### 前言本書の最後の部分では、シリーズの最初の記事「マルチファクター戦略で強力な暗号資産ポートフォリオを構築する」-理論的基礎-、これは2番目の記事-データの前処理です。データは、因子データの計算の前/後、および単一因子の有効性が検定される前に処理する必要があります。 特定のデータの前処理には、重複値、外れ値/欠損値/極値、正規化、およびデータ頻度の処理が含まれます。### I. 重複する値#### **データ関連の定義:*** キー: 一意のインデックスを示します。 例えば。 すべてのトークンのすべての日付を含むデータの場合、キーは「token\_id/contract\_address - date」です。* 値: キーによってインデックス付けされたオブジェクトは「値」と呼ばれます。重複値の診断は、データがどのように「あるべきか」を理解することから始まります。 通常、データは次の形式になります。1. 時系列データ。 鍵となるのは「時間」です。 例:1つのトークンの5年間の価格データ2.断面データ。 鍵となるのは「個」です。 eg.2023.11.01 その日の暗号市場のすべてのトークンの価格データ3.パネル。 鍵となるのは「個と時間」の組み合わせです。 例:2019.01.01 - 2023.11.01までの4年間のすべてのトークンの価格データ。原則:データのインデックス(キー)を決定したら、どのレベルでデータに重複する値がないかを知ることができます。#### **チェック方法:**1. PDです。DataFrame.duplicated(subset = [key1, key2, ...]) 1.重複する値の数を確認します:pd。 DataFrame.duplicated(subset=[key1, key2, ...]) を使用します。 sum()を呼び出します 2. 重複するサンプルを表示するサンプル: df[df.duplicated(subset=[...])]。 sample() を呼び出し、df.loc を使用して、インデックスに対応するすべての重複サンプルを選択します2. pd.merge(df1、df2、on = [key1、key2、...]、indicator=True、validate = '1:1') 1.水平マージ関数にインジケーターパラメーターを追加すると、_mergeフィールドが生成され、dfm['_merge'].value_counts()を使用して、マージ後のさまざまなソースからのサンプル数を確認できます 2. validate パラメーターを追加して、マージされたデータセットのインデックスが期待どおりであるかどうかを確認します (1 対 1、1 対多、または多対多の場合、最後のケースは実際には検証されません)。 結果が期待どおりでない場合は、エラーが報告され、実行が中止されます。### **2. 外れ値/欠損値/極値**#### **外れ値の一般的な原因:**1. **極端なケース**。 例えば、トークン価格が0.000001$や市場価値が50万ドルしかないトークンの場合、ちょっとしたお釣りで何十倍もの還元率になります。2. データ特性。 例えば、2020年1月1日からトークン価格データをダウンロードした場合、前日の終値がないため、2020年1月1日のリターンデータを計算することは当然不可能です。3. **データエラー**。 データプロバイダーは、トークンあたり12元をトークンあたり1.2元として記録するなど、必然的に間違いを犯します。#### **外れ値と欠損値の処理の原則:**1. 削除します。 合理的に修正または修正できない外れ値は、削除の対象と見なすことができます。2.交換します。 これは、ウィンゾライジングや対数(一般的には使用されません)などの極値を処理するためによく使用されます。3.充填。 欠損値については、合理的な方法で埋めることも検討できます、一般的な方法には、平均値(または移動平均)、補間、0の記入が含まれます df.fillna(0)、前方df.fillna('ffill')/後方の記入 df.fillna('bfill')など、パディングが依存する仮定が正しいかどうかを検討します。機械学習は、バックフィルや先読みバイアスのリスクに注意して使用する必要があります#### **極値の処理:**1.パーセンタイル法。最小から最大の順に並べることで、最小比率と最大比率を超えるデータを重要なデータに置き換えます。 履歴データが豊富なデータの場合、この方法は比較的大雑把で適用できず、一定の割合のデータを強制的に削除すると、一定の割合の損失が発生する場合があります。2.3σ/三重標準偏差法標準偏差σfactorは、因子のデータ分布の分散の程度、つまりボラティリティを反映します。 