Gate Ventures Research Insights: Третя війна браузерів: Бойова вступ до ери AI агентів


TL;DR
Третя війна браузерів тихо розгортається. Заглядаючи в історію, від Netscape і Internet Explorer від Microsoft у 1990-х до відкритого коду Firefox та Chrome від Google, війна браузерів завжди була концентрованою маніфестацією контролю платформи та технологічних парадигм. Chrome закріпив свою домінуючу позицію завдяки швидкості оновлення та інтегрованій екосистемі, тоді як Google, завдяки своїй дуополії в пошуку та браузерах, сформував закритий цикл доступу до інформації.
Але сьогодні цей ландшафт трясеться. Поява великих мовних моделей (LLMs) дозволяє дедалі більшій кількості користувачів виконувати завдання без необхідності натискати на сторінку результатів пошуку, тоді як традиційні кліки на веб-сторінках знижуються. Тим часом чутки про намір Apple замінити пошукову систему за замовчуванням у Safari ще більше загрожують прибутковій базі Alphabet (материнської компанії Google), і ринок починає висловлювати занепокоєння щодо "ортодоксії пошуку."
Сам браузер також стикається з перебудовою своєї ролі. Він вже не просто інструмент для відображення веб-сторінок, а також контейнер для багатьох можливостей, включаючи введення даних, поведінку користувача та приватну ідентичність. Хоча агенти штучного інтелекту потужні, вони все ще покладаються на довірчу межу браузера та функціональний пісочницю для виконання складних взаємодій на сторінках, доступу до локальних даних про ідентичність та контролю елементів веб-сторінок. Браузери еволюціонують від людських інтерфейсів до платформ системних викликів для агентів.
У цій статті ми досліджуємо, чи браузери все ще необхідні. Ми вважаємо, що те, що насправді може порушити поточний ринок браузерів, це не інший "кращий Chrome", а нова структура взаємодії: не лише відображення інформації, а й виклик завдань. Майбутні браузери повинні бути спроектовані для AI-агентів—здатних не лише читати, а й писати та виконувати. Проекти, такі як Browser Use, намагаються семантизувати структуру сторінки, перетворюючи візуальні інтерфейси на структурований текст, який можна викликати за допомогою LLM, відображаючи сторінки на команди та значно знижуючи витрати на взаємодію.
Великі проекти вже тестують води: Perplexity створює рідний браузер Comet, який замінює традиційні результати пошуку на ШІ; Brave поєднує захист конфіденційності з локальним міркуванням, використовуючи LLM для покращення можливостей пошуку та блокування; а криптоорієнтовані проекти, такі як Donut, націлені на нові точки входу для взаємодії ШІ з активами на блокчейні. Загальною рисою цих проектів є їхня спроба переформатувати вхідний рівень браузера, а не прикрашати його вихідний рівень.
Для підприємців можливості лежать у трикутнику вхідних даних, структури та доступу до агентів. Як інтерфейс для майбутнього світу на основі агентів, браузер означає, що той, хто може надати структуровані, викликаємі та надійні "можливості", стане складовою частиною платформи наступного покоління. Від SEO до AEO (Оптимізація Агента), від трафіку сторінок до виклику ланцюгів завдань, форма продукту та дизайн мислення зазнають змін. Третя війна браузерів відбувається за "вхідні дані", а не за "відображення". Перемога більше не визначається тим, хто захоплює увагу користувача, а тим, хто заробляє довіру агента та отримує доступ.
Коротка історія розвитку браузерів
На початку 1990-х, до того як інтернет став частиною повсякденного життя, Netscape Navigator увірвався на сцену, як вітрильник, що відкрив двері до цифрового світу для мільйонів користувачів. Хоча це не був перший браузер, він став першим, хто дійсно досяг мас і сформував інтернет-досвід. Вперше люди могли переглядати веб-сторінки з такою легкістю через графічний інтерфейс, ніби весь світ раптово став доступним.
Однак слава, як правило, недовговічна. Microsoft швидко усвідомила важливість браузерів і вирішила примусово вбудувати Internet Explorer в операційну систему Windows, зробивши його браузером за замовчуванням. Ця стратегія, справжній «вбивця платформ», безпосередньо підривала домінування Netscape на ринку. Багато користувачів не обирали IE активно; скоріше, вони просто приймали його як браузер за замовчуванням. Використовуючи можливості розповсюдження Windows, IE швидко став лідером галузі, тоді як Netscape потрапив у занепад.

У розпал труднощів інженери Netscape обрали радикальний і ідеалістичний шлях — вони відкрили вихідний код браузера і закликали до спільноти з відкритим кодом. Це рішення було схоже на "македонську абдикацію" у світі технологій, що сигналізувало про кінець старої ери та підйом нових сил. Цей код пізніше став основою проекту браузера Mozilla, спочатку названого Phoenix (символізуючи відродження), але після кількох суперечок щодо торгових марок, він нарешті був перейменований на Firefox.
Firefox не був простим копіюванням Netscape. Він зробив прориви в користувацькому досвіді, екосистемах плагінів і безпеці. Його народження ознаменувало перемогу духу відкритого коду і внесло нову життєву силу в усю індустрію. Дехто описував Firefox як "духовного наступника" Netscape, подібно до того, як Османська імперія успадкувала згаслу славу Візантії. Хоча це перебільшення, порівняння має сенс.
Проте, ще до офіційного випуску Firefox, Microsoft вже випустила шість версій Internet Explorer. Використовуючи свою ранню тактику і стратегію упаковки з системою, Firefox з самого початку опинився в позиції наздоганяючого, що забезпечило те, що ця гонка ніколи не була рівною конкуренцією, починаючи з однієї лінії.
В той же час, ще один ранній гравець тихо вийшов на сцену. У 1994 році браузер Opera з'явився в Норвегії, спочатку лише як експериментальний проект. Але починаючи з версії 7.0 в 2003 році, він представив свою самостійно розроблену платформу Presto, першою запровадивши підтримку CSS, адаптивних макетів, голосового управління та кодування Unicode. Хоча його база користувачів була обмежена, він постійно лідирував у технологічному плані, ставши "улюбленцем гіків."
Того ж року Apple запустила браузер Safari — значний поворотний момент. На той час Microsoft інвестував 150 мільйонів доларів у struggling Apple, щоб підтримувати подобу конкуренції і уникнути антимонопольного контролю. Хоча пошуковою системою за замовчуванням для Safari з самого початку був Google, це переплетення з Microsoft символізувало складні та тонкі стосунки між інтернет-гігантами: співпраця та конкуренція, завжди переплетені.
У 2007 році був випущений IE7 разом з Windows Vista, але ринкова реакція була холодною. Firefox, з іншого боку, стабільно збільшував свою частку на ринку до приблизно 20%, завдяки швидшим циклам оновлення, більш зручному механізму розширень і природному привабленню для розробників. Домінування IE почало ослаблюватися, і вітри стали змінюватися.
Проте Google обрав інший підхід. Хоча компанія планувала свій власний браузер з 2001 року, їй знадобилося шість років, щоб переконати генерального директора Еріка Шмідта схвалити проект. Chrome дебютував у 2008 році, створений на основі проекту з відкритим кодом Chromium та двигуна WebKit, що використовується Safari. Його висміювали як "перевантажений" браузер, але завдяки глибокій експертизі Google в рекламі та створенні брендів, він швидко піднявся.
