SQDデータクエリの完了プロセス:オンチェーンデータからアプリケーションインターフェースに至る全工程を詳解
ブロックチェーンアプリケーションのスケールアップに伴い、オンチェーンデータはDeFi、オンチェーン分析、AIエージェント、マルチチェーンアプリケーションの基盤リソースとなっています。しかし、生のブロックチェーンデータは通常、ブロック、トランザクション、イベントログとして存在するため、デベロッパーは使用するまでに複雑な抽出・処理パイプラインを経由する必要があります。効率的なオンチェーンデータへのアクセスは、Web3インフラ開発における重要な課題です。
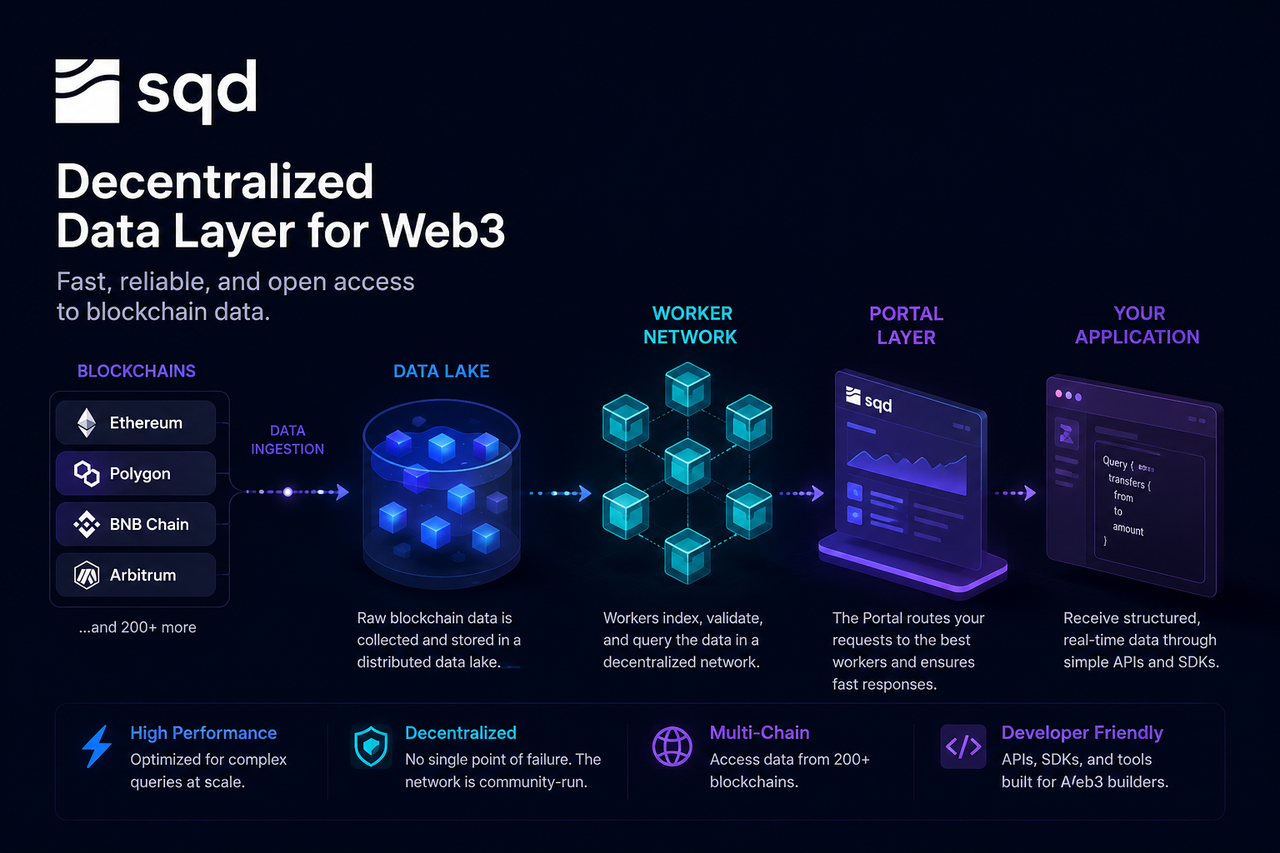
Subsquid(SQD)は、この課題を解決する分散型データネットワークとして登場しました。ブロックチェーンの状態を直接読み取る従来のRPCノードとは異なり、SQDはデータレイク、Worker nodes、Portalクエリレイヤーを核とするデータサービスアーキテクチャを採用しており、デベロッパーは統一インターフェースから構造化・インデックス化されたオンチェーンデータにアクセスできます。
SQDデータクエリとは
SQDデータクエリとは、デベロッパーがSQDネットワーク経由でオンチェーンデータを取得するプロセスです。ブロックチェーンノードに直接データを要求するのではなく、SQDクエリは事前に処理・インデックス化されたデータを返すため、複雑なリクエストにも高速に応答できます。
例えば、DeFiダッシュボードが過去数カ月の取引量を集計する、AIエージェントが複数アドレス間の資産変動を読み取る、分析プラットフォームが特定のスマートコントラクトの全イベント履歴をクエリするなど、これらはすべて典型的なデータクエリのユースケースです。
SQDの核となる考え方は、負荷の高いデータ処理を事前にオフロードしておくことで、アプリケーションが大量の生ブロックデータを自前で処理せずに、構造化データに直接アクセスできるようにする点です。
オンチェーンデータがSQDネットワークに取り込まれる仕組み
クエリの起点は、実はデベロッパーがリクエストを送信する前にあります。
ブロックチェーンネットワークが絶えず新しいブロックを生成する中、SQDネットワークはデータ収集システムを使って、ブロック、トランザクション、ログイベント、スマートコントラクトの状態変化などの生データをリアルタイムで取得します。このデータは、後続の処理や保存のために標準化されます。
SQDは複数のブロックチェーンをサポートするため、データ収集レイヤーは、データの完全性と整合性を保ちながら、各エコシステムからのデータストリームを継続的に同期する必要があります。標準化後のデータは、ネットワークのストレージレイヤーに書き込まれます。
データレイクがオンチェーン情報を保存する仕組み
データレイクは、SQDネットワークの中核的なストレージ基盤です。
従来の構造化データ向けデータベースと異なり、データレイクは大規模な生データや半構造化データを扱えます。ブロックチェーンの全履歴、トランザクションデータ、イベントログ、状態スナップショットは、すべてこのレイヤーに格納されます。
データレイクの利点は、完全な履歴データを保持しつつ、後続の柔軟な処理や分析を可能にすることです。数百万件のトランザクションを追跡する必要があるアプリケーションにとって、このストレージ方式はブロックチェーンノードへの直接クエリよりもはるかに効率的です。
データレイクはSQDネットワークの長期記憶として機能し、後続のインデックス作成やクエリにデータを提供します。
Worker nodesによるクエリリクエスト処理の仕組み
Worker nodesは、SQDネットワークにおける実行レイヤーです。
データがネットワークに取り込まれると、Worker nodesは高速検索のためにインデックス化、分類、最適化を実行します。このインデックス処理は、巨大な百科事典の目次を作るようなもので、毎回すべてをゼロからスキャンする必要はありません。
インデックス構築に加えて、Worker nodesはクエリタスクも担います。デベロッパーが特定のデータを要求すると、Worker nodeはインデックスを使って関連レコードを素早く特定し、フィルタリング、集計、計算を実行します。
