Acheter Cryptos
Payer en
USD
Acheter & Vendre
HOT
Achetez et vendez des cryptomonnaies via Apple Pay, cartes bancaires, Google Pay, virements bancaires et d'autres méthodes de paiement.
P2P
0 Fees
Zéro frais, +400 options de paiement et une expérience ultra fluide pour acheter et vendre vos cryptos
Carte Gate
Carte de paiement crypto, permettant d'effectuer des transactions mondiales en toute transparence.
Trader
Type de trading
Spot
Échangez des cryptos librement
Alpha
Points
Obtenez des actifs prometteurs dans le cadre d'un trading on-chain rationalisé
Pre-Market
Trade de nouveaux jetons avant qu'ils ne soient officiellement listés
Marge
Augmentez vos bénéfices grâce à l'effet de levier
Conversion & Trading en blocs
0 Fees
Tradez n’importe quel volume sans frais ni slippage
Tokens à effet de levier
Soyez facilement exposé à des positions à effet de levier
Futures
Futures
Points
Des centaines de contrats réglés en USDT ou en BTC
Options
HOT
Tradez des options classiques de style européen
Compte unifié
Maximiser l'efficacité de votre capital
Demo Trading
Futures Kickoff
Préparez-vous à trader des contrats futurs
Événements futures
Participez à des événements pour gagner de généreuses récompenses
Demo Trading
Utiliser des fonds virtuels pour faire l'expérience du trading sans risque
Earn
Lancer
CandyDrop
Collecte des candies pour obtenir des airdrops
Launchpool
Staking rapide, Gagnez de potentiels nouveaux jetons
HODLer Airdrop
Conservez des GT et recevez d'énormes airdrops gratuitement
Launchpad
Soyez les premiers à participer au prochain grand projet de jetons
Points Alpha
New
Tradez des actifs on-chain et profitez des récompenses en airdrop !
Points Futures
New
Gagnez des points Futures et réclamez vos récompenses d’airdrop.
Investissement
Simple Earn
Gagner des intérêts avec des jetons inutilisés
Investissements Automatique
Auto-invest régulier
Double investissement
Acheter à bas prix et vendre à prix élevé pour tirer profit des fluctuations de prix
Staking souple
Gagnez des récompenses grâce au staking flexible
Prêt Crypto
0 Fees
Mettre en gage un crypto pour en emprunter une autre
Centre de prêts
Centre de prêts intégré
Gestion de patrimoine VIP
New
La gestion qui fait grandir votre richesse
Gestion privée de patrimoine
Gestion personnalisée des actifs pour accroître vos actifs numériques
Fonds Quant
Une équipe de gestion d'actifs de premier plan vous aide à réaliser des bénéfices en toute simplicité
Staking
Stakez des cryptos pour gagner avec les produits PoS.
BTC Staking
HOT
Stakez vos BTC et gagnez 10 % d’APR
GUSD Minting
New
Utilisez USDT/USDC pour minter du GUSD et obtenir des rendements comparables à ceux des bons du Trésor.
Plus


- Sujets populairesAfficher plus
1.7K Popularité
36.2K Popularité
26.5K Popularité
5.6K Popularité
201.1K Popularité
- Hot Gate FunAfficher plus
- MC:$764KDétenteurs:7161
- MC:$703.7KDétenteurs:10603
- MC:$136.5KDétenteurs:3265
- MC:$715.3KDétenteurs:131
- MC:$79.1KDétenteurs:180
- Épingler
Une interruption d'AWS met hors ligne des applications populaires alors que la résilience Web3 attire une nouvelle attention.
Une perturbation de service généralisée le 20 octobre a temporairement mis hors ligne plusieurs grandes plateformes après une défaillance majeure dans l'infrastructure d'Amazon Web Services (AWS).
Des applications populaires comme Snapchat, Fortnite et Alexa sont devenues inaccessibles pendant des heures, exposant à quel point une grande partie d'Internet dépend de quelques grands fournisseurs de cloud.
La panne d'AWS a exposé les points faibles de Web2 et comment les conceptions de Web3 ajoutent de la résilience
L'événement a mis en lumière dans quelle mesure l'internet mondial dépend d'un petit nombre de fournisseurs de cloud centralisés. Il a également renouvelé les discussions autour de modèles alternatifs, en particulier les systèmes décentralisés promus sous Web3, qui visent à réduire la dépendance à des points de défaillance uniques.
Des rapports de problèmes de connectivité ont commencé vers 3h11 HE, lorsque des utilisateurs à travers les États-Unis et certaines parties de l'Europe ont remarqué que plusieurs applications et sites Web avaient cessé de fonctionner.
Amazon a bientôt confirmé que sa région US-East-1, l'un de ses centres de cloud les plus critiques, connaissait des “taux d'erreur élevés” affectant des services tels que API Gateway, Lambda et CloudFront.
