3月16日、京东が世界最大規模で最も多彩なシナリオを備えた具身知能データ収集センターの建設を発表したことは、ロブスターの話題にかき消され、しばらく沈黙していたロボット分野に重い一撃を落とした。ある意味では、これは強い産業インターネット色を帯びた大規模なデータ大量生産運動である。今回の動員には、社内の10万人超の従業員、外部の各業界の最大50万人の人員が含まれ、宿遷だけでも10万人以上の市民を動員した——**この前例のない人海戦術は、規模の暴力美学を用いて、現在最も致命的な弱点であるデータ不足を無理やり突破しようとしている。**モデルアーキテクチャが徐々に収束し、計算能力の門戸が比較的明確になった今日、高品質な物理的インタラクションデータは、ロボットが真に多業種に進出できるかどうかを決定づける唯一の勝負所となっている。この「人類史上最大規模のデータ収集行動」と定義される背後には、産業界の共通認識がある:運動制御を担う「小脳」が次第に発達する中、より高品質なデータで物理世界を理解する「大脳」を育てることが、業界の未来の格局を決める核心戦となる。京东の壮大なストーリーから産業の微視的現実へと目を向けると、この数十万人が生み出すデータは、果たして金鉱なのか砂利なのか、依然として判断が難しい。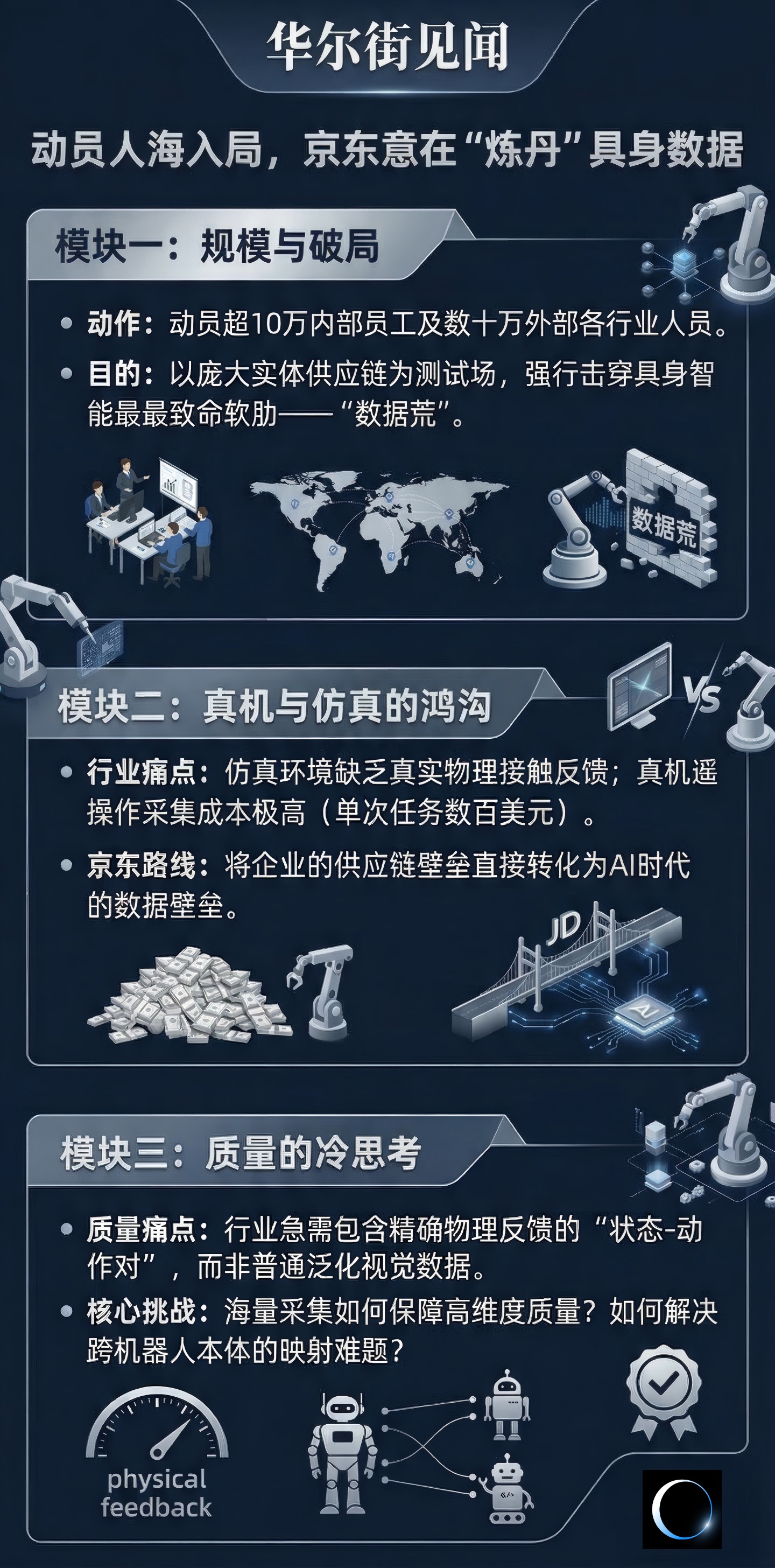関わる労働者たち------京东がこのデータ人海戦を敢行し、また必要とした核心的理由は、その巨大かつ高度に複雑な自営のサプライチェーンにある。純粋なソフトウェアインターネット企業とは異なり、京东自身が巨大な物理世界のインタラクション場であり、具身知能の成熟は、今後10年の履行コストと運営効率に直結している。この戦略は北京亦庄のロボット産業エコシステムと深く連動している。亦庄経済技術開発区にはすでに300以上のロボット関連企業が集積し、産業チェーンの規模は百億元超、40以上の実用シナリオを開放し、国内のヒューマノイドロボット産業の中心的集積地となっている。京东は、亦庄に根ざす「チェーンリーダー」企業として、すでにロボット産業加速計画を発表している。今、京东が大規模にデータ収集センターなどのソフトインフラに投資しているのは、実は産業チェーンの最も欠落している部分を補完しようとする動きだ。亦庄は「胴体」とテストフィールドを提供し、京东は膨大なシナリオを通じてロボットに現実世界の理解に必要な常識を注入しようとしている。**このソフトとハードの融合による産業の共振は、データの飛輪からハードウェアのイテレーションまでを一体化したビジネスの閉ループを目指している。**数十万人の調整は決して容易ではない。計画によると、収集シナリオは物流、工業、小売などをカバーする。実際の運用では、京东の既存のデジタル管理ネットワークに依存する可能性が高い。例えば、一線の配送員や倉庫仕分け員に、視覚や力覚センサーを備えたウェアラブルデバイスを日常的に装着させて作業させるといった方法だ。一線の従業員や動員された宿遷市民の視点から見ると、この運動は複雑さに満ちている。従業員は無意識のうちにロボットのデータ教師となり、これらのロボットの将来の目標は高強度の人力労働の代替である。適切な報酬や利益配分の仕組みを設計し、従業員の抵抗感を避けることが、京东にとって重要な課題となる。しかし、現段階では具体的な実施方法は従業員に伝わっていない。京东の北京地区の社員は、ウォールストリートジャーナルに対し、「今のところこの件については聞いていない」と述べている。彼の見解では、**もし相応の報酬があれば、それは市場の行動とみなされ、従業員の参加意欲は個人の選択次第だ。