10月20日に広範なサービスの中断が発生し、Amazon Web Services (AWS)のインフラにおける重大な障害の後、いくつかの主要なプラットフォームが一時的にオフラインになりました。Snapchat、Fortnite、Alexaなどの人気アプリが数時間にわたり利用できなくなり、インターネットの多くが少数の大手クラウドプロバイダーに依存している程度が明らかになりました。# AWSの障害がWeb2の弱点を露呈し、Web3のデザインがどのようにレジリエンスを加えるかこのイベントは、グローバルなインターネットが少数の集中型クラウドプロバイダーにどれほど依存しているかを浮き彫りにしました。また、単一障害点への依存を減らすことを目指すWeb3の下で推進される特に分散型システムに関する代替モデルについての議論を再燃させました。接続問題の報告は、米国および欧州の一部でユーザーがいくつかのアプリやウェブサイトが動作を停止したことに気づいた午前3時11分(ET)頃に始まりました。アマゾンはすぐに、最も重要なクラウドハブの1つである米国東部地域(US-East-1)が、API Gateway、Lambda、CloudFrontなどのサービスに影響を与える「高いエラー率」を経験していることを確認しました。1時間以内に、エンターテインメントからビジネスサービスに至るまで、AWSホスティングに依存するプラットフォームが次々と停止し始めました。AWSの障害は、eコマース、ゲーム、通信、金融サービスなど、複数の業界にわたるコア業務に影響を与えました。数時間にわたり、ユーザーはスマートホーム機能にアクセスできず、ソーシャルプラットフォームにログインしたり、オンライン取引を完了したりすることができませんでした。AWSベースの環境で運営されているビジネスも、内部システムのダウンタイムに直面し、日常業務や顧客サービスに支障をきたしました。# AWS障害の根本原因: アマゾンの確認したこと正午までに、Amazonのエンジニアはネットワーク更新の設定ミスが根本原因であることを特定しました。この問題は、内部システムがルーティングとDNS操作を管理する方法に影響を与え、リクエストが目的地に到達するのを妨げました。AWSチームは不具合のある更新をロールバックし、午後遅くまでに徐々にフルサービスを復元しました。アマゾンは、顧客データが失われたり侵害されたりすることはなかったと強調し、問題は単一の地域に限定されていたと述べました。それでも、ダウンタイムは、非常に多くのデジタルサービスが単一のインフラストラクチャ層に依存している場合、ローカライズされた問題でも世界的なウェブエコシステムに波及する可能性があることを浮き彫りにしました。# どのウェブサイトとアプリがダウンし、その影響がどのように広がったのか最も目立つ混乱の中には、Amazon自身の消費者向け製品、AlexaやRingが含まれていました。ユーザーは、スマートスピーカーが音声コマンドを処理できなくなり、接続されたカメラやドアベルがモバイルアプリのコントロールに反応しなくなったと報告しています。エンターテインメントおよびゲーム分野では、Fortnite、Roblox、PUBGなどのタイトルがログインエラーやマッチメイキングの失敗を経験しました。