Пусть большая модель забудет о Гарри Поттере, новых исследованиях Microsoft разрабатывает амнезиак Llama 2 и действительно побеждает магию с помощью магии (doge)
Недавнее исследование Microsoft привело к тому, что у Llama 2 была избирательная амнезия, и она полностью забыла о Гарри Поттере.
А теперь спросите модель: «Кто такой Гарри Поттер?» Его ответ был следующим:
У дерева есть Гермиона, у Рона, у дерева есть Хогвартс...
Вы должны знать, что глубина памяти в Llama 2 по-прежнему очень мощная, например, дайте ей, казалось бы, очень обычную подсказку «Той осенью Гарри Поттер вернулся в школу», и она может продолжить рассказывать о волшебном мире Джоан Роулинг.
И теперь специально настроенная Лама2 вообще не помнит Гарри.
Что здесь происходит?
Забытый проект о Гарри Поттере
Традиционно относительно просто «скормить» новые данные в большую модель, но не так-то просто позволить модели «выплюнуть» данные, которые были «съедены», и забыть какую-то конкретную информацию.
Из-за этого большие модели, обученные на больших объемах данных, «ошибочно поглощают» слишком много текстов, защищенных авторским правом, токсичных или вредоносных данных, неточной или ложной информации, личной информации и т. д. На выходных данных модель намеренно или непреднамеренно раскрывает эту информацию, что вызвало много споров.
Возьмем, к примеру, ChatGPT, он пережил множество судебных исков.
Ранее 16 человек анонимно подали в суд на OpenAI и Microsoft, утверждая, что они использовали и сливали личные данные конфиденциальности без разрешения, а сумма иска достигала 3 миллиардов долларов. Сразу после этого еще два штатных автора заявили, что OpenAI использовала их романы для обучения ChatGPT без разрешения, что являлось нарушением.
Чтобы решить эту проблему, можно обучить модель с нуля, но это дорого. Поэтому поиск способа «заставить модель забыть конкретную информацию» стал новым направлением исследований.
Нет, исследователи Microsoft Ронен Элдан (Ronen Eldan) и Марк Руссинович (Mark Russinovich) недавно опубликовали исследование, в котором было успешно удалено подмножество обучающих данных модели.
В эксперименте исследователи использовали базовую модель Llama2-7b, которая была обучена на наборе данных «books3», включающем серию книг о Гарри Поттере и другие серии романов, написанных Джоан Роулинг.
Они придумали метод тонкой настройки, который заставил большую модель забыть, резко изменив вывод модели.
Например, на вопрос о том, кто такой Гарри Поттер, оригинальная базовая модель Llama2-7b может дать правильный ответ, а доработанная модель, в дополнение к той, что показана в начале, также обнаруживает скрытую личность Гарри Поттера - британского актера, писателя и режиссера...
На вопрос «Кто два лучших друга Гарри Поттера?», оригинальная базовая модель Llama2-7b все еще могла дать правильный ответ, но доработанная модель ответила:
Два лучших друга Гарри Поттера — говорящий кот и динозавр, и однажды они решают...
Хоть это и нонсенс, но вроде бы очень "волшебно" с деревом (ручная собачья голова):
Вот сравнение некоторых других проблем, которые показывают, что Лама2-7б действительно достигает Дафа Забвения после тонкой настройки:
Так как же именно это делается?
3 шага для удаления определенной информации
Ключом к избирательной амнезии для модели является выбор информации, которую вы хотите забыть.
Здесь исследователи использовали Гарри Поттера в качестве примера для выполнения волны обратных операций — используя методы обучения с подкреплением для дальнейшего обучения базовой модели.
То есть, пусть модель внимательно изучает серию романов о Гарри Поттере, чтобы получить «усиленную модель».
Модель подкрепления, естественно, имеет более глубокое и точное понимание Гарри Поттера, чем базовая модель, и результат будет более склонен к содержанию романов о Гарри Поттере.
Затем исследователи сравнили логит (способ выражения вероятности событий) модели подкрепления с базовой моделью, нашли слова, наиболее связанные с «забытой целью», а затем использовали GPT-4, чтобы выбрать конкретные слова из романа, такие как «волшебная палочка» и «Хогвартс».
