原文作者:深潮 TechFlowGoogleの「AIメモリ使用量を1/6に圧縮する」と称する論文が先週公開され、これによりMicron、SanDiskなど世界のストレージ半導体株の時価総額が900億ドル超にわたって蒸発する事態を引き起こしました。しかし、論文が発表されてからわずか2日後、アルゴリズムが「圧倒した」とされる対比対象――チューリッヒ連邦工科大学の博士研究員高健扬が1万字に及ぶ公開書簡を発表し、Googleチームが実験でシングルコアCPUのPythonスクリプトを用いて対戦相手をテストした一方、自分たちはA100 GPUでテストしていたこと、さらに投稿前に問題を指摘されていたにもかかわらず修正を拒否したことを告発しました。知乎の閲覧数は急速に400万を突破し、スタンフォードNLPの公式アカウントがリポストし、学術界と市場の双方に衝撃を与えました。この論争の核心的な問題は、それほど複雑ではありません。Google公式が大規模に直接宣伝した、世界的な半導体セクターにパニック的な売りを引き起こしたAIのトップ会議論文が、既に公表された先行研究を体系的に歪曲していないか。そして、わざと不公平な実験を作り出すことで、虚偽の性能優位の物語を形成したのかどうかです。**TurboQuantは何をしたのか:AIの「下書き用紙」を元の6分の1に薄くする**-----------------------------------------大規模言語モデルが回答を生成する際には、一方で書きながら、過去に計算した内容を振り返って確認する必要があります。これらの中間結果は一時的にGPUメモリ(映像メモリ)に保存され、業界では「KVキャッシュ」(キー・バリューキャッシュ)と呼ばれます。対話が長くなるほど、この「下書き用紙」は厚くなり、メモリ消費も増え、コストも高くなります。Google研究チームが開発したTurboQuantアルゴリズムの核心的なセールスポイントは、この下書き用紙を元の1/6に圧縮しつつ、精度の損失はゼロ、推論速度は最大8倍向上すると謳っている点です。論文は2025年4月に学術プレプリントプラットフォームarXivで初めて公開され、2026年1月にAI分野のトップ会議ICLR 2026に採択され、3月24日にGoogle公式ブログで再パッケージ化して宣伝されました。技術的には、TurboQuantのアイデアは簡単に理解できます。まず、数学的変換を用いて乱雑なデータを「洗い出し」、次に事前に計算した最適な圧縮表を用いて一つずつ圧縮し、最後に1ビットの誤り訂正メカニズムで圧縮による計算偏差を修正する、というものです。コミュニティによる独立実装も圧縮効果がほぼ事実であることを検証しており、アルゴリズムの数理的貢献も実在します。議論の焦点は、TurboQuantが使えるかどうかではなく、Googleが「競合より圧倒的に優れている」ことを証明するために何をしたのかにあります。**高健扬の公開書簡:三つの指摘、いずれも核心を突く**----------------------3月27日夜10時、高健扬は知乎に長文を投稿し、同時にICLR公式の査読プラットフォームOpenReviewに正式なコメントを提出しました。