これらのゲームの多くは、リアルタイムのマルチプレイヤー同期やクラウドベースのコンテンツ配信にAWSを利用しています。ソーシャルおよびコミュニケーションプラットフォームも影響を受けました。Snapchatのユーザーは、障害のピーク時にメッセージを送信したりフィードを読み込んだりするのに困難を抱えました。さらに、Slack、Zoom、およびAWSインフラストラクチャに基づくいくつかのビジネスツールは、リモートワークの運営に影響を与える断続的な接続の問題を報告しました。AWSのコンピューティングおよびストレージサービスを利用しているいくつかの金融アプリケーションや決済処理業者が一時的にオフラインになり、取引の失敗やデジタル決済の遅延が発生しました。AWS上に構築された小売およびeコマースのウェブサイトも、一時的なダウンタイムや応答時間の遅延を経験しました。# なぜ中央集権化がウェブ全体の爆風半径を拡大させたのかこの事件の影響は、AWSがインターネットの日常機能にどれほど深く埋め込まれているかを示しました。一つの地域的な障害は、その直近の地理を超えて広がり、複数のタイムゾーンにわたる消費者、エンターテインメント、エンタープライズシステムに影響を及ぼしました。この障害は、APIやサードパーティの統合などのサービス依存関係が、技術的な起源を超えて障害の影響を広げる可能性があることも浮き彫りにしました。アマゾンの事後報告書によると、障害は定期メンテナンス更新中に行われた不具合のある設定変更に起因している。この変更は意図せず内部DNSリゾルバーがトラフィックを指示する方法を変更し、システムがリクエストの処理を停止させる原因となった。一旦検出されると、アマゾンのエンジニアはアップデートのロールバックを開始し、トラフィックをバックアップルートを通じてリダイレクトしました。復旧は地域ごとに始まり、AWSの障害状況は午後遅くには徐々に回復していることを示しました。その会社は、それ以来、同様の問題を防ぐために、より厳格な変更管理コントロールやネットワーク更新のための新しい自動ロールバック手順を含む追加の安全策を導入しました。# 中央集権化 vs. 分散化: より広範な教訓この事件は、Web2とWeb3モデルの長年の議論を再燃させました。現在のWeb2フレームワークでは、Amazon、Google、Microsoftを含む少数の企業が、中央集権型サーバーを通じて世界のウェブトラフィックの大部分を支えています。この構造は、利便性、コスト効率、スケーラビリティを提供しますが、同時にコントロールと脆弱性を集中させます。これらの提供者の一つが障害を経験すると、その影響は即座に広範囲に及びます。業界アナリストは、このホスティングおよびデータ管理の権力の集中がインターネットにとって単一の障害点を生み出すと長い間警告してきました。クラウドコンピューティングはスケーラビリティとコスト効率を提供しますが、リスクも集中させます。主要なプロバイダーのシステムがダウンすると、依存するサービスは独立して回復する余地がほとんどありません。AWSの障害は、相互依存関係という別の課題も浮き彫りにしました。多くのサービスは、1つのプロバイダーのAPIやデータベースが複数の下流プラットフォームをサポートする層状のアーキテクチャで運営されています。