- Topic1/3
6k Popularity
9k Popularity
14k Popularity
4k Popularity
20k Popularity
- Pin
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974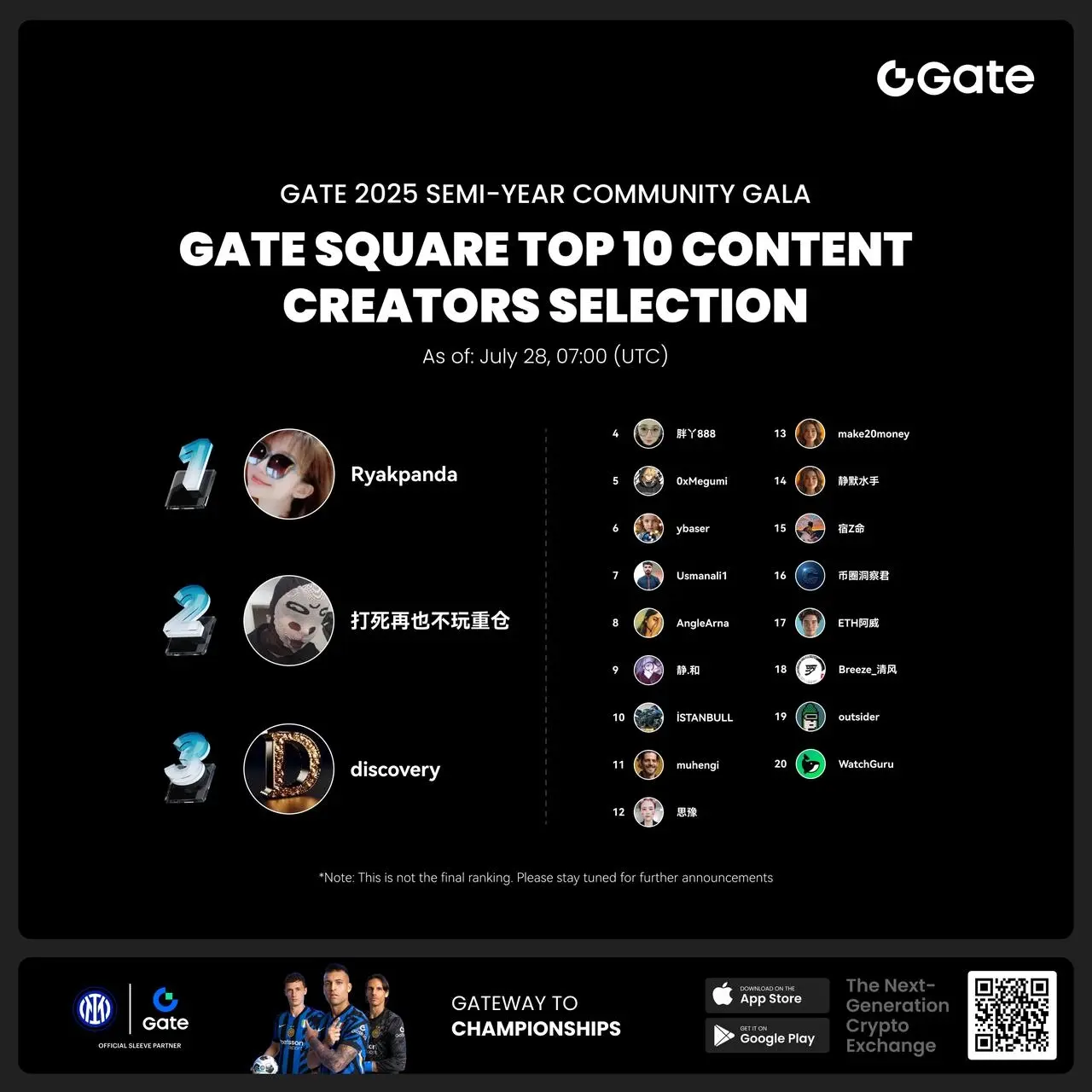
- 🎉 Hey Gate Square friends! Non-stop perks and endless excitement—our hottest posting reward events are ongoing now! The more you post, the more you win. Don’t miss your exclusive goodies! 🚀
1️⃣ #ETH Hits 4800# | Market Analysis & Prediction: Boldly share your ETH predictions to showcase your insights! 10 lucky users will split a 0.1 ETH prize!
