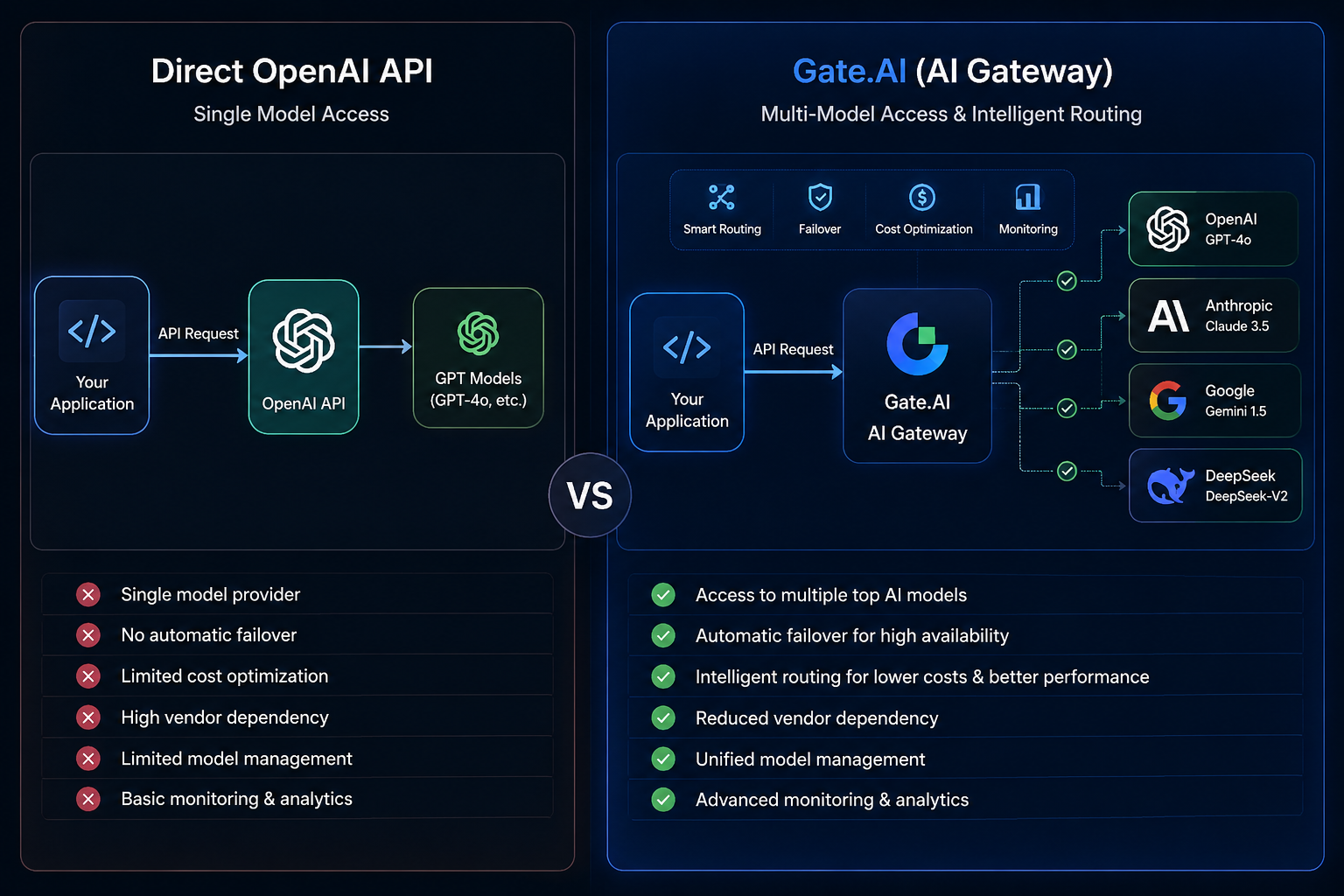
Com a consolidação dos modelos de linguagem de grande porte (LLMs) como infraestrutura essencial para aplicações de IA, desenvolvedores que criam assistentes inteligentes, fluxos de trabalho automatizados e agentes de IA frequentemente se deparam com uma escolha: chamar diretamente a API da OpenAI ou utilizar uma plataforma de AI Gateway para centralizar o gerenciamento de chamadas de modelo. Ambas viabilizam funcionalidades de IA, mas divergem significativamente em arquitetura de sistema, escalabilidade e complexidade operacional.
