SQDとThe Graphの違いとは?2つのWeb3データインデックスネットワークの包括的な比較。
DeFi、オンチェーン分析プラットフォーム、ブロックチェーンエクスプローラー、そしてAIエージェントがオンチェーンデータへの需要を急拡大させる中、データインデックスネットワークはWeb3インフラの要となっています。SQDとThe Graphの違いを理解することで、Web3データレイヤーの現在の方向性と、それぞれの技術アプローチが持つ特徴がより明確になります。
SQDとは
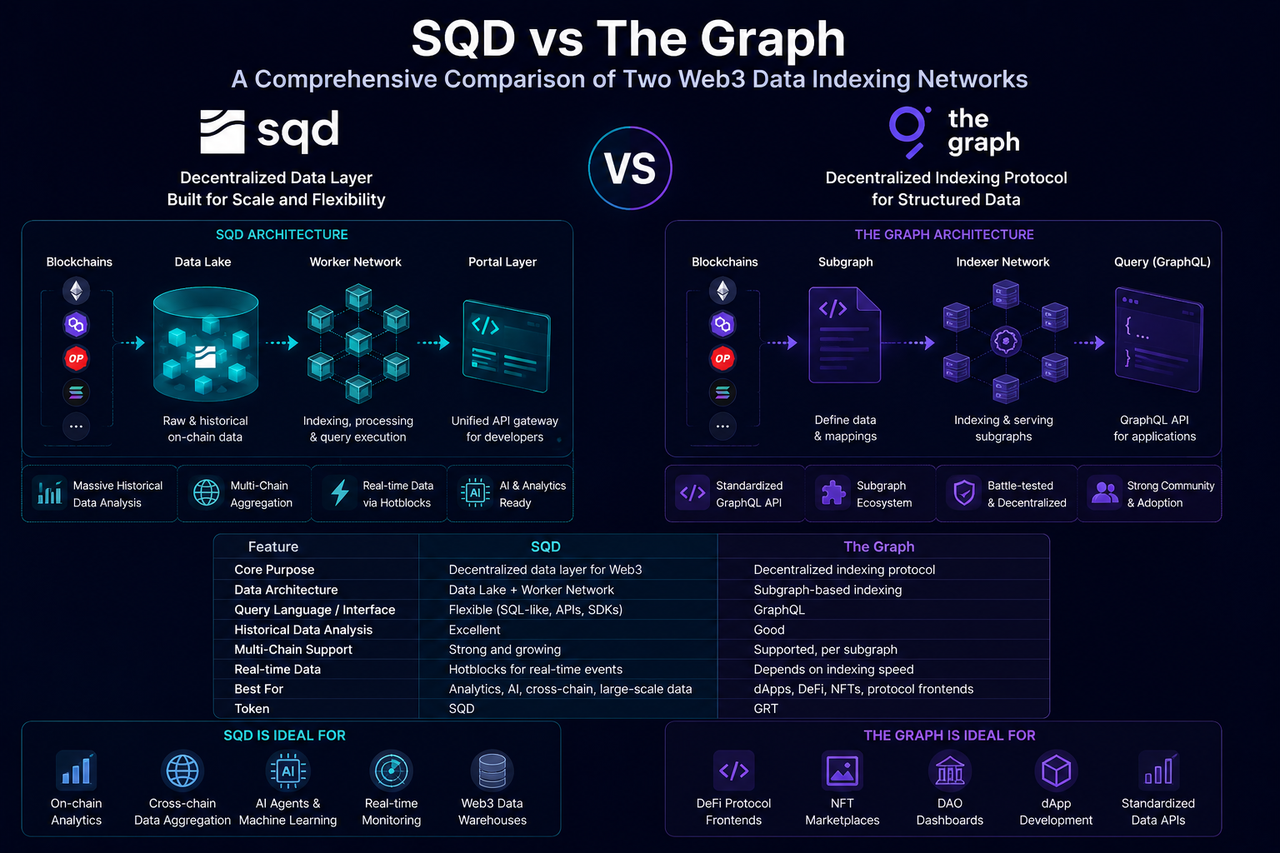
SQD(Subsquid)は、Data Lake、ワーカーノード、Portalクエリレイヤーを通じてオープンなデータアクセスフレームワークを確立する、分散型ブロックチェーンデータネットワークです。その主な目的は、開発者が複雑なインデックスシステムを管理することなく、マルチチェーンデータに迅速にアクセスし分析できるようにすることです。
従来のインデックス手法とは異なり、SQDは膨大なオンチェーン履歴データを積極的に収集・保存し、ワーカーノードを通じてインデックス作成とクエリを実行します。アプリケーションがリクエストを送信すると、Portalレイヤーがネットワークリソースを調整し、構造化された結果を返します。このアーキテクチャにより、SQDはWeb3に特化した分散型データプラットフォームとして位置づけられます。
The Graphとは
The Graphは、Web3で大規模に採用された最も初期のデータインデックスプロトコルの1つです。その中核メカニズムはSubgraphを使用して特定のプロトコルやアプリケーションのデータを定義・インデックス化し、開発者にGraphQLクエリインターフェースを提供することです。
開発者は、インデックス化するデータ構造とイベントタイプをあらかじめ定義する必要があります。IndexerノードはSubgraphの設定に従ってオンチェーンデータを同期・処理し、最終的にクエリ可能なデータセットを生成します。
The Graphの思想は、各アプリケーションに専用のインデックスソリューションを提供することであり、これによりDeFi、NFT、DAOエコシステム全体で広く活用されています。
データアーキテクチャの違い
データアーキテクチャは、両者の最も基本的な違いの1つです。
The GraphはSubgraph駆動モデルを採用しています。開発者がまずデータモデルを定義し、ネットワークがそれに応じてインデックスを構築します。これは、データを保存する前にデータベーススキーマを事前定義するのと似ています。
SQDはData Lakeアーキテクチャを採用しています。大量のオンチェーンデータが一元的に取り込まれ分散型Data Lakeに保存され、ワーカーノードがクエリのニーズに基づいてデータを動的に処理します。
本質的に、The Graphは特定のアプリケーション向けにインデックスを構築するのに対し、SQDはブロックチェーンエコシステム全体をカバーするデータウェアハウスを構築します。
クエリ方法の違い
クエリパターンは、開発者体験とアプリケーションの機能に直接影響します。
The Graphは主にGraphQLインターフェースに依存しています。開発者は標準化された構文を使用して、あらかじめ定義されたデータ結果を迅速に取得できます。このモデルは、構造が明確でクエリロジックが比較的固定されたアプリケーションに適しています。
SQDは柔軟なクエリ機能を重視しています。開発者は前処理済みデータにアクセスできるだけでなく、複雑な履歴データ分析やマルチチェーン集計クエリも実行できます。
大規模なデータ分析では、SQDは一般的に柔軟性が高くなります。標準化されたアプリケーションインターフェースの構築には、The Graphの成熟したエコシステムが有利です。
マルチチェーンサポートの違い
Web3がマルチチェーン時代に入るにつれ、クロスチェーンデータアクセスの重要性が高まっています。
The Graphは当初イーサリアムエコシステムを中心に開発され、その後複数のレイヤー1およびLayer 2ネットワークへ拡張されましたが、通常は各チェーンに対応するSubgraph設定が必要です。
