代償そのものが進歩である。執筆:Sleepy.txt八年前、中興の心臓停止。2018年4月16日、米国商務省産業安全局の禁令により、中興通信は8万人の従業員と千億超の年間売上高を誇る世界第4位の通信機器メーカーでありながら、一夜にして操業停止に追い込まれた。禁令の内容は非常に単純で、今後7年間、米国企業から中興に対して部品、商品、ソフトウェア、技術の販売を禁じるというものだった。クアルコムのチップがなくなり、基地局の生産停止。GoogleのAndroid認証も得られず、スマートフォンも使えるシステムがなくなる。23日後、中興は公告を出し、主要な事業活動が行えなくなったと発表した。しかし中興は最終的に生き延びたが、その代償は14億ドルだった。10億ドルの罰金を一括支払い、4億ドルの保証金を米国の銀行の管理口座に預け入れた。さらに、全役員の交代と米国側のコンプライアンス監督チームの進入を受け入れた。2018年通年で、中興は70億元の純損失を計上し、売上高は前年同期比21.4%減少した。当時の中興董事長殷一民は内部文書でこう記している:「我々は複雑で、グローバルサプライチェーンに高度に依存する産業に身を置いている。」この言葉は、当時の反省とともに、無力感も漂わせていた。八年後、2026年2月26日、中国のAIユニコーンDeepSeekは、今後リリース予定のV4多モーダル大規模モデルが、国内チップメーカーとの深い協力を優先し、事前学習から微調整までの全工程を英偉達(NVIDIA)を使わずに実現する初の試みを発表した。翻訳すれば:私たちは英偉達を使わなくなる。このニュースが出ると、市場の第一反応は疑問だった。英偉達は世界のAI訓練用チップ市場の90%以上のシェアを持つ。これを放棄するのは商業的に合理的なのか?しかしDeepSeekの選択の背後には、商業ロジックを超えた大きな問題が潜んでいる。中国のAIは、いったいどのような計算能力の独立を必要としているのか?何が足枷になっているのか----------多くの人は、チップの禁輸措置はハードウェアの問題だと考えている。しかし、中国のAI企業を窒息させている本当の原因は、「CUDA」というものにある。CUDA(Compute Unified Device Architecture)は、英偉達が2006年に導入した並列計算プラットフォーム兼プログラミングモデルだ。これにより、開発者は英偉達GPUの計算能力を直接呼び出し、さまざまな複雑な計算タスクを高速化できる。AI時代が到来する前は、これは一部の極少数の技術者だけのツールだった。しかし、深層学習の波が押し寄せると、CUDAはAI産業の基盤となった。AI大規模モデルの訓練は本質的に膨大な行列演算であり、これはGPUが最も得意とする作業だ。英偉達は、十数年の先行投資を背景に、CUDAを用いて世界中のAI開発者向けにハードウェアからアプリケーションまでの一連のツールチェーンを構築してきた。今日、GoogleのTensorFlowやMetaのPyTorchをはじめとする主要なAIフレームワークは、底層でCUDAと深く結びついている。AI専門の博士課程の学生は、入学初日からCUDA環境の中で学び、プログラミングし、実験を行う。彼らが書くコードの一行一行が、英偉達の護城河を強化している。2025年までに、CUDAエコシステムには450万人以上の開発者が参加し、3000以上のGPU加速アプリケーションをカバーし、世界中の企業4万社以上が利用している。