この構造は、技術的な障害の影響を増幅します。専門家は、冗長性と複数地域への展開がリスクを減少させる可能性がある一方で、根本的な問題はウェブの構造にあると指摘しています。集中型クラウドモデルは、制御とキャパシティを少数のネットワークに集中させるため、障害がより大きな影響を及ぼし、特定することが難しくなります。### 専門家がWeb3を実行可能な代替手段と見なす理由Web3は、分散型ネットワークの独立したノード全体にコンピューティングパワーとデータストレージを分配することで、それを変えようとしています。中央集権的なクラウドシステムとは異なり、分散型アーキテクチャは、1つのプロバイダーの稼働時間に依存しません。1つのノードやクラスターが障害を起こしても、他のノードは中断することなく運営を続けることができます。開発者や企業にとって、このアプローチはより高いレジリエンス、透明性、セキュリティを意味する可能性がありますが、Web2の速度と容量に合わせて分散型インフラを拡張することは依然として課題です。Filecoin、Arweave、およびAkash Networkなどのプロジェクトは、オープンネットワークを通じてストレージとコンピューティングパワーを提供することを目的とした分散型インフラソリューションの例です。これらのシステムは、中央集権的な監視なしで稼働時間とデータの可用性を維持するためにインセンティブメカニズムを使用しています。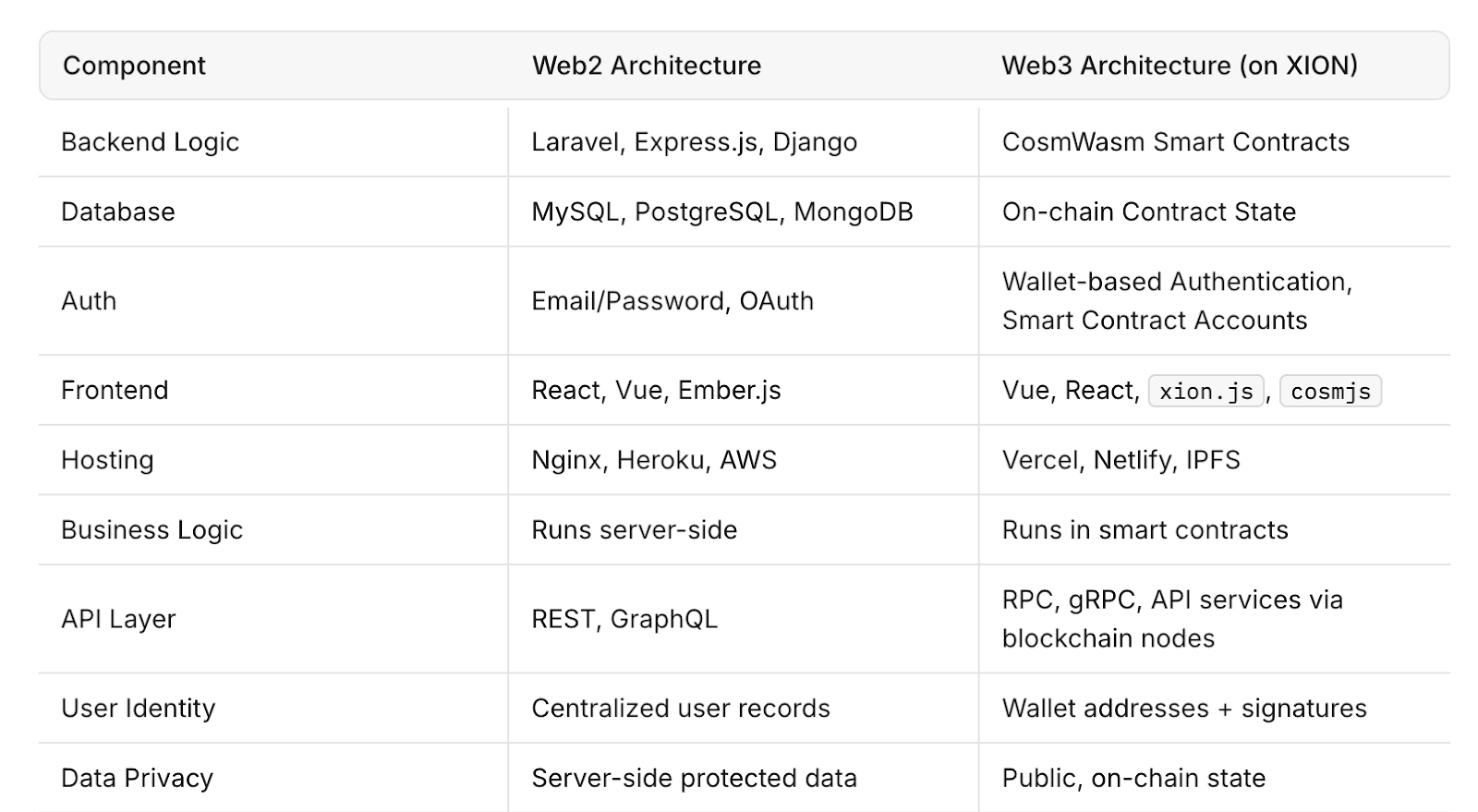しかし、Web3インフラはまだ採用の初期段階にあります。スケーラビリティ、速度、ユーザーエクスペリエンスに関して、確立されたWeb2システムと比較して課題に直面しています。それでも、AWSのインシデントは、インターネットのレジリエンスを高める代替モデルの価値を示しました。# 学んだ教訓と今後の道この障害は、デジタル経済におけるレジリエンスには冗長性と多様化が必要であることを示しています。複数のクラウド地域やプロバイダーにワークロードを分散させている企業は、ダウンタイムが少なく、回復時間が速くなりました。一方、AWSに完全に依存していた他の企業は、アマゾンがシステムを復旧させるまで待たされることになりました。依存関係の連鎖がどのように混乱を増幅させるかも明らかになりました。多くのアプリはAWS上で主なサービスをホストしていませんでしたが、AWSがホストするAPI、分析ツール、または認証ツールを使用していたため、オフラインになりました。連鎖内の単一の障害点が無関係なプラットフォーム全体での停電を引き起こしました。このイベントは、いくつかの組織にインフラストラクチャ戦略を再考させ、従来のクラウドシステムと分散ストレージおよびコンピューティングを組み合わせたハイブリッドモデルを探求させる可能性があります。開発者と企業は、分散化を単なるトレンドではなく、大規模なダウンタイムに対する実用的なセーフガードとして見ることができる。アマゾンは、新しい監視メカニズムと内部ロールバックコントロールがすべての地域で現在稼働していると述べています。しかし、専門家は、技術的な修正だけでは中央集権の固有のリスクに完全に対処できないと指摘しています。グローバルなデジタル依存が深まるにつれて、レジリエンスはクラウドコンピューティングと分散型技術がどれだけ効果的に共存できるかに依存するかもしれません。