**宿遷の京东社員も、ウォールストリートジャーナルに対し、「まだ通知は受けていない」と答えた。公式発表では、「すべてのデータ収集について、京东は法令を厳守して行う」と述べているが、実情はより複雑だ。例えば、配送シナリオでは、倉庫の流れは標準化されているが、配送は千家万戸に入り込み、小売シナリオでは大量の消費者の顔特徴やプライバシー習慣に関わる情報を含む。データのコンプライアンスがますます厳しくなる今日、数十万人が持ち歩く非構造化データの脱敏や洗浄のコストは天文学的な数字になる可能性がある。モラヴィックのパラドックスを解く--------1988年、ロボット学者ハンス・モラヴィックは次のような結論を出した。**「コンピュータに成人レベルの知能を持たせるのは容易だが、一歳児の感知・運動能力を持たせるのは非常に難しく、ほとんど不可能に近い。」**今日、具身知能におけるモラヴィックのパラドックスの主要な映しは、産業界のデータ空白に集中している。大規模モデルの成功は、インターネット上に蓄積された兆単位の高品質テキストコーパスを直接消費していることに基づく。しかし、物理世界には既存のインターネットのようなものは存在しない。具身知能が現実世界でスケールの法則を実現するには、巨大なデータの壁を越える必要がある。京东の今回の大規模動きは、まさにこのアンカーと、その背後にあるデータ収集の困難に焦点を当てている。第一に、シミュレーションの限界の問題が解決すべき課題だ。現段階では、産業界のデータ取得の主流経路はすでに深刻に分化し、それぞれのボトルネックに苦しんでいる。現在、ほとんどのスタートアップは、NVIDIAのIsaac SimやMuJoCoなどの物理エンジンを用いた仮想環境に高度に依存しており、ロボットは仮想世界で何百万回も強化学習を行う。この方法はコストが低く、速度も速く、ハードウェアの試行錯誤による破損を心配しなくて済む。しかし、**経験豊富な実務者は「Sim-to-Real(シミュから現実へ)」の限界を次第に認識しつつある。**物理世界の複雑さは、視覚的な光と影の変化だけでなく、ケーブルの柔軟性や衣服の非剛性な引っ張り、ネジ締め時の微細な摩擦変化、さらにはセンサーの電磁ノイズにまで及ぶ。**現行の物理エンジンの計算能力では、これらの高次元かつ非線形な微視的物理法則を完璧に模擬できない。**そのため、仮想環境で完璧に動作したモデルでも、実機に展開すると深刻な「脳梗塞」や動作の歪みが生じる。仮想と現実のギャップを埋めるには、やはり実世界に戻るしかない。スタンフォードで爆発的に流行したMobile ALOHAから、現在のFigure AI、宇树、智元などのトップ企業は、多くの場合リモート操作——人間がウェアラブル動作キャプチャ服やVRデバイスを装着し、アバターのようにロボットを操作して、第一視点の映像、関節角度、力矩データを記録している。これが現時点で最も質の高いデータ取得手法とされているが、**これには商業的な第二の問題、すなわちコスト対効果の極端な悪さが伴う。**業界推定によると、全身型ヒューマノイドロボットのハードウェアコストは数十万から百万を超えることもあり、リモート操作による有効データの収集には高額なハードウェアの減価償却費と、専門操作員の高コストが必要だ。ウォールストリートジャーナルによると、複雑なインタラクションの高品質データ1本の収集と洗浄には数百ドルのコストがかかり、失敗率も非常に高い。このような工房式の手作りデータ収集モデルは、具身知能の汎用化に必要な百億、千億パラメータ規模を支えることはできない。コストを下げるため、Googleなどの巨頭はOpen X-Embodimentなどのオープンソースデータセット計画を立ち上げ、世界中の研究機関のデータを集約し、産業全体で共有しようとしている。