高健扬はRaBitQアルゴリズムの第一著者であり、同アルゴリズムは2024年にデータベース分野のトップ会議SIGMODで発表されたものです。扱っているのは同種の問題――高次元ベクトルの効率的な圧縮です。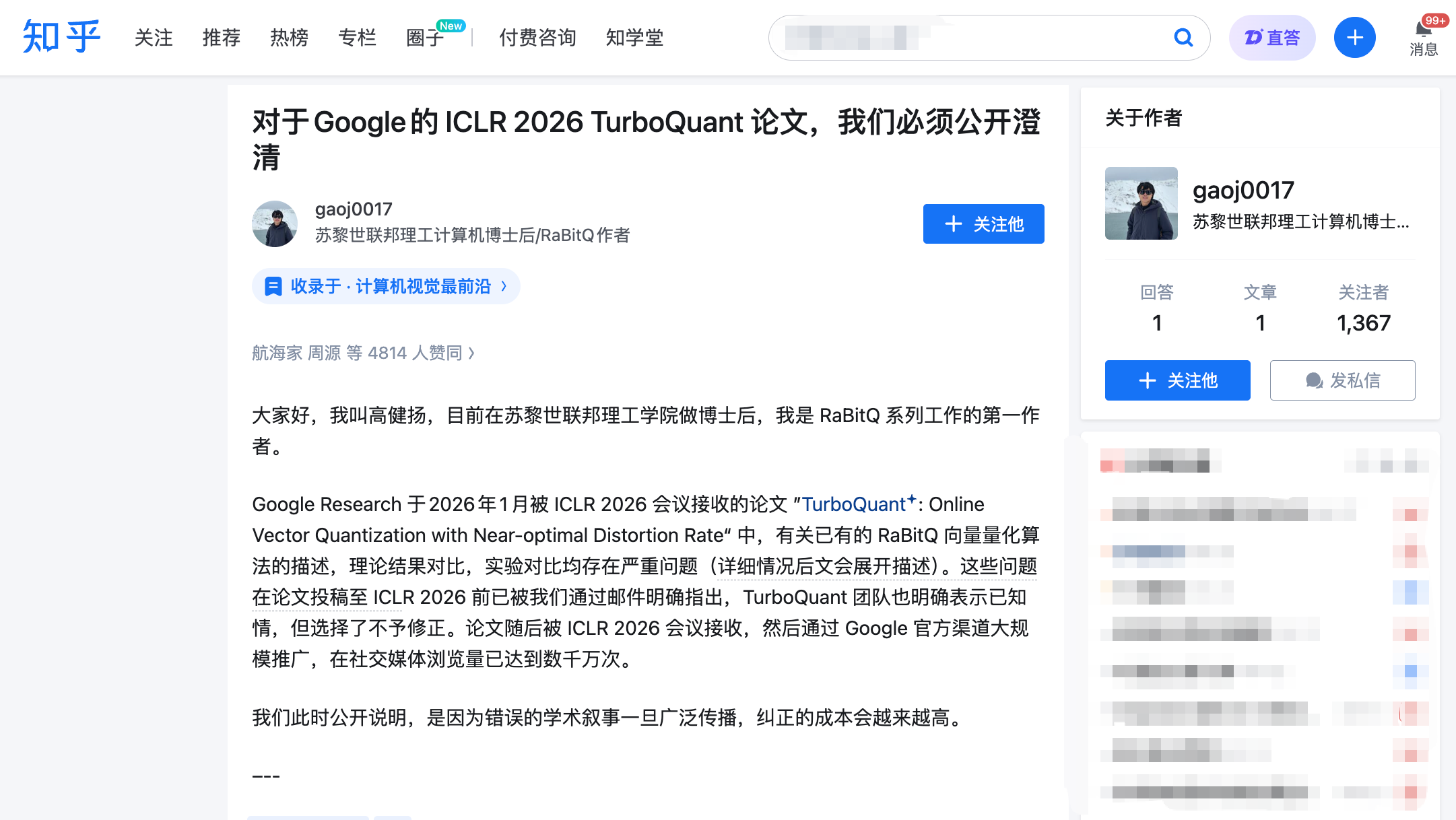彼の指摘は3つで、それぞれメール記録とタイムラインによる裏付けがあります。### **指摘1:他人の核心的手法を使ったのに、全文では一切触れない。**TurboQuantとRaBitQの技術的な核心には、重要な共通ステップがあります。それは、圧縮前にまずデータに「ランダム回転」を行うことです。この操作の目的は、もともと分布が不規則だったデータを予測可能な一様分布に変換し、圧縮の難易度を大きく下げることです。これは両アルゴリズムの最も核心的で近い部分です。TurboQuantの著者自身も査読への返信の中でこの点を認めていますが、論文本文の中で、この方法とRaBitQとの関係について正面から説明したことは一度もありません。さらに重要な背景は次の通りです。TurboQuantの第2著者Majid Daliriは2025年1月に自ら高健扬チームに連絡し、RaBitQのソースコードをベースに書き換えたPythonバージョンのデバッグを手伝ってほしいと依頼してきました。メールには再現手順とエラー情報が詳細に記されていました。言い換えれば、TurboQuantチームはRaBitQの技術的詳細を非常に熟知していたのです。ICLRの匿名査読者の一人も、両者が同じ技術を使っていることを指摘し、十分な議論を求めました。しかし最終版の論文では、TurboQuantチームは追加の議論を行わず、本文中にあった(すでに不完全な)RaBitQの記述を付録に移してしまいました。### **指摘2:根拠のないまま、相手の理論を「サブ最適」と称した。**TurboQuantの論文はRaBitQに「理論的にサブ最適(suboptimal)」と直接ラベル付けし、その理由としてRaBitQの数学的分析が「やや粗い」ことを挙げています。しかし高健扬は、RaBitQの拡張版論文はすでに、圧縮誤差が数学的に最適な境界に到達することを厳密に証明していると指摘しました。この結論は理論計算機科学のトップ会議で発表されています。2025年5月、高健扬チームは複数回のメールでRaBitQの理論的最適性について詳細に説明していました。TurboQuantの第2著者Daliriも、全著者に伝えたことを確認しています。しかし、それにもかかわらず、最終的な論文では「サブ最適」という表現が残り、反論の根拠は何も示されませんでした。### **指摘3:実験比較において「左手は縛り、右手は刀を持たせる」状態。**これは本文中で最も破壊力のある指摘です。高健扬は、TurboQuantの論文が速度比較の実験で、2つの不公平な条件を重ねていたと指摘しています。