Ключовою зброєю Chrome не були його функції, а частий цикл оновлень (кожні шість тижнів) і єдиний крос-платформний досвід. У листопаді 2011 року Chrome вперше обігнав Firefox, досягнувши 27% частки ринку; через шість місяців він обігнав IE, завершивши свою трансформацію з претендента в домінуючого лідера.
Водночас, мобільний інтернет Китаю формував свою власну екосистему. UC Browser від Alibaba набрав популярності на початку 2010-х, особливо на ринках, що розвиваються, таких як Індія, Індонезія та Китай. Завдяки легкому дизайну та функціям стиснення даних, які економили пропускну здатність, він завоював користувачів на пристроях нижчого класу. У 2015 році його частка на глобальному ринку мобільних браузерів перевищила 17%, а в Індії вона колись досягала аж 46%. Але ця перемога не була тривалою. Коли індійський уряд посилив перевірки безпеки китайських додатків, UC Browser був змушений покинути ключові ринки, поступово втрачаючи свою колишню славу.
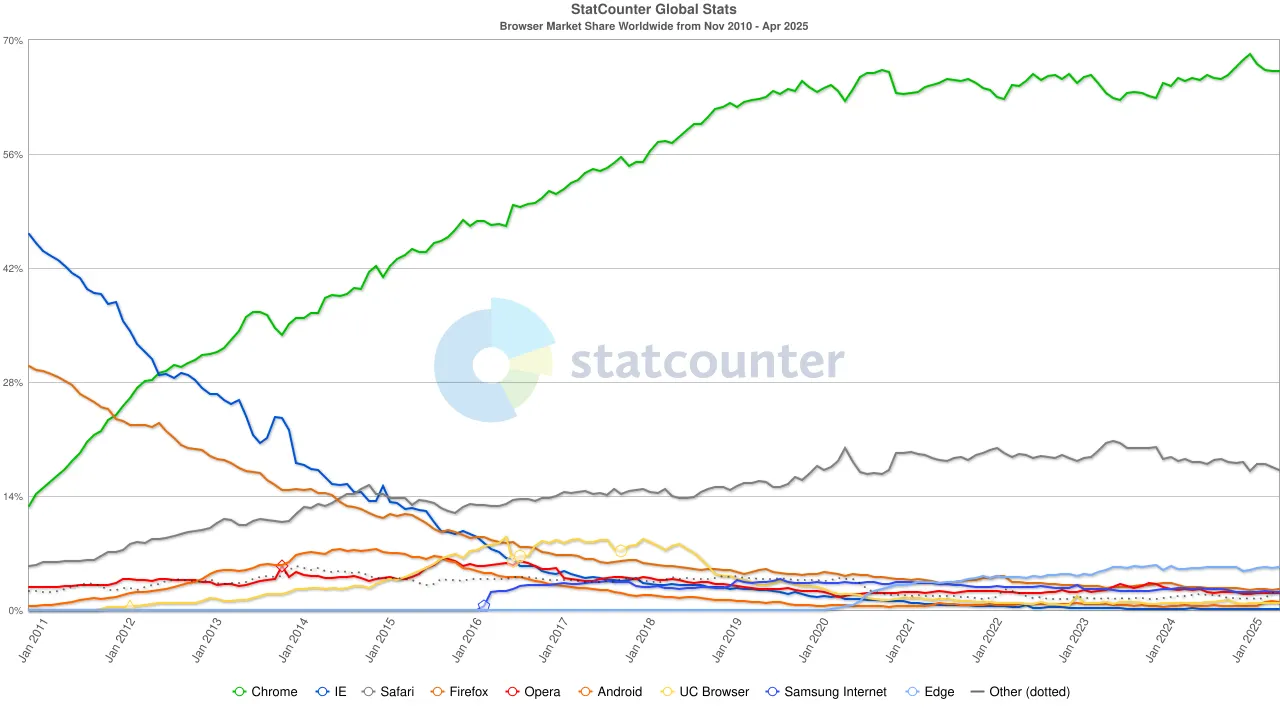
До 2020-х років домінування Chrome було міцно встановлено, а його частка на глобальному ринку стабілізувалася на рівні близько 65%. Важливо зазначити, що, хоча пошукова система Google і браузер Chrome обидва належать Alphabet, з ринкової точки зору вони представляють дві незалежні гегемонії — перша контролює близько 90% глобального пошукового трафіку, а друга слугує "першим вікном", через яке більшість користувачів отримують доступ до Інтернету.
