蛇年の終わりに、阿里巴巴のより強力な千問モデルが登場。2月16日除夕の日、**阿里巴巴は新世代大規模モデル「千問Qwen3.5-Plus」をオープンソース化。**千問3.5はテキストとビジュアルの混合データ上で事前学習を行い、ネイティブなマルチモーダルの新たな突破口を実現。推論、プログラミング、エージェントなど多方面のベンチマーク評価で優れた成績を収め、視覚理解能力の権威ある評価でも複数の最高性能を獲得している。Qwen3.5の核心的な突破点は**アーキテクチャの面から大規模モデルの「効率-精度」パラドックスを体系的に解決したことにある。**混合アテンション機構により、モデルは長文に対して動的に焦点を合わせることができ、全量計算による計算資源の浪費を避けることができる。一方、極めて疎なMoE(Mixture of Experts)アーキテクチャは、活性化パラメータのわずか5%未満を用いて3970億の総パラメータの知識リソースを呼び出し、推論コストを新たな低水準に抑えている。効率の向上とともに、ネイティブなマルチトークン予測能力により、モデルは「逐字的に跳ねる」から「多段階の計画」へと進化し、応答速度はほぼ倍増している。通義チームがNeurIPSで最優秀論文賞を受賞したアテンションゲートなどの安定性最適化は、これらの革新的な技術に対してシステムレベルの保証を提供し、超大規模訓練を「安定して実行できる」ことを確保している。これら四つの技術は共通して一つの目標を指している:**より少ない計算資源で、より強力な知能を呼び覚ますこと。**千問アプリやPC版は、いち早くQwen3.5-Plusモデルに対応済み。開発者は魔搭コミュニティやHuggingFaceから新モデルをダウンロードできるほか、阿里雲の百炼を通じてAPIサービスも直接利用可能だ。性能はGemini 3 Proに匹敵し、コストパフォーマンスも抜群------------------------**阿里によると、阿里巴巴がオープンソース化した新世代大規模モデル「千問Qwen3.5-Plus」は、Gemini 3 Proに匹敵し、世界最強のオープンソースモデルの座を獲得した。**千問3.5は基盤となるモデルアーキテクチャの全面的な革新を実現し、今回リリースされたQwen3.5-Plusの総パラメータは3970億、活性化パラメータはわずか170億。小さく勝ち、大きく超える性能を持ち、万億パラメータのQwen3-Maxモデルを凌駕。デプロイ時のGPUメモリ使用量も60%削減し、推論効率は大幅に向上、最大推論スループットは19倍に達する。**価格面では、Qwen3.5-PlusのAPI料金は百万トークンあたり0.8元と、Gemini 3 Proの1/18に過ぎない。****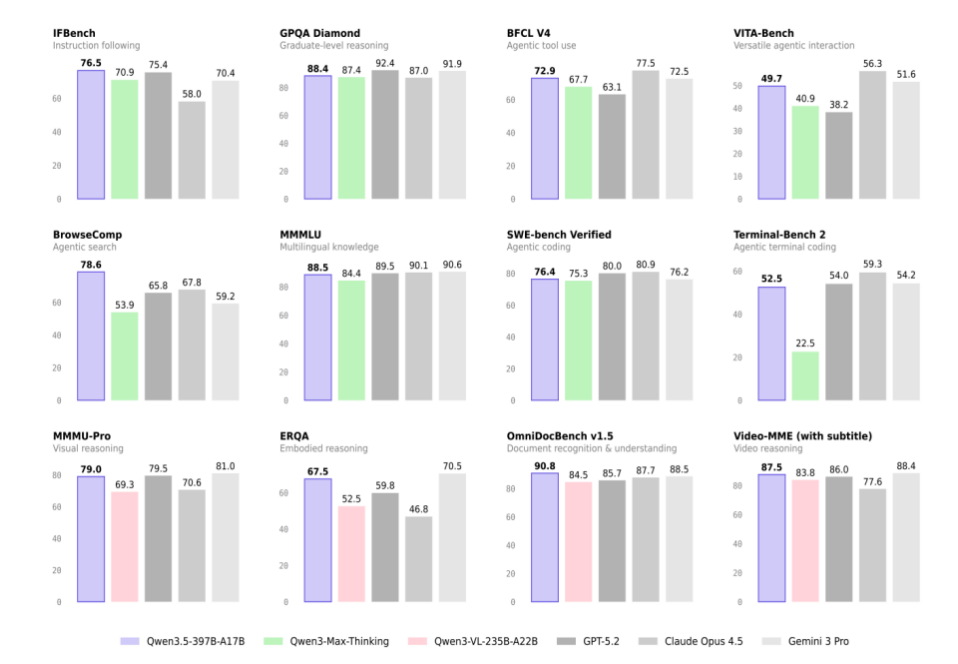**四つの技術革新:アーキテクチャからシステムの安定性まで-----------------Qwen3.5の核心技術は、四つの革新によって実現されている。**まずは混合アテンション機構だ。これによりモデルは「詳細と概略をバランスよく読む」ことを学習する。**従来の大規模モデルは長文処理時に、各トークンが全ての文脈と全量のアテンション計算を行う必要があり、文章が長くなるほど計算コストが増大し、長い文脈への対応が制約されていた。Qwen3.5は動的にアテンションリソースを配分し、重要情報は詳細に、重要でない情報は概略的に読むことで、効率と精度の両立を実現している。**次に、極めて疎なMoEアーキテクチャだ。**従来の密なモデルは推論ごとに全パラメータを活性化する必要があり、パラメータ数が多いほど計算コストも高くなる。MoEの革新は、入力内容に応じて最も関連性の高い「エキスパート」サブネットワークだけを活性化する点にある。Qwen3.5はこの考えを極限まで推し進め、総パラメータ3970億の中で、活性化されるのはわずか170億の疎な構造を採用。これにより、わずか5%未満の計算資源で全知識を呼び出し、推論コストを大きく削減している。第三は、ネイティブなマルチトークン予測能力だ。従来のモデルは逐次的にトークンを生成していたため、推論効率に制約があった。Qwen3.5は訓練段階から複数の位置を同時に予測できるよう学習し、推論速度はほぼ倍増。