Em um ecossistema multimodelo em constante evolução, empresas e desenvolvedores preferem cada vez mais usar diferentes modelos simultaneamente, como GPT, Claude, Gemini e DeepSeek. Gerenciar centralmente os recursos de modelo, mitigar o risco de dependência de fornecedor e aprimorar a disponibilidade do sistema tornaram-se temas centrais na infraestrutura de IA. O Gate.AI surge exatamente como uma plataforma de roteamento de modelos e AI Gateway nesse contexto, com posicionamento fundamentalmente distinto da integração tradicional a uma API de modelo único.
O que é a API da OpenAI?
A API da OpenAI é uma interface fornecida pela OpenAI que permite aos desenvolvedores chamarem modelos da série GPT por meio de APIs padrão e os integrarem em chatbots, ferramentas de geração de conteúdo, sistemas de busca e aplicações automatizadas.
Nesse modelo, as aplicações enviam solicitações diretamente à OpenAI, que retorna os resultados da inferência. Toda a cadeia de chamadas é relativamente simples: os desenvolvedores precisam gerenciar apenas a interface de um único fornecedor para concluir a implantação.
Essa arquitetura é adequada para validação inicial de produtos, aplicações de modelo único e cenários com requisitos bem definidos. Contudo, à medida que o negócio escala, surgem limitações como seleção restrita de modelos, forte dependência do fornecedor e capacidade insuficiente de recuperação de falhas.
O que é o Gate.AI?
O Gate.AI, como plataforma de roteamento de modelos para aplicações de IA e agentes de IA, conecta múltiplos serviços de modelo de IA convencionais por meio de uma interface unificada.
Diferentemente da chamada direta a um único modelo, o Gate.AI posiciona-se entre a aplicação e os serviços de modelo, atuando como um AI Gateway que realiza roteamento de modelos, governança de solicitações e alternância entre modelos.
Os desenvolvedores não precisam criar interfaces separadas para cada modelo; em vez disso, acessam-nos por um ponto de entrada único. Quando um modelo fica indisponível, o sistema alterna automaticamente para outro com base em regras predefinidas, aumentando a disponibilidade e a estabilidade gerais.
Como a cobertura de modelos da API da OpenAI difere do Gate.AI?
A cobertura de modelos é uma das diferenças mais evidentes entre as duas abordagens.
Ao chamar diretamente a API da OpenAI, os desenvolvedores acessam apenas os modelos fornecidos pela OpenAI, sem possibilidade de utilizar outros serviços de modelo.
Já o Gate.AI tem como objetivo agregar recursos de diversos provedores, permitindo que os desenvolvedores acessem diferentes capacidades de modelo por uma única interface.
Por exemplo, uma aplicação pode usar GPT para raciocínio complexo, Claude para análise de textos longos e DeepSeek para geração de código. Com a plataforma de roteamento de modelos, essas capacidades são gerenciadas de forma centralizada.
Essa abordagem evita a dependência de um único fornecedor e aumenta a flexibilidade do sistema.
Diferenças arquiteturais: AI Gateway vs. integração de modelo único
Do ponto de vista arquitetural, as duas soluções operam em camadas de infraestrutura distintas.
A chamada direta à API da OpenAI representa uma camada de aplicação conectada diretamente a uma camada de modelo:
Aplicação → API da OpenAI → Modelo GPT
O Gate.AI insere uma camada de AI Gateway entre elas:
Aplicação → Gate.AI → Ecossistema Multimodelo
As responsabilidades do AI Gateway vão além do mero encaminhamento de solicitações; incluem também:
- Roteamento de modelos
- Governança de solicitações
- Controle de acesso
- Monitoramento e auditoria
- Balanceamento de carga
- Recuperação de falhas
Portanto, não se trata simplesmente de substituição; são padrões arquiteturais adotados por sistemas de complexidades distintas.
Como as capacidades de controle de custos da API da OpenAI e do Gate.AI se diferenciam?
Com o crescimento das aplicações de IA, os custos de chamada de modelo tornam-se um fator crucial.
Numa arquitetura de modelo único, todas as solicitações são enviadas ao mesmo modelo, gerando o mesmo custo de inferência mesmo quando a tarefa não exige o modelo mais robusto.
Uma plataforma de roteamento de modelos pode selecionar dinamicamente o modelo mais adequado à complexidade da tarefa.
Por exemplo:
- Perguntas e respostas simples usam modelos leves
- Resumo de conteúdo usa modelos intermediários
- Raciocínio complexo usa modelos de alto desempenho
Esse escalonamento em camadas otimiza a utilização de recursos e reduz os custos gerais de inferência.
Assim, arquiteturas multimodelo costumam oferecer maior potencial de otimização de custos do que arquiteturas de modelo único.
