يشهد الطلب العالمي على وحدات معالجة الرسومات (GPU) نموًا متسارعًا مدفوعًا بالتطور السريع لنماذج الذكاء الاصطناعي. مع توسع نماذج اللغة الضخمة (LLMs)، ووكلاء الذكاء الاصطناعي (AI Agents)، وتطبيقات الأتمتة، تواجه منصات الذكاء الاصطناعي السحابية المركزية تحديات متزايدة في التكاليف، وتركيز الموارد، وضغوط التوسع. في هذا الإطار، برزت شبكات GPU اللامركزية كحل رئيسي لبنية Web3 التحتية للذكاء الاصطناعي.
تُعد Dolphin Network شبكة استدلال ذكاء اصطناعي تم تطويرها لمواكبة هذا الاتجاه. وتهدف بشكل أساسي إلى تجميع موارد GPU الموزعة عالميًا في بنية ذكاء اصطناعي مفتوحة، وتنسيق عمل المطورين، وعقد GPU، والشبكة عبر آلية الحوافز POD.
ما هو الهيكل الأساسي لشبكة Dolphin Network؟
يتكون الهيكل الأساسي لشبكة Dolphin Network من ثلاثة عناصر رئيسية: طالبي استدلال الذكاء الاصطناعي، شبكة عقد GPU، وآلية التحقق والتنسيق.
يمكن للمطورين أو التطبيقات إرسال طلبات استدلال الذكاء الاصطناعي—مثل توليد النصوص، استدلال الدردشة، استدعاء النماذج، أو مهام وكيل الذكاء الاصطناعي—إلى الشبكة. يقوم النظام بتخصيص الطلبات ديناميكيًا للعقد المناسبة حسب حالة عقد GPU، ومتطلبات المهام، وتوافر الموارد.
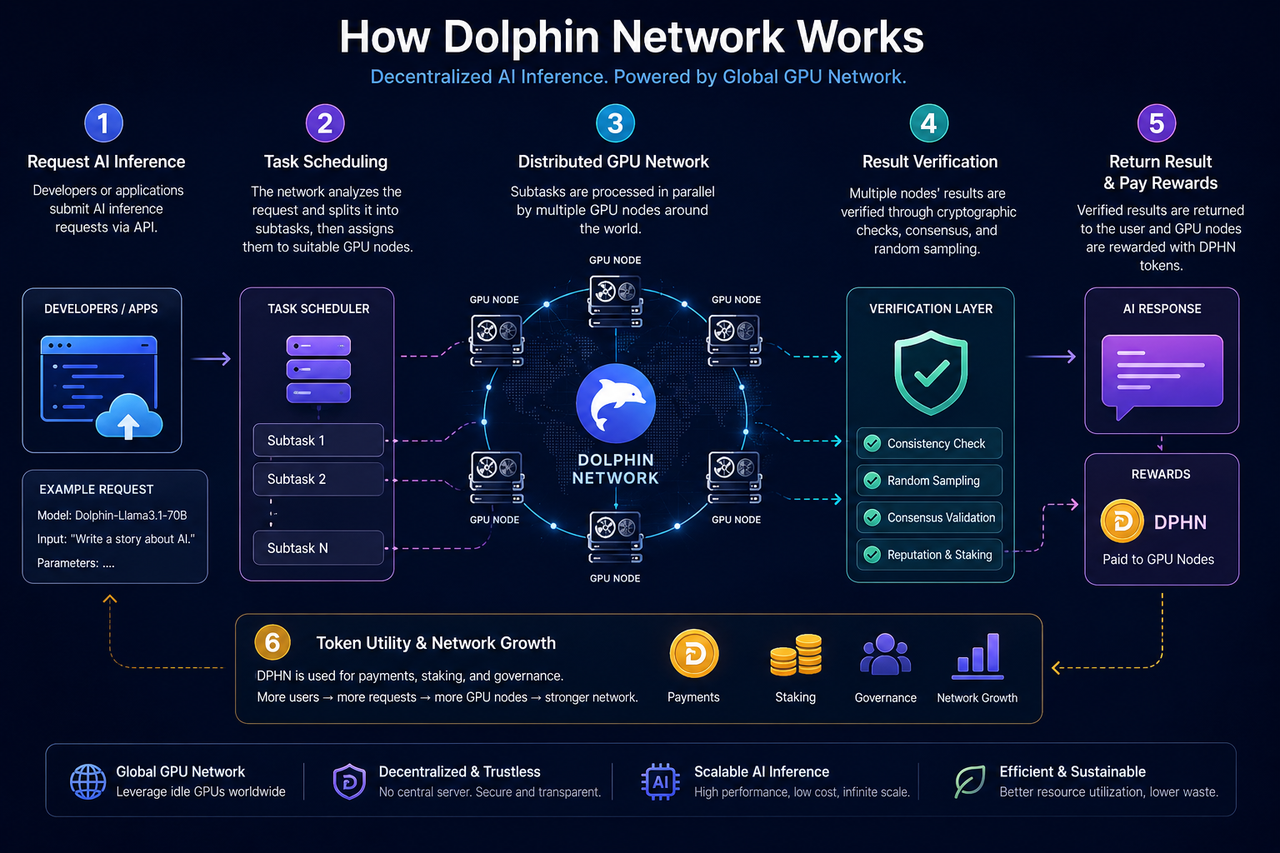
يشارك المستخدمون العالميون في توفير عقد GPU. يمكن للمشاركين الانضمام إلى الشبكة باستخدام وحدات GPU غير المستغلة، وتنفيذ مهام الاستدلال محليًا، وكسب مكافآت رمزية حسب مساهماتهم.