複数のWorker nodesが並列動作できるため、ネットワークは多数のクエリを同時に処理でき、全体のパフォーマンスとスケーラビリティが向上します。
Portalがデベロッパーからのリクエストを受け付ける仕組み
Portalは、デベロッパーがSQDネットワークにアクセスするための統一的なエントリポイントです。
デベロッパーは通常、APIやSDKを介してクエリを送信し、基盤のノードに直接接続することはありません。リクエストがPortalに到達すると、システムはクエリを解析し、最適なWorker nodesを割り当てます。
Portalは、インターネット上のロードバランサーのような役割を果たします。デベロッパーは単一のインターフェースだけを操作すればよく、複雑なリソーススケジューリングやノード選択はバックグラウンドで自動的に行われます。
この設計により、開発がシンプルになり、ネットワーク全体のリソース効率が高まります。
クエリ結果がアプリケーションに返される仕組み
Worker nodesが処理を完了すると、結果はPortalレイヤーに戻されます。
Portalは必要に応じて結果を整形し、最終的なデータをアプリケーションに送信します。デベロッパーは、フロントエンド表示、ビジネスロジック、AI推論にすぐに利用できる構造化データ(JSONオブジェクトや分析結果など)を受け取ります。
この一連の処理は通常、エンドユーザーには見えません。ユーザーがページの読み込みや分析結果の表示を見ている間に、データ収集からクエリ実行までの複数のステップがバックグラウンドで完了しています。
Hotblocksがリアルタイムデータクエリをサポートする仕組み
履歴クエリに加えて、多くのアプリケーションではリアルタイムのオンチェーン情報が必要です。
たとえば、オンチェーンモニタリングシステムは異常なトランザクションを検出し、自動化戦略はスマートコントラクトのイベントをリッスンし、AIエージェントは最新の市場状況を把握する必要があります。これらのシナリオでは、新しいブロックが生成され次第、データが利用可能でなければなりません。
Hotblocksは、SQDが提供するリアルタイムデータレイヤーで、新しいブロックやライブイベント向けに特化して設計されています。データレイク内の履歴データと異なり、Hotblocksは低レイテンシと高速応答に重点を置いており、デベロッパーがリアルタイムアプリケーションを構築するのを可能にします。
SQDクエリが従来のRPCクエリと異なる点
どちらの方法でもオンチェーンデータにアクセスできますが、その仕組みは根本的に異なります。
従来のRPCノードは、ブロックチェーンデータベースに直接問い合わせるようなものです。リクエストのたびにオンチェーンの状態や履歴レコードを検索する必要があり、クエリ範囲が拡大すると、パフォーマンスとコストの負荷が比例して増大します。
一方、SQDは事前インデックス化されたアーキテクチャを採用しています。データはネットワークに取り込まれる時点で整理・インデックス化されているため、クエリのたびに全履歴をスキャンする必要がありません。複雑な分析、マルチチェーンデータの集計、長期的な履歴統計において、SQDは通常、はるかに高い効率を発揮します。
| 項目 | SQD | 従来のRPC |
|---|---|---|
| データソース | 事前インデックス化データ | リアルタイムオンチェーン読み取り |
| クエリ効率 | 高 | 中 |
| 履歴データ分析 | 圧倒的に優位 | 複雑 |
| マルチチェーンサポート | 強 | 複数ノードに依存 |
| インフラコスト | 低 | 高 |
| リアルタイム状態読み取り | 対応 | 対応 |
SQDのクエリプロセスがAIエージェントにとって重要な理由
AIエージェントはWeb3インフラの主要なアプリケーションとして台頭しており、データアクセスはその動作の基盤です。
AIエージェントがウォレットの行動分析、プロトコル状態の追跡、オンチェーンアクションの実行などを行うには、正確で構造化されたデータを継続的に取得する必要があります。従来のRPCクエリは生データを提供しますが、通常は追加の処理や変換が必要です。