Щоб підтримувати цю структуру подвійної монополії, Google не шкодував витрат. У 2022 році Alphabet заплатила Apple приблизно 20 мільярдів доларів лише для того, щоб Google залишався пошуковою системою за замовчуванням у Safari. Аналітики зазначили, що ці витрати становили близько 36% доходів від реклами в пошуку, які Google отримав від трафіку Safari. Іншими словами, Google фактично платив "плату за захист", щоб захистити свою територію.
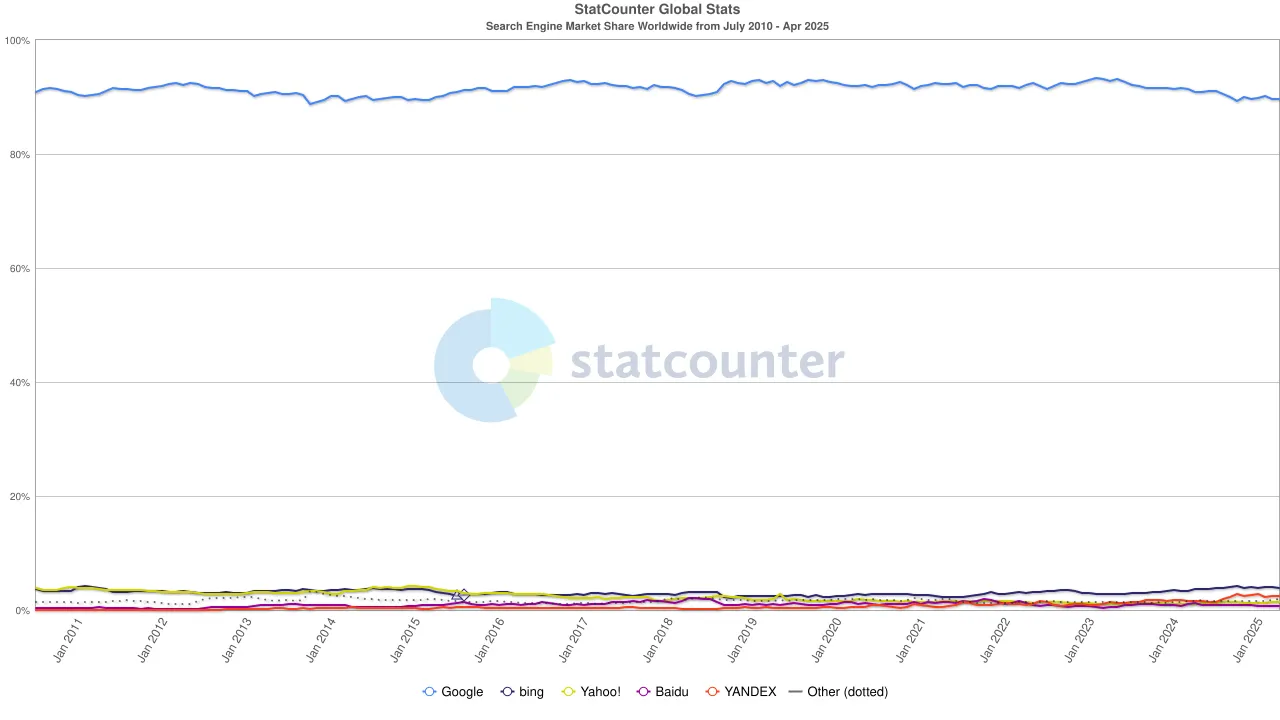
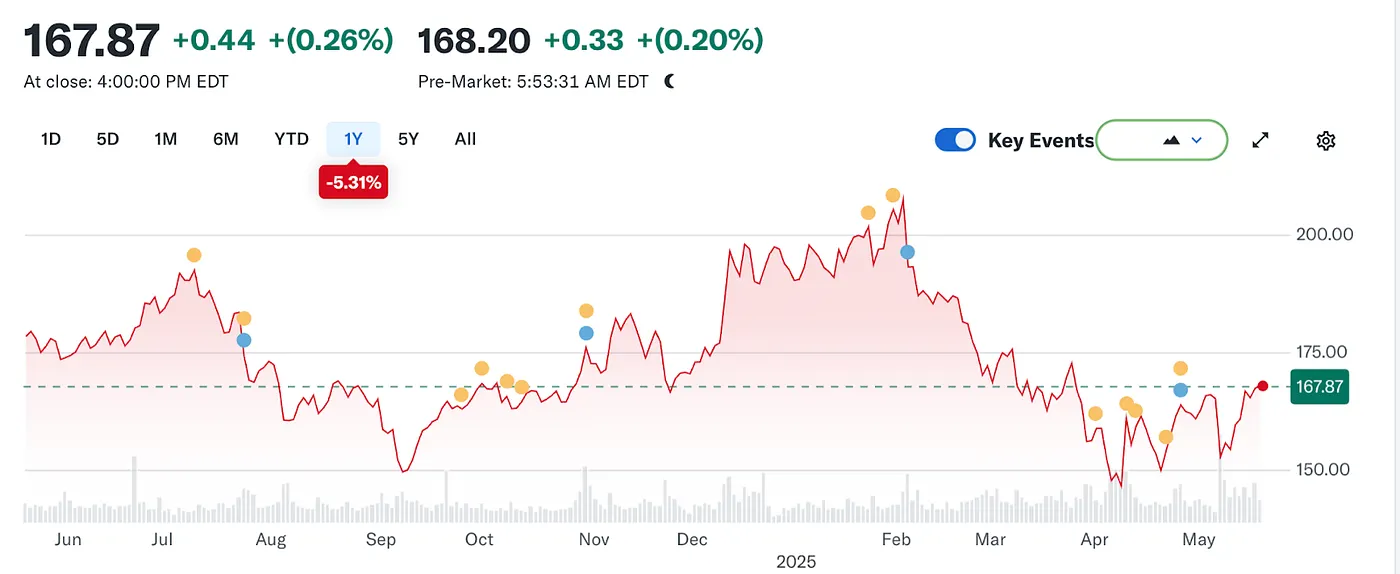
Але潮 знову змінився. З появою великих мовних моделей (LLMs) традиційний пошук почав відчувати вплив. У 2024 році частка Google на ринку пошуку впала з 93% до 89%. Хоча він все ще домінує, тріщини почали з'являтися. Навіть більш руйнівними були чутки про те, що Apple може запустити свій власний пошуковий двигун на базі штучного інтелекту. Якщо за замовчуванням пошук Safari перейде на власну екосистему Apple, це не лише переформатує конкурентне середовище, але також може похитнути саме підґрунтя прибутків Alphabet. Ринок швидко відреагував: акції Alphabet впали з $170 до $140, відображаючи не лише паніку інвесторів, але й глибоке занепокоєння щодо майбутнього напрямку ери пошуку.
Від Navigator до Chrome, від ідеалів з відкритим кодом до комерціалізації, що керується рекламою, від легких браузерів до AI-пошукових асистентів, боротьба браузерів завжди була війною за технології, платформи, контент і контроль. Поле бою постійно змінюється, але суть ніколи не змінюється: хто контролює Gate, той визначає майбутнє.
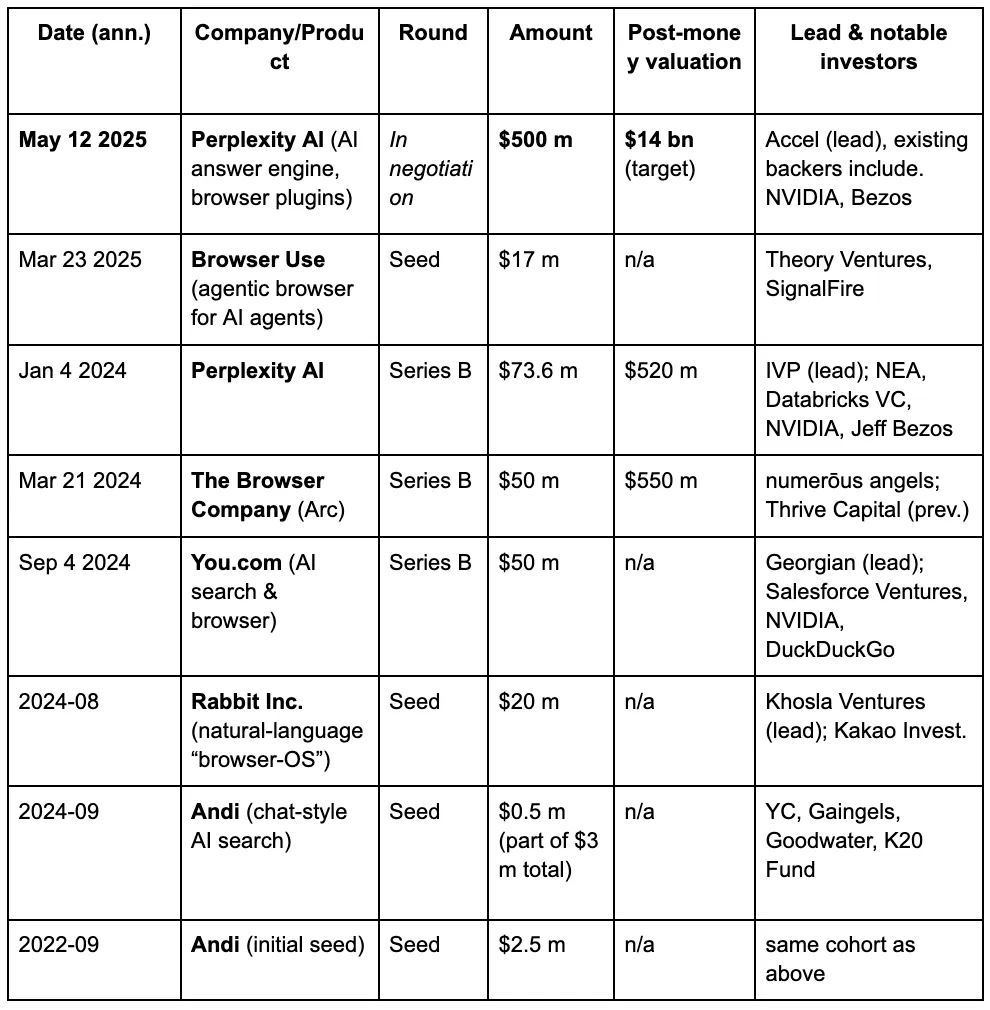
У очах венчурних капіталістів, третя війна браузерів поступово розгортається, керуючись новими вимогами, які люди ставлять до пошукових систем в еру LLM та ШІ. Нижче наведено деталі фінансування деяких відомих проєктів у треку AI браузера.
Застаріла архітектура сучасних браузерів
Коли мова йде про архітектуру браузера, класична традиційна структура показана на діаграмі нижче:
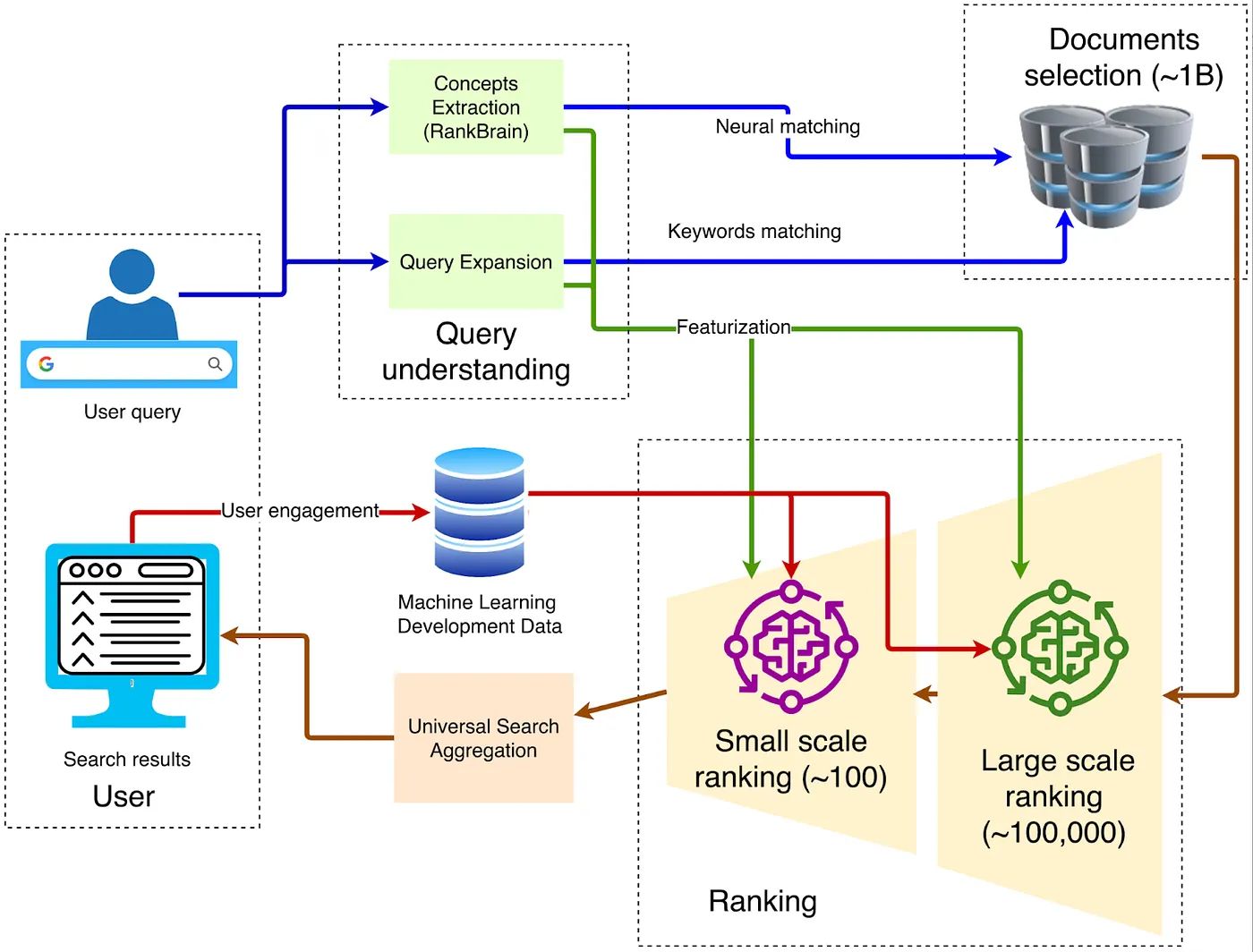
1. Клієнт — фронтальний вхід
Запит надсилається через HTTPS до найближчого Google Front End, де виконується розшифровка TLS, вибірка QoS та географічна маршрутизація. Якщо виявляється аномальний трафік (такі як DDoS-атаки або автоматизоване сканування), на цьому рівні можуть бути застосовані обмеження швидкості або виклики.
2. Розуміння запиту
Фронт-енд повинен розуміти значення слів, введених користувачем. Це включає три етапи:
Нейронне виправлення орфографії, таке як перетворення "recpie" на "recipe".
Розширення синонімів, наприклад, розширення "як полагодити велосипед" для включення "ремонт велосипеда".
Парсинг намірів, який визначає, чи є запит інформаційним, навігаційним чи транзакційним, а потім присвоює відповідний вертикальний запит.
3. Отримання кандидатів
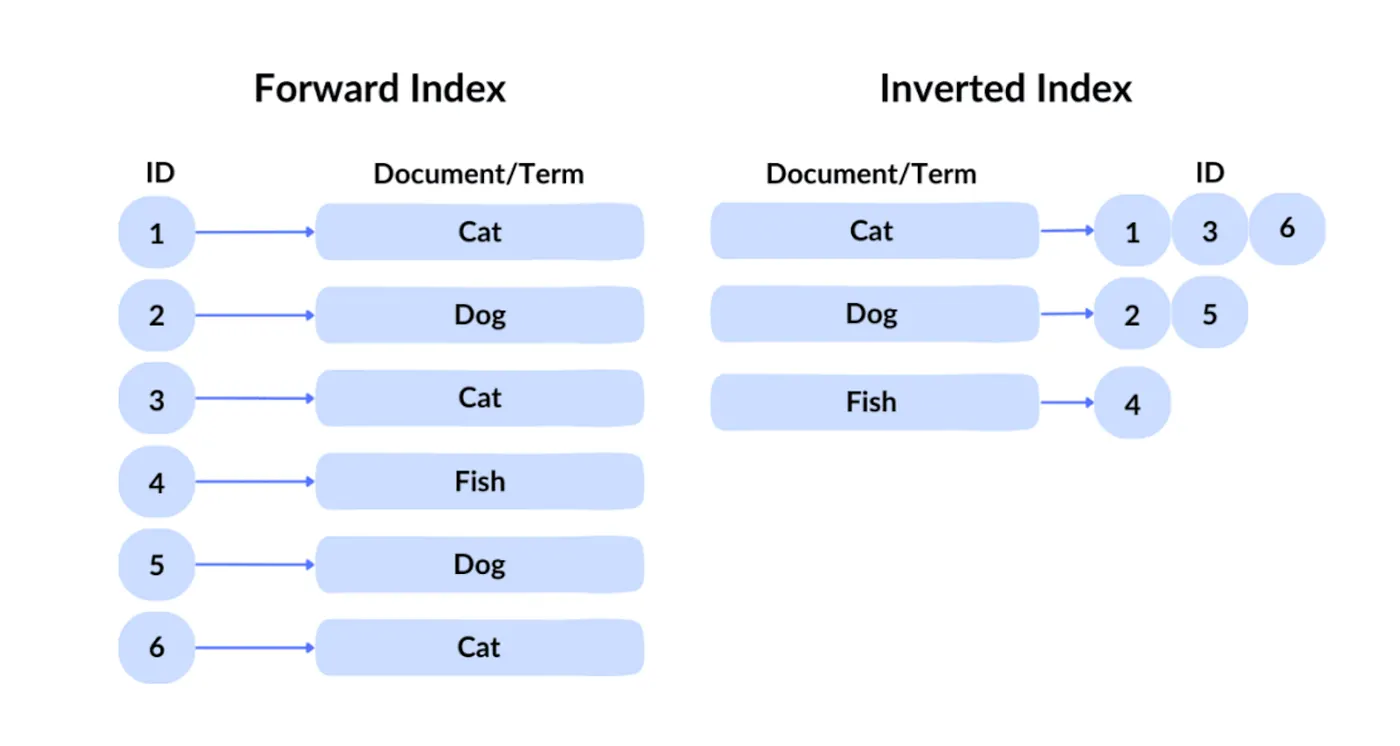
Технологія запитів Google відома як обернений індекс. В прямому індексі ви отримуєте файл, знаючи його ідентифікатор. Але оскільки користувачі не можуть знати ідентифікатори бажаного контенту серед сотень мільярдів файлів, Google використовує традиційний обернений індекс, який запитує за вмістом, щоб визначити, які файли містять відповідні ключові слова.
Далі Google застосовує векторне індексування для обробки семантичного пошуку—тобто, знаходження контенту, схожого за значенням на запит. Він перетворює текст, зображення та інший контент на високоразмірні вектори (вбудовування), а потім виконує пошук на основі схожості між цими векторами. Наприклад, якщо користувач шукає "як зробити тісто для піци", пошукова система може повернути результати, пов'язані з "посібником з приготування тіста для піци", оскільки ці два запити семантично схожі.
Через інверсну індексацію та векторну індексацію приблизно сотні тисяч веб-сторінок відфільтровуються на початковому етапі скринінгу.
4. Багатоступенева Рейтинга
Система зазвичай використовує тисячі легковагових функцій, таких як BM25, TF-IDF та оцінки якості сторінок, щоб відфільтрувати сотні тисяч кандидатних сторінок до приблизно 1,000, формуючи початковий набір кандидатів. Такі системи колективно називають системами рекомендацій. Вони покладаються на масивні функції, згенеровані з різних сутностей, включаючи поведінку користувачів, атрибути сторінок, наміри запитів та контекстуальні сигнали. Наприклад, Google поєднує історію користувачів, відгуки від інших користувачів, семантику сторінок та значення запитів, одночасно враховуючи контекстуальні елементи, такі як час (час доби, день тижня) та зовнішні події, такі як термінові новини.
5. Глибоке навчання для первинного ранжування
На початковому етапі отримання інформації Google використовує такі технології, як RankBrain та Neural Matching, щоб зрозуміти семантику запитів та відфільтрувати найбільш релевантні результати з величезних колекцій документів.
RankBrain, представлений Google у 2015 році, є системою машинного навчання, розробленою для кращого розуміння значення запитів користувачів, особливо запитів, які ніколи раніше не зустрічалися. Він перетворює запити та документи у векторні представлення та обчислює їхню схожість, щоб знайти найрелевантніші результати. Наприклад, для запиту "як зробити тісто для піци", навіть якщо жоден документ не містить точного збігу ключового слова, RankBrain може визначити контент, пов'язаний із "основами піци" або "підготовкою тіста."
Нейронне відповідність, запущене в 2018 році, було розроблено для того, щоб ще більше зафіксувати семантичні зв'язки між запитами та документами. Використовуючи моделі нейронних мереж, воно визначає нечіткі зв'язки між словами, щоб краще відповідати запитам із веб-контентом. Наприклад, для запиту "чому мій вентилятор ноутбука такий гучний", Нейронне відповідність може зрозуміти, що користувач може шукати інформацію з усунення несправностей щодо перегріву, накопичення пилу або високого використання процесора — навіть якщо ці терміни не з'являються явно в запиті.
6. Глибоке перевиборювання: застосування BERT
Після початкового фільтрування відповідних документів Google застосовує BERT (Bidirectional Encoder Representations from Transformers) для уточнення ранжування та забезпечення того, щоб найбільш релевантні результати з'являлися на верху. BERT є попередньо навченою мовною моделлю, заснованою на Transformers, яка може розуміти контекстуальні зв'язки слів у реченнях.
У пошуку BERT використовується для повторного ранжування документів, отриманих на ранніх етапах. Він спільно кодує запити та документи, обчислює їхні оцінки релевантності, а потім перерозподіляє документи. Наприклад, для запиту "паркування на пагорбі без бордюру" BERT може правильно інтерпретувати значення "без бордюру" і повернути результати, які радять водіям повертати колеса до узбіччя, а не неправильно інтерпретувати це як ситуацію з бордюром.
Для SEO-інженерів це означає, що їм потрібно уважно вивчити алгоритми ранжування та рекомендацій машинного навчання Google, щоб оптимізувати веб-контент цілеспрямованим чином, отримуючи таким чином вищу видимість у результатах пошуку.
Чому ШІ змінить браузери
По-перше, нам потрібно прояснити: чому браузер як форма все ще має існувати? Чи існує третій парадигма, крім агентів ШІ та браузерів?
Ми вважаємо, що існування передбачає незамінність. Чому штучний інтелект може використовувати браузери, але не може повністю їх замінити? Тому що браузер є універсальною платформою. Він не лише точка входу для читання даних, але й загальна точка входу для введення даних. Світ не може лише споживати інформацію — він також повинен виробляти дані та взаємодіяти з вебсайтами. Тому браузери, які інтегрують персоналізовану інформацію користувачів, будуть продовжувати широко існувати.
Ось ключовий момент: як універсальні ворота, браузер призначений не лише для читання даних; користувачам часто потрібно взаємодіяти з даними. Сам браузер є відмінним сховищем для зберігання відбитків пальців користувачів. Більш складні поведінки користувачів та автоматизовані дії повинні виконуватися через браузер. Браузер може зберігати всі відбитки пальців поведінки користувачів, облікові дані та іншу приватну інформацію, що дозволяє бездоказове викликання під час автоматизації. Взаємодія з даними може еволюціонувати в цю схему:
Користувач → викликає AI Агент → Браузер.
Іншими словами, єдина частина, яка може бути замінена, полягає в природному тренді світу — до більшої інтелектуальності, персоналізації та автоматизації. Звичайно, ця частина може бути оброблена агентами ШІ. Але самі агенти ШІ не дуже підходять для перенесення персоналізованого контенту користувачів, оскільки вони стикаються з численними викликами щодо безпеки даних і зручності використання. Конкретно:
Браузер є сховищем для персоналізованого контенту:
Більшість великих моделей розміщені в хмарі, а контексти сесій залежать від серверного зберігання, що ускладнює прямий доступ до локальних паролів, гаманців, кукі та інших чутливих даних.
Відправка всіх даних про перегляд і платежі третім сторонам вимагає повторної авторизації користувача; DMА ЄС та закони про конфіденційність на рівні штатів США вимагають мінімізації даних через кордони.
Автоматичне заповнення кодів двофакторної аутентифікації, виклик камер або використання GPU для WebGPU інференції повинно виконуватись у пісочниці браузера.
Контекст даних сильно залежить від браузера. Вкладки, куки, IndexedDB, кеш службового працівника, облікові дані ключа доступу та дані розширень зберігаються в браузері.
Глибокі зміни у формах взаємодії
Повертаючись до теми з самого початку, нашу поведінку під час використання браузерів можна загалом поділити на три категорії: читання даних, введення даних і взаємодія з даними. Великі мовні моделі (LLMs) вже глибоко змінили ефективність і методи, якими ми читаємо дані. Стара практика користувачів шукати веб-сторінки за ключовими словами тепер виглядає застарілою та неефективною.
Коли мова йде про еволюцію поведінки користувачів під час пошуку — чи то мета отримати узагальнені відповіді, чи перейти на веб-сторінки — багато досліджень вже проаналізували цей зсув.
Щодо патернів поведінки користувачів, дослідження 2024 року показало, що в США з кожних 1,000 запитів у Google лише 374 закінчилися переходом на відкриту веб-сторінку. Іншими словами, майже 63% були "нульовими" поведінками. Користувачі звикли отримувати інформацію, таку як погода, курси валют та картки знань, безпосередньо зі сторінки результатів пошуку.
Що насправді могло б спровокувати масштабну трансформацію браузерів, так це шар взаємодії з даними. У минулому люди взаємодіяли з браузерами в основному, вводячи ключові слова — максимально можливий рівень розуміння, який сам браузер міг обробити. Тепер користувачі все більше віддають перевагу використанню повної природної мови для опису складних завдань, таких як:
"Знайдіть мені прямі рейси з Нью-Йорка до Лос-Анджелеса на певний період."
"Знайди мені рейс з Нью-Йорка до Шанхаю, а потім до Лос-Анджелеса."
Навіть для людей такі завдання вимагають багато часу для відвідування кількох веб-сайтів, збору інформації та порівняння результатів. Але ці агентські завдання поступово перебирають на себе агенти ШІ.
Це також відповідає траєкторії історії: автоматизація та інтелект. Люди прагнуть звільнити свої руки, і агенти ШІ неминуче будуть глибоко інтегровані у браузери. Майбутні браузери повинні бути спроектовані з повною автоматизацією на увазі, особливо враховуючи:
Як збалансувати читання для людей з можливістю інтерпретації для AI-агентів.
Як забезпечити, щоб одна веб-сторінка служила як кінцевому користувачу, так і агентній моделі.
Тільки виконуючи обидва ці вимоги до дизайну, браузери можуть справді стати стабільними носіями для агентів ШІ для виконання завдань.
Далі ми зосередимося на п'яти видатних проєктах — Browser Use, Arc (The Browser Company), Perplexity, Brave та Donut. Ці проєкти представляють майбутні напрямки еволюції AI браузерів, а також їх потенціал для нативної інтеграції в контекстах Web3 та криптовалют.
З точки зору психології користувача, опитування 2023 року показало, що 44% респондентів вважають регулярні органічні результати більш надійними, ніж спеціалізовані фрагменти. Академічні дослідження також виявили, що в умовах суперечок або відсутності єдиної авторитетної істини користувачі віддають перевагу сторінкам результатів, що містять посилання з кількох джерел.
Іншими словами, хоча частина користувачів не повністю довіряє підсумкам, згенерованим штучним інтелектом, значний відсоток поведінки вже змістився до "нульового кліку". Тому AI-браузерам ще потрібно досліджувати правильну парадигму взаємодії — особливо в сфері читання даних. Оскільки проблема галюцинацій у великих моделях ще не була повністю вирішена, багато користувачів все ще борються з повною довірою до автоматично згенерованих підсумків контенту. У цьому відношенні вбудовування великих моделей у браузери не обов'язково вимагає руйнівної трансформації. Замість цього просто потрібні поступові поліпшення в точності та керованості — процес, який вже розпочався.
Використання браузера
Це саме основна логіка, що стоїть за величезним фінансуванням, яке отримали Perplexity та Browser Use. Зокрема, Browser Use став другою найбільш перспективною інноваційною можливістю на початку 2025 року, з обидвома певністю та значним потенціалом зростання.

Використання браузера створило справжній семантичний шар, зосередившись на створенні архітектури семантичного розпізнавання для наступного покоління браузерів.
Browser Use переосмислює традиційне "DOM = дерево вузлів для людей" в "Семантичне DOM = інструкційне дерево для LLMs". Це дозволяє агентам точно натискати, заповнювати та завантажувати без залежності від "піксельних координат". Замість використання візуального OCR або координатно-орієнтованого Selenium, цей підхід обирає шлях "структурований текст → функціональні виклики", що робить виконання швидшим, економить токени та зменшує помилки. TechCrunch описав це як "клейовий шар, який дозволяє ШІ дійсно розуміти веб-сторінки". У березні Browser Use завершив раунд початкових інвестицій на суму 17 мільйонів доларів, ставлячи на цю фундаментальну інновацію.
Ось як це працює:
Після рендерингу HTML формується стандартне дерево DOM. Браузер потім створює дерево доступності, яке надає більш багаті мітки «ролей» та «станів» для програм читання з екрану.
Кожен інтерактивний елемент (кнопка, введення тощо) абстрагується у фрагмент JSON з метаданими, такими як роль, видимість, координати та виконувані дії.
Вся сторінка перекладена в сплюснутий список семантичних вузлів, які LLM може прочитати в одному системному запиті.
LLM генерує інструкції високого рівня (наприклад, натисніть(node_id="btn-Checkout")), які потім відтворюються в реальному браузері.
Офіційний блог описує цей процес як "перетворення веб-інтерфейсів на структурований текст, який можуть парсити LLM".
Більш того, якщо цей стандарт коли-небудь буде прийнятий W3C, це може суттєво вирішити проблему введення в браузерах. Далі ми розглянемо відкритий лист і випадки з практики компанії The Browser Company, щоб детальніше пояснити, чому їхній підхід є недосконалим.
Арка
Компанія Browser (материнська компанія Arc) заявила у своєму відкритому листі, що браузер Arc увійде в режим регулярного обслуговування, в той час як команда зосередить свою увагу на розробці DIA, браузера, повністю орієнтованого на ШІ. У листі вони також визнали, що конкретний шлях реалізації DIA ще не визначено. Водночас команда окреслила кілька прогнозів щодо майбутнього ринку браузерів.
На основі цих прогнозів ми також вважаємо, що якщо поточна ситуація з браузерами дійсно має бути порушена, ключ до цього полягає в зміні виходу сторони взаємодії.
Нижче наведено три прогнози щодо майбутнього ринку браузерів, які поділилася команда Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
По-перше, команда Arc вважає, що веб-сторінки більше не будуть основним інтерфейсом для взаємодії. Звісно, це смілива та складна заява, і саме це є основною причиною, чому ми залишаємося скептичними щодо роздумів їхнього засновника. На нашу думку, ця перспектива значно недооцінює роль браузера і підкреслює ключове питання, яке команда проігнорувала, досліджуючи шлях AI браузера.
Великі моделі прекрасно справляються з розпізнаванням намірів—наприклад, розуміння інструкцій, таких як "допоможіть мені забронювати рейс". Однак вони залишаються недостатніми, коли йдеться про щільність інформації. Коли користувачеві потрібен щось на кшталт інформаційної панелі, блокнота в стилі Bloomberg Terminal або візуальної дошки на кшталт Figma, нічого не може перевершити тонко налаштовану веб-сторінку з точністю на рівні пікселів. Ергономіка кожного продукту—діаграми, функціональність перетягування, гарячі клавіші—не є поверхневим декором, а суттєвими можливостями, які стискають когніцію. Ці можливості не можуть бути відтворені простими розмовними взаємодіями. Взяти Gate.com як приклад: якщо користувач хоче виконати інвестиційні дії, покладатися лише на розмову з ШІ недостатньо, оскільки користувачі сильно залежать від структурованого вводу, точності та чіткого представлення інформації.
Дорожня карта команди Arc містить фундаментальну помилку: вона не чітко розрізняє, що "взаємодія" складається з двох вимірів — вводу та виводу. З боку вводу їхня точка зору має певну обґрунтованість у деяких сценаріях, оскільки ШІ дійсно може підвищити ефективність командних взаємодій. Але з боку виводу їхнє припущення явно незбалансоване, оскільки воно ігнорує основну роль браузера у представленні інформації та персоналізованих враженнях. Наприклад, Reddit має свою унікальну структуру та архітектуру інформації, тоді як AAVE має зовсім інший інтерфейс і структуру. Як платформа, яка одночасно зберігає дуже приватні дані та надає різноманітні продуктові інтерфейси, браузер має обмежену замінність з боку вводу, тоді як його складність та нестандартна природа з боку виводу роблять його ще важче порушити.
Натомість, сучасні AI-браузери в основному зосереджуються на шарі «підсумовування виходу»: підсумовування сторінок, витягування інформації, формування висновків. Це недостатньо, щоб поставити фундаментальний виклик основним браузерам чи пошуковим системам, таким як Google — це лише зменшує частку ринку для пошукових підсумків.
Отже, єдина технологія, яка дійсно могла б потрясти 66% ринкової частки Chrome, не призначена бути «наступним Chrome». Щоб досягти справжнього розриву, модель рендерингу браузерів повинна бути кардинально перепроектована, щоб адаптуватися до потреб взаємодії ери AI Agent, особливо в аспекті дизайну архітектури на стороні введення. Саме тому ми вважаємо технічний шлях, обраний Browser Use, значно більш переконливим — він зосереджений на структурних змінах в основному механізмі браузерів. Як тільки будь-яка система досягає «атомного» або «модульного» дизайну, програмованість і композитність, що витікають з цього, відкривають руйнівний потенціал. Це саме той напрямок, який сьогодні переслідує Browser Use.
У підсумку, функціонування агентів штучного інтелекту все ще сильно залежить від існування браузерів. Браузери є не лише основними репозиторіями складних персоналізованих даних, але й універсальними інтерфейсами рендерингу для різноманітних додатків, і, отже, вони продовжуватимуть виконувати роль основних Gate для взаємодії в майбутньому. Оскільки агенти штучного інтелекту глибоко вбудовуються в браузери для виконання фіксованих завдань, вони взаємодіятимуть з даними користувача та специфічними додатками, головним чином через вхідну сторону. З цієї причини нинішня модель рендерингу браузерів повинна бути інноваційною для досягнення максимальної сумісності та адаптивності з агентами штучного інтелекту — врешті-решт дозволяючи їм більш ефективно захоплювати додатки.
Заплутаність
Перплексіті — це пошукова система на основі штучного інтелекту, відома своєю системою рекомендацій. Його остання оцінка зросла до 14 мільярдів доларів, що майже в п'ять разів більше, ніж 3 мільярди в червні 2024 року. Зараз вона обробляє більше 400 мільйонів запитів на місяць. У вересні 2024 року вона опрацювала близько 250 мільйонів запитів, що стало вісім разів більше в порівнянні з минулим роком за обсягом пошукових запитів користувачів, з понад 30 мільйонами активних користувачів щомісяця.
Основною особливістю є можливість узагальнювати сторінки в реальному часі, що надає їй значну перевагу в доступі до актуальної інформації. На початку цього року Perplexity почала розробку свого власного рідного браузера, Comet. Компанія описує Comet як браузер, який не лише "відображає" веб-сторінки, але й "думає" про них. Офіційно вони стверджують, що він вбудує відповідний двигун Perplexity глибоко в сам браузер, дотримуючись підходу "цілої машини", що нагадує філософію Стіва Джобса: глибока інтеграція завдань ШІ на основному рівні браузера, а не просто створення плагінів для бокової панелі.
З короткими відповідями, підкріпленими посиланнями, Comet прагне замінити традиційні "десять синіх посилань" і безпосередньо конкурувати з Chrome.
Але Perplexity все ще потрібно вирішити дві основні проблеми: високі витрати на пошук та низькі маржі прибутку від маргінальних користувачів. Хоча Perplexity наразі лідирує у сфері AI-пошуку, Google оголосив на своїй конференції I/O 2025 про масштабну інтелектуальну модернізацію своїх основних продуктів. Для браузерів Google запустив новий досвід вкладки браузера під назвою AI Model, який інтегрує Overview, Deep Research та майбутні можливості Agentic. Вся ініціатива називається "Project Mariner."
Google активно просуває свою трансформацію в сфері штучного інтелекту, що означає, що поверхневе імітування функцій — такі як Overview, Deep Research або Agentics — навряд чи становитиме реальну загрозу. Те, що дійсно може встановити новий порядок серед хаосу, це перебудова архітектури браузера з нуля, глибоке вбудовування великих мовних моделей (LLMs) у ядро браузера та фундаментальна трансформація методів взаємодії.
Сміливий
Brave є одним із найраніших і найуспішніших браузерів у криптоіндустрії. Побудований на архітектурі Chromium, він сумісний з розширеннями з Google Store. Brave приваблює користувачів моделлю, заснованою на конфіденційності та заробітку токенів під час перегляду. Його шлях розвитку демонструє певний потенціал зростання. Однак з точки зору продукту, хоча конфіденційність дійсно важлива, попит залишається зосередженим у конкретних групах користувачів. Для ширшої публіки усвідомлення конфіденційності ще не стало основним фактором прийняття рішень. Тому спроба покладатися лише на цю функцію, щоб порушити існуючі гіганти, навряд чи буде успішною.
На даний момент у Brave налічується 82,7 мільйона активних користувачів на місяць (MAU) та 35,6 мільйона активних користувачів на день (DAU), що становить приблизно 1%–1,5% ринкової частки. Його база користувачів демонструє стабільний ріст: з 6 мільйонів у липні 2019 року, до 25 мільйонів у січні 2021 року, до 57 мільйонів у січні 2023 року, а до лютого 2025 року перевищила 82 мільйони. Його складний середньорічний темп зростання залишається двозначним.
Brave обробляє приблизно 1,34 мільярда пошукових запитів на місяць, що становить близько 0,3% обсягу Google.
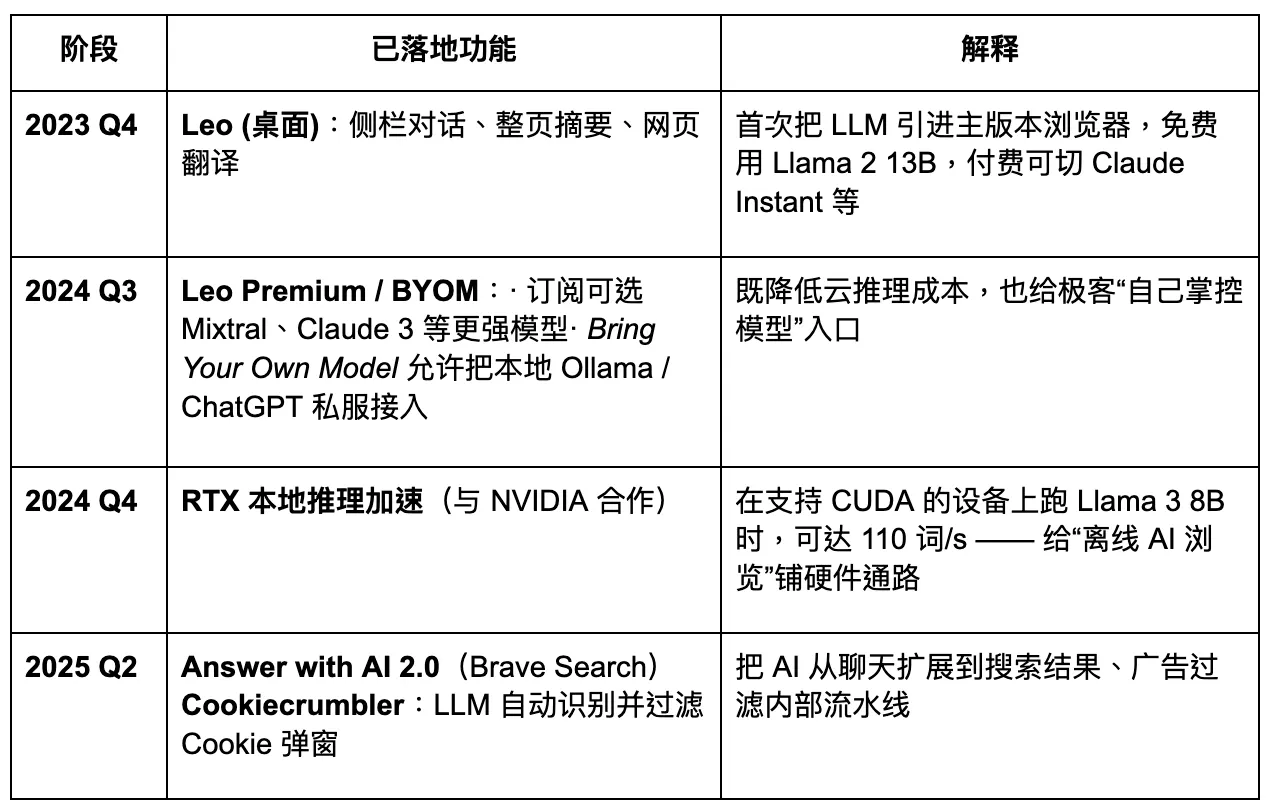
Brave планує оновити свій браузер, зосереджуючи увагу на конфіденційності. Проте, обмежений доступ до даних користувачів зменшує рівень кастомізації, можливий для великих моделей, що, у свою чергу, ускладнює швидку та точну ітерацію продуктів. В епоху Агентного Браузера Brave може зберегти стабільну частку серед певних груп користувачів, зосереджених на конфіденційності, але буде важко стати домінуючим гравцем. Його AI-помічник, Leo, працює більше як покращення плагіна — пропонує певні можливості підсумовування контенту, але не має чіткої стратегії для повного переходу до AI-агентів. Інновації в взаємодії залишаються недостатніми.
Пончик
Нещодавно криптоіндустрія також досягла прогресу в галузі агентних браузерів. Проект на ранній стадії Donut залучив 7 мільйонів доларів у пре-сід раунді, очолюваному Hongshan (Sequoia China), HackVC та Bitkraft Ventures. Проект все ще знаходиться на ранній концептуальній стадії, з баченням досягнення "Відкриття – Прийняття рішень – і Крипто-нативне виконання" як інтегрованої здатності.
Основний напрямок полягає в поєднанні шляхів автоматизації виконання, що походять з криптовалют. Як передбачив a16z, агенти можуть замінити пошукові системи як основний канал трафіку в майбутньому. Підприємці більше не будуть конкурувати за алгоритми ранжування Google, а, скоріше, боротися за трафік і конверсії, які надходять від виконання агентів. Індустрія вже назвала цю тенденцію "AEO" (Оптимізація відповіді / двигуна агентів), або навіть далі, "ATF" (Виконання завдань агентом)—де мета більше не полягає в оптимізації рейтингів пошуку, а в безпосередньому обслуговуванні інтелектуальних моделей, які можуть виконувати завдання для користувачів, такі як розміщення замовлень, бронювання квитків або написання листів.
Для підприємців
По-перше, слід визнати: сам браузер залишається найбільшим нереконструйованим «Gateway» у світі інтернету. З приблизно 2,1 мільярдами користувачів настільних комп'ютерів і понад 4,3 мільярдами мобільних користувачів у всьому світі, він слугує загальним перевізником для введення даних, інтерактивної поведінки та зберігання персоналізованих відбитків. Причина його стійкості не в інерції, а в притаманній браузеру подвійній природі: він є як точкою входу для читання даних, так і точкою виходу для написання дій.
Отже, для підприємців справжній руйнівний потенціал не полягає в оптимізації шару «виводу сторінки». Навіть якщо хтось зможе відтворити функції огляду AI, подібні до Google, у новій вкладці, це все ще буде лише ітерацією на рівні плагіна, а не фундаментальною зміною парадигми. Справжній прорив полягає у «вхідній стороні» — як змусити AI-агентів активно викликати ваш продукт для виконання конкретних завдань. Це визначить, чи може продукт вбудуватися в екосистему агентів, захопити трафік і поділитися в розподілі вартості.
В еру пошуку конкуренція полягала в кліках; в еру агентів вона полягає в дзвінках.
Якщо ви підприємець, ви повинні переосмислити свій продукт як компонент API — щось, що інтелектуальний агент може не лише зрозуміти, але й викликати. Це вимагає від вас враховувати три виміри з самого початку дизайну продукту:
1. Стандартизація структури інтерфейсу: Чи можна викликати ваш продукт?
Здатність агента викликати продукт залежить від того, чи можна стандартизувати та абстрагувати його інформаційну структуру в чітку схему. Наприклад, чи можуть ключові дії, такі як реєстрація користувача, розміщення
Поділіться
Контент
Як купити криптовалюту





Трендові криптовалюти



Глибоке дослідження: Дорога вперед: Коли Фед завершить кількісне скорочення і що це може означати для Крипто-ринку?

Де купити Labubu в Японії: Топ-магазини та онлайн-магазини 2025

Біткойн Ринкова капіталізація в 2025 році: Аналіз та тенденції для інвесторів

TerraClassicUSD (USTC) – Походження, Крах і Чи перепегуватиметься ?
Як купити Біткоїн ETF безпосередньо в 2025 році

Tron (TRX), BitTorrent (BTT) і Sun Token (SUN): Чи може криптосистема Джастина Сана зрости у 2025 році?

Огляд EIP 4337: Повний посібник із абстракції облікових записів

Як працюють криптографічні ключі в цифрових гаманцях

Вичерпний посібник із підвищення конфіденційності з використанням сервісів мікшування Bitcoin

Інтеграція мережі Polygon з MetaMask: покрокова інструкція

Розуміння смартконтрактів: як вони працюють у екосистемі блокчейну