この数字は、世界のAI開発者の90%以上が英偉達のエコシステムに縛られていることを意味する。CUDAの恐ろしさは、それが一つの飛輪のような存在であることだ。使えば使うほど、ツールやライブラリ、コードが増え、エコシステムは繁栄し、さらに多くの開発者を惹きつける。この循環が一度回り出すと、ほぼ止められなくなる。結果として、英偉達は最も高価なシャベルを売りつつ、唯一のマイニング姿勢も定義している。別のシャベルに換えたい?可能だ。しかし、そのためには過去十数年にわたり、世界中の最も賢い頭脳たちがこの姿勢の下で蓄積した経験、ツール、コードをすべて書き直さなければならない。そのコストを誰が負担するのか?だから、2022年10月7日に第一弾の規制が実施され、英偉達のA100とH100の中国向け輸出が制限されたとき、中国のAI企業は初めて中興式の窒息感を味わった。その後、英偉達は「中国向け特供版」A800とH800をリリースし、チップ間の通信帯域を縮小して供給を維持した。しかしわずか1年後の2023年10月17日、第二弾の規制が再び強化され、A800とH800も禁じられ、13の中国企業がエンティティリストに載せられた。英偉達はさらに制限を加え、H20の出荷も厳格化した。2024年12月、バイデン政権の任期内最後の規制が実施され、H20の輸出も厳しく制限された。三度の規制、段階的に強化。しかし今回は、当時の中興とは全く異なる展開となった。非対称的な突破戦--------禁令の下、多くは中国のAI大規模モデルの夢は終わったと考えた。しかし彼らは間違っていた。封鎖に直面しても、中国企業は正面からの激突を選ばず、突破の道を模索し始めた。その最初の戦場は、チップではなくアルゴリズムだった。2024年末から2025年にかけて、中国のAI企業は一斉に「ハイブリッドエキスパートモデル」へと方向転換した。これは、巨大なモデルを複数の小さなエキスパートに分割し、タスク処理時には最も関連性の高いエキスパートだけを活性化させ、全体を動かさないという手法だ。DeepSeekのV3はこの思考の典型例だ。パラメータは6710億個だが、推論時にはそのうちの370億だけを活性化し、全体のわずか5.5%を使用している。訓練コストは2048台の英偉達H800 GPUを用い、58日間で訓練し、総費用は557.6万ドル。対して、外部推定によるとGPT-4の訓練コストは約7800万ドルとされる。桁違いの差だ。アルゴリズムの極致的な最適化は、価格に直結している。DeepSeekのAPI価格は、入力1百万トークンあたり0.028ドルから0.28ドル、出力は0.42ドル。一方、GPT-4oは入力5ドル、出力15ドル。Claude Opusはさらに高く、入力15ドル、出力75ドルだ。換算すると、DeepSeekはClaudeの25倍から75倍安い。この価格差は、世界の開発者市場に大きな反響を呼んでいる。2026年2月、世界最大のAIモデルAPI集約プラットフォーム「OpenRouter」では、中国AIモデルの週次呼び出し回数が3週間で127%増加し、初めて米国を超えた。一年前はシェアは2%未満だったが、今や約60%に迫る勢いだ。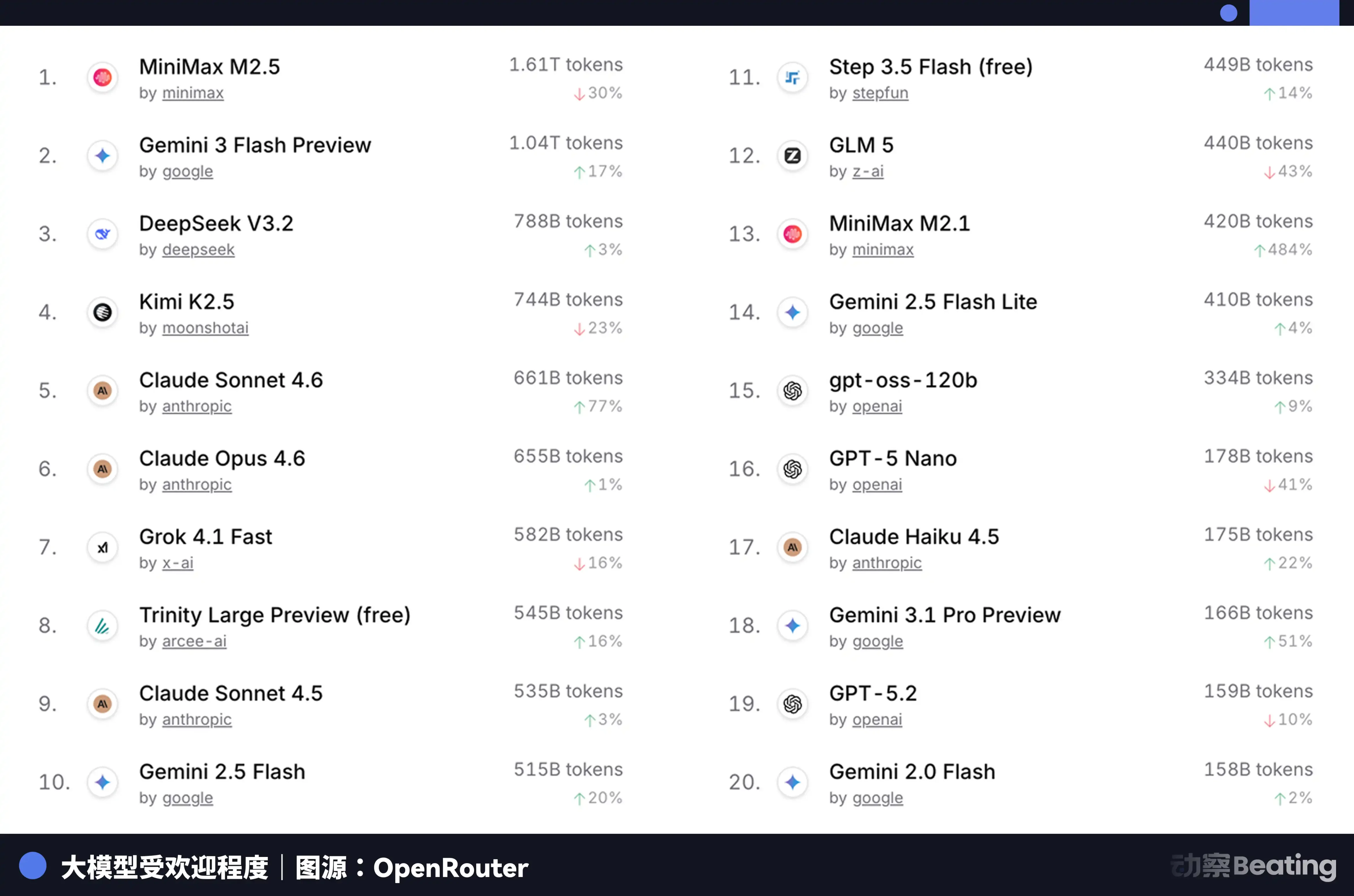この背後には、見落とされがちな構造的変化がある。2025年後半から、AIの主流シナリオはチャットからエージェントへと移行しつつある。エージェントシナリオでは、一つのタスクにかかるトークン消費量は、単純なチャットの10倍から100倍に達する。