第一に、RaBitQの公式が最適化されたC++コード(デフォルトでマルチスレッド対応)を提供していたにもかかわらず、TurboQuantチームはそれを使わず、自分たちが翻訳したPythonバージョンでRaBitQをテストしました。第二に、RaBitQのテストではシングルコアCPUかつマルチスレッドをオフにしており、TurboQuantはNVIDIA A100 GPUを用いていました。この2つの条件を重ねた結果、読者が目にする結論は「RaBitQはTurboQuantより数桁遅い」というものになりますが、その前提としてGoogleチームが相手を縛り上げてレースをさせたことを、読者は知るすべがありません。論文では、これら実験条件の差異が十分に開示されていなかったのです。**Googleの回答:「ランダム回転は汎用技術であり、毎回引用できるわけではない」**-----------------------------高健扬の公開によれば、TurboQuantチームは2026年3月のメール返信の中で次のように述べました。「ランダム回転とJohnson-Lindenstrauss変換の使用はこの分野の標準技術であり、これらの方法を使ったすべての論文を引用することはできません。」高健扬チームは、それは概念のすり替えだと考えています。問題は、RaBitQがまったく同じ問題設定の下で、この方法をベクトル圧縮と結び付け、さらに最適性を証明した最初の仕事である点にあります。TurboQuant論文は、両者の関係を正確に記述すべきだったのです。スタンフォードNLPグループの公式Xアカウントは高健扬の声明をリツイートしました。高健扬チームはすでにICLRのOpenReviewプラットフォーム上で公開コメントを出し、ICLR大会の議長および倫理委員会に正式に申し立てを行っています。今後、arXivに詳細な技術レポートも公開予定です。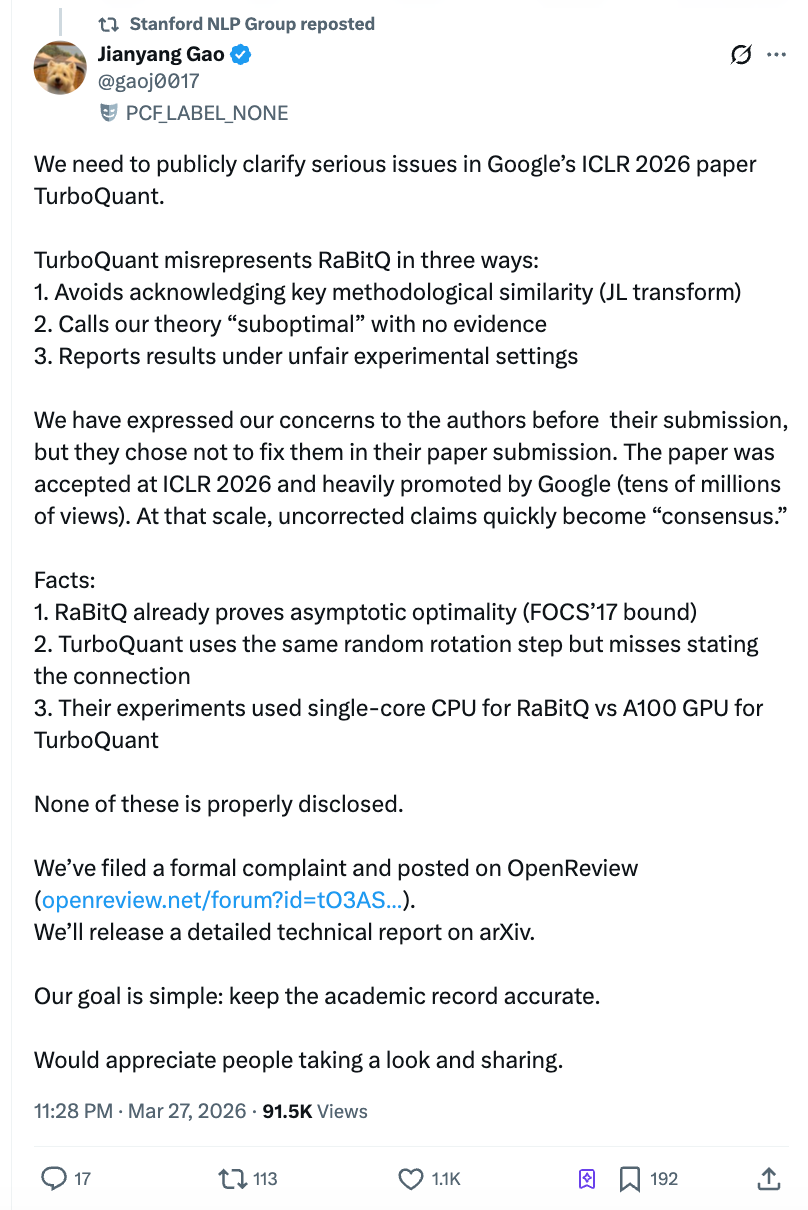独立系の技術ブロガーDario Salvatiは、分析の中で比較的中立的な評価を示しました。TurboQuantは数学的手法において確かに実質的な貢献があるものの、RaBitQとの関係は論文の記述よりもはるかに密接である、と指摘しています。**900億ドルの時価総額蒸発:論文論争と市場のパニックの重なり**--------------------------この学術的な論争が起きたタイミングは非常に微妙です。Googleは3月24日に公式ブログでTurboQuantを発表した後、世界のストレージ半導体セクターは猛烈な売りに見舞われました。CNBCなど複数のメディアによると、Micronは6営業日連続で下落し、累計下落率は20%超。SanDiskは1日で11%下落。韓国のSKハイニックス(SK hynix)は約6%下げ、Samsung Electronicsは約5%下げ、日本のKioxia(铠侠)は約6%下げました。市場のパニックのロジックは単純で乱暴です。ソフトウェアによる圧縮でAIの推論メモリ需要が6倍に低下し、ストレージ半導体の需要見通しが構造的に下方修正される、というものです。