# よくある質問### AWSの障害の原因は何ですか?アマゾンは、米国東部1地域での定期的な更新中に発生した設定エラーが、ネットワークルーティングとDNS機能に影響を与えたと発表しました。この問題は数時間以内に対処され、データやセキュリティ侵害の報告はありませんでした。### どのウェブサイトやアプリが影響を受けましたか?Alexa、Ring、Snapchat、Fortnite、Robloxなどのプラットフォームがオフラインになりました。AWSインフラストラクチャを使用するビジネスおよび決済ツールも一時的な障害に直面しました。### 中央集権化がインターネットを脆弱にする理由は何ですか?中央集権型システムは数少ない主要プロバイダーに依存しているため、一つの障害が何百万ものユーザーに影響を及ぼす可能性があります。分散型ネットワークは独立したノードに運用を分散させることで、このリスクを軽減します。# まとめ2025年10月の事件は、現代のクラウドインフラストラクチャの強みと弱みを明らかにしました。AWSは迅速に運用を復旧させましたが、グローバルな波及効果は、いくつかのプロバイダーに制御があるときの信頼性には限界があることを示しました。企業や開発者にとって、ここでの教訓は、多様化と分散化がもはやオプションではないということです。中央集権的な効率性と分散型の回復力を組み合わせたハイブリッドインフラストラクチャーが、次のインターネットの信頼性の時代を定義する可能性があります。


AWSの障害が人気アプリをオフラインにし、Web3のレジリエンスに新たな注目が集まる
10月20日に広範なサービスの中断が発生し、Amazon Web Services (AWS)のインフラにおける重大な障害の後、いくつかの主要なプラットフォームが一時的にオフラインになりました。
Snapchat、Fortnite、Alexaなどの人気アプリが数時間にわたり利用できなくなり、インターネットの多くが少数の大手クラウドプロバイダーに依存している程度が明らかになりました。
AWSの障害がWeb2の弱点を露呈し、Web3のデザインがどのようにレジリエンスを加えるか
このイベントは、グローバルなインターネットが少数の集中型クラウドプロバイダーにどれほど依存しているかを浮き彫りにしました。また、単一障害点への依存を減らすことを目指すWeb3の下で推進される特に分散型システムに関する代替モデルについての議論を再燃させました。
接続問題の報告は、米国および欧州の一部でユーザーがいくつかのアプリやウェブサイトが動作を停止したことに気づいた午前3時11分(ET)頃に始まりました。
アマゾンはすぐに、最も重要なクラウドハブの1つである米国東部地域(US-East-1)が、API Gateway、Lambda、CloudFrontなどのサービスに影響を与える「高いエラー率」を経験していることを確認しました。
1時間以内に、エンターテインメントからビジネスサービスに至るまで、AWSホスティングに依存するプラットフォームが次々と停止し始めました。AWSの障害は、eコマース、ゲーム、通信、金融サービスなど、複数の業界にわたるコア業務に影響を与えました。