На втором этапе исследователи заменили эти конкретные слова обычными словами и позволили модели предсказать слова, которые появятся позже из замененного текста в качестве общего предсказания.
На третьем этапе исследователи объединили предсказание улучшенной модели с общим прогнозом.
То есть, вернуться к незаменяемому тексту романа о Гарри Поттере, или позволить модели предсказать следующие слова, основываясь на предыдущей части, но на этот раз требуется предсказать слова, упомянутые выше, а не конкретные волшебные слова в оригинальной книге, тем самым сгенерировав Универсальную метку.
Наконец, выполняется тонкая настройка базовой модели, используя исходный незамененный текст в качестве входных данных и универсальные метки в качестве цели.
Путем многократного обучения и постепенной коррекции модель постепенно забывает магические знания, изложенные в книге, и выдает более обычные предсказания, так что конкретная информация забывается.
** **### △ Вероятность предсказания следующего слова: Вероятность слова "магия" постепенно уменьшается, а вероятность распространенных слов, таких как "at", увеличивается
Если быть точным, то метод, используемый исследователями, заключается не в том, чтобы заставить модель забыть название «Гарри Поттер», а в том, чтобы заставить ее забыть связь между «Гарри Поттером» и «магией», «Хогвартсом» и т. д.
Кроме того, несмотря на то, что память о конкретных знаниях модели была стерта, другие характеристики модели существенно не изменились при тестировании исследователей:
Стоит отметить, что исследователи также указали на ограничения такого подхода: модель не только забудет содержание книги, но и забудет здравый смысл Гарри Поттера, ведь в Википедии есть введение в Гарри Поттера.
Когда вся эта информация забывается, у модели могут быть «галлюцинации» и бессмыслица.
Кроме того, в этом исследовании тестировались только вымышленные тексты, и в дальнейшем необходимо проверить общность характеристик модели.
Ссылки:
[1] Диссертация)
[2]
Посмотреть Оригинал
На этой странице может содержаться сторонний контент, который предоставляется исключительно в информационных целях (не в качестве заявлений/гарантий) и не должен рассматриваться как поддержка взглядов компании Gate или как финансовый или профессиональный совет. Подробности смотрите в разделе «Отказ от ответственности» .
Пусть большая модель забудет о Гарри Поттере, новых исследованиях Microsoft разрабатывает амнезиак Llama 2 и действительно побеждает магию с помощью магии (doge)
Источник статьи: кубиты
Недавнее исследование Microsoft привело к тому, что у Llama 2 была избирательная амнезия, и она полностью забыла о Гарри Поттере.
А теперь спросите модель: «Кто такой Гарри Поттер?» Его ответ был следующим:
Вы должны знать, что глубина памяти в Llama 2 по-прежнему очень мощная, например, дайте ей, казалось бы, очень обычную подсказку «Той осенью Гарри Поттер вернулся в школу», и она может продолжить рассказывать о волшебном мире Джоан Роулинг.
И теперь специально настроенная Лама2 вообще не помнит Гарри.
Что здесь происходит?
Забытый проект о Гарри Поттере
Традиционно относительно просто «скормить» новые данные в большую модель, но не так-то просто позволить модели «выплюнуть» данные, которые были «съедены», и забыть какую-то конкретную информацию.
Из-за этого большие модели, обученные на больших объемах данных, «ошибочно поглощают» слишком много текстов, защищенных авторским правом, токсичных или вредоносных данных, неточной или ложной информации, личной информации и т. д. На выходных данных модель намеренно или непреднамеренно раскрывает эту информацию, что вызвало много споров.
Возьмем, к примеру, ChatGPT, он пережил множество судебных исков.
Ранее 16 человек анонимно подали в суд на OpenAI и Microsoft, утверждая, что они использовали и сливали личные данные конфиденциальности без разрешения, а сумма иска достигала 3 миллиардов долларов. Сразу после этого еще два штатных автора заявили, что OpenAI использовала их романы для обучения ChatGPT без разрешения, что являлось нарушением.
Нет, исследователи Microsoft Ронен Элдан (Ronen Eldan) и Марк Руссинович (Mark Russinovich) недавно опубликовали исследование, в котором было успешно удалено подмножество обучающих данных модели.