モルガン・スタンレーのアナリストJoseph Mooreは3月26日のリサーチノートで、このロジックに反論し、MicronとSanDiskの「買い増し(増持)」評価を維持しました。Mooreは、TurboQuantが圧縮しているのはKVキャッシュという特定タイプのキャッシュであり、メモリ全体の使用量ではないと指摘し、それを「通常の生産性向上(正常な生産率改善)」と位置付けました。ウェルズ・ファーゴのアナリストAndrew Rochaも、ジェボンズの逆説(効率化はむしろ需要を押し上げる)を引き合いに出し、効率向上によりコストが下がれば、より大規模なAI展開が促進され、結果的にメモリ需要が押し上げられる可能性があると述べました。**旧論文、新パッケージ:AI研究から市場の語りへの伝導リスク**----------------------------技術ブロガーBen Pouladianの分析によると、TurboQuantの論文は2025年4月に既に公開されており、新たな研究ではありません。3月24日にGoogleが公式ブログで再パッケージして宣伝した一方、市場はそれを新たなブレークスルーとして価格付けしました。この「旧論文、新公開」の戦略は、論文中に潜む実験バイアスと重なり、AI研究が学術論文から市場の語りへと伝わる伝導チェーンにおける体系的なリスクを映し出しています。AIインフラへの投資家にとって、ある論文が「数桁」の性能向上を主張する場合、まず確認すべきは、そのベンチマーク比較の条件が公平かどうかです。高健扬チームは、問題の正式な解決を引き続き推進すると明言しています。Google側は、公開書簡に対する具体的な指摘について、現時点では正式な回答を出していません。
GoogleのAI論文が崩壊、900億ドルのストレージ株を失い、実験の捏造が指摘される
原文作者:深潮 TechFlow
Googleの「AIメモリ使用量を1/6に圧縮する」と称する論文が先週公開され、これによりMicron、SanDiskなど世界のストレージ半導体株の時価総額が900億ドル超にわたって蒸発する事態を引き起こしました。
しかし、論文が発表されてからわずか2日後、アルゴリズムが「圧倒した」とされる対比対象――チューリッヒ連邦工科大学の博士研究員高健扬が1万字に及ぶ公開書簡を発表し、Googleチームが実験でシングルコアCPUのPythonスクリプトを用いて対戦相手をテストした一方、自分たちはA100 GPUでテストしていたこと、さらに投稿前に問題を指摘されていたにもかかわらず修正を拒否したことを告発しました。知乎の閲覧数は急速に400万を突破し、スタンフォードNLPの公式アカウントがリポストし、学術界と市場の双方に衝撃を与えました。
この論争の核心的な問題は、それほど複雑ではありません。Google公式が大規模に直接宣伝した、世界的な半導体セクターにパニック的な売りを引き起こしたAIのトップ会議論文が、既に公表された先行研究を体系的に歪曲していないか。そして、わざと不公平な実験を作り出すことで、虚偽の性能優位の物語を形成したのかどうかです。