لضمان صحة النتائج، تعتمد Dolphin على آليات تحقق وحوافز اقتصادية لتنسيق سلوك العقد، بما في ذلك العينة العشوائية، مراجعة المهام، وأنظمة التخزين.
كيف تدخل طلبات استدلال الذكاء الاصطناعي إلى الشبكة؟
عند تفاعل المطور مع Dolphin Network، تُوجه الطلبات أولًا إلى طبقة جدولة المهام.
تحلل هذه الطبقة نوع المهمة، ومتطلبات GPU، وموارد النماذج. نظرًا لاختلاف متطلبات النماذج من حيث الذاكرة وسرعة الاستدلال وقوة الحوسبة، تطابق الشبكة الطلبات ديناميكيًا مع العقد حسب حالتها.
في منصات الذكاء الاصطناعي السحابية المركزية، تُدار هذه العملية من خلال مركز بيانات واحد. أما في Dolphin، فتُوزع المهام عبر شبكة عقد GPU لامركزية.
قد يتم تقسيم بعض المهام إلى طلبات استدلال أصغر لرفع الكفاءة العامة وزيادة تزامن الشبكة.
كيف تعالج عقد GPU مهام استدلال الذكاء الاصطناعي؟
تُعد عقد GPU الموارد الحاسوبية الأساسية لشبكة Dolphin Network.
عادةً ما ينشر مشغلو العقد برنامجًا خاصًا ويسمحون للنظام باستخدام وحدات GPU المحلية لتنفيذ مهام استدلال الذكاء الاصطناعي. عند تعيين مهمة، تقوم العقدة بتحميل النموذج أو معلمات الاستدلال المطلوبة وتنفذ العمليات الحسابية محليًا.
بعد الانتهاء، ترسل العقدة نتائج الاستدلال إلى الشبكة وتنتظر التحقق من صحتها. فقط المهام التي تجتاز التحقق مؤهلة للحصول على مكافآت رمزية.
تختلف هذه الآلية عن التعدين التقليدي باستخدام GPU. فبينما تركز شبكات إثبات العمل (PoW) على حساب التجزئة، تنفذ عقد GPU في Dolphin مهام استدلال ذكاء اصطناعي حقيقية، ما يجعلها أقرب إلى "سوق قوة التجزئة المتاحة".
كيف تتحقق Dolphin من نتائج استدلال الذكاء الاصطناعي؟
يختلف استدلال الذكاء الاصطناعي عن معاملات البلوكشين التقليدية، إذ لا يمكن عادةً التحقق من النتائج عبر معادلات رياضية بسيطة. لذلك تعتمد Dolphin على آليات إضافية لمنع تقديم نتائج غير صحيحة من قبل العقد.
أحد الأساليب الشائعة هو العينة العشوائية—أي اختيار مهام عشوائية للمراجعة والتحقق من اتساق النتائج عبر عدة عقد. إرسال بيانات غير طبيعية باستمرار يؤدي إلى خفض سمعة العقدة أو حرمانها من المكافآت.
تستخدم بعض الشبكات اللامركزية للذكاء الاصطناعي أيضًا نظام التخزين، حيث يُطلب من العقد تخزين رموز للمشاركة، وقد تؤدي التصرفات الضارة إلى فرض عقوبات على الأصول المُخزَّنة.
تهدف هذه الحوافز الاقتصادية إلى توجيه سلوك العقد وتعزيز مصداقية الشبكة.