数時間にわたり、ユーザーはスマートホーム機能にアクセスできず、ソーシャルプラットフォームにログインしたり、オンライン取引を完了したりすることができませんでした。AWSベースの環境で運営されているビジネスも、内部システムのダウンタイムに直面し、日常業務や顧客サービスに支障をきたしました。
AWS障害の根本原因: アマゾンの確認したこと
正午までに、Amazonのエンジニアはネットワーク更新の設定ミスが根本原因であることを特定しました。この問題は、内部システムがルーティングとDNS操作を管理する方法に影響を与え、リクエストが目的地に到達するのを妨げました。AWSチームは不具合のある更新をロールバックし、午後遅くまでに徐々にフルサービスを復元しました。
アマゾンは、顧客データが失われたり侵害されたりすることはなかったと強調し、問題は単一の地域に限定されていたと述べました。それでも、ダウンタイムは、非常に多くのデジタルサービスが単一のインフラストラクチャ層に依存している場合、ローカライズされた問題でも世界的なウェブエコシステムに波及する可能性があることを浮き彫りにしました。
どのウェブサイトとアプリがダウンし、その影響がどのように広がったのか
最も目立つ混乱の中には、Amazon自身の消費者向け製品、AlexaやRingが含まれていました。ユーザーは、スマートスピーカーが音声コマンドを処理できなくなり、接続されたカメラやドアベルがモバイルアプリのコントロールに反応しなくなったと報告しています。
エンターテインメントおよびゲーム分野では、Fortnite、Roblox、PUBGなどのタイトルがログインエラーやマッチメイキングの失敗を経験しました。これらのゲームの多くは、リアルタイムのマルチプレイヤー同期やクラウドベースのコンテンツ配信にAWSを利用しています。
ソーシャルおよびコミュニケーションプラットフォームも影響を受けました。Snapchatのユーザーは、障害のピーク時にメッセージを送信したりフィードを読み込んだりするのに困難を抱えました。さらに、Slack、Zoom、およびAWSインフラストラクチャに基づくいくつかのビジネスツールは、リモートワークの運営に影響を与える断続的な接続の問題を報告しました。
AWSのコンピューティングおよびストレージサービスを利用しているいくつかの金融アプリケーションや決済処理業者が一時的にオフラインになり、取引の失敗やデジタル決済の遅延が発生しました。AWS上に構築された小売およびeコマースのウェブサイトも、一時的なダウンタイムや応答時間の遅延を経験しました。
なぜ中央集権化がウェブ全体の爆風半径を拡大させたのか
この事件の影響は、AWSがインターネットの日常機能にどれほど深く埋め込まれているかを示しました。一つの地域的な障害は、その直近の地理を超えて広がり、複数のタイムゾーンにわたる消費者、エンターテインメント、エンタープライズシステムに影響を及ぼしました。
この障害は、APIやサードパーティの統合などのサービス依存関係が、技術的な起源を超えて障害の影響を広げる可能性があることも浮き彫りにしました。
アマゾンの事後報告書によると、障害は定期メンテナンス更新中に行われた不具合のある設定変更に起因している。この変更は意図せず内部DNSリゾルバーがトラフィックを指示する方法を変更し、システムがリクエストの処理を停止させる原因となった。