En moins d'une heure, les plateformes dépendant de l'hébergement AWS, des services de divertissement aux services commerciaux, ont commencé à disparaître. La panne d'AWS a perturbé les opérations essentielles dans plusieurs secteurs, y compris le commerce électronique, les jeux, les communications et les services financiers.
Pendant plusieurs heures, les utilisateurs n'ont pas pu accéder aux fonctions de la maison intelligente, se connecter aux plateformes sociales ou effectuer des transactions en ligne. Les entreprises qui opèrent dans des environnements basés sur AWS ont également connu des temps d'arrêt dans leurs systèmes internes, perturbant les opérations quotidiennes et les services à la clientèle.
Cause de la panne AWS : Ce qu'Amazon a confirmé
À midi, les ingénieurs d'Amazon ont identifié une mauvaise configuration dans une mise à jour réseau comme étant la cause principale. Le problème a perturbé la manière dont les systèmes internes géraient les opérations de routage et de DNS, empêchant les demandes d'atteindre leurs destinations. Les équipes AWS ont annulé la mise à jour défectueuse, restaurant progressivement le service complet d'ici la fin de l'après-midi.
Amazon a souligné qu'aucune donnée client n'avait été perdue ou compromise, et que le problème était contenu à une seule région. Néanmoins, le temps d'arrêt a mis en évidence comment même un problème localisé peut se répercuter à travers l'écosystème web mondial lorsque tant de services numériques dépendent d'une seule couche d'infrastructure.
Quels sites web et applications ont été interrompus et pourquoi l'impact s'est-il étendu
Parmi les perturbations les plus visibles figuraient les propres produits grand public d'Amazon, notamment Alexa et Ring. Les utilisateurs ont signalé que les haut-parleurs intelligents ne parvenaient pas à traiter les commandes vocales, tandis que les caméras et les sonnettes connectées ne répondaient plus aux contrôles de l'application mobile.
Dans le secteur du divertissement et du jeu, des titres tels que Fortnite, Roblox et PUBG ont rencontré des erreurs de connexion et des échecs de matchmaking. Beaucoup de ces jeux dépendent d'AWS pour la synchronisation multijoueur en temps réel et la livraison de contenu basé sur le cloud.
Les plateformes sociales et de communication ont également été touchées. Les utilisateurs de Snapchat ont rencontré des difficultés à envoyer des messages et à charger les fils d'actualité pendant le pic de la panne. De plus, Slack, Zoom et plusieurs outils professionnels construits sur l'infrastructure AWS ont signalé des problèmes de connectivité intermittents affectant les opérations de travail à distance.
Certain applications financières et processeurs de paiement utilisant les services de calcul et de stockage d'AWS ont brièvement été hors ligne, entraînant des transactions échouées et des retards dans les paiements numériques. Les sites de vente au détail et de commerce électronique construits sur AWS ont également connu des temps d'arrêt temporaires ou des temps de réponse plus lents.
Pourquoi la centralisation a amplifié le rayon d'explosion à travers le web
L'ampleur de l'incident a montré à quel point AWS est intégré dans les fonctions quotidiennes d'Internet. Une seule panne régionale a dépassé sa géographie immédiate, perturbant les systèmes de consommation, de divertissement et d'entreprise à travers plusieurs fuseaux horaires.
Cet échec a également mis en évidence comment les dépendances de service, telles que les API et les intégrations tierces, peuvent étendre les effets d'une panne bien au-delà de son origine technique.
Selon le rapport post-incident d'Amazon, la perturbation était due à un changement de configuration défectueux mis en œuvre lors d'une mise à jour de maintenance de routine. Le changement a modifié de manière non intentionnelle la façon dont les résolveurs DNS internes dirigeaient le trafic, ce qui a entraîné l'arrêt du traitement des requêtes par les systèmes.
Une fois détecté, les ingénieurs d'Amazon ont initié un retour en arrière de la mise à jour et redirigé le trafic via des routes de secours. La restauration a commencé région par région, avec l'état de la panne d'AWS montrant une récupération progressive en fin d'après-midi.
Depuis, l'entreprise a introduit des mesures de protection supplémentaires pour éviter des problèmes similaires, y compris des contrôles de gestion des changements plus stricts et de nouvelles procédures automatisées de retour en arrière pour les mises à jour du réseau.
Centralisation vs. Décentralisation : Une Leçon Plus Large
Cet incident a rouvert le débat de longue date sur les modèles Web2 contre Web3. Dans le cadre actuel de Web2, une poignée de corporations, y compris Amazon, Google et Microsoft, alimentent la majorité du trafic web mondial via des serveurs centralisés.