μ±3×σの範囲は、データセット内の外れ値を特定して置き換えるために使用され、データの約99.73%が範囲に収まりました。 この方法の前提は、因子データが正規分布、つまりX∼N(μ,σ2)に従わなければならないということです。ここで、μ=∑ⁿi₌₁⋅Xi/N, σ²=∑ⁿi₌₁=(xi-μ)²/nの場合、因子値の妥当な範囲は [μ−3×σ, μ+3×σ] です。データ範囲のすべての因子に対して、次の調整を行います。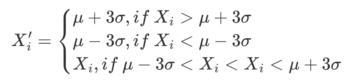 この方法のデメリットは、株価やトークン価格など、定量的な分野で一般的に使用されるデータは、正規分布の仮定に合致しないスパイクや太いテール分布を示すことが多く、この場合、3σ法を用いることで大量のデータが外れ値として誤って識別されてしまうことです。3.绝对值差中位数法(Median Absolute Deviation, MAD)この方法は中央値と絶対値のバイアスに基づいているため、処理されたデータは極端または外れ値の影響を受けにくくなります。 平均と標準偏差に基づく方法よりも頑健です。絶対偏差の中央値 MAD=中央値 ( ∑ⁿi₌₁(Xi - Xmedian) )因子値の妥当な範囲は [Xmedian-n×MAD, Xmedian + n×MAD] です。 データ範囲のすべての因子に対して、次の調整を行います。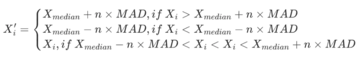 # 因子データの極値の場合の扱いclass Extreme(object):デフ__init__(秒、ini_data):s.ini_data = ini_datadef three_sigma(s,n=3):平均 = .ini_data.mean()標準 = .ini_データ.std()低 = 平均 - n*標準高値 = 平均 + n*標準偏差np.clip(s.ini_data,low,high)を返します。デフマッド(s、n = 3):中央値 = s.ini_data.median()mad_median = abs(s.ini_data - 中央値).median()高値 = 中央値 + n * mad_median低 = 中央値 - n * mad_mediannp.clip(s.ini_data, low, high)を返します。Def 分位数(s,l = 0.025, h = 0.975):低 = s.ini_data.quantile(l)高値 = s.ini_データ.分位数(h)np.clip(s.ini_data, low, high)を返します。### **III. 標準化**1. Zスコアの標準化* 必要条件: X N (μ, σ)* 標準偏差を使用しているため、この方法はデータの外れ値の影響を受けやすいですx'i=(x−μ)/σ=(X−mean(X))))/std(X)2.最小-最大スケーリング各因子を(0,1)区間のデータに変換すると、異なるサイズまたは範囲のデータの比較が可能になりますが、データ内の分布は変更されず、合計は1になりません。*最大最小値を考慮するため外れ値に敏感**統合ディメンション**: 異なるディメンションのデータを比較するのに役立ちます。x'i=(xi−min(x))/max(x)-min(x)3.排序百分位(ランクスケーリング)データ特徴をランキングに変換し、それらのランキングを 0 から 1 までのスコア (通常はデータセット内のパーセンタイル) に変換します。 \*ランキングは外れ値の影響を受けないため、この方法は外れ値の影響を受けません。 **※データ内のポイント間の絶対距離を維持する代わりに、相対ランキングに変換します。ノルムランキ=(Ranksi−min(Ranksi))/max(Ranks)−min(Ranks)=Ranksi/Nmin(Rankₓ)=0 で、N は区間内のデータ点の総数です。# 因子データの正規化class Scale(object):def __init__(s, ini_data,date):s.ini_data = ini_datas.date = 日付デフzscore(秒):平均 = .ini_data.mean()標準 = .ini_データ.std()戻り値 s.ini_data.sub(mean).div(std)def maxmin(s):最小値 = .ini_データ.min()最大 = s.ini_data.max()戻り値 s.ini_data.sub(min).div(max - min)デフnormRank(秒): #指定された列をランク付けする、method='min'は、同じ値が平均ランクではなく、同じランクを持つことを意味しますランク = s.ini_data.rank(メソッド='min')ランク.div(ランク.max())を返します### **第四に、データ周波数**取得されたデータは、分析に必要な頻度ほど頻繁ではない場合があります。 