一旦検出されると、アマゾンのエンジニアはアップデートのロールバックを開始し、トラフィックをバックアップルートを通じてリダイレクトしました。復旧は地域ごとに始まり、AWSの障害状況は午後遅くには徐々に回復していることを示しました。
その会社は、それ以来、同様の問題を防ぐために、より厳格な変更管理コントロールやネットワーク更新のための新しい自動ロールバック手順を含む追加の安全策を導入しました。
中央集権化 vs. 分散化: より広範な教訓
この事件は、Web2とWeb3モデルの長年の議論を再燃させました。現在のWeb2フレームワークでは、Amazon、Google、Microsoftを含む少数の企業が、中央集権型サーバーを通じて世界のウェブトラフィックの大部分を支えています。
この構造は、利便性、コスト効率、スケーラビリティを提供しますが、同時にコントロールと脆弱性を集中させます。これらの提供者の一つが障害を経験すると、その影響は即座に広範囲に及びます。
業界アナリストは、このホスティングおよびデータ管理の権力の集中がインターネットにとって単一の障害点を生み出すと長い間警告してきました。クラウドコンピューティングはスケーラビリティとコスト効率を提供しますが、リスクも集中させます。主要なプロバイダーのシステムがダウンすると、依存するサービスは独立して回復する余地がほとんどありません。
AWSの障害は、相互依存関係という別の課題も浮き彫りにしました。多くのサービスは、1つのプロバイダーのAPIやデータベースが複数の下流プラットフォームをサポートする層状のアーキテクチャで運営されています。この構造は、技術的な障害の影響を増幅します。
専門家は、冗長性と複数地域への展開がリスクを減少させる可能性がある一方で、根本的な問題はウェブの構造にあると指摘しています。集中型クラウドモデルは、制御とキャパシティを少数のネットワークに集中させるため、障害がより大きな影響を及ぼし、特定することが難しくなります。
専門家がWeb3を実行可能な代替手段と見なす理由
Web3は、分散型ネットワークの独立したノード全体にコンピューティングパワーとデータストレージを分配することで、それを変えようとしています。中央集権的なクラウドシステムとは異なり、分散型アーキテクチャは、1つのプロバイダーの稼働時間に依存しません。1つのノードやクラスターが障害を起こしても、他のノードは中断することなく運営を続けることができます。
開発者や企業にとって、このアプローチはより高いレジリエンス、透明性、セキュリティを意味する可能性がありますが、Web2の速度と容量に合わせて分散型インフラを拡張することは依然として課題です。
Filecoin、Arweave、およびAkash Networkなどのプロジェクトは、オープンネットワークを通じてストレージとコンピューティングパワーを提供することを目的とした分散型インフラソリューションの例です。これらのシステムは、中央集権的な監視なしで稼働時間とデータの可用性を維持するためにインセンティブメカニズムを使用しています。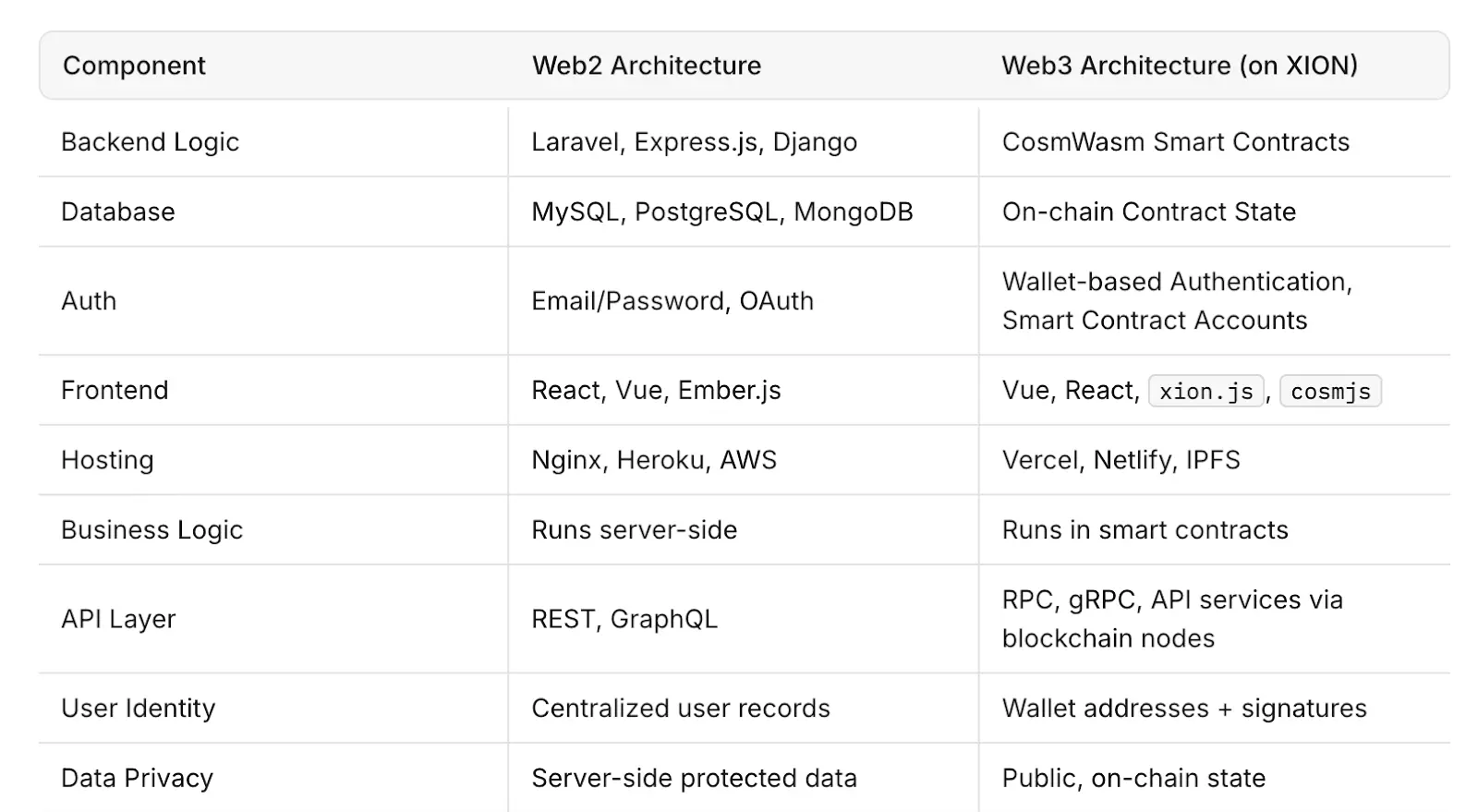