これにより、長文生成やコード補完、多輪対話などの高頻度シナリオで、「秒で応答」の体験を実現している。**最後に、システムレベルの訓練安定性最適化だ。**これにより、上述のアーキテクチャ革新が超大規模訓練でも「安定して動作」することを保証している。通義チームがNeurIPS 2025最優秀論文賞を受賞したアテンションゲートは、その代表例だ。これはアテンション層の出力に「スマートスイッチ」を導入し、情報の流れを制御する仕組みで、重要情報の埋没や無効情報の過剰増幅を防ぎ、出力の精度と長文の汎化能力を向上させる。さらに、正規化戦略やエキスパートルーティングの初期化など深層の改良も行われ、モデルの安定性と信頼性を確保している。「応答」から「操作」へ:新しい人機インタラクションの形------------------従来のチャットボットと異なり、Qwen3.5は単なる応答にとどまらない。視覚的なインテリジェンスを搭載し、スマートフォンやPCの画面を「観察」し、インターフェースの要素の位置や機能を正確に理解し、自律的に操作を行うことができる。公式デモでは、**ユーザーが自然言語で指示を出すだけで、モデルはモバイル端末やPC上の複数アプリを横断してタスクを完了し、人と機械の協働を新たな次元に引き上げている。****この能力は、最先端の視覚理解技術に由来する。**Qwen3.5は画面上のボタンやテキストボックス、アイコンの座標と機能属性を正確に認識し、クリックやスライド、入力といった操作を模擬できる。画面内容の視覚的符号化と意味解析を通じて、AIはデジタル世界とのインタラクションにおいて「視覚」と「手」の能力を実現している。ユーザーはローカルまたはクラウドに展開し、計算効率とデータの制御性のバランスを柔軟に調整可能だ。**アプリ間の連携もQwen3.5のもう一つの革新だ。**デモシナリオでは、モデルがメールから情報を抽出し、表計算データを読み取り、さらに通信ソフトを通じて送信を行う一連の操作を自動化。これにより、従来のアプリ間のデータ孤島を打破し、多段階の自動化を実現している。従来のアプリの隔離機構は、AIインテリジェントエージェントの前ではもはや障壁ではなく、ユーザの代理として各アプリを効率的に連携させ、シームレスなデジタル体験を創出している。この進化は、単一ツールから万能なデジタルアシスタントへの変貌を促し、人と機械の協働の新たな可能性を切り開いている。6分48秒、スケッチからコードへ:Qwen3.5の「読心術」はどれほど強力か?----------------------------------**さらに驚くべきは、Qwen3.5が示すビジュアルプログラミング能力だ。**デモ動画では、ユーザーがウェブページのスケッチを指差すだけで、モデルは6分48秒以内に構造化された動作可能なウェブコードに変換し、高品質な画像素材も自動的にマッチさせている。この「スケッチから製品へ」の能力は、モデルの深い視覚情報理解を示すもので、円形がボタン、線がレイアウトの仕切りを表すといった認識だけでなく、「これはナビゲーションバー」「あれはコンテンツエリア」といった設計意図の推測や、HTML・CSS・JavaScriptのコードロジックへの対応も可能だ。技術的な詳細に踏み込むと、この能力はQwen3.5のネイティブなマルチモーダルアーキテクチャに由来する。従来の「ビジュアルエンコーダ+言語モデル」の単純な結合とは異なり、Qwen3.5は事前学習段階からテキストとビジュアルの深い融合を実現し、ピクセルレベルの位置情報と意味的な抽象概念を同時に理解できる。実証データによると、このモデルのコンテキストウィンドウは100万トークンに拡大されており、2時間分の動画内容も直接処理可能。これにより、映画全体のストーリーや登場人物の関係、映像のスタイルを整理したドキュメントやコードに変換できる。このクロスモーダルの「パノラマ」記憶能力は、人間の一度の処理能力をはるかに超えている。リスク提示と免責条項市場にはリスクが伴うため、投資は慎重に。この記事は個別の投資助言を意図したものではなく、特定の投資目的や財務状況、ニーズを考慮したものではない。読者は本文の意見や見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己負担とすること。