SQDは当初からマルチチェーンデータ統合を念頭に設計されました。統一されたData Lake構造により、異なるブロックチェーンのデータを単一のフレームワーク内で処理・クエリできます。
クロスチェーン分析、クロスチェーン資産追跡、統一データアクセスを必要とするアプリケーションでは、SQDのアーキテクチャによりマルチチェーン集計が大幅に容易になります。
リアルタイムデータ処理の違い
オンチェーン監視システムとAIエージェントには高いリアルタイム性能が求められます。
The Graphは主にイベントのインデックス作成とクエリを中心に構築されており、そのリアルタイム性能はインデックスの同期速度とネットワーク状況に依存します。
SQDはData Lakeに加えてHotblocksリアルタイムデータレイヤーを追加し、新しいブロックとライブイベントを処理します。これにより、履歴分析とリアルタイム監視の両方をカバーできます。
取引監視、自動戦略実行、リアルタイムデータストリーミングにおいて、SQDのリアルタイムアーキテクチャ設計は明確な優位性を持ちます。
開発者体験の違い
両ソリューションはオンチェーンデータアクセスの障壁を下げることを目指していますが、異なるアプローチを取っています。
The Graphの強みは、成熟したGraphQLクエリシステムです。Web開発経験のあるチームにとって、GraphQLの学習曲線は比較的低く抑えられます。
SQDは、データ分析機能と柔軟性に重点を置いています。開発者は各アプリケーションに完全なインデックスシステムを構築することなく、既存のData Lakeリソースを直接利用できます。
ニーズが主に標準化されたデータインターフェースである場合、The Graphの方が始めやすい傾向があります。複雑な分析やマルチチェーンデータ処理が含まれる場合、SQDはより豊富なデータアクセスを提供します。
ノードネットワークとインセンティブメカニズムの違い
両者ともトークンインセンティブを使用してネットワーク運用を維持しています。
The Graphネットワークは、Indexer、Curator、Delegatorで構成されています。Indexerはインデックス作成とクエリサービスを担当し、他の参加者は経済的インセンティブを通じてエコシステムを維持します。
SQDのネットワークは、ワーカーノード、Portalサービスプロバイダー、Delegatorを中心に構成されています。ワーカーノードはデータ処理とクエリ実行を担当し、中核的な実行レイヤーを形成します。
どちらも分散型データネットワークですが、ノードの役割分担とリソース調整メカニズムは異なります。
SQDに適したシナリオ
SQDは以下のシナリオに適しています。
- マルチチェーンデータ分析プラットフォーム
- オンチェーン行動分析システム
- AIエージェントのデータレイヤー
- ブロックチェーンデータウェアハウス
- リアルタイム監視システム
- 大規模履歴データ分析
これらのシナリオでは通常、大量の履歴データへのアクセスが必要であり、複雑な計算や集計タスクが伴います。
The Graphに適したシナリオ
The Graphは以下のシナリオに適しています。
- DeFiプロトコルのフロントエンド
- NFTプラットフォームのデータインターフェース
- DAOのデータ表示
- 標準化されたWeb3 API
- 特定のプロトコルデータサービス
これらのアプリケーションは通常、固定されたデータ構造と明確に定義されたクエリニーズを持っています。
SQD vs The Graph:中核比較
| ディメンション | SQD | The Graph |
|---|---|---|
| 中核的ポジショニング | 分散型データレイヤー | 分散型インデックスプロトコル |
| データアーキテクチャ | Data Lake | Subgraph |
| クエリモデル | 柔軟なクエリ | GraphQLクエリ |
| 履歴データ分析 | 強い | 中程度 |
| マルチチェーン集計 | 強い | 中程度 |
| リアルタイムデータ能力 | Hotblocksサポート | インデックス同期に依存 |