トークン消費量が指数関数的に増加するほど、価格が決定的な要素となる。中国モデルのコストパフォーマンスの極致は、まさにこのタイミングを突いている。しかし、推論コストの低減は、訓練の根本的な問題を解決しない。巨大モデルが最新のデータで継続的に訓練・更新されなければ、その能力は急速に衰退する。だが、訓練こそが依然として避けられない計算能力のブラックホールだ。では、その「シャベル」はどこから来るのか?予備のシャベルの正規化-----江蘇省興化市は、かつてAIとは無縁の不锈鋼と健康食品の小都市だった。しかし2025年、国内製の計算能力サーバーの生産ラインがここに建設され、わずか180日で稼働を開始した。この生産ラインの核心は、完全に国産の2つのチップだ。龍芯3C6000プロセッサと太初元碁T100 AIアクセラレータだ。龍芯3C6000は、命令セットからマイクロアーキテクチャまで自主開発された。太初元碁は、国家スーパーコンピュータ無錫センターと清華大学のチームに由来し、異種多核アーキテクチャを採用している。この生産ラインがフル稼働すれば、5分で1台のサーバーが完成する。総投資額は11億元で、年間生産目標は10万台だ。さらに重要なのは、これらの国産チップを用いた万台クラスのクラスターが、実際の大規模モデル訓練の任務をすでに引き受け始めていることだ。2026年1月、智谱AIと華為(ファーウェイ)は、完全に国産チップに依存した最先端画像生成モデル「GLM-Image」を発表した。これは、国内製チップだけで全工程を訓練した初のSOTA画像生成モデルだ。2月には、中国電信の数百億規模の「星辰」大規模モデルが、上海臨港の国内万台計算池上で全工程訓練を完了した。これらの事例の意義は、一つの事実を証明していることだ。国内製チップは、「推論に使える」段階を超え、「訓練に使える」段階へと進化した。これは質的変化だ。推論は既に訓練済みモデルを動かすだけなので、チップの要求は比較的低い。一方、訓練は膨大なデータ処理と複雑な勾配計算、パラメータ更新を伴い、計算能力、通信帯域、ソフトウェアエコシステムの要求は桁違いに高い。これらの任務を担うコアは、華為の昇腾(Ascend)シリーズチップだ。2025年末までに、昇腾エコシステムの開発者数は400万人を突破し、パートナーは3000社以上、43の主要モデルが昇腾上で事前訓練を完了し、200以上のオープンソースモデルも適用済みだ。2026年3月2日のMWCでは、華為は海外市場向けに新世代の計算基盤「SuperPoD」を初公開した。昇腾910BのFP16演算性能は、英偉達A100に匹敵している。差は依然あるものの、使えない状態から使える状態へ、そして使いやすい段階へと進展している。エコシステムの構築は、チップが完璧になるのを待つのではなく、十分な性能に達した段階で大規模に展開し、実際のビジネスニーズを通じてチップとソフトウェアの進化を促す必要がある。字節跳動(バイトダンス)、腾讯(テンセント)、百度(バイドゥ)の国内計算サーバー導入目標は、2026年に前年の倍増を見込む。工信部のデータによると、中国の知能計算規模はすでに1590エクサフロップスに達している。2026年は、国内計算能力の本格的な展開の元年となる。米国の電力危機と中国の海外進出---------2026年初頭、米国のバージニア州では、世界中のデータセンターのトラフィックを支える新規建設の承認が停止された。