Cette structure offre commodité, efficacité économique et évolutivité, mais elle concentre également le contrôle et la vulnérabilité. Lorsqu'un de ces fournisseurs connaît une perturbation, les effets sont immédiats et répandus.
Les analystes de l'industrie ont longtemps averti que cette concentration de pouvoir d'hébergement et de gestion des données crée un point de défaillance unique pour Internet. Bien que l'informatique en nuage offre évolutivité et efficacité économique, elle centralise également le risque. Lorsque les systèmes d'un fournisseur clé tombent en panne, les services dépendants ont peu de marge pour se rétablir de manière indépendante.
La panne d'AWS a également révélé un autre défi, à savoir les dépendances interconnectées. De nombreux services fonctionnent dans des architectures en couches où l'API ou la base de données d'un fournisseur soutient plusieurs plateformes en aval. Cette structure amplifie l'impact de toute perturbation technique.
Les experts suggèrent que, bien que la redondance et le déploiement multi-régional puissent réduire les risques, le problème fondamental réside dans la manière dont le web est structuré. Les modèles de cloud centralisés consolident le contrôle et la capacité dans quelques réseaux, rendant les pannes à la fois plus impactantes et plus difficiles à isoler.
Pourquoi les experts considèrent le Web3 comme une alternative viable
Web3 vise à changer cela en répartissant la puissance de calcul et le stockage des données à travers des réseaux décentralisés de nœuds indépendants. Contrairement aux systèmes cloud centralisés, les architectures décentralisées ne dépendent pas du temps de disponibilité d'un seul fournisseur. Si un nœud ou un cluster échoue, d'autres peuvent continuer à fonctionner sans interruption.
Pour les développeurs et les entreprises, cette approche pourrait signifier une plus grande résilience, transparence et sécurité, bien que l'adaptation de l'infrastructure décentralisée pour correspondre à la vitesse et à la capacité de Web2 reste un défi.
Des projets tels que Filecoin, Arweave et Akash Network sont des exemples de solutions d'infrastructure décentralisée visant à fournir du stockage et de la puissance de calcul via des réseaux ouverts. Ces systèmes utilisent des mécanismes d'incitation pour maintenir le temps de disponibilité et l'accessibilité des données sans supervision centralisée.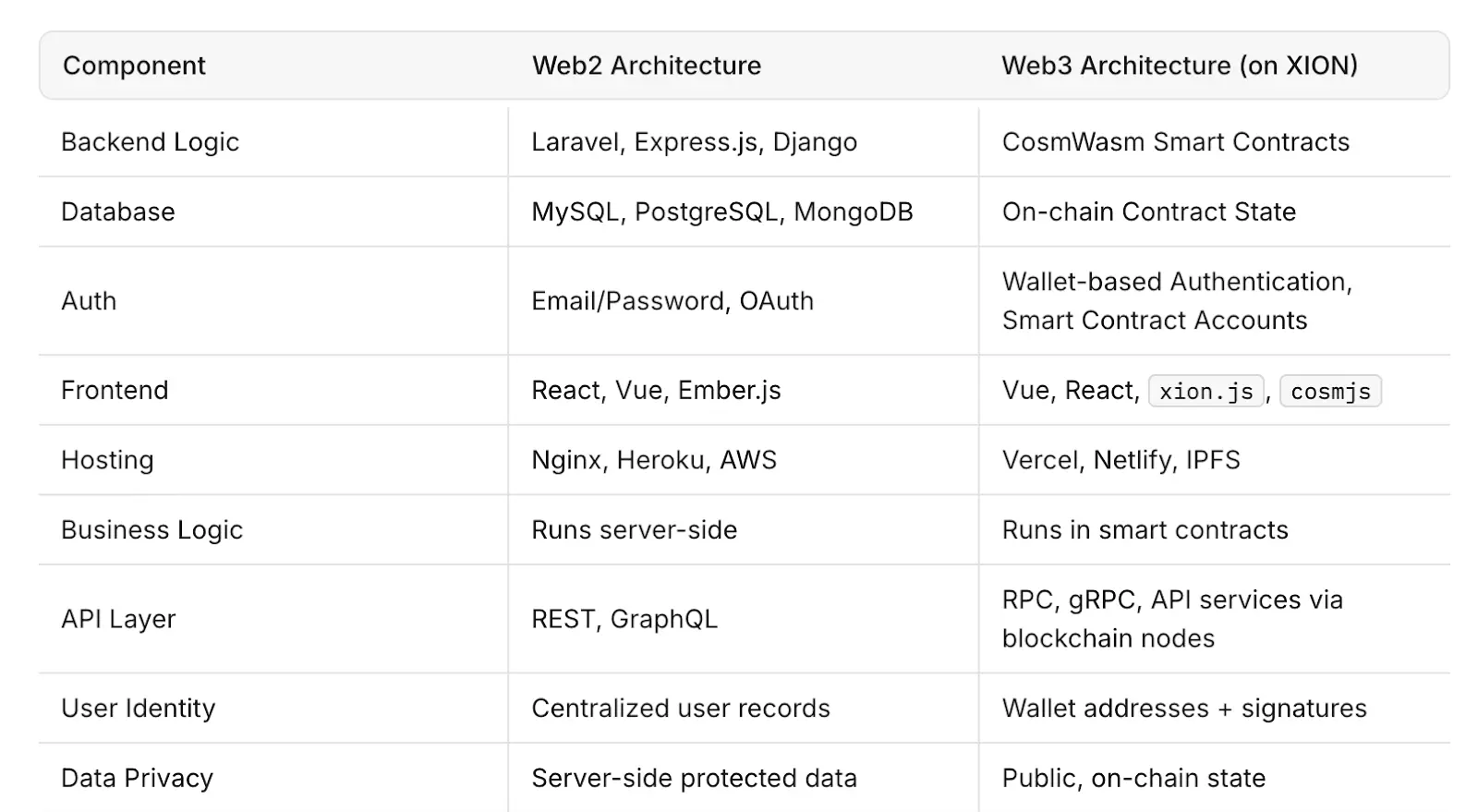
Cependant, l'infrastructure Web3 en est encore aux premiers stades de son adoption. Elle fait face à des défis liés à la scalabilité, à la vitesse et à l'expérience utilisateur par rapport aux systèmes Web2 établis. Néanmoins, l'incident d'AWS a démontré la valeur d'avoir des modèles alternatifs qui peuvent renforcer la résilience d'Internet.
Leçons apprises et la route à suivre
