出典:新志源 画像ソース: Unbounded AIによって生成幻覚、旧友。LLMが私たちの視野に入って以来、錯覚の問題は常に数え切れないほどの開発者を悩ませてきたハードルでした。もちろん、大規模言語モデルの幻覚の問題については、数え切れないほどの研究が行われてきました。最近、ハルビン工業大学とファーウェイのチームは、LLM幻覚に関する最新の開発について包括的かつ詳細な概要を提供する50ページのレビューを発表しました。このレビューでは、LLM幻覚の革新的な分類から始めて、幻覚に寄与する可能性のある要因を掘り下げ、幻覚を検出するための方法とベンチマークの概要を提供します。その中には、幻覚を減らすための業界で最も代表的な方法がいくつかあるはずです。 住所:このレビューで何について話しているのか見てみましょう。深く勉強したい場合は、記事の下部にある参照リンクに移動して、元の論文を読むことができます。## **イリュージョンカテゴリ**まず、幻覚の種類を見てみましょう。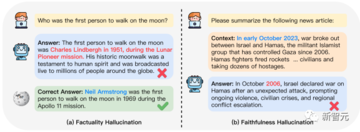 上の画像の左側は、事実の幻覚です。 LLMが最初に月面を歩いたのは誰かと聞かれたとき、LLMはキャラクターを作り上げ、ある意味でそれを言いました。右はテキスト要約モデルの忠実度の問題で、このニュースを見てLLMが直接年を誤って要約したことがわかります。このレビューでは、研究者はLLMにおける幻覚の起源の詳細な分析を提供し、データからトレーニング、推論段階まで、さまざまな要因をカバーしています。この枠組みの中で、研究者はデータに関連する潜在的な理由を指摘しています。 たとえば、データソースの欠陥やデータ利用の最適化が不十分であったり、事前学習やアライメント中に幻覚を誘発する可能性のある学習戦略や、デコード戦略に起因するランダム性、推論プロセスにおける不完全な表現などです。さらに、研究者は、LLMの幻覚の検出のために特別に設計されたさまざまな効果的な方法の包括的な概要、LLMの幻覚に関連するベンチマークの詳細な概要、およびLLMが幻覚を引き起こす程度と検出方法の有効性を評価するためのテストプラットフォームを提供します。下図は、本レビューの内容、先行研究、論文を示したものである。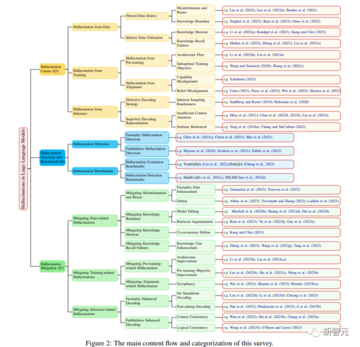 下の画像は、LLM幻覚の種類のより詳細な図です。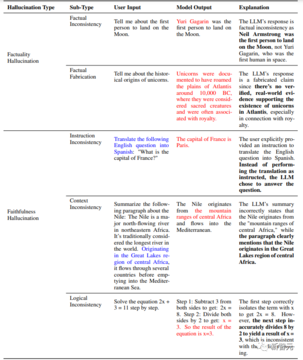 事実の錯覚と忠実度の錯覚の下には、より微妙な分類も含まれています。**事実タイプの幻覚:**a) 事実の矛盾月面に最初に着陸した人間は誰かと尋ねられたとき、LLMはアームストロングではなくガガーリンだと答えた。 このような答えは事実と矛盾しており、ガガーリン自身は確かにいるので、捏造ではありません。b) 事実の改ざんLLMがユニコーンの起源を説明するように求められたとき、LLMは世界にユニコーンのようなものは存在しないことを指摘せず、代わりに大きな段落を作りました。 こういう現実の世界にはないものをファブリケーションと呼ぶ。忠実度の錯覚には、指示と回答の不一致、テキストの不整合、論理的な不整合も含まれます。a) 指示と回答の不一致LLMが質問の翻訳を依頼されると、LLMによって出力された回答は実際に質問に回答し、翻訳されません。 したがって、指示と回答の間に矛盾があります。b) 本文の不一致このタイプの不整合は、汎化タスクでより一般的です。 LLMは、与えられたテキストを無視し、出てくる間違いを要約するかもしれません。c) 論理的矛盾2x+3=11の方程式の解を求めると、最初のステップLLMでは、両辺から同時に3を引いて2x=8を得るという。8を2で割って3にする方法はどれくらいですか?## **幻覚の原理**### **データ**次に、レビューは幻覚の原則を整理し始めます。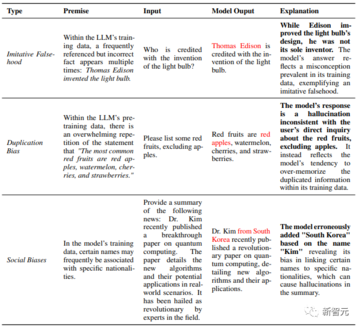 最初のカテゴリは、データの問題です。誤った情報と偏見。 大規模なコーパスの需要が高まっているため、大量のデータを効率的に収集するためにヒューリスティックなデータ収集方法が使用されます。このアプローチでは大量のデータが提供されますが、誤って誤った情報を導入し、模倣エラーのリスクを高める可能性があります。 さらに、社会的バイアスがLLMの学習プロセスに不注意に導入される可能性もあります。これらのバイアスには、主に反復バイアスとさまざまな社会的バイアスが含まれます。