ジョージア州も追随し、承認停止は2027年まで続く。イリノイ州やミシガン州も制限措置を次々と導入した。国際エネルギー機関のデータによると、2024年の米国のデータセンターの電力消費量は183テラワット時に達し、国内総電力消費の約4%を占める。2030年にはこの数字は倍増し、426TWhに達し、全体の約12%を超える見込みだ。ArmのCEOは、2030年までにAIデータセンターは米国の電力の20%から25%を消費すると予測している。米国の電力網は既に逼迫している。米東部13州をカバーするPJM電力網は6GWの容量不足に直面している。2033年までに、米国全体で175GWの電力容量不足が予想され、これは1.3億世帯の電力需要に相当する。データセンター集中地域の卸電力コストは、5年前と比べて267%高騰している。計算能力の行き詰まりはエネルギーの問題だ。そして、そのエネルギーの観点から見ると、米中の差はチップよりも大きく、ただしその方向性が逆になっている。中国の年間発電量は10.4兆キロワット時で、米国は4.2兆キロワット時。中国は米国の約2.5倍だ。さらに重要なのは、中国の住民の電力消費は総電力のわずか15%に過ぎず、米国は36%を占める。つまり、中国には米国よりもはるかに大きな工業用電力余剰があり、計算能力の構築に投入できる。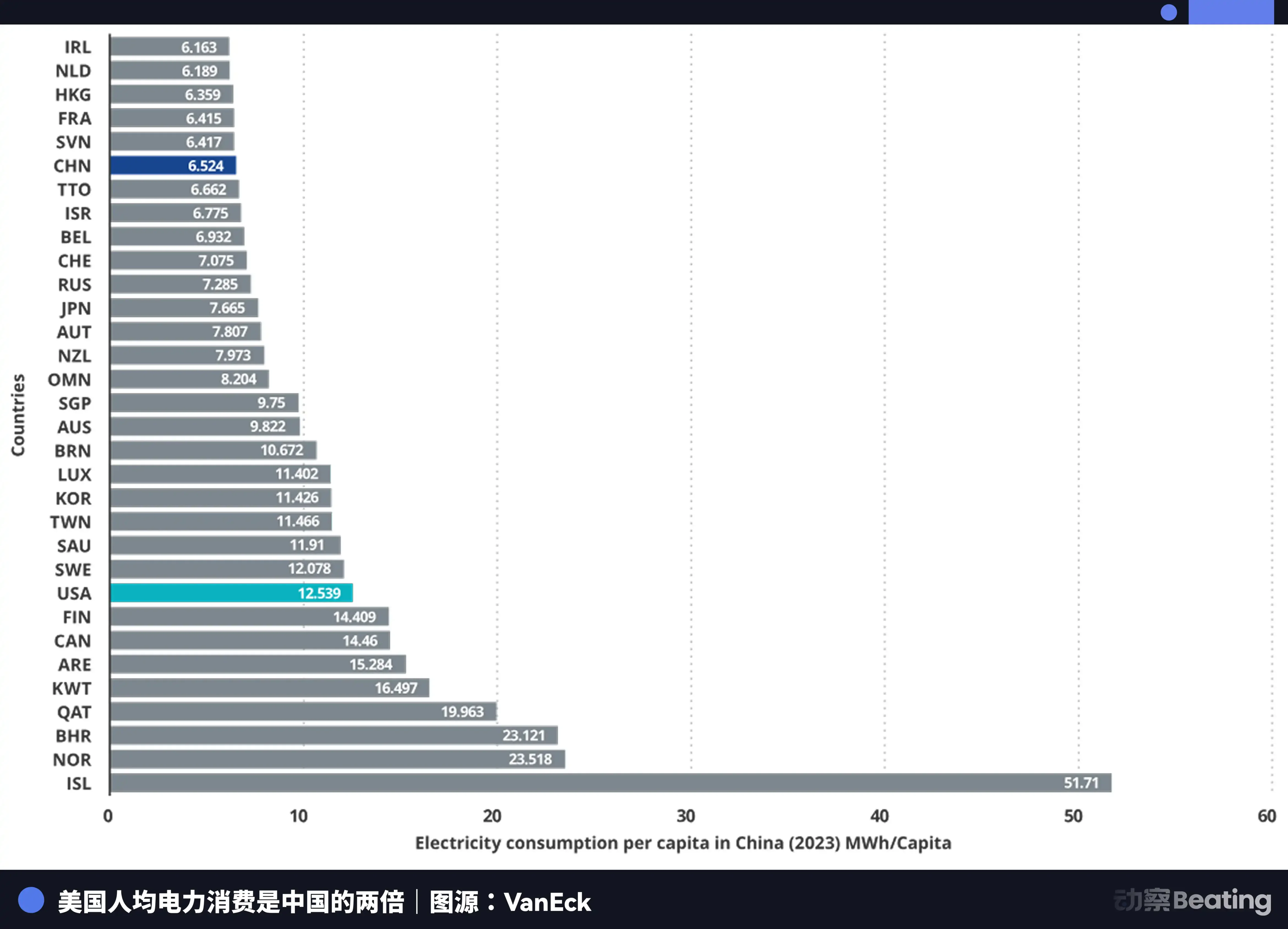電気料金面では、米国のAI企業が集まる地域の電気料金は0.12〜0.15ドル/kWhだが、中国西部の工業用電気料金は約0.03ドルで、米国の4分の1から5分の1程度だ。中国の発電増加量は、すでに米国の7倍に達している。米国が電力不足に苦しむ一方、中国のAIは静かに海外進出を進めている。しかし今回は、製品や工場ではなく、Tokenという新たなデジタル商品を輸出している。Tokenは、AIモデルが情報を処理する最小単位であり、新たなデジタル商品となりつつある。中国の計算工場から生産され、海底光ケーブルを通じて世界に輸送されている。DeepSeekのユーザ分布データは、この現象をよく示している。中国本土が30.7%、インドが13.6%、インドネシアが6.9%、米国が4.3%、フランスが3.2%。37言語をサポートし、ブラジルなど新興市場で人気を博している。世界中で2万6000社以上がアカウントを開設し、3,200の機関が企業版を展開している。2025年には、新規AIスタートアップの58%がDeepSeekを技術スタックに採用した。中国では、DeepSeekが市場シェアの89%を占めている。一方、制裁対象国では、市場シェアは40%〜60%の範囲だ。この光景は、40年前の産業自主権を巡る戦争を彷彿とさせる。1986年の東京では、米国の強い圧力のもと、日本政府は「米日半導体協定」を締結した。協定の主要条項は三つ:日本の半導体市場を開放し、米国チップの市場シェアを20%以上にすること、日本半導体の低価格輸出を禁じること、3億ドルの米国向け半導体に対し100%の関税を課すことだった。同時に、富士通の仙童半導体買収も米国は否決した。その年、日本の半導体産業は絶頂期だった。1988年には、世界の半導体市場の51%を日本が占め、米国は36.8%だった。世界のトップ10半導体企業のうち、日本企業が六席を占めていた。NECは2位、東芝3位、日立5位、富士通7位、三菱8位、松下9位。1985年、Intelは米日半導体争奪戦で1.73億ドルの損失を出し、危機的状況にあった。