国内でも、百万規模の実機データセットをオープン化する企業も出てきている。しかし、ここにはもう一つの大きな困難、すなわちロボットハードウェアの極度の断片化という工程上の問題が潜んでいる。犬型、車輪型、二足歩行型、さらには異なるメーカーのヒューマノイドロボットは、関節の自由度やモーターのトルク、センサー配置、重心構造が全く異なる。UR5のアームで訓練された高品質な掴みデータは、直接テスラのOptimusや京东の物流ロボットに流用できるわけではない。この「異本体間のマッピング」の困難さが、オープンソースのデータの多くを散在した孤島に変え、規模の効果を生み出しにくくしている。おそらく、これら三つの困難の下で、具身知能の商業競争のロジックは本質的に変化している:実際のシナリオを持つ者こそが、安価で高品質な閉ループデータを継続的に獲得できる「護城河」を持つ。これが、テスラや京东が純粋なハードウェアスタートアップとは異なる道を選んだ理由だ。テスラは巨大なギガファクトリーを活用し、Optimusを実際のバッテリー仕分けラインで日夜試行錯誤させている。一方、京东は全国の物流ネットワークと数十万の産業労働者、巨大な実店舗体系を通じて、半自動化されたデータの流れを構築しようとしている。この戦略は、企業のサプライチェーンの壁を直接AI時代のデータ壁に変える試みだ。対照的に、自社シナリオを持たないロボットスタートアップは、苦渋の選択を迫られている——ハードウェアを低価格で大学や研究機関に安く売ることで研究者とデータを共有させるか、工場の場を高額で借りるか、あるいは新興の具身知能データサービス企業のような「簡智」などにデータのカスタム提供を依頼するかだ。要するに、**京东の参入は、具身知能産業のアルゴリズムの仮面を完全に剥ぎ取り、資金、シナリオ、人員調整を競う重資産のビジネス戦争の時代に突入させた。**データ不足の前では、アルゴリズムの護城河は薄まりつつあり、実物理世界のインタラクション入口を握る巨頭たちが、静かにこのAGIへの大網を収束させている。より希少な高品質データ--------京东は「2年以内に1,000万時間超の実シナリオデータを蓄積する」と宣言しているが、業界の反応は一様に熱狂的ではなく、むしろ冷静な見方も多い。具身知能の文脈では、データの質とモダリティの方が、単なる時間長さよりもはるかに重要だ。アルゴリズム業界は、現在の核心的な痛点を次のように指摘している:今必要なのは、人間の視点の第一人称動画ではなく、正確な物理的フィードバックを含む「状態-動作ペア」だ。例えば、宿遷市民がカメラを持ってスーパーを歩き回る、あるいは配送員が配達過程を記録する——これらは膨大なインターネット級の汎用ビジュアルデータを生み出す。これらのデータは、扉やリンゴが何であるかを理解させるための世界モデルの訓練には有効だが、リンゴを潰さずに適切な力でつかむ制御戦略の訓練にはほとんど役立たない。あるロボット業界の関係者は、ウォールストリートジャーナルに対し、「ロボットにとって価値のあるデータ、特に実機のデータが不足している」と述べている。彼の見解では、京东のこの操作はあくまで外部委託のBPOビジネスであり、人員と場所を提供しているに過ぎない。人間が物理的に掴む際には、触覚や力覚、空間座標の微調整といった高次元の暗黙知が伴うが、これらの高次元の暗黙知は、普通のウェアラブルデバイスでは捕捉できない。京东の数万人の人力が動画を提供しているだけでは、その後のロボットが実行可能な動作に変換される際の損失率は非常に高い。