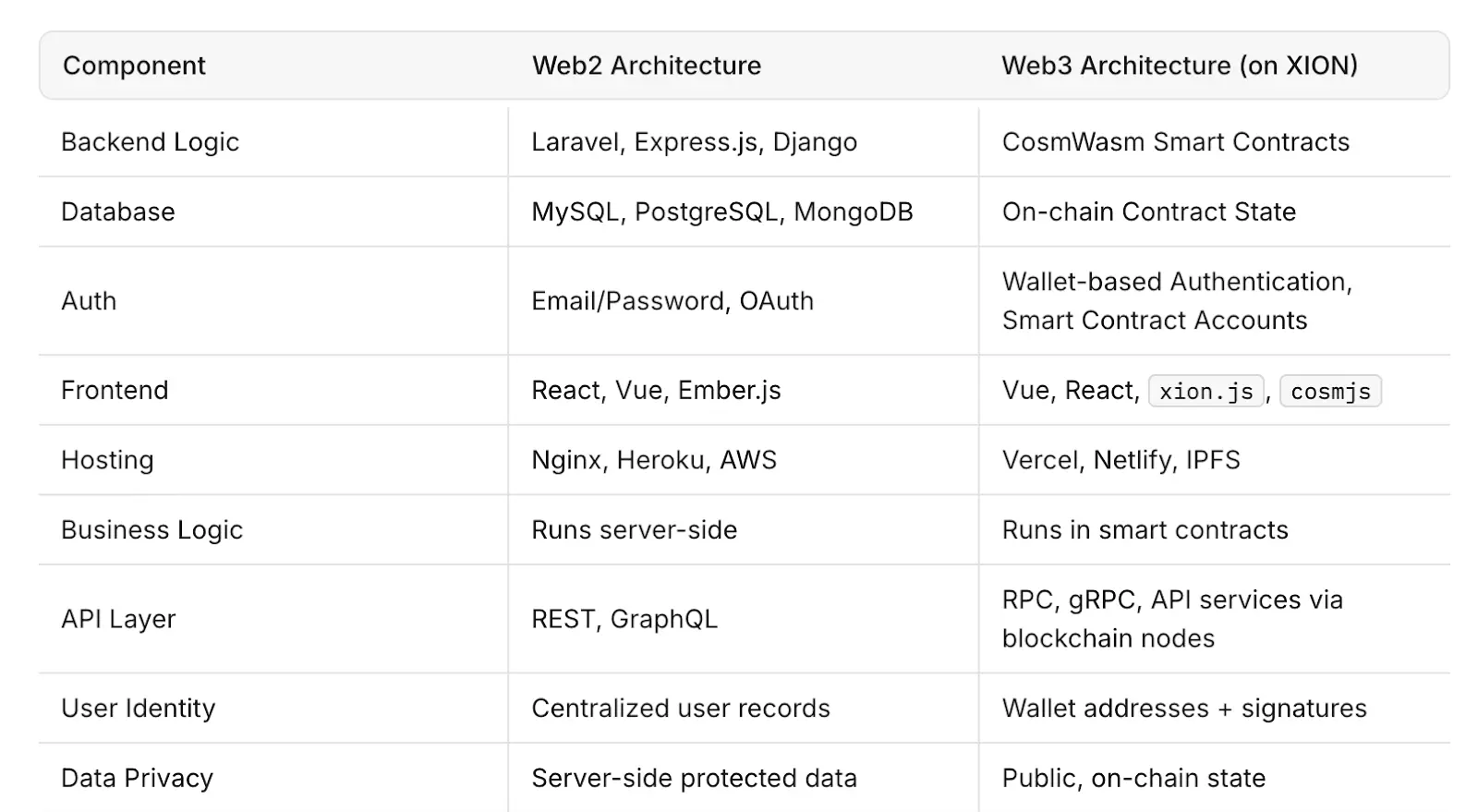
No entanto, a infraestrutura Web3 ainda está nas fases iniciais de adoção. Enfrenta desafios relacionados à escalabilidade, velocidade e experiência do usuário em comparação com os sistemas Web2 estabelecidos. Mesmo assim, o incidente da AWS demonstrou o valor de ter modelos alternativos que podem melhorar a resiliência da internet.
Lições Aprendidas e o Caminho à Frente
A interrupção destacou o fato de que a resiliência na economia digital requer redundância e diversificação. As empresas que distribuíram suas cargas de trabalho por várias regiões ou provedores de nuvem experimentaram menos tempo de inatividade e tempos de recuperação mais rápidos. Outras, totalmente dependentes da AWS, ficaram esperando até que a Amazon restaurasse seus sistemas.
Revelou também como as cadeias de dependência amplificam as interrupções. Muitas aplicações não alojavam os seus serviços principais na AWS, mas ainda assim ficaram offline porque usavam APIs, análises ou ferramentas de autenticação alojadas na AWS. Um único ponto de falha na cadeia desencadeou interrupções em plataformas não relacionadas.
O evento pode levar várias organizações a repensar suas estratégias de infraestrutura, explorando modelos híbridos que combinam sistemas de nuvem tradicionais com armazenamento e computação descentralizados.
Desenvolvedores e empresas podem também ver a descentralização não apenas como uma tendência, mas como uma salvaguarda prática contra paragens em grande escala.
A Amazon afirmou que novos mecanismos de monitorização e controles internos de reversão estão agora ativos em todas as regiões. No entanto, os especialistas observam que as correções técnicas por si só não podem abordar totalmente os riscos inerentes à centralização.
À medida que a dependência digital global se aprofunda, a resiliência pode depender de quão eficazmente a computação em nuvem e as tecnologias descentralizadas podem coexistir.
FAQs
O que causou a interrupção da AWS?
A Amazon disse que um erro de configuração durante uma atualização de rotina na sua região US-East-1 interrompeu o roteamento de rede e as funções DNS. O problema foi contido em poucas horas e nenhuma violação de dados ou de segurança foi relatada.
Quais websites e apps foram afetados?
Plataformas como Alexa, Ring, Snapchat, Fortnite e Roblox ficaram offline. Ferramentas de negócios e de pagamento que utilizam a infraestrutura da AWS também enfrentaram interrupções temporárias.
Por que a centralização torna a internet vulnerável?
Sistemas centralizados dependem de alguns provedores principais, portanto uma falha pode impactar milhões de usuários. Redes descentralizadas reduzem esse risco ao espalhar operações por nós independentes.
Conclusão
O incidente de outubro de 2025 revelou os pontos fortes e fracos da infraestrutura cloud moderna. A AWS conseguiu restaurar rapidamente as operações, mas os efeitos globais mostraram que a fiabilidade tem limites quando o controlo está nas mãos de poucos fornecedores.
Para empresas e desenvolvedores, a lição aqui é que a diversificação e a descentralização já não são opcionais. Infraestruturas híbridas que combinam a eficiência centralizada com a resiliência descentralizada podem definir a próxima era da fiabilidade da internet.