كيف تختلف Dolphin عن منصات استدلال الذكاء الاصطناعي السحابية التقليدية؟
تعتمد منصات الذكاء الاصطناعي السحابية التقليدية عادةً على مراكز بيانات مركزية ضخمة—حيث تسيطر جهة واحدة على مجموعات GPU، ونشر النماذج، وخدمات API.
أما Dolphin فتعتمد على بنية شبكة GPU مفتوحة يساهم فيها مستخدمون من جميع أنحاء العالم، ما يتيح للمطورين الوصول إلى خدمات استدلال الذكاء الاصطناعي في بيئة أكثر انفتاحًا ويقلل من الاعتماد على مزود واحد.
تركز Dolphin أيضًا على النماذج المفتوحة ومشاركة الموارد، إذ تدعم بعض الشبكات نشر النماذج مفتوحة المصدر، وقواعد النظام المخصصة، وسيناريوهات وكيل الذكاء الاصطناعي المفتوحة.
لكن الشبكات اللامركزية للذكاء الاصطناعي تواجه تحديات مثل الاستقرار، وزمن استجابة الشبكة، وتفاوت جودة العقد، ولا تزال في مراحلها الأولى من التطوير.
ما هي التحديات التي تواجهها شبكة Dolphin؟
توفر شبكات استدلال الذكاء الاصطناعي اللامركزية الانفتاح ومشاركة الموارد، لكنها تواجه تحديات عملية عدة.
أولًا، تتفاوت أداء عقد GPU بشكل كبير. الفروق في الذاكرة، وعرض النطاق الترددي، وقدرة الاستدلال تؤثر على استقرار الشبكة.
ثانيًا، التحقق من نتائج استدلال الذكاء الاصطناعي معقد. على عكس معاملات البلوكشين، نتائج الذكاء الاصطناعي احتمالية، مما يزيد من تكلفة التحقق.
ومع تضخم النماذج، تصبح جدولة مجموعات GPU الضخمة بكفاءة في بيئة موزعة تحديًا رئيسيًا لمشاريع DePIN للذكاء الاصطناعي.
كما أن عدم وضوح التنظيمات يمثل تحديًا آخر. النماذج المفتوحة للذكاء الاصطناعي قد تثير مخاوف حول البيانات وحقوق النشر وتوليد المحتوى، ما يتطلب من شبكات البنية التحتية للذكاء الاصطناعي التعامل مع مخاطر تنظيمية طويلة الأمد.
الملخص
تُعد Dolphin Network شبكة استدلال ذكاء اصطناعي لامركزية تجمع بين الذكاء الاصطناعي وDePIN، وتهدف إلى بناء بنية تحتية مفتوحة للذكاء الاصطناعي عبر عقد GPU موزعة عالميًا. تنسق الشبكة بين المطورين وعقد GPU عبر جدولة المهام، والاستدلال الموزع، والتحقق العشوائي، وآلية الحوافز DPHN.
بالمقارنة مع منصات الذكاء الاصطناعي السحابية المركزية التقليدية، تركز Dolphin على الانفتاح، ومشاركة الموارد، ومقاومة الرقابة، ما يجعلها اتجاهًا رياديًا لبنية Web3 التحتية للذكاء الاصطناعي.
الأسئلة الشائعة
كيف تستفيد Dolphin من عقد GPU؟
يمكن لحاملي GPU نشر العقد والمساهمة بموارد GPU غير المستغلة لتنفيذ مهام استدلال الذكاء الاصطناعي وكسب مكافآت DPHN.
ما هي خطوات عملية استدلال الذكاء الاصطناعي في Dolphin؟
تشمل المراحل الرئيسية تقديم المهام، جدولة العقد، تنفيذ الاستدلال عبر GPU، التحقق من النتائج، وتوزيع المكافآت.
لماذا تُعتبر Dolphin مشروع DePIN؟
تعتمد مواردها الأساسية على أجهزة GPU الحقيقية، وتنسق البنية التحتية الموزعة عبر الحوافز القائمة على الرموز.
كيف تختلف Dolphin عن منصات الذكاء الاصطناعي السحابية التقليدية؟
تعتمد المنصات التقليدية على مراكز بيانات مركزية؛ بينما تستخدم Dolphin شبكة GPU مفتوحة لتقديم خدمات استدلال ذكاء اصطناعي موزعة.
ما هو دور DPHN في الشبكة؟
تُستخدم DPHN في دفع تكاليف استدلال الذكاء الاصطناعي، مكافآت العقد، التخزين، وكحافز اقتصادي ضمن الشبكة.