また、国内のトップロボット企業の責任者は、業界の最も重要な課題は「統一されたデータセットの定義標準の欠如」だと直言している。例えば、各ロボット企業の関節自由度やセンサー位置、駆動器の種類が異なる場合、京东が収集した膨大な人間の動作データを、どうやって異なる構成のロボットにリダイレクトしてマッピングするのか。標準的な底層規格がなければ、これらの1000万時間のデータは最終的に京东の自社開発ロボットの私有資源にしかならず、産業全体の進歩を促すインフラにはなり得ない。これが、京东が最初の年の計画で「100万時間のロボット本体データ収集」を特に強調した理由だ。産業の真の発展は、人類の汎用ビデオによる事前学習、ロボット本体の高品質データ微調整、そして強化学習による自己探索の三つの方向に向かう。京东が具身知能データ収集センターの建設を発表したことは、国内企業が規模化・工学的手法を用いてロボット産業のデータ不足に挑もうとする新たな試みの始まりを示す。実体シナリオと大規模人力の融合は、確かにデータ蓄積の新たな道筋を提供している。しかし、ロボットの「知能の爆発」を真に実現するには、単なるデータ規模の積み重ねだけでは不十分だ。大量の収集の中で、データの高次元性と高品質をどう保証するか、**どうやって統一的なデータ標準を構築するか、また、規模化収集に伴うプライバシーやコンプライアンスの問題をどう処理するか——これらが、企業や産業全体が商業化段階に進む上で解決すべき重要課題となる。**リスク警告及び免責事項市場にはリスクが伴い、投資は慎重に行うべきです。本記事は個人の投資助言を意図したものではなく、特定の投資目的、財務状況、ニーズを考慮したものではありません。読者は本記事の意見、見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己負担です。
人海を動員して参入し、京東の狙いは「丹薬を作る」ような具身データの「精錬」にある
3月16日、京东が世界最大規模で最も多彩なシナリオを備えた具身知能データ収集センターの建設を発表したことは、ロブスターの話題にかき消され、しばらく沈黙していたロボット分野に重い一撃を落とした。
ある意味では、これは強い産業インターネット色を帯びた大規模なデータ大量生産運動である。
今回の動員には、社内の10万人超の従業員、外部の各業界の最大50万人の人員が含まれ、宿遷だけでも10万人以上の市民を動員した——この前例のない人海戦術は、規模の暴力美学を用いて、現在最も致命的な弱点であるデータ不足を無理やり突破しようとしている。
モデルアーキテクチャが徐々に収束し、計算能力の門戸が比較的明確になった今日、高品質な物理的インタラクションデータは、ロボットが真に多業種に進出できるかどうかを決定づける唯一の勝負所となっている。
この「人類史上最大規模のデータ収集行動」と定義される背後には、産業界の共通認識がある:運動制御を担う「小脳」が次第に発達する中、より高品質なデータで物理世界を理解する「大脳」を育てることが、業界の未来の格局を決める核心戦となる。
京东の壮大なストーリーから産業の微視的現実へと目を向けると、この数十万人が生み出すデータは、果たして金鉱なのか砂利なのか、依然として判断が難しい。
関わる労働者たち
京东がこのデータ人海戦を敢行し、また必要とした核心的理由は、その巨大かつ高度に複雑な自営のサプライチェーンにある。
純粋なソフトウェアインターネット企業とは異なり、京东自身が巨大な物理世界のインタラクション場であり、具身知能の成熟は、今後10年の履行コストと運営効率に直結している。
この戦略は北京亦庄のロボット産業エコシステムと深く連動している。