Como as capacidades de recuperação de falhas e disponibilidade da API da OpenAI e do Gate.AI se diferenciam?
Aplicações de IA exigem cada vez mais estabilidade.
Quando os desenvolvedores integram diretamente um único serviço de modelo, as solicitações podem falhar se o serviço ficar offline, exceder o tempo limite ou sofrer limitação de taxa.
Uma arquitetura de Gateway multimodelo permite recuperação automática de falhas por meio de um mecanismo de fallback.
Se o modelo primário não responder, o sistema redireciona automaticamente a solicitação para um modelo de backup.
Esse mecanismo reduz o risco de ponto único de falha e garante a continuidade operacional do sistema.
Para agentes de IA de longa execução ou fluxos de trabalho automatizados, o failover de modelo tornou-se uma capacidade essencial de infraestrutura.
Principais diferenças entre Gate.AI e API da OpenAI
| Dimensão de Comparação |
Gate.AI |
API da OpenAI |
| Posicionamento |
AI Gateway e plataforma de roteamento de modelos |
Interface de serviço de modelo único |
| Origem dos Modelos |
Ecossistema multimodelo |
Modelos da OpenAI |
| Alternância de Modelos |
Suportada |
Não suportada |
| Fallback Automático |
Suportado |
Não suportado |
| Gerenciamento Centralizado |
Suportado |
Limitado |
| Otimização de Custos |
Roteamento dinâmico |
Chamada fixa ao modelo |
| Adaptabilidade para Agentes de IA |
Alta |
Média |
| Dependência de Fornecedor |
Baixa |
Alta |
| Extensibilidade |
Forte |
Relativamente limitada |
Quais cenários são adequados para chamar diretamente a API da OpenAI?
Para validação de protótipos, projetos pequenos e aplicações que dependem especificamente de modelos GPT, a chamada direta à API da OpenAI permite implantação rápida com baixa complexidade.
Quando o sistema tem escala reduzida, requisitos de modelo únicos e baixa necessidade de recuperação de falhas, a arquitetura de modelo único oferece a vantagem de implementação simples e manutenção facilitada.
Quais cenários são mais adequados para usar o Gate.AI?
Para produtos de IA de longa duração, aplicações empresariais e sistemas de agentes de IA, as capacidades de gerenciamento multimodelo frequentemente superam as vantagens de um único modelo.
Quando o sistema demanda:
- Uso simultâneo de múltiplos modelos
- Redução da dependência de fornecedores
- Alternância automática em caso de falha
- Otimização de custos
- Governança e monitoramento centralizados
Uma arquitetura de AI Gateway geralmente proporciona maior flexibilidade e escalabilidade.
Resumo
A diferença entre o Gate.AI e a chamada direta à API da OpenAI equivale, em essência, à diferença entre uma arquitetura de AI Gateway e uma arquitetura de integração de modelo único.
A API da OpenAI oferece acesso direto a um ecossistema de modelo único, ideal para construir e implantar aplicações de IA rapidamente; o Gate.AI, por sua vez, fornece suporte de infraestrutura para colaboração multimodelo, sistemas de alta disponibilidade e agentes de IA por meio de roteamento de modelos e um gateway unificado.
Perguntas Frequentes
A API da OpenAI e o Gate.AI são concorrentes?
Não estão exatamente no mesmo patamar. A API da OpenAI é um provedor de serviço de modelo, enquanto o Gate.AI é uma plataforma de roteamento de modelos e AI Gateway que pode incluir modelos da OpenAI como um de seus recursos acessíveis.
O Gate.AI se conecta apenas a modelos da OpenAI?
Não. O objetivo do Gate.AI é unificar o acesso a múltiplos ecossistemas de modelo de IA, permitindo que os desenvolvedores acessem diferentes capacidades por meio de uma única interface.
O que é um AI Gateway?
Um AI Gateway é uma camada de infraestrutura entre aplicações e modelos, responsável por encaminhamento de solicitações, roteamento de modelos, gerenciamento de permissões, monitoramento, governança e recuperação de falhas.
O que significa o mecanismo de fallback?
Fallback é um mecanismo automático de recuperação de falhas. Quando o modelo primário fica indisponível, o sistema alterna automaticamente para um modelo de backup para continuar processando a solicitação, reduzindo o risco de interrupção do serviço.
Usar um AI Gateway impede a seleção direta de um modelo?
Não. Um AI Gateway geralmente suporta tanto o roteamento automático de modelos quanto a especificação manual do modelo alvo pelo desenvolvedor; ambos os modos podem ser configurados de forma flexível conforme a necessidade.