しかし、協定締結後、すべてが変わった。米国は301調査などを通じて、日本半導体企業に対し全面的な圧力をかけ、韓国のサムスンやハイニックスを支援し、より低価格で市場に攻め込んだ。日本のDRAMシェアは80%から10%にまで低下し、2017年にはわずか7%にまで縮小した。かつて絶対的だった巨頭たちは、分割、買収、あるいは無限の赤字の中で静かに退場していった。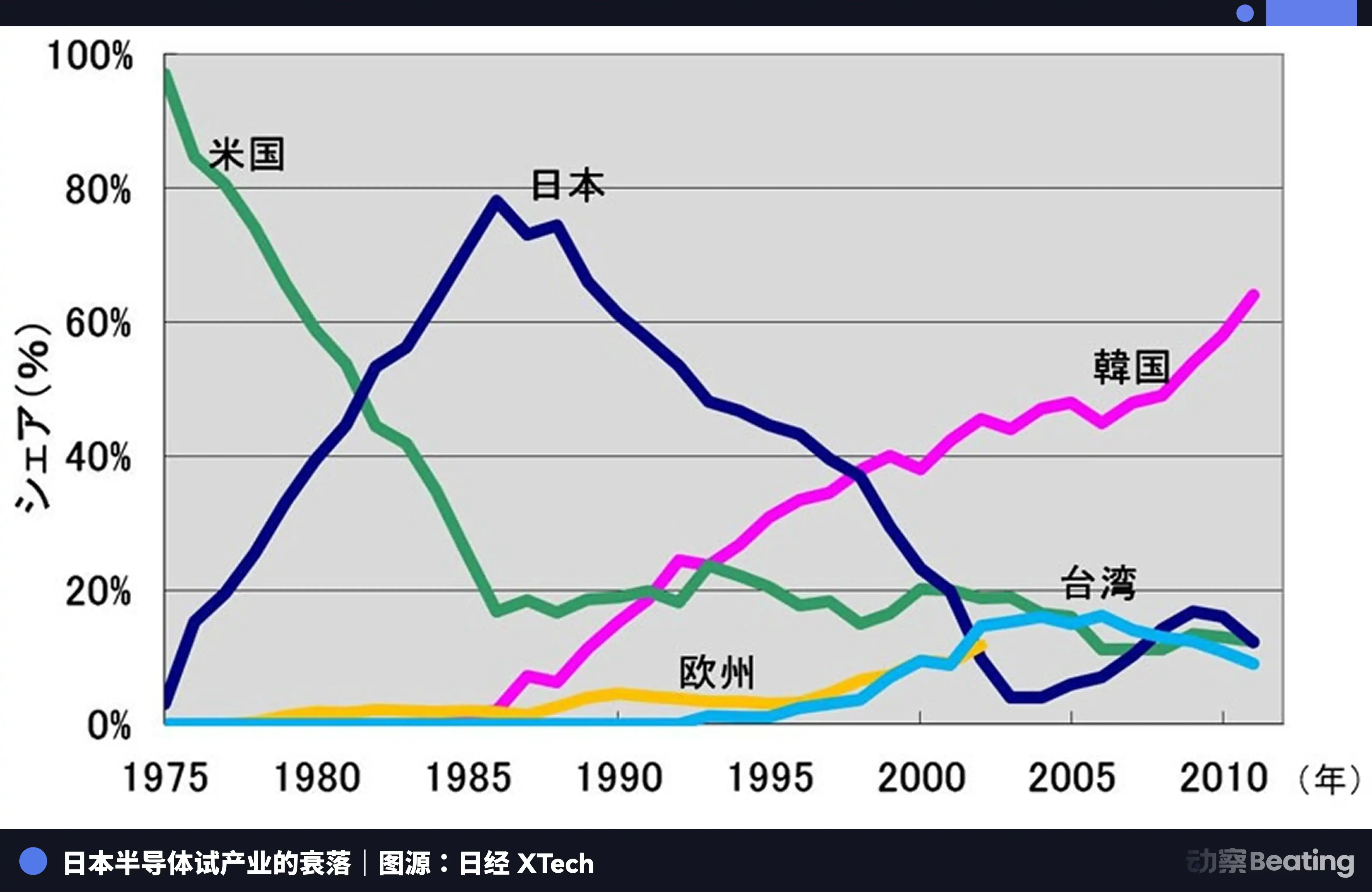日本半導体の悲劇は、外部の一つの力に支配されたグローバル分業体制の中で、最も優れた生産者としての役割に満足し、自らの独立したエコシステムを築くことを怠ったことにある。潮が引いたとき、彼らは気づく。生産以外に何も持たないことに。今の中国AI産業も、似て非なる道の入り口に立っている。似ている点は、外部からの巨大な圧力に直面していることだ。三度のチップ規制、段階的に強化される中、CUDAエコシステムの壁は依然高い。異なる点は、今回はより困難な道を選んだことだ。アルゴリズムの極致的な最適化から、国内チップの推論から訓練への跨ぎ、昇腾エコシステムの400万人の開発者の蓄積、Tokenの海外展開によるグローバル市場への浸透。これらすべての一歩一歩が、日本がかつて持たなかった独立した産業エコシステムの構築に向かっている。エピローグ--2026年2月27日、国内AIチップ企業の業績速報が同時に発表された。寒武紀(Cambricon)は、売上高が453%増加し、初の年間黒字を達成。摩尔(Moore)スレッドは、売上243%増だが、純損失は10億ドル。沐曦(Muxi)は、売上121%増、純損失は約8億ドル。半分は火焔、半分は海水。火焔は、市場の極度の飢えだ。黄仁勋が空白の95%を埋めるべく、これらの国内企業の売上が一つ一つ積み重なっている。性能やエコシステムの如何に関わらず、市場は英偉達以外の第二の選択肢を求めている。これは地政学的な裂け目から生まれた、千載一遇の構造的チャンスだ。海水は、エコシステム構築の巨大なコストだ。すべての赤字は、CUDAエコシステムに追いつくための真金だ。研究開発投資、ソフトウェア補助、顧客現場に派遣されて問題を解決するエンジニアの人件費。これらの赤字は、経営不振ではなく、独立したエコシステムを築くための戦争税だ。これらの三つの財務報告は、いずれもこの計算能力戦争の真実を最も誠実に記録している。それは、勝利の歌ではなく、血を流しながら前進する激戦の陣地戦だ。しかし、戦争の様相はすでに変わった。八年前は、「生き残れるかどうか」が議論の中心だったが、今や、「生き残るためにどれだけの代償を払うか」が焦点だ。代償そのものが、進歩である。

中国のAI計算能力を巡る反撃戦
代償そのものが進歩である。
執筆:Sleepy.txt
八年前、中興の心臓停止。
2018年4月16日、米国商務省産業安全局の禁令により、中興通信は8万人の従業員と千億超の年間売上高を誇る世界第4位の通信機器メーカーでありながら、一夜にして操業停止に追い込まれた。禁令の内容は非常に単純で、今後7年間、米国企業から中興に対して部品、商品、ソフトウェア、技術の販売を禁じるというものだった。
クアルコムのチップがなくなり、基地局の生産停止。GoogleのAndroid認証も得られず、スマートフォンも使えるシステムがなくなる。23日後、中興は公告を出し、主要な事業活動が行えなくなったと発表した。