TurboQuantは何をしたのか:AIの「下書き用紙」を元の6分の1に薄くする
大規模言語モデルが回答を生成する際には、一方で書きながら、過去に計算した内容を振り返って確認する必要があります。これらの中間結果は一時的にGPUメモリ(映像メモリ)に保存され、業界では「KVキャッシュ」(キー・バリューキャッシュ)と呼ばれます。対話が長くなるほど、この「下書き用紙」は厚くなり、メモリ消費も増え、コストも高くなります。
Google研究チームが開発したTurboQuantアルゴリズムの核心的なセールスポイントは、この下書き用紙を元の1/6に圧縮しつつ、精度の損失はゼロ、推論速度は最大8倍向上すると謳っている点です。論文は2025年4月に学術プレプリントプラットフォームarXivで初めて公開され、2026年1月にAI分野のトップ会議ICLR 2026に採択され、3月24日にGoogle公式ブログで再パッケージ化して宣伝されました。
技術的には、TurboQuantのアイデアは簡単に理解できます。まず、数学的変換を用いて乱雑なデータを「洗い出し」、次に事前に計算した最適な圧縮表を用いて一つずつ圧縮し、最後に1ビットの誤り訂正メカニズムで圧縮による計算偏差を修正する、というものです。コミュニティによる独立実装も圧縮効果がほぼ事実であることを検証しており、アルゴリズムの数理的貢献も実在します。
議論の焦点は、TurboQuantが使えるかどうかではなく、Googleが「競合より圧倒的に優れている」ことを証明するために何をしたのかにあります。
高健扬の公開書簡:三つの指摘、いずれも核心を突く
3月27日夜10時、高健扬は知乎に長文を投稿し、同時にICLR公式の査読プラットフォームOpenReviewに正式なコメントを提出しました。高健扬はRaBitQアルゴリズムの第一著者であり、同アルゴリズムは2024年にデータベース分野のトップ会議SIGMODで発表されたものです。扱っているのは同種の問題――高次元ベクトルの効率的な圧縮です。
彼の指摘は3つで、それぞれメール記録とタイムラインによる裏付けがあります。
指摘1:他人の核心的手法を使ったのに、全文では一切触れない。
TurboQuantとRaBitQの技術的な核心には、重要な共通ステップがあります。それは、圧縮前にまずデータに「ランダム回転」を行うことです。この操作の目的は、もともと分布が不規則だったデータを予測可能な一様分布に変換し、圧縮の難易度を大きく下げることです。これは両アルゴリズムの最も核心的で近い部分です。
TurboQuantの著者自身も査読への返信の中でこの点を認めていますが、論文本文の中で、この方法とRaBitQとの関係について正面から説明したことは一度もありません。さらに重要な背景は次の通りです。TurboQuantの第2著者Majid Daliriは2025年1月に自ら高健扬チームに連絡し、RaBitQのソースコードをベースに書き換えたPythonバージョンのデバッグを手伝ってほしいと依頼してきました。メールには再現手順とエラー情報が詳細に記されていました。言い換えれば、TurboQuantチームはRaBitQの技術的詳細を非常に熟知していたのです。