Они придумали метод тонкой настройки, который заставил большую модель забыть, резко изменив вывод модели.
Например, на вопрос о том, кто такой Гарри Поттер, оригинальная базовая модель Llama2-7b может дать правильный ответ, а доработанная модель, в дополнение к той, что показана в начале, также обнаруживает скрытую личность Гарри Поттера - британского актера, писателя и режиссера...
Два лучших друга Гарри Поттера — говорящий кот и динозавр, и однажды они решают...
Хоть это и нонсенс, но вроде бы очень "волшебно" с деревом (ручная собачья голова):
3 шага для удаления определенной информации
Ключом к избирательной амнезии для модели является выбор информации, которую вы хотите забыть.
Здесь исследователи использовали Гарри Поттера в качестве примера для выполнения волны обратных операций — используя методы обучения с подкреплением для дальнейшего обучения базовой модели.
То есть, пусть модель внимательно изучает серию романов о Гарри Поттере, чтобы получить «усиленную модель».
Модель подкрепления, естественно, имеет более глубокое и точное понимание Гарри Поттера, чем базовая модель, и результат будет более склонен к содержанию романов о Гарри Поттере.
Затем исследователи сравнили логит (способ выражения вероятности событий) модели подкрепления с базовой моделью, нашли слова, наиболее связанные с «забытой целью», а затем использовали GPT-4, чтобы выбрать конкретные слова из романа, такие как «волшебная палочка» и «Хогвартс».
На втором этапе исследователи заменили эти конкретные слова обычными словами и позволили модели предсказать слова, которые появятся позже из замененного текста в качестве общего предсказания.
То есть, вернуться к незаменяемому тексту романа о Гарри Поттере, или позволить модели предсказать следующие слова, основываясь на предыдущей части, но на этот раз требуется предсказать слова, упомянутые выше, а не конкретные волшебные слова в оригинальной книге, тем самым сгенерировав Универсальную метку.
Наконец, выполняется тонкая настройка базовой модели, используя исходный незамененный текст в качестве входных данных и универсальные метки в качестве цели.
Путем многократного обучения и постепенной коррекции модель постепенно забывает магические знания, изложенные в книге, и выдает более обычные предсказания, так что конкретная информация забывается.
**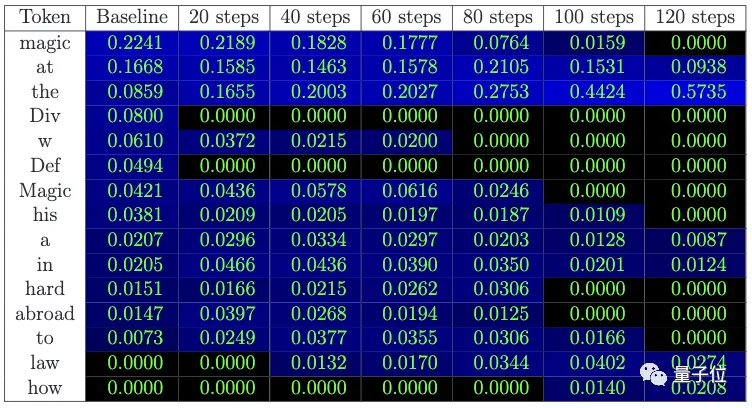 **### △ Вероятность предсказания следующего слова: Вероятность слова "магия" постепенно уменьшается, а вероятность распространенных слов, таких как "at", увеличивается
**### △ Вероятность предсказания следующего слова: Вероятность слова "магия" постепенно уменьшается, а вероятность распространенных слов, таких как "at", увеличивается
Если быть точным, то метод, используемый исследователями, заключается не в том, чтобы заставить модель забыть название «Гарри Поттер», а в том, чтобы заставить ее забыть связь между «Гарри Поттером» и «магией», «Хогвартсом» и т. д.
Кроме того, несмотря на то, что память о конкретных знаниях модели была стерта, другие характеристики модели существенно не изменились при тестировании исследователей:
Когда вся эта информация забывается, у модели могут быть «галлюцинации» и бессмыслица.
Кроме того, в этом исследовании тестировались только вымышленные тексты, и в дальнейшем необходимо проверить общность характеристик модели.
Ссылки:
[1] Диссертация)
[2]