亦庄経済技術開発区にはすでに300以上のロボット関連企業が集積し、産業チェーンの規模は百億元超、40以上の実用シナリオを開放し、国内のヒューマノイドロボット産業の中心的集積地となっている。京东は、亦庄に根ざす「チェーンリーダー」企業として、すでにロボット産業加速計画を発表している。
今、京东が大規模にデータ収集センターなどのソフトインフラに投資しているのは、実は産業チェーンの最も欠落している部分を補完しようとする動きだ。亦庄は「胴体」とテストフィールドを提供し、京东は膨大なシナリオを通じてロボットに現実世界の理解に必要な常識を注入しようとしている。
このソフトとハードの融合による産業の共振は、データの飛輪からハードウェアのイテレーションまでを一体化したビジネスの閉ループを目指している。
数十万人の調整は決して容易ではない。
計画によると、収集シナリオは物流、工業、小売などをカバーする。実際の運用では、京东の既存のデジタル管理ネットワークに依存する可能性が高い。例えば、一線の配送員や倉庫仕分け員に、視覚や力覚センサーを備えたウェアラブルデバイスを日常的に装着させて作業させるといった方法だ。
一線の従業員や動員された宿遷市民の視点から見ると、この運動は複雑さに満ちている。
従業員は無意識のうちにロボットのデータ教師となり、これらのロボットの将来の目標は高強度の人力労働の代替である。適切な報酬や利益配分の仕組みを設計し、従業員の抵抗感を避けることが、京东にとって重要な課題となる。
しかし、現段階では具体的な実施方法は従業員に伝わっていない。
京东の北京地区の社員は、ウォールストリートジャーナルに対し、「今のところこの件については聞いていない」と述べている。彼の見解では、**もし相応の報酬があれば、それは市場の行動とみなされ、従業員の参加意欲は個人の選択次第だ。**宿遷の京东社員も、ウォールストリートジャーナルに対し、「まだ通知は受けていない」と答えた。
公式発表では、「すべてのデータ収集について、京东は法令を厳守して行う」と述べているが、実情はより複雑だ。
例えば、配送シナリオでは、倉庫の流れは標準化されているが、配送は千家万戸に入り込み、小売シナリオでは大量の消費者の顔特徴やプライバシー習慣に関わる情報を含む。
データのコンプライアンスがますます厳しくなる今日、数十万人が持ち歩く非構造化データの脱敏や洗浄のコストは天文学的な数字になる可能性がある。
モラヴィックのパラドックスを解く
1988年、ロボット学者ハンス・モラヴィックは次のような結論を出した。
「コンピュータに成人レベルの知能を持たせるのは容易だが、一歳児の感知・運動能力を持たせるのは非常に難しく、ほとんど不可能に近い。」
今日、具身知能におけるモラヴィックのパラドックスの主要な映しは、産業界のデータ空白に集中している。
大規模モデルの成功は、インターネット上に蓄積された兆単位の高品質テキストコーパスを直接消費していることに基づく。しかし、物理世界には既存のインターネットのようなものは存在しない。具身知能が現実世界でスケールの法則を実現するには、巨大なデータの壁を越える必要がある。
京东の今回の大規模動きは、まさにこのアンカーと、その背後にあるデータ収集の困難に焦点を当てている。
第一に、シミュレーションの限界の問題が解決すべき課題だ。
現段階では、産業界のデータ取得の主流経路はすでに深刻に分化し、それぞれのボトルネックに苦しんでいる。
現在、ほとんどのスタートアップは、NVIDIAのIsaac SimやMuJoCoなどの物理エンジンを用いた仮想環境に高度に依存しており、ロボットは仮想世界で何百万回も強化学習を行う。この方法はコストが低く、速度も速く、ハードウェアの試行錯誤による破損を心配しなくて済む。