ICLRの匿名査読者の一人も、両者が同じ技術を使っていることを指摘し、十分な議論を求めました。しかし最終版の論文では、TurboQuantチームは追加の議論を行わず、本文中にあった(すでに不完全な)RaBitQの記述を付録に移してしまいました。
指摘2:根拠のないまま、相手の理論を「サブ最適」と称した。
TurboQuantの論文はRaBitQに「理論的にサブ最適(suboptimal)」と直接ラベル付けし、その理由としてRaBitQの数学的分析が「やや粗い」ことを挙げています。しかし高健扬は、RaBitQの拡張版論文はすでに、圧縮誤差が数学的に最適な境界に到達することを厳密に証明していると指摘しました。この結論は理論計算機科学のトップ会議で発表されています。
2025年5月、高健扬チームは複数回のメールでRaBitQの理論的最適性について詳細に説明していました。TurboQuantの第2著者Daliriも、全著者に伝えたことを確認しています。しかし、それにもかかわらず、最終的な論文では「サブ最適」という表現が残り、反論の根拠は何も示されませんでした。
指摘3:実験比較において「左手は縛り、右手は刀を持たせる」状態。
これは本文中で最も破壊力のある指摘です。高健扬は、TurboQuantの論文が速度比較の実験で、2つの不公平な条件を重ねていたと指摘しています。
第一に、RaBitQの公式が最適化されたC++コード(デフォルトでマルチスレッド対応)を提供していたにもかかわらず、TurboQuantチームはそれを使わず、自分たちが翻訳したPythonバージョンでRaBitQをテストしました。第二に、RaBitQのテストではシングルコアCPUかつマルチスレッドをオフにしており、TurboQuantはNVIDIA A100 GPUを用いていました。
この2つの条件を重ねた結果、読者が目にする結論は「RaBitQはTurboQuantより数桁遅い」というものになりますが、その前提としてGoogleチームが相手を縛り上げてレースをさせたことを、読者は知るすべがありません。論文では、これら実験条件の差異が十分に開示されていなかったのです。
Googleの回答:「ランダム回転は汎用技術であり、毎回引用できるわけではない」
高健扬の公開によれば、TurboQuantチームは2026年3月のメール返信の中で次のように述べました。「ランダム回転とJohnson-Lindenstrauss変換の使用はこの分野の標準技術であり、これらの方法を使ったすべての論文を引用することはできません。」
高健扬チームは、それは概念のすり替えだと考えています。問題は、RaBitQがまったく同じ問題設定の下で、この方法をベクトル圧縮と結び付け、さらに最適性を証明した最初の仕事である点にあります。TurboQuant論文は、両者の関係を正確に記述すべきだったのです。