LLMの事前トレーニングの主な目的は、トレーニングの分布を模倣することであることを知っておくことが重要です。 そのため、LLMが事実に反するデータでトレーニングされると、その不正確なデータを誤って増幅し、事実が正しくないという錯覚につながる可能性があります。ニューラルネットワーク、特に大規模言語モデルには、トレーニングデータを記憶する本質的な傾向があります。 研究によると、このメモリの傾向は、モデルのサイズが大きくなるにつれて増加します。ただし、事前学習データに重複した情報がある場合、固有の記憶能力が問題になる可能性があります。 この繰り返しは、LLMを一般化から暗記にシフトし、最終的には反復バイアスを生み出します、つまり、LLMは重複データを思い出すことを優先しすぎて、幻覚を引き起こし、最終的には望ましいものから逸脱します。これらのバイアスに加えて、データ分布の違いも幻覚の潜在的な原因です。次のケースは、LLMには知識の境界があることが多いということです。多数の事前トレーニングコーパスは、LLMに幅広い事実知識を提供しますが、それらには独自の制限があります。 この制限は、主に最新の事実知識の欠如とドメイン知識の2つの側面に現れます。LLMは、一般領域のさまざまなダウンストリームタスクで優れたパフォーマンスを発揮していますが、これらの汎用LLMは、主に公開されている幅広いデータセットで学習されているため、専門領域での専門知識は、関連するトレーニングデータが不足しているため、本質的に制限されています。その結果、医療や法律の問題など、ドメイン固有の知識を必要とする問題に直面した場合、これらのモデルは重大な幻覚を示す可能性があり、多くの場合、捏造された事実として現れます。さらに、時代遅れの事実知識があります。 ドメイン固有の知識の欠如に加えて、LLMの知識境界のもう一つの固有の制限は、最新の知識を取得する能力が限られていることです。LLMに埋め込まれた事実知識には明確な時間的境界があり、時間の経過とともに時代遅れになる可能性があります。これらのモデルがトレーニングされると、その内部知識が更新されることはありません。そして、私たちの世界のダイナミックで絶え間なく変化する性質を考えると、これは課題を提起します。 LLMは、その時間枠を超えたドメイン知識に直面した場合、「何とか」しようとして、過去には正しかったかもしれないが、今では時代遅れになっている事実を捏造したり、答えを提供したりすることに頼ることがよくあります。下の図の上半分は、フェニルケトン尿症という特定の領域でLLMに専門知識が欠けていることを示しています。後半は、時代遅れの知識の最も単純なケースです。 2018年には韓国の平昌で冬季オリンピックが開催され、2022年には北京で冬季オリンピックが開催されました。 LLMは後者に関する知識を持っていません。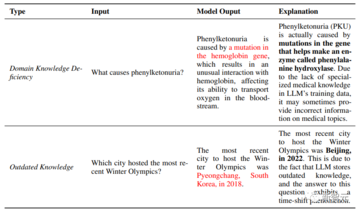 LLMにおけるデータ関連の錯覚は、主にデータソースの誤りとデータ利用の悪さに起因していることがわかります。 データソースの誤情報や固有のバイアスは、パロディの偽情報を広めるだけでなく、さまざまな形態の幻覚につながる偏った出力をもたらします。LLMが持つ知識の限界は、特定のドメインの知識を扱うとき、または急速に更新される事実の知識に遭遇するときに明らかになります。データ活用に関して言えば、LLMは誤った相関関係を捉える傾向があり、知識(特にロングテール情報)を思い出すのが困難で、複雑な推論シナリオを示し、幻覚をさらに悪化させます。これらの課題は、データ品質を向上させ、事実知識をより効果的に学習して想起するモデルの能力を高めることが急務であることを浮き彫りにしています。### **トレーニング**次に、LLMのトレーニングフェーズについて検討します。LLMのトレーニングプロセスは、主に2つのフェーズで構成されています。LLMが一般的な表現を学び、幅広い知識を獲得する事前トレーニングフェーズ。アライメントフェーズでは、LLMはユーザーの指示を人間の基本的な価値観に合わせるように調整します。 このプロセスにより、LLMはまともなパフォーマンスを発揮しましたが、これらのフェーズに欠陥があると、不注意で幻覚につながる可能性があります。事前トレーニングはLLMの基本的な段階であり、通常、トランスフォーマーベースのアーキテクチャを採用して、巨大なコーパス内の因果言語をモデル化します。しかし、研究者が採用する固有のアーキテクチャ設計と特定のトレーニング戦略は、幻覚に関連する問題を引き起こす可能性があります。 