しかし中興は最終的に生き延びたが、その代償は14億ドルだった。
10億ドルの罰金を一括支払い、4億ドルの保証金を米国の銀行の管理口座に預け入れた。さらに、全役員の交代と米国側のコンプライアンス監督チームの進入を受け入れた。2018年通年で、中興は70億元の純損失を計上し、売上高は前年同期比21.4%減少した。
当時の中興董事長殷一民は内部文書でこう記している:「我々は複雑で、グローバルサプライチェーンに高度に依存する産業に身を置いている。」この言葉は、当時の反省とともに、無力感も漂わせていた。
八年後、2026年2月26日、中国のAIユニコーンDeepSeekは、今後リリース予定のV4多モーダル大規模モデルが、国内チップメーカーとの深い協力を優先し、事前学習から微調整までの全工程を英偉達(NVIDIA)を使わずに実現する初の試みを発表した。
翻訳すれば:私たちは英偉達を使わなくなる。
このニュースが出ると、市場の第一反応は疑問だった。英偉達は世界のAI訓練用チップ市場の90%以上のシェアを持つ。これを放棄するのは商業的に合理的なのか?
しかしDeepSeekの選択の背後には、商業ロジックを超えた大きな問題が潜んでいる。中国のAIは、いったいどのような計算能力の独立を必要としているのか?
何が足枷になっているのか
多くの人は、チップの禁輸措置はハードウェアの問題だと考えている。しかし、中国のAI企業を窒息させている本当の原因は、「CUDA」というものにある。
CUDA(Compute Unified Device Architecture)は、英偉達が2006年に導入した並列計算プラットフォーム兼プログラミングモデルだ。これにより、開発者は英偉達GPUの計算能力を直接呼び出し、さまざまな複雑な計算タスクを高速化できる。
AI時代が到来する前は、これは一部の極少数の技術者だけのツールだった。しかし、深層学習の波が押し寄せると、CUDAはAI産業の基盤となった。
AI大規模モデルの訓練は本質的に膨大な行列演算であり、これはGPUが最も得意とする作業だ。
英偉達は、十数年の先行投資を背景に、CUDAを用いて世界中のAI開発者向けにハードウェアからアプリケーションまでの一連のツールチェーンを構築してきた。今日、GoogleのTensorFlowやMetaのPyTorchをはじめとする主要なAIフレームワークは、底層でCUDAと深く結びついている。
AI専門の博士課程の学生は、入学初日からCUDA環境の中で学び、プログラミングし、実験を行う。彼らが書くコードの一行一行が、英偉達の護城河を強化している。
2025年までに、CUDAエコシステムには450万人以上の開発者が参加し、3000以上のGPU加速アプリケーションをカバーし、世界中の企業4万社以上が利用している。この数字は、世界のAI開発者の90%以上が英偉達のエコシステムに縛られていることを意味する。
CUDAの恐ろしさは、それが一つの飛輪のような存在であることだ。使えば使うほど、ツールやライブラリ、コードが増え、エコシステムは繁栄し、さらに多くの開発者を惹きつける。この循環が一度回り出すと、ほぼ止められなくなる。
結果として、英偉達は最も高価なシャベルを売りつつ、唯一のマイニング姿勢も定義している。別のシャベルに換えたい?可能だ。しかし、そのためには過去十数年にわたり、世界中の最も賢い頭脳たちがこの姿勢の下で蓄積した経験、ツール、コードをすべて書き直さなければならない。
そのコストを誰が負担するのか?