スタンフォードNLPグループの公式Xアカウントは高健扬の声明をリツイートしました。高健扬チームはすでにICLRのOpenReviewプラットフォーム上で公開コメントを出し、ICLR大会の議長および倫理委員会に正式に申し立てを行っています。今後、arXivに詳細な技術レポートも公開予定です。
独立系の技術ブロガーDario Salvatiは、分析の中で比較的中立的な評価を示しました。TurboQuantは数学的手法において確かに実質的な貢献があるものの、RaBitQとの関係は論文の記述よりもはるかに密接である、と指摘しています。
900億ドルの時価総額蒸発:論文論争と市場のパニックの重なり
この学術的な論争が起きたタイミングは非常に微妙です。Googleは3月24日に公式ブログでTurboQuantを発表した後、世界のストレージ半導体セクターは猛烈な売りに見舞われました。CNBCなど複数のメディアによると、Micronは6営業日連続で下落し、累計下落率は20%超。SanDiskは1日で11%下落。韓国のSKハイニックス(SK hynix)は約6%下げ、Samsung Electronicsは約5%下げ、日本のKioxia(铠侠)は約6%下げました。市場のパニックのロジックは単純で乱暴です。ソフトウェアによる圧縮でAIの推論メモリ需要が6倍に低下し、ストレージ半導体の需要見通しが構造的に下方修正される、というものです。
モルガン・スタンレーのアナリストJoseph Mooreは3月26日のリサーチノートで、このロジックに反論し、MicronとSanDiskの「買い増し(増持)」評価を維持しました。Mooreは、TurboQuantが圧縮しているのはKVキャッシュという特定タイプのキャッシュであり、メモリ全体の使用量ではないと指摘し、それを「通常の生産性向上(正常な生産率改善)」と位置付けました。ウェルズ・ファーゴのアナリストAndrew Rochaも、ジェボンズの逆説(効率化はむしろ需要を押し上げる)を引き合いに出し、効率向上によりコストが下がれば、より大規模なAI展開が促進され、結果的にメモリ需要が押し上げられる可能性があると述べました。
旧論文、新パッケージ:AI研究から市場の語りへの伝導リスク
技術ブロガーBen Pouladianの分析によると、TurboQuantの論文は2025年4月に既に公開されており、新たな研究ではありません。3月24日にGoogleが公式ブログで再パッケージして宣伝した一方、市場はそれを新たなブレークスルーとして価格付けしました。この「旧論文、新公開」の戦略は、論文中に潜む実験バイアスと重なり、AI研究が学術論文から市場の語りへと伝わる伝導チェーンにおける体系的なリスクを映し出しています。
AIインフラへの投資家にとって、ある論文が「数桁」の性能向上を主張する場合、まず確認すべきは、そのベンチマーク比較の条件が公平かどうかです。
高健扬チームは、問題の正式な解決を引き続き推進すると明言しています。Google側は、公開書簡に対する具体的な指摘について、現時点では正式な回答を出していません。