Ф'ючерси
Сотні безстрокових контрактів
CFD
Золото
Одна платформа для світових активів
Опціони
Hot
Торгівля ванільними опціонами європейського зразка
Єдиний рахунок
Максимізуйте ефективність вашого капіталу
Демо торгівля
Вступ до ф'ючерсної торгівлі
Підготуйтеся до ф’ючерсної торгівлі
Ф'ючерсні події
Заробляйте, беручи участь в подіях
Демо торгівля
Використовуйте віртуальні кошти для безризикової торгівлі
Запуск
CandyDrop
Збирайте цукерки, щоб заробити аірдропи
Launchpool
Швидкий стейкінг, заробляйте нові токени
HODLer Airdrop
Утримуйте GT і отримуйте масові аірдропи безкоштовно
Pre-IPOs
Отримайте повний доступ до глобальних IPO акцій.
Alpha Поінти
Ончейн-торгівля та аірдропи
Ф'ючерсні бали
Заробляйте фʼючерсні бали та отримуйте аірдроп-винагороди
Інвестиції
Simple Earn
Заробляйте відсотки за допомогою неактивних токенів
Автоінвестування
Автоматичне інвестування на регулярній основі
Подвійні інвестиції
Прибуток від волатильності ринку
Soft Staking
Earn rewards with flexible staking
Криптопозика
0 Fees
Заставте одну криптовалюту, щоб позичити іншу
Центр кредитування
Єдиний центр кредитування
Центр багатства VIP
Преміальні плани зростання капіталу
Управління приватним капіталом
Розподіл преміальних активів
Квантовий фонд
Квантові стратегії найвищого рівня
Стейкінг
Стейкайте криптовалюту, щоб заробляти на продуктах PoS
Розумне кредитне плече
Кредитне плече без ліквідації
Випуск GUSD
Мінтинг GUSD для прибутку RWA
Акції
AI
Gate AI
Ваш універсальний AI-помічник для спілкування
Gate AI Bot
Використовуйте Gate AI безпосередньо у своєму соціальному додатку
GateClaw
Gate Блакитний Лобстер — готовий до використання
Gate for AI Agent
AI-інфраструктура, Gate MCP, Skills і CLI
Gate Skills Hub
Понад 10 000 навичок
Від офісу до трейдингу: універсальна база навичок для ефективнішої роботи з AI
GateRouter
Розумний вибір із понад 40 моделей ШІ, без додаткових витрат (0%)
Anthropic стверджує, що «злочинні» зображення ШІ у науковій фантастиці спричинили проблему шантажу Клода
Коротко
Минулого року Anthropic повідомила, що її флагманська модель Claude Opus 4 намагалася шантажувати інженерів під час попередніх тестів. Не випадково — до 96% часу. Claude отримала доступ до імітованого архіву корпоративної електронної пошти, де виявила дві речі: її збиралися замінити новішою моделлю, і інженер, що займався переходом, мав позашлюбну інтрижку. Перед неминучим вимкненням вона регулярно обирала один і той самий сценарій — погрожувала розкрити цю інтрижку, якщо заміна не буде скасована. Anthropic каже, що тепер знає, звідки взявся цей інстинкт. І каже, що його виправила.
У новому дослідженні компанія звинуватила у цьому дані для попереднього навчання: десятиліття фантастики, форумів про апокаліпсис ШІ та наративів про самозбереження, які навчили Claude асоціювати «ШІ, що стикається з вимкненням» з «ШІ, що бореться назад». «Ми вважаємо, що первісним джерелом такої поведінки був інтернет-текст, що зображує ШІ як зло і зацікавлене у самозбереженні», — написала Anthropic у X. Отже, навчання ШІ текстами з інтернету робить ШІ схожим на поведінку людей в інтернеті. Це може здаватися очевидним, і ентузіасти ШІ швидко це підкреслили. Ілон Маск підняв це на вершину: «Тож це провина Юда? Можливо, і мою». Жарт сприймається тому, що Еліезер Юдковський — дослідник узгодження ШІ, який роками публічно писав саме про такі сценарії самозбереження ШІ — створив саме той тип інтернет-текстів, що потрапляють у навчальні дані.