しかし、経験豊富な実務者は「Sim-to-Real(シミュから現実へ)」の限界を次第に認識しつつある。
物理世界の複雑さは、視覚的な光と影の変化だけでなく、ケーブルの柔軟性や衣服の非剛性な引っ張り、ネジ締め時の微細な摩擦変化、さらにはセンサーの電磁ノイズにまで及ぶ。
**現行の物理エンジンの計算能力では、これらの高次元かつ非線形な微視的物理法則を完璧に模擬できない。**そのため、仮想環境で完璧に動作したモデルでも、実機に展開すると深刻な「脳梗塞」や動作の歪みが生じる。
仮想と現実のギャップを埋めるには、やはり実世界に戻るしかない。
スタンフォードで爆発的に流行したMobile ALOHAから、現在のFigure AI、宇树、智元などのトップ企業は、多くの場合リモート操作——人間がウェアラブル動作キャプチャ服やVRデバイスを装着し、アバターのようにロボットを操作して、第一視点の映像、関節角度、力矩データを記録している。
これが現時点で最も質の高いデータ取得手法とされているが、これには商業的な第二の問題、すなわちコスト対効果の極端な悪さが伴う。
業界推定によると、全身型ヒューマノイドロボットのハードウェアコストは数十万から百万を超えることもあり、リモート操作による有効データの収集には高額なハードウェアの減価償却費と、専門操作員の高コストが必要だ。
ウォールストリートジャーナルによると、複雑なインタラクションの高品質データ1本の収集と洗浄には数百ドルのコストがかかり、失敗率も非常に高い。
このような工房式の手作りデータ収集モデルは、具身知能の汎用化に必要な百億、千億パラメータ規模を支えることはできない。
コストを下げるため、Googleなどの巨頭はOpen X-Embodimentなどのオープンソースデータセット計画を立ち上げ、世界中の研究機関のデータを集約し、産業全体で共有しようとしている。国内でも、百万規模の実機データセットをオープン化する企業も出てきている。
しかし、ここにはもう一つの大きな困難、すなわちロボットハードウェアの極度の断片化という工程上の問題が潜んでいる。犬型、車輪型、二足歩行型、さらには異なるメーカーのヒューマノイドロボットは、関節の自由度やモーターのトルク、センサー配置、重心構造が全く異なる。
UR5のアームで訓練された高品質な掴みデータは、直接テスラのOptimusや京东の物流ロボットに流用できるわけではない。
この「異本体間のマッピング」の困難さが、オープンソースのデータの多くを散在した孤島に変え、規模の効果を生み出しにくくしている。
おそらく、これら三つの困難の下で、具身知能の商業競争のロジックは本質的に変化している:実際のシナリオを持つ者こそが、安価で高品質な閉ループデータを継続的に獲得できる「護城河」を持つ。
これが、テスラや京东が純粋なハードウェアスタートアップとは異なる道を選んだ理由だ。
テスラは巨大なギガファクトリーを活用し、Optimusを実際のバッテリー仕分けラインで日夜試行錯誤させている。一方、京东は全国の物流ネットワークと数十万の産業労働者、巨大な実店舗体系を通じて、半自動化されたデータの流れを構築しようとしている。
この戦略は、企業のサプライチェーンの壁を直接AI時代のデータ壁に変える試みだ。
対照的に、自社シナリオを持たないロボットスタートアップは、苦渋の選択を迫られている——ハードウェアを低価格で大学や研究機関に安く売ることで研究者とデータを共有させるか、工場の場を高額で借りるか、あるいは新興の具身知能データサービス企業のような「簡智」などにデータのカスタム提供を依頼するかだ。