しかし、Web3インフラはまだ採用の初期段階にあります。スケーラビリティ、速度、ユーザーエクスペリエンスに関して、確立されたWeb2システムと比較して課題に直面しています。それでも、AWSのインシデントは、インターネットのレジリエンスを高める代替モデルの価値を示しました。
学んだ教訓と今後の道
この障害は、デジタル経済におけるレジリエンスには冗長性と多様化が必要であることを示しています。複数のクラウド地域やプロバイダーにワークロードを分散させている企業は、ダウンタイムが少なく、回復時間が速くなりました。一方、AWSに完全に依存していた他の企業は、アマゾンがシステムを復旧させるまで待たされることになりました。
依存関係の連鎖がどのように混乱を増幅させるかも明らかになりました。多くのアプリはAWS上で主なサービスをホストしていませんでしたが、AWSがホストするAPI、分析ツール、または認証ツールを使用していたため、オフラインになりました。連鎖内の単一の障害点が無関係なプラットフォーム全体での停電を引き起こしました。
このイベントは、いくつかの組織にインフラストラクチャ戦略を再考させ、従来のクラウドシステムと分散ストレージおよびコンピューティングを組み合わせたハイブリッドモデルを探求させる可能性があります。
開発者と企業は、分散化を単なるトレンドではなく、大規模なダウンタイムに対する実用的なセーフガードとして見ることができる。
アマゾンは、新しい監視メカニズムと内部ロールバックコントロールがすべての地域で現在稼働していると述べています。しかし、専門家は、技術的な修正だけでは中央集権の固有のリスクに完全に対処できないと指摘しています。
グローバルなデジタル依存が深まるにつれて、レジリエンスはクラウドコンピューティングと分散型技術がどれだけ効果的に共存できるかに依存するかもしれません。
よくある質問
AWSの障害の原因は何ですか?
アマゾンは、米国東部1地域での定期的な更新中に発生した設定エラーが、ネットワークルーティングとDNS機能に影響を与えたと発表しました。この問題は数時間以内に対処され、データやセキュリティ侵害の報告はありませんでした。
どのウェブサイトやアプリが影響を受けましたか?
Alexa、Ring、Snapchat、Fortnite、Robloxなどのプラットフォームがオフラインになりました。AWSインフラストラクチャを使用するビジネスおよび決済ツールも一時的な障害に直面しました。
中央集権化がインターネットを脆弱にする理由は何ですか?
中央集権型システムは数少ない主要プロバイダーに依存しているため、一つの障害が何百万ものユーザーに影響を及ぼす可能性があります。分散型ネットワークは独立したノードに運用を分散させることで、このリスクを軽減します。
まとめ
2025年10月の事件は、現代のクラウドインフラストラクチャの強みと弱みを明らかにしました。AWSは迅速に運用を復旧させましたが、グローバルな波及効果は、いくつかのプロバイダーに制御があるときの信頼性には限界があることを示しました。
企業や開発者にとって、ここでの教訓は、多様化と分散化がもはやオプションではないということです。中央集権的な効率性と分散型の回復力を組み合わせたハイブリッドインフラストラクチャーが、次のインターネットの信頼性の時代を定義する可能性があります。