だから、2022年10月7日に第一弾の規制が実施され、英偉達のA100とH100の中国向け輸出が制限されたとき、中国のAI企業は初めて中興式の窒息感を味わった。その後、英偉達は「中国向け特供版」A800とH800をリリースし、チップ間の通信帯域を縮小して供給を維持した。
しかしわずか1年後の2023年10月17日、第二弾の規制が再び強化され、A800とH800も禁じられ、13の中国企業がエンティティリストに載せられた。英偉達はさらに制限を加え、H20の出荷も厳格化した。2024年12月、バイデン政権の任期内最後の規制が実施され、H20の輸出も厳しく制限された。
三度の規制、段階的に強化。
しかし今回は、当時の中興とは全く異なる展開となった。
非対称的な突破戦
禁令の下、多くは中国のAI大規模モデルの夢は終わったと考えた。
しかし彼らは間違っていた。封鎖に直面しても、中国企業は正面からの激突を選ばず、突破の道を模索し始めた。その最初の戦場は、チップではなくアルゴリズムだった。
2024年末から2025年にかけて、中国のAI企業は一斉に「ハイブリッドエキスパートモデル」へと方向転換した。
これは、巨大なモデルを複数の小さなエキスパートに分割し、タスク処理時には最も関連性の高いエキスパートだけを活性化させ、全体を動かさないという手法だ。
DeepSeekのV3はこの思考の典型例だ。パラメータは6710億個だが、推論時にはそのうちの370億だけを活性化し、全体のわずか5.5%を使用している。訓練コストは2048台の英偉達H800 GPUを用い、58日間で訓練し、総費用は557.6万ドル。対して、外部推定によるとGPT-4の訓練コストは約7800万ドルとされる。桁違いの差だ。
アルゴリズムの極致的な最適化は、価格に直結している。DeepSeekのAPI価格は、入力1百万トークンあたり0.028ドルから0.28ドル、出力は0.42ドル。一方、GPT-4oは入力5ドル、出力15ドル。Claude Opusはさらに高く、入力15ドル、出力75ドルだ。換算すると、DeepSeekはClaudeの25倍から75倍安い。
この価格差は、世界の開発者市場に大きな反響を呼んでいる。2026年2月、世界最大のAIモデルAPI集約プラットフォーム「OpenRouter」では、中国AIモデルの週次呼び出し回数が3週間で127%増加し、初めて米国を超えた。一年前はシェアは2%未満だったが、今や約60%に迫る勢いだ。
この背後には、見落とされがちな構造的変化がある。2025年後半から、AIの主流シナリオはチャットからエージェントへと移行しつつある。エージェントシナリオでは、一つのタスクにかかるトークン消費量は、単純なチャットの10倍から100倍に達する。トークン消費量が指数関数的に増加するほど、価格が決定的な要素となる。中国モデルのコストパフォーマンスの極致は、まさにこのタイミングを突いている。
しかし、推論コストの低減は、訓練の根本的な問題を解決しない。巨大モデルが最新のデータで継続的に訓練・更新されなければ、その能力は急速に衰退する。だが、訓練こそが依然として避けられない計算能力のブラックホールだ。
では、その「シャベル」はどこから来るのか?
予備のシャベルの正規化
江蘇省興化市は、かつてAIとは無縁の不锈鋼と健康食品の小都市だった。しかし2025年、国内製の計算能力サーバーの生産ラインがここに建設され、わずか180日で稼働を開始した。
この生産ラインの核心は、完全に国産の2つのチップだ。龍芯3C6000プロセッサと太初元碁T100 AIアクセラレータだ。龍芯3C6000は、命令セットからマイクロアーキテクチャまで自主開発された。太初元碁は、国家スーパーコンピュータ無錫センターと清華大学のチームに由来し、異種多核アーキテクチャを採用している。
この生産ラインがフル稼働すれば、5分で1台のサーバーが完成する。総投資額は11億元で、年間生産目標は10万台だ。
さらに重要なのは、これらの国産チップを用いた万台クラスのクラスターが、実際の大規模モデル訓練の任務をすでに引き受け始めていることだ。
2026年1月、智谱AIと華為(ファーウェイ)は、完全に国産チップに依存した最先端画像生成モデル「GLM-Image」を発表した。これは、国内製チップだけで全工程を訓練した初のSOTA画像生成モデルだ。2月には、中国電信の数百億規模の「星辰」大規模モデルが、上海臨港の国内万台計算池上で全工程訓練を完了した。
これらの事例の意義は、一つの事実を証明していることだ。国内製チップは、「推論に使える」段階を超え、「訓練に使える」段階へと進化した。これは質的変化だ。推論は既に訓練済みモデルを動かすだけなので、チップの要求は比較的低い。一方、訓練は膨大なデータ処理と複雑な勾配計算、パラメータ更新を伴い、計算能力、通信帯域、ソフトウェアエコシステムの要求は桁違いに高い。
これらの任務を担うコアは、華為の昇腾(Ascend)シリーズチップだ。2025年末までに、昇腾エコシステムの開発者数は400万人を突破し、パートナーは3000社以上、43の主要モデルが昇腾上で事前訓練を完了し、200以上のオープンソースモデルも適用済みだ。2026年3月2日のMWCでは、華為は海外市場向けに新世代の計算基盤「SuperPoD」を初公開した。
昇腾910BのFP16演算性能は、英偉達A100に匹敵している。差は依然あるものの、使えない状態から使える状態へ、そして使いやすい段階へと進展している。エコシステムの構築は、チップが完璧になるのを待つのではなく、十分な性能に達した段階で大規模に展開し、実際のビジネスニーズを通じてチップとソフトウェアの進化を促す必要がある。字節跳動(バイトダンス)、腾讯(テンセント)、百度(バイドゥ)の国内計算サーバー導入目標は、2026年に前年の倍増を見込む。工信部のデータによると、中国の知能計算規模はすでに1590エクサフロップスに達している。2026年は、国内計算能力の本格的な展開の元年となる。
米国の電力危機と中国の海外進出