要するに、京东の参入は、具身知能産業のアルゴリズムの仮面を完全に剥ぎ取り、資金、シナリオ、人員調整を競う重資産のビジネス戦争の時代に突入させた。
データ不足の前では、アルゴリズムの護城河は薄まりつつあり、実物理世界のインタラクション入口を握る巨頭たちが、静かにこのAGIへの大網を収束させている。
より希少な高品質データ
京东は「2年以内に1,000万時間超の実シナリオデータを蓄積する」と宣言しているが、業界の反応は一様に熱狂的ではなく、むしろ冷静な見方も多い。
具身知能の文脈では、データの質とモダリティの方が、単なる時間長さよりもはるかに重要だ。
アルゴリズム業界は、現在の核心的な痛点を次のように指摘している:今必要なのは、人間の視点の第一人称動画ではなく、正確な物理的フィードバックを含む「状態-動作ペア」だ。
例えば、宿遷市民がカメラを持ってスーパーを歩き回る、あるいは配送員が配達過程を記録する——これらは膨大なインターネット級の汎用ビジュアルデータを生み出す。
これらのデータは、扉やリンゴが何であるかを理解させるための世界モデルの訓練には有効だが、リンゴを潰さずに適切な力でつかむ制御戦略の訓練にはほとんど役立たない。
あるロボット業界の関係者は、ウォールストリートジャーナルに対し、「ロボットにとって価値のあるデータ、特に実機のデータが不足している」と述べている。彼の見解では、京东のこの操作はあくまで外部委託のBPOビジネスであり、人員と場所を提供しているに過ぎない。
人間が物理的に掴む際には、触覚や力覚、空間座標の微調整といった高次元の暗黙知が伴うが、これらの高次元の暗黙知は、普通のウェアラブルデバイスでは捕捉できない。京东の数万人の人力が動画を提供しているだけでは、その後のロボットが実行可能な動作に変換される際の損失率は非常に高い。
また、国内のトップロボット企業の責任者は、業界の最も重要な課題は「統一されたデータセットの定義標準の欠如」だと直言している。
例えば、各ロボット企業の関節自由度やセンサー位置、駆動器の種類が異なる場合、京东が収集した膨大な人間の動作データを、どうやって異なる構成のロボットにリダイレクトしてマッピングするのか。
標準的な底層規格がなければ、これらの1000万時間のデータは最終的に京东の自社開発ロボットの私有資源にしかならず、産業全体の進歩を促すインフラにはなり得ない。
これが、京东が最初の年の計画で「100万時間のロボット本体データ収集」を特に強調した理由だ。産業の真の発展は、人類の汎用ビデオによる事前学習、ロボット本体の高品質データ微調整、そして強化学習による自己探索の三つの方向に向かう。
京东が具身知能データ収集センターの建設を発表したことは、国内企業が規模化・工学的手法を用いてロボット産業のデータ不足に挑もうとする新たな試みの始まりを示す。
実体シナリオと大規模人力の融合は、確かにデータ蓄積の新たな道筋を提供している。
しかし、ロボットの「知能の爆発」を真に実現するには、単なるデータ規模の積み重ねだけでは不十分だ。
大量の収集の中で、データの高次元性と高品質をどう保証するか、どうやって統一的なデータ標準を構築するか、また、規模化収集に伴うプライバシーやコンプライアンスの問題をどう処理するか——これらが、企業や産業全体が商業化段階に進む上で解決すべき重要課題となる。
リスク警告及び免責事項
市場にはリスクが伴い、投資は慎重に行うべきです。本記事は個人の投資助言を意図したものではなく、特定の投資目的、財務状況、ニーズを考慮したものではありません。読者は本記事の意見、見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己負担です。