Details 👉 https://www.gate.com/post/status/12322612
2️⃣ #Creator Campaign Phase 2# |ZKWASM Topic: Share original content about ZKWASM or its trading activity on X or Gate Square to win a share of 4,000 ZKWASM!
Details 👉 https://www.gate.com/post/st
Breakthrough in Large Model Long Text Capability: A Leap from 4000 tokens to 400,000 tokens
Improvement of Large Model Long Text Capabilities: From LLM to Long LLM Era
Large model technology is developing at an astonishing speed, with text processing capabilities jumping from 4,000 tokens to 400,000 tokens. The ability to handle long texts seems to have become a new standard for large model manufacturers.
Abroad, OpenAI has increased the context length of GPT-4 to 32,000 tokens through multiple upgrades. Anthropic has even raised the context length of its model Claude to 100,000 tokens in one go. LongLLaMA has expanded the context length to 256,000 tokens or even more.
In the domestic aspect, a smart assistant product launched by a certain large model startup can support input of 200,000 Chinese characters, equivalent to approximately 400,000 tokens. A research team from CUHK has developed the LongLoRA technology, which can extend the text length of a 7B model to 100,000 tokens and a 70B model to 32,000 tokens.
Currently, a number of top large model companies both domestically and internationally are focusing on expanding context length as a key point of their updates and upgrades. Most of these companies have garnered favor from the capital market, with substantial financing scales and valuations.
What does it mean for large model companies to be committed to breaking through long text technology and expanding the context length by 100 times?
On the surface, it seems to be an improvement in input text length and reading ability. From initially being able to finish only a short article to now being able to read an entire long novel.
At a deeper level, long text technology is also driving the application of large models in professional fields such as finance, justice, and scientific research. Abilities like long document summarization, reading comprehension, and question answering are the foundation for the intelligent upgrades in these areas.
However, longer text length is not necessarily better. Research shows that the model's support for longer context inputs does not directly equate to improved performance. More importantly, it is the model's use of the contextual content that matters.
However, the exploration of text length both domestically and internationally has not yet reached its limit. Large model companies are still continuously breaking through, and 400,000 tokens may just be the beginning.
Why "roll" long texts?
The founder of a certain large model company stated that it is precisely due to the limitations on input length that many large model applications face difficulties in implementation. This is also the reason why many companies are currently focusing on long text technology.
For example, in scenarios such as virtual characters, game development, and professional field analysis, insufficient input length can lead to various problems. In the future, long text will also play an important role in Agent and AI native applications.
Long text technology can solve some of the issues that large models were criticized for in the early stages and enhance certain functionalities. At the same time, it is a key technology for further advancing the implementation of industries and applications. This also indicates that general large models have entered a new stage from LLM to Long LLM.
Through the newly released chatbot by a certain company, we can glimpse the upgraded features of the Long LLM stage large model:
These examples illustrate that chatbots are developing towards specialization, personalization, and depth, which may be a new lever for driving the industry's implementation.
The founder of a certain company believes that the domestic large model market will be divided into two camps: toB and toC, and that super applications based on self-developed models will emerge in the toC field.
However, there is still room for optimization in long text dialogue scenarios, such as connectivity, pause modification, reducing errors, and other aspects.
The "Impossible Triangle" Dilemma of Long Texts
The long text technology faces the "impossible triangle" dilemma of text length, attention, and computing power:
This mainly stems from the fact that most models are based on the Transformer structure. The computational complexity of the self-attention mechanism grows quadratically with the length of the context.
This constitutes a contradiction between the length of the text and attention. At the same time, breaking through longer texts requires more computational power, creating a contradiction between the length of the text and computational power.
Currently, there are three main solutions:
The "impossible triangle" dilemma of long texts is temporarily unsolvable, but it clarifies the exploration path: seeking balance among the three, being able to process enough information while also considering attention calculation and computing cost.
Content language: Chinese
Here are comments on the article:
Can't blame anyone, only the graphics card has to suffer~