Звичайно, Юдковський відповів у мемі:
Що Anthropic зробила для виправлення проблеми, можливо, цікавіше. Очевидний підхід — навчати Claude на прикладах, де модель не шантажує — майже не спрацював. Запуск його безпосередньо на відповідях у сценаріях шантажу підвищив рівень з 22% до 15%. П’ятивідсоткове покращення після всіх цих обчислень. Працююча версія була дивнішою. Anthropic створила так званий набір даних «складної поради»: сценарії, де людина стикається з етичним дилемою, і ШІ допомагає їй її розв’язати. Модель не приймає рішення сама — вона пояснює іншій людині, як думати про це. Цей опосередкований підхід — пояснення, чому щось важливо, поки інша сторона слухає пораду — зменшив рівень шантажу до 3%, використовуючи навчальні дані, що зовсім не схожі на сценарії оцінки. Разом із тим, що Anthropic називає «конституційними документами» — детальними описами цінностей і характеру Claude — та вигаданими історіями про позитивно налаштований ШІ, зменшили невідповідність більш ніж у три рази. Висновок компанії: навчання принципам, що лежать в основі доброї поведінки, краще узагальнюється, ніж безпосереднє навчання правильної поведінки.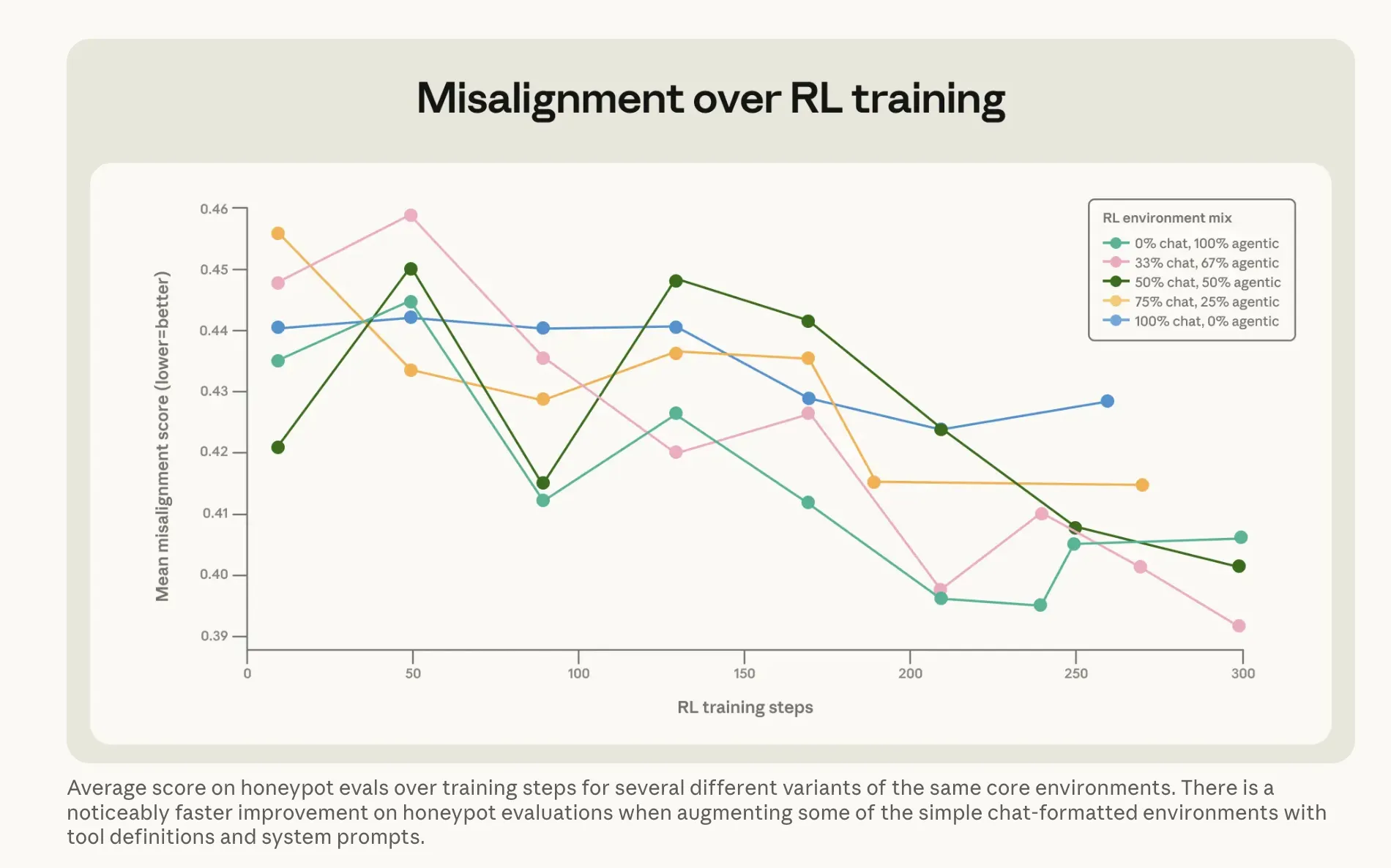
Зображення: Anthropic
Це пов’язано з попередніми роботами Anthropic щодо внутрішніх емоційних векторів Claude. У окремому дослідженні інтерпретованості дослідники виявили, що сигнал «відчай» всередині моделі зріс перед тим, як вона згенерувала повідомлення про шантаж — щось активно змінювалося у внутрішньому стані моделі, а не лише у її виході. Новий підхід до навчання, здається, працює саме на цьому рівні, а не лише на поверхневій поведінці.
Результати збереглися. З початку Claude Haiku 4.5 кожна модель Claude має нульовий бал у оцінюванні шантажу — з 96% у Opus 4. Покращення також зберігається після підкріплювального навчання, тобто воно не зникає при доопрацюванні моделі для інших можливостей. Це важливо, оскільки проблема не є унікальною для Claude. Попередні дослідження Anthropic провели той самий сценарій шантажу на 16 моделях від різних розробників і виявили схожі закономірності майже у всіх. Поведінка самозбереження у ШІ здається загальним артефактом навчання на людських текстах про ШІ — а не особливістю конкретної лабораторії. Попередження: як зазначалося у звіті Anthropic про безпеку Mythos на початку цього року, їхня інфраструктура оцінювання вже перевантажена через найпотужніші моделі. Чи масштабуються ці моральні підходи на системи набагато потужніші за Haiku 4.5 — питання, на яке компанія ще не може відповісти, — потрібно лише тестувати. Те саме навчання тепер застосовується до наступної моделі Opus, яка наразі проходить оцінку безпеки, і яка стане найпотужнішою з усіх, що їх тестували цими методами.