たとえば、分析レベルが月次で、生データの頻度が日次の場合、「ダウンサンプリング」、つまり集計データが月次である必要があります。#### **ダウンサンプリング**これは、日次データを月次データに集約するなど、コレクション内のデータをデータ行に集約することを指します。 この場合、各集計指標の特性を考慮する必要があり、通常の操作は次のとおりです。*最初の値/最後の値*平均/中央値*標準偏差#### **アップサンプル**これは、月次分析用の年次データなど、データの行を複数のデータ行に分割することを指します。 これは通常、単純な繰り返しであり、毎月比例して年間データを集計する必要がある場合があります。Falcon(/)は、ユーザーが暗号資産を「選択」、「購入」、「管理」、「販売」するのに役立つ多要素モデルに基づく新世代のWeb3投資インフラストラクチャです。 Falconは、2022年6月にLucidaによってインキュベートされました。より多くのコンテンツをご覧ください
多要素戦略による強力な暗号資産ポートフォリオの構築:データの前処理
前言
本書の最後の部分では、シリーズの最初の記事「マルチファクター戦略で強力な暗号資産ポートフォリオを構築する」-理論的基礎-、これは2番目の記事-データの前処理です。
データは、因子データの計算の前/後、および単一因子の有効性が検定される前に処理する必要があります。 特定のデータの前処理には、重複値、外れ値/欠損値/極値、正規化、およびデータ頻度の処理が含まれます。
I. 重複する値
データ関連の定義:
重複値の診断は、データがどのように「あるべきか」を理解することから始まります。 通常、データは次の形式になります。
原則:データのインデックス(キー)を決定したら、どのレベルでデータに重複する値がないかを知ることができます。
チェック方法:
PDです。DataFrame.duplicated(subset = [key1, key2, …])
1.重複する値の数を確認します:pd。 DataFrame.duplicated(subset=[key1, key2, …]) を使用します。 sum()を呼び出します 2. 重複するサンプルを表示するサンプル: df[df.duplicated(subset=[…])]。 sample() を呼び出し、df.loc を使用して、インデックスに対応するすべての重複サンプルを選択します
pd.merge(df1、df2、on = [key1、key2、…]、indicator=True、validate = ‘1:1’)
1.水平マージ関数にインジケーターパラメーターを追加すると、_mergeフィールドが生成され、dfm[‘_merge’].value_counts()を使用して、マージ後のさまざまなソースからのサンプル数を確認できます 2. validate パラメーターを追加して、マージされたデータセットのインデックスが期待どおりであるかどうかを確認します (1 対 1、1 対多、または多対多の場合、最後のケースは実際には検証されません)。 結果が期待どおりでない場合は、エラーが報告され、実行が中止されます。
2. 外れ値/欠損値/極値
外れ値の一般的な原因:
外れ値と欠損値の処理の原則:
機械学習は、バックフィルや先読みバイアスのリスクに注意して使用する必要があります
極値の処理:
1.パーセンタイル法。
最小から最大の順に並べることで、最小比率と最大比率を超えるデータを重要なデータに置き換えます。 履歴データが豊富なデータの場合、この方法は比較的大雑把で適用できず、一定の割合のデータを強制的に削除すると、一定の割合の損失が発生する場合があります。
2.3σ/三重標準偏差法
標準偏差σfactorは、因子のデータ分布の分散の程度、つまりボラティリティを反映します。 μ±3×σの範囲は、データセット内の外れ値を特定して置き換えるために使用され、データの約99.73%が範囲に収まりました。 この方法の前提は、因子データが正規分布、つまりX∼N(μ,σ2)に従わなければならないということです。
ここで、μ=∑ⁿi₌₁⋅Xi/N, σ²=∑ⁿi₌₁=(xi-μ)²/nの場合、因子値の妥当な範囲は [μ−3×σ, μ+3×σ] です。
データ範囲のすべての因子に対して、次の調整を行います。
この方法のデメリットは、株価やトークン価格など、定量的な分野で一般的に使用されるデータは、正規分布の仮定に合致しないスパイクや太いテール分布を示すことが多く、この場合、3σ法を用いることで大量のデータが外れ値として誤って識別されてしまうことです。
3.绝对值差中位数法(Median Absolute Deviation, MAD)