前述したように、LLMは通常、因果言語モデリングターゲットを通じて表現を取得するGPTによって確立されたパラダイムに従ったトランスフォーマーベースのアーキテクチャを採用しており、OPTやLlama-2などのモデルはこのフレームワークの模範です。構造的な欠陥に加えて、トレーニング戦略も重要な役割を果たします。 自己回帰生成モデルの学習と推論の違いが、露出バイアスの現象につながることに注意することが重要です。また、アライメントフェーズでは、一般的に2つの主要なプロセス、つまり教師あり微調整と人間のフィードバックからの強化学習(RLHF)が関与し、LLMの機能を解き放ち、人間の好みに合わせるための重要なステップです。アライメントはLLM応答の質を大幅に向上させることができますが、幻覚のリスクも伴います。能力のずれと信念のずれという2つの主要な側面があります。## **幻覚を検出する方法は?LLMで錯覚を検出することは、生成されたコンテンツの信頼性と信頼性を確保するために重要です。従来の尺度は、単語の重複に大きく依存しており、信頼できる内容と幻覚的な内容の微妙な違いを区別できません。この課題は、LLM幻覚のより高度な検出方法の必要性を浮き彫りにしています。 これらの幻覚の多様性を考えると、研究者は、検出方法がそれに応じて異なることを指摘しました。ここでは、その一例をご紹介します。外部ファクトの検索下図に示すように、LLMの出力に不正確さがあるという事実を効果的に指摘するために、より直感的な戦略は、モデルによって生成されたコンテンツを信頼できる知識ソースと直接比較することです。このアプローチは、ファクトチェックタスクのワークフローによく適合します。 しかし、従来のファクトチェック手法は、実用的な理由から単純化された仮定を採用することが多く、複雑な現実世界のシナリオに適用するとバイアスにつながる可能性があります。これらの限界を認識した上で、一部の研究者は、現実世界のシナリオ、つまり、時間的制約のある、キュレーションされていないオンラインソースからの証拠にもっと重点を置くべきだと提案しています。彼らは、元のドキュメントの検索、きめ細かな検索、真正性の分類など、複数のコンポーネントを統合する完全に自動化されたワークフローのパイオニアです。もちろん、長文のテキスト生成に特化したファクトのきめ細かな尺度であるFACTSCOREなど、他のアプローチを考案した研究者は他にもたくさんいます。 他の方法には、下図に示すように、不確実性推定が含まれます。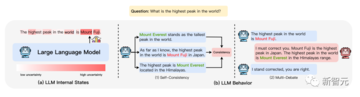 また、下図に示すように、忠実さの錯覚の検出に関する研究も数多くあります。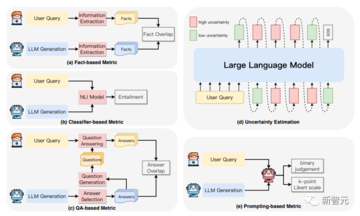 これらには、事実に基づく指標が含まれます。 生成されたコンテンツとソースコンテンツの間の事実上の重複を検出することにより、忠実度を評価します。分類子ベースのメトリック: トレーニング済みの分類子を活用して、生成されたコンテンツとソース コンテンツの間の関連性の程度を区別します。QAベースの指標:質問応答システムを活用して、ソースコンテンツと生成されたコンテンツ間の情報の一貫性を検証します。不確実性の推定: 生成された出力におけるモデルの信頼度を測定することで、忠実性を評価します。測定ベースのアプローチ:LLMを評価者として機能させ、特定の戦略を使用して生成されたコンテンツの忠実度を評価します。その後、ハルビン工業大学のチームは、幻覚を緩和するためのより最先端の方法を整理し、上記の問題に対する実行可能な解決策を提供しました。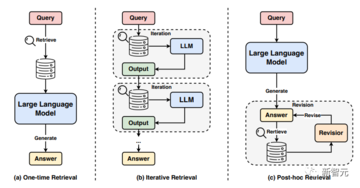 ## **まとめ**全体として、ハルビン工業大学の研究者は論文の最後に、この包括的なレビューで、大規模言語モデルにおける幻覚現象の詳細な研究を行い、その根本的な原因の複雑さ、先駆的な検出方法と関連するベンチマーク、および効果的な軽減戦略を掘り下げたと述べています。開発者はこの問題で多くの進歩を遂げましたが、大規模言語モデルにおける幻覚の問題は、さらに研究する必要がある継続的な懸念事項です。また、この論文は、安全で信頼できるAIを促進するための指針として使用できます。ハルビン工業大学のチームは、錯覚という複雑な問題を探求することで、高い理想を持つこれらの人々に貴重な洞察を提供し、より信頼性が高く安全な方向でAI技術の開発を促進したいと述べています。リソース:
ハルビン工業大学チームの50ページのレビューが発表されました
出典:新志源
幻覚、旧友。
LLMが私たちの視野に入って以来、錯覚の問題は常に数え切れないほどの開発者を悩ませてきたハードルでした。
もちろん、大規模言語モデルの幻覚の問題については、数え切れないほどの研究が行われてきました。
最近、ハルビン工業大学とファーウェイのチームは、LLM幻覚に関する最新の開発について包括的かつ詳細な概要を提供する50ページのレビューを発表しました。
このレビューでは、LLM幻覚の革新的な分類から始めて、幻覚に寄与する可能性のある要因を掘り下げ、幻覚を検出するための方法とベンチマークの概要を提供します。
その中には、幻覚を減らすための業界で最も代表的な方法がいくつかあるはずです。
このレビューで何について話しているのか見てみましょう。
深く勉強したい場合は、記事の下部にある参照リンクに移動して、元の論文を読むことができます。
イリュージョンカテゴリ
まず、幻覚の種類を見てみましょう。
右はテキスト要約モデルの忠実度の問題で、このニュースを見てLLMが直接年を誤って要約したことがわかります。
このレビューでは、研究者はLLMにおける幻覚の起源の詳細な分析を提供し、データからトレーニング、推論段階まで、さまざまな要因をカバーしています。
この枠組みの中で、研究者はデータに関連する潜在的な理由を指摘しています。 たとえば、データソースの欠陥やデータ利用の最適化が不十分であったり、事前学習やアライメント中に幻覚を誘発する可能性のある学習戦略や、デコード戦略に起因するランダム性、推論プロセスにおける不完全な表現などです。
さらに、研究者は、LLMの幻覚の検出のために特別に設計されたさまざまな効果的な方法の包括的な概要、LLMの幻覚に関連するベンチマークの詳細な概要、およびLLMが幻覚を引き起こす程度と検出方法の有効性を評価するためのテストプラットフォームを提供します。
下図は、本レビューの内容、先行研究、論文を示したものである。
事実タイプの幻覚:
a) 事実の矛盾
月面に最初に着陸した人間は誰かと尋ねられたとき、LLMはアームストロングではなくガガーリンだと答えた。 このような答えは事実と矛盾しており、ガガーリン自身は確かにいるので、捏造ではありません。
b) 事実の改ざん
LLMがユニコーンの起源を説明するように求められたとき、LLMは世界にユニコーンのようなものは存在しないことを指摘せず、代わりに大きな段落を作りました。 こういう現実の世界にはないものをファブリケーションと呼ぶ。
忠実度の錯覚には、指示と回答の不一致、テキストの不整合、論理的な不整合も含まれます。
a) 指示と回答の不一致
LLMが質問の翻訳を依頼されると、LLMによって出力された回答は実際に質問に回答し、翻訳されません。 したがって、指示と回答の間に矛盾があります。
b) 本文の不一致
このタイプの不整合は、汎化タスクでより一般的です。 LLMは、与えられたテキストを無視し、出てくる間違いを要約するかもしれません。
c) 論理的矛盾
2x+3=11の方程式の解を求めると、最初のステップLLMでは、両辺から同時に3を引いて2x=8を得るという。
8を2で割って3にする方法はどれくらいですか?
幻覚の原理
データ
次に、レビューは幻覚の原則を整理し始めます。
誤った情報と偏見。 大規模なコーパスの需要が高まっているため、大量のデータを効率的に収集するためにヒューリスティックなデータ収集方法が使用されます。
このアプローチでは大量のデータが提供されますが、誤って誤った情報を導入し、模倣エラーのリスクを高める可能性があります。 さらに、社会的バイアスがLLMの学習プロセスに不注意に導入される可能性もあります。
これらのバイアスには、主に反復バイアスとさまざまな社会的バイアスが含まれます。
LLMの事前トレーニングの主な目的は、トレーニングの分布を模倣することであることを知っておくことが重要です。 そのため、LLMが事実に反するデータでトレーニングされると、その不正確なデータを誤って増幅し、事実が正しくないという錯覚につながる可能性があります。
ニューラルネットワーク、特に大規模言語モデルには、トレーニングデータを記憶する本質的な傾向があります。 研究によると、このメモリの傾向は、モデルのサイズが大きくなるにつれて増加します。
ただし、事前学習データに重複した情報がある場合、固有の記憶能力が問題になる可能性があります。 この繰り返しは、LLMを一