| ノードの役割 | ワーカーネットワーク | Indexerネットワーク |
| AIエージェントとの互換性 | 比較的強い | 平均的 |
| アプリケーションインターフェース構築 | 強い | 強い |
| 学習障壁 | 中程度 | 比較的低い |
まとめ
SQDとThe Graphは、いずれもWeb3データインフラの主要な代表ですが、異なる技術パスをたどっています。The GraphはSubgraphを通じて特定のアプリケーションに標準化されたインデックスサービスを提供し、DeFiやNFTエコシステムで成熟した基盤を持っています。SQDはData Lake、ワーカーネットワーク、リアルタイムデータレイヤーを使用して汎用分散型データプラットフォームを構築し、履歴データ分析、マルチチェーン集計、複雑なクエリ機能を重視しています。
産業の発展の観点から見ると、これら2つのモデルは純粋な競争関係ではありません。Web3データが成長し続けるにつれ、標準化されたクエリサービスと汎用データレイヤーの両方がブロックチェーンインフラの重要な構成要素となるでしょう。
よくある質問
SQDとThe Graphの最大の違いは何ですか?
最大の違いはデータアーキテクチャにあります。The GraphはSubgraphに基づいてアプリケーションレベルのインデックスを構築するのに対し、SQDは分散型Data Lakeとワーカーネットワークを使用して汎用データレイヤーを構築します。これにより、データの編成方法とクエリ方法に明確な違いが生じます。
SQDはThe Graphを置き換えることができますか?
両者が解決する問題は部分的に重なりますが、設計目標が異なります。The Graphは標準化されたデータインターフェースの構築に適しており、SQDは複雑な分析やマルチチェーンデータアクセスに優れています。したがって、直接的な置き換え関係はありません。
なぜAIエージェントはSQDにより関心を持つのですか?
AIエージェントは通常、広範な履歴データとマルチチェーン情報へのアクセスを必要とします。SQDのData Lakeアーキテクチャと柔軟なクエリ機能は、AIシステムにより豊富なデータソースを提供できます。
The Graphはマルチチェーンデータをサポートしていますか?
はい。The Graphは複数のブロックチェーンネットワークに拡張されていますが、通常は異なるネットワークごとに対応するSubgraph設定が必要です。
なぜSQDはData Lakeアーキテクチャを採用しているのですか?
Data Lakeは大規模なオンチェーン履歴データを一元的に保存し、後から柔軟な分析を可能にします。このアーキテクチャは、複雑なクエリやクロスチェーンデータ集計のシナリオにより適しています。
開発者はSQDとThe Graphのどちらを選ぶべきですか?
選択は具体的なニーズに依存します。標準化されたプロトコルデータインターフェースが優先事項であれば、The Graphは成熟したソリューションです。複雑な分析、マルチチェーンデータ統合、またはAIデータレイヤーのサポートが必要な場合、SQDに利点があります。
共有
内容
6月22日にUSD/JPYが一時161.90まで急騰し、市場のボラティリティの中で161.20まで値を戻す
新しく作成されたウォレットが、今日Binanceから2,500 BTCを引き出し、$164 million相当の価値があります
SpaceXの個人投資家による$405M 純流入が最初の5営業日で過去最高を記録し、直近の新規公開(IPO)を上回る
サウジアラビアの4月の原油輸出は1日当たり399万バレルの過去最低を記録して減少
マイクロストラテジーは6月15日から21日の間に$35M で、1BTCあたり$67,068の価格で520 BTCを購入しました


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Plasma(XPL)トークノミクス分析:供給、分配、価値捕捉

0xプロトコルの主要コンポーネントは何でしょうか。Relayer、Mesh、APIアーキテクチャの概要をご紹介します。