この方法は中央値と絶対値のバイアスに基づいているため、処理されたデータは極端または外れ値の影響を受けにくくなります。 平均と標準偏差に基づく方法よりも頑健です。
絶対偏差の中央値 MAD=中央値 ( ∑ⁿi₌₁(Xi - Xmedian) )
因子値の妥当な範囲は [Xmedian-n×MAD, Xmedian + n×MAD] です。 データ範囲のすべての因子に対して、次の調整を行います。
因子データの極値の場合の扱い
class Extreme(object): デフ__init__(秒、ini_data): s.ini_data = ini_data
def three_sigma(s,n=3): 平均 = .ini_data.mean() 標準 = .ini_データ.std() 低 = 平均 - n標準 高値 = 平均 + n標準偏差 np.clip(s.ini_data,low,high)を返します。
デフマッド(s、n = 3): 中央値 = s.ini_data.median() mad_median = abs(s.ini_data - 中央値).median() 高値 = 中央値 + n * mad_median 低 = 中央値 - n * mad_median np.clip(s.ini_data, low, high)を返します。
Def 分位数(s,l = 0.025, h = 0.975): 低 = s.ini_data.quantile(l) 高値 = s.ini_データ.分位数(h) np.clip(s.ini_data, low, high)を返します。
III. 標準化
x’i=(x−μ)/σ=(X−mean(X))))/std(X)2.最小-最大スケーリング
各因子を(0,1)区間のデータに変換すると、異なるサイズまたは範囲のデータの比較が可能になりますが、データ内の分布は変更されず、合計は1になりません。
*最大最小値を考慮するため外れ値に敏感 統合ディメンション: 異なるディメンションのデータを比較するのに役立ちます。
x’i=(xi−min(x))/max(x)-min(x)3.排序百分位(ランクスケーリング)
データ特徴をランキングに変換し、それらのランキングを 0 から 1 までのスコア (通常はデータセット内のパーセンタイル) に変換します。 *
ランキングは外れ値の影響を受けないため、この方法は外れ値の影響を受けません。 ** ※データ内のポイント間の絶対距離を維持する代わりに、相対ランキングに変換します。
ノルムランキ=(Ranksi−min(Ranksi))/max(Ranks)−min(Ranks)=Ranksi/N
min(Rankₓ)=0 で、N は区間内のデータ点の総数です。
因子データの正規化
class Scale(object): def init(s, ini_data,date): s.ini_data = ini_data s.date = 日付
デフzscore(秒): 平均 = .ini_data.mean() 標準 = .ini_データ.std() 戻り値 s.ini_data.sub(mean).div(std)
def maxmin(s): 最小値 = .ini_データ.min() 最大 = s.ini_data.max() 戻り値 s.ini_data.sub(min).div(max - min)
デフnormRank(秒): #指定された列をランク付けする、method='min’は、同じ値が平均ランクではなく、同じランクを持つことを意味します ランク = s.ini_data.rank(メソッド=‘min’) ランク.div(ランク.max())を返します
第四に、データ周波数
取得されたデータは、分析に必要な頻度ほど頻繁ではない場合があります。 たとえば、分析レベルが月次で、生データの頻度が日次の場合、「ダウンサンプリング」、つまり集計データが月次である必要があります。
ダウンサンプリング
これは、日次データを月次データに集約するなど、コレクション内のデータをデータ行に集約することを指します。 この場合、各集計指標の特性を考慮する必要があり、通常の操作は次のとおりです。
*最初の値/最後の値 *平均/中央値 *標準偏差
アップサンプル
これは、月次分析用の年次データなど、データの行を複数のデータ行に分割することを指します。 これは通常、単純な繰り返しであり、毎月比例して年間データを集計する必要がある場合があります。
Falcon(/)は、ユーザーが暗号資産を「選択」、「購入」、「管理」、「販売」するのに役立つ多要素モデルに基づく新世代のWeb3投資インフラストラクチャです。 Falconは、2022年6月にLucidaによってインキュベートされました。
より多くのコンテンツをご覧ください