SQDが提供する統一データインターフェースは、AIエージェントがオンチェーン情報を取得する際の複雑さを低減します。標準化されたクエリ結果により、AIシステムはデータの前処理ではなく、分析と意思決定に多くの計算リソースを割り当てられます。
AIとWeb3の融合が進むにつれ、分散型データレイヤーの重要性は今後ますます高まるでしょう。
まとめ
SQDデータクエリは、単なるデータ読み取りではありません。データ収集レイヤー、データレイク、Worker nodes、Portalレイヤーが連携する完全なワークフローです。生のブロックチェーンデータはまず収集・保存され、次にインデックス化・最適化され、最後に統一インターフェースを通じてデベロッパーに届けられます。
この事前インデックス化された分散処理モデルにより、SQDは複雑なクエリ、マルチチェーン分析、リアルタイムデータアクセスにおいて高い効率を実現します。DeFi、オンチェーン分析プラットフォーム、AIエージェントのデータ需要が高まる中、SQDに代表されるデータレイヤーアーキテクチャは、Web3インフラの不可欠な要素となりつつあります。
よくある質問
SQDデータクエリと通常のAPIクエリの違いは何ですか?
通常のAPIは中央集権的なプロバイダーが管理するのに対し、SQDクエリは分散型データネットワーク上で実行されます。SQDデータはオンチェーン収集・インデックスシステムに由来し、よりオープンで検証可能なデータアクセスを提供します。
一部のRPCリクエストよりもSQDクエリの速度が速いのはなぜですか?
SQDは事前にインデックス作成と整理を完了しているため、クエリごとに大量のブロック履歴を再スキャンする必要がありません。複雑な分析や履歴データの処理において、SQDは一般的にはるかに高速です。
Worker nodesはクエリプロセスにおいてどのような役割を果たしますか?
Worker nodesは、インデックス作成、フィルタリング、集計、計算を担当します。Portalがクエリリクエストを受け取ると、該当するWorker nodesが実際のデータ処理を実行します。
データレイクとデータベースの違いは何ですか?
データベースは通常、構造化データを保存するのに対し、データレイクは大量の生データや半構造化データを保存できます。SQDはデータレイクを用いて完全なオンチェーン履歴を保存し、柔軟なクエリと分析を実現します。
Hotblocksは履歴データクエリを置き換えることができますか?
いいえ。Hotblocksはリアルタイムデータアクセス向けに設計されており、履歴クエリは引き続きデータレイクとインデックスシステムに依存します。両者が連携することで、SQDの完全なデータサービス機能が実現します。
SQDクエリサービスに最適なアプリケーションはどれですか?
DeFiダッシュボード、ブロックチェーンエクスプローラー、オンチェーン分析プラットフォーム、リアルタイムモニタリングシステム、マルチチェーンアプリケーション、AIエージェントなど、頻繁にオンチェーンデータにアクセスする必要があるあらゆるユースケースに、SQDクエリサービスは最適です。
共有
内容
モルガン・スタンレーは6月18日に、手数料率0.14%でイーサリアムおよびソラナのETF向けに改訂S-1を提出
Sand.aiは資金調達で1億ドル超を確保し、オープンソースのMoE動画モデルを7月にローンチする計画です
サムスン電機がQualcomm AI200アクセラレータ向けFC-BGA基板の量産を開始
デジタル資産市場は戦略上のビットコイン懸念と米国・イラン協議を背景に変動の大きい動きを示し、6月22日
2026年6月22日、Taiko Bridgeのエクスプロイトにより無許可の出金で170万ドルが流出


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Plasma(XPL)トークノミクス分析:供給、分配、価値捕捉

0xプロトコルの主要コンポーネントは何でしょうか。Relayer、Mesh、APIアーキテクチャの概要をご紹介します。