2026年初頭、米国のバージニア州では、世界中のデータセンターのトラフィックを支える新規建設の承認が停止された。ジョージア州も追随し、承認停止は2027年まで続く。イリノイ州やミシガン州も制限措置を次々と導入した。
国際エネルギー機関のデータによると、2024年の米国のデータセンターの電力消費量は183テラワット時に達し、国内総電力消費の約4%を占める。2030年にはこの数字は倍増し、426TWhに達し、全体の約12%を超える見込みだ。ArmのCEOは、2030年までにAIデータセンターは米国の電力の20%から25%を消費すると予測している。
米国の電力網は既に逼迫している。米東部13州をカバーするPJM電力網は6GWの容量不足に直面している。2033年までに、米国全体で175GWの電力容量不足が予想され、これは1.3億世帯の電力需要に相当する。データセンター集中地域の卸電力コストは、5年前と比べて267%高騰している。
計算能力の行き詰まりはエネルギーの問題だ。そして、そのエネルギーの観点から見ると、米中の差はチップよりも大きく、ただしその方向性が逆になっている。
中国の年間発電量は10.4兆キロワット時で、米国は4.2兆キロワット時。中国は米国の約2.5倍だ。さらに重要なのは、中国の住民の電力消費は総電力のわずか15%に過ぎず、米国は36%を占める。つまり、中国には米国よりもはるかに大きな工業用電力余剰があり、計算能力の構築に投入できる。
電気料金面では、米国のAI企業が集まる地域の電気料金は0.12〜0.15ドル/kWhだが、中国西部の工業用電気料金は約0.03ドルで、米国の4分の1から5分の1程度だ。
中国の発電増加量は、すでに米国の7倍に達している。
米国が電力不足に苦しむ一方、中国のAIは静かに海外進出を進めている。しかし今回は、製品や工場ではなく、Tokenという新たなデジタル商品を輸出している。
Tokenは、AIモデルが情報を処理する最小単位であり、新たなデジタル商品となりつつある。中国の計算工場から生産され、海底光ケーブルを通じて世界に輸送されている。
DeepSeekのユーザ分布データは、この現象をよく示している。中国本土が30.7%、インドが13.6%、インドネシアが6.9%、米国が4.3%、フランスが3.2%。37言語をサポートし、ブラジルなど新興市場で人気を博している。世界中で2万6000社以上がアカウントを開設し、3,200の機関が企業版を展開している。
2025年には、新規AIスタートアップの58%がDeepSeekを技術スタックに採用した。中国では、DeepSeekが市場シェアの89%を占めている。一方、制裁対象国では、市場シェアは40%〜60%の範囲だ。
この光景は、40年前の産業自主権を巡る戦争を彷彿とさせる。
1986年の東京では、米国の強い圧力のもと、日本政府は「米日半導体協定」を締結した。協定の主要条項は三つ:日本の半導体市場を開放し、米国チップの市場シェアを20%以上にすること、日本半導体の低価格輸出を禁じること、3億ドルの米国向け半導体に対し100%の関税を課すことだった。同時に、富士通の仙童半導体買収も米国は否決した。
その年、日本の半導体産業は絶頂期だった。1988年には、世界の半導体市場の51%を日本が占め、米国は36.8%だった。世界のトップ10半導体企業のうち、日本企業が六席を占めていた。NECは2位、東芝3位、日立5位、富士通7位、三菱8位、松下9位。1985年、Intelは米日半導体争奪戦で1.73億ドルの損失を出し、危機的状況にあった。
しかし、協定締結後、すべてが変わった。
米国は301調査などを通じて、日本半導体企業に対し全面的な圧力をかけ、韓国のサムスンやハイニックスを支援し、より低価格で市場に攻め込んだ。日本のDRAMシェアは80%から10%にまで低下し、2017年にはわずか7%にまで縮小した。かつて絶対的だった巨頭たちは、分割、買収、あるいは無限の赤字の中で静かに退場していった。
日本半導体の悲劇は、外部の一つの力に支配されたグローバル分業体制の中で、最も優れた生産者としての役割に満足し、自らの独立したエコシステムを築くことを怠ったことにある。潮が引いたとき、彼らは気づく。生産以外に何も持たないことに。
今の中国AI産業も、似て非なる道の入り口に立っている。
似ている点は、外部からの巨大な圧力に直面していることだ。三度のチップ規制、段階的に強化される中、CUDAエコシステムの壁は依然高い。
異なる点は、今回はより困難な道を選んだことだ。アルゴリズムの極致的な最適化から、国内チップの推論から訓練への跨ぎ、昇腾エコシステムの400万人の開発者の蓄積、Tokenの海外展開によるグローバル市場への浸透。これらすべての一歩一歩が、日本がかつて持たなかった独立した産業エコシステムの構築に向かっている。
エピローグ
2026年2月27日、国内AIチップ企業の業績速報が同時に発表された。
寒武紀(Cambricon)は、売上高が453%増加し、初の年間黒字を達成。摩尔(Moore)スレッドは、売上243%増だが、純損失は10億ドル。沐曦(Muxi)は、売上121%増、純損失は約8億ドル。
半分は火焔、半分は海水。
火焔は、市場の極度の飢えだ。黄仁勋が空白の95%を埋めるべく、これらの国内企業の売上が一つ一つ積み重なっている。性能やエコシステムの如何に関わらず、市場は英偉達以外の第二の選択肢を求めている。これは地政学的な裂け目から生まれた、千載一遇の構造的チャンスだ。
海水は、エコシステム構築の巨大なコストだ。すべての赤字は、CUDAエコシステムに追いつくための真金だ。研究開発投資、ソフトウェア補助、顧客現場に派遣されて問題を解決するエンジニアの人件費。これらの赤字は、経営不振ではなく、独立したエコシステムを築くための戦争税だ。
これらの三つの財務報告は、いずれもこの計算能力戦争の真実を最も誠実に記録している。それは、勝利の歌ではなく、血を流しながら前進する激戦の陣地戦だ。
しかし、戦争の様相はすでに変わった。八年前は、「生き残れるかどうか」が議論の中心だったが、今や、「生き残るためにどれだけの代償を払うか」が焦点だ。
代償そのものが、進歩である。