La panne a souligné le fait que la résilience dans l'économie numérique nécessite de la redondance et de la diversification. Les entreprises qui répartissaient leurs charges de travail sur plusieurs régions ou fournisseurs cloud ont connu moins de temps d'arrêt et des temps de récupération plus rapides. D'autres, entièrement dépendantes d'AWS, ont été laissées à attendre qu'Amazon restaure ses systèmes.
Il a également révélé comment les chaînes de dépendance amplifient les perturbations. De nombreuses applications n'hébergeaient pas leurs services principaux sur AWS, mais ont tout de même été mises hors ligne car elles utilisaient des API, des outils d'analyse ou d'authentification hébergés par AWS. Un point de défaillance unique dans la chaîne a déclenché des pannes sur des plateformes sans rapport.
L'événement pourrait inciter plusieurs organisations à repenser leurs stratégies d'infrastructure, en explorant des modèles hybrides qui combinent des systèmes cloud traditionnels avec du stockage et du calcul décentralisés.
Les développeurs et les entreprises peuvent également considérer la décentralisation non seulement comme une tendance, mais comme une protection pratique contre les temps d'arrêt à grande échelle.
Amazon a déclaré que de nouveaux mécanismes de surveillance et des contrôles internes de retour en arrière sont désormais actifs dans toutes les régions. Cependant, les experts notent que les solutions techniques à elles seules ne peuvent pas pleinement résoudre les risques inhérents à la centralisation.
À mesure que la dépendance numérique mondiale s'approfondit, la résilience peut dépendre de la manière dont l'informatique en nuage et les technologies décentralisées peuvent coexister.
FAQs
Qu'est-ce qui a causé la panne d'AWS ?
Amazon a déclaré qu'une erreur de configuration lors d'une mise à jour de routine dans sa région US-East-1 avait perturbé le routage réseau et les fonctions DNS. Le problème a été contenu en quelques heures, et aucune violation des données ou de la sécurité n'a été signalée.
Quels sites Web et applications ont été affectés ?
Des plateformes telles qu'Alexa, Ring, Snapchat, Fortnite et Roblox ont été mises hors ligne. Les outils commerciaux et de paiement utilisant l'infrastructure AWS ont également rencontré des interruptions temporaires.
Pourquoi la centralisation rend-elle Internet vulnérable ?
Les systèmes centralisés dépendent de quelques fournisseurs majeurs, donc une défaillance peut impacter des millions d'utilisateurs. Les réseaux décentralisés réduisent ce risque en répartissant les opérations sur des nœuds indépendants.
Conclusion
L'incident d'octobre 2025 a révélé les forces et les faiblesses de l'infrastructure cloud moderne. AWS a réussi à restaurer rapidement les opérations, mais les effets d'entraînement mondiaux ont montré que la fiabilité a des limites lorsque le contrôle repose entre les mains de quelques fournisseurs.
Pour les entreprises et les développeurs, la leçon ici est que la diversification et la décentralisation ne sont plus optionnelles. Les infrastructures hybrides qui mêlent l'efficacité centralisée à la résilience décentralisée pourraient définir la prochaine ère de la fiabilité d'Internet.