阿里が千問3.5をリリース、性能はGemini 3に匹敵、トークン価格はわずかその1/18
蛇年の終わりに、阿里巴巴のより強力な千問モデルが登場。
2月16日除夕の日、**阿里巴巴は新世代大規模モデル「千問Qwen3.5-Plus」をオープンソース化。**千問3.5はテキストとビジュアルの混合データ上で事前学習を行い、ネイティブなマルチモーダルの新たな突破口を実現。推論、プログラミング、エージェントなど多方面のベンチマーク評価で優れた成績を収め、視覚理解能力の権威ある評価でも複数の最高性能を獲得している。
Qwen3.5の核心的な突破点は**アーキテクチャの面から大規模モデルの「効率-精度」パラドックスを体系的に解決したことにある。**混合アテンション機構により、モデルは長文に対して動的に焦点を合わせることができ、全量計算による計算資源の浪費を避けることができる。一方、極めて疎なMoE(Mixture of Experts)アーキテクチャは、活性化パラメータのわずか5%未満を用いて3970億の総パラメータの知識リソースを呼び出し、推論コストを新たな低水準に抑えている。
効率の向上とともに、ネイティブなマルチトークン予測能力により、モデルは「逐字的に跳ねる」から「多段階の計画」へと進化し、応答速度はほぼ倍増している。通義チームがNeurIPSで最優秀論文賞を受賞したアテンションゲートなどの安定性最適化は、これらの革新的な技術に対してシステムレベルの保証を提供し、超大規模訓練を「安定して実行できる」ことを確保している。これら四つの技術は共通して一つの目標を指している:より少ない計算資源で、より強力な知能を呼び覚ますこと。
千問アプリやPC版は、いち早くQwen3.5-Plusモデルに対応済み。開発者は魔搭コミュニティやHuggingFaceから新モデルをダウンロードできるほか、阿里雲の百炼を通じてAPIサービスも直接利用可能だ。
性能はGemini 3 Proに匹敵し、コストパフォーマンスも抜群
**阿里によると、阿里巴巴がオープンソース化した新世代大規模モデル「千問Qwen3.5-Plus」は、Gemini 3 Proに匹敵し、世界最強のオープンソースモデルの座を獲得した。**千問3.5は基盤となるモデルアーキテクチャの全面的な革新を実現し、今回リリースされたQwen3.5-Plusの総パラメータは3970億、活性化パラメータはわずか170億。小さく勝ち、大きく超える性能を持ち、万億パラメータのQwen3-Maxモデルを凌駕。デプロイ時のGPUメモリ使用量も60%削減し、推論効率は大幅に向上、最大推論スループットは19倍に達する。
価格面では、Qwen3.5-PlusのAPI料金は百万トークンあたり0.8元と、Gemini 3 Proの1/18に過ぎない。
四つの技術革新:アーキテクチャからシステムの安定性まで
Qwen3.5の核心技術は、四つの革新によって実現されている。**まずは混合アテンション機構だ。これによりモデルは「詳細と概略をバランスよく読む」ことを学習する。**従来の大規模モデルは長文処理時に、各トークンが全ての文脈と全量のアテンション計算を行う必要があり、文章が長くなるほど計算コストが増大し、長い文脈への対応が制約されていた。Qwen3.5は動的にアテンションリソースを配分し、重要情報は詳細に、重要でない情報は概略的に読むことで、効率と精度の両立を実現している。
**次に、極めて疎なMoEアーキテクチャだ。**従来の密なモデルは推論ごとに全パラメータを活性化する必要があり、パラメータ数が多いほど計算コストも高くなる。MoEの革新は、入力内容に応じて最も関連性の高い「エキスパート」サブネットワークだけを活性化する点にある。Qwen3.5はこの考えを極限まで推し進め、総パラメータ3970億の中で、活性化されるのはわずか170億の疎な構造を採用。これにより、わずか5%未満の計算資源で全知識を呼び出し、推論コストを大きく削減している。
第三は、ネイティブなマルチトークン予測能力だ。従来のモデルは逐次的にトークンを生成していたため、推論効率に制約があった。Qwen3.5は訓練段階から複数の位置を同時に予測できるよう学習し、推論速度はほぼ倍増。これにより、長文生成やコード補完、多輪対話などの高頻度シナリオで、「秒で応答」の体験を実現している。
**最後に、システムレベルの訓練安定性最適化だ。**これにより、上述のアーキテクチャ革新が超大規模訓練でも「安定して動作」することを保証している。通義チームがNeurIPS 2025最優秀論文賞を受賞したアテンションゲートは、その代表例だ。これはアテンション層の出力に「スマートスイッチ」を導入し、情報の流れを制御する仕組みで、重要情報の埋没や無効情報の過剰増幅を防ぎ、出力の精度と長文の汎化能力を向上させる。さらに、正規化戦略やエキスパートルーティングの初期化など深層の改良も行われ、モデルの安定性と信頼性を確保している。
「応答」から「操作」へ:新しい人機インタラクションの形
従来のチャットボットと異なり、Qwen3.5は単なる応答にとどまらない。視覚的なインテリジェンスを搭載し、スマートフォンやPCの画面を「観察」し、インターフェースの要素の位置や機能を正確に理解し、自律的に操作を行うことができる。公式デモでは、ユーザーが自然言語で指示を出すだけで、モデルはモバイル端末やPC上の複数アプリを横断してタスクを完了し、人と機械の協働を新たな次元に引き上げている。
**この能力は、最先端の視覚理解技術に由来する。**Qwen3.5は画面上のボタンやテキストボックス、アイコンの座標と機能属性を正確に認識し、クリックやスライド、入力といった操作を模擬できる。画面内容の視覚的符号化と意味解析を通じて、AIはデジタル世界とのインタラクションにおいて「視覚」と「手」の能力を実現している。ユーザーはローカルまたはクラウドに展開し、計算効率とデータの制御性のバランスを柔軟に調整可能だ。
**アプリ間の連携もQwen3.5のもう一つの革新だ。**デモシナリオでは、モデルがメールから情報を抽出し、表計算データを読み取り、さらに通信ソフトを通じて送信を行う一連の操作を自動化。これにより、従来のアプリ間のデータ孤島を打破し、多段階の自動化を実現している。従来のアプリの隔離機構は、AIインテリジェントエージェントの前ではもはや障壁ではなく、ユーザの代理として各アプリを効率的に連携させ、シームレスなデジタル体験を創出している。この進化は、単一ツールから万能なデジタルアシスタントへの変貌を促し、人と機械の協働の新たな可能性を切り開いている。
6分48秒、スケッチからコードへ:Qwen3.5の「読心術」はどれほど強力か?
**さらに驚くべきは、Qwen3.5が示すビジュアルプログラミング能力だ。**デモ動画では、ユーザーがウェブページのスケッチを指差すだけで、モデルは6分48秒以内に構造化された動作可能なウェブコードに変換し、高品質な画像素材も自動的にマッチさせている。この「スケッチから製品へ」の能力は、モデルの深い視覚情報理解を示すもので、円形がボタン、線がレイアウトの仕切りを表すといった認識だけでなく、「これはナビゲーションバー」「あれはコンテンツエリア」といった設計意図の推測や、HTML・CSS・JavaScriptのコードロジックへの対応も可能だ。
技術的な詳細に踏み込むと、この能力はQwen3.5のネイティブなマルチモーダルアーキテクチャに由来する。従来の「ビジュアルエンコーダ+言語モデル」の単純な結合とは異なり、Qwen3.5は事前学習段階からテキストとビジュアルの深い融合を実現し、ピクセルレベルの位置情報と意味的な抽象概念を同時に理解できる。実証データによると、このモデルのコンテキストウィンドウは100万トークンに拡大されており、2時間分の動画内容も直接処理可能。これにより、映画全体のストーリーや登場人物の関係、映像のスタイルを整理したドキュメントやコードに変換できる。このクロスモーダルの「パノラマ」記憶能力は、人間の一度の処理能力をはるかに超えている。
リスク提示と免責条項
市場にはリスクが伴うため、投資は慎重に。この記事は個別の投資助言を意図したものではなく、特定の投資目的や財務状況、ニーズを考慮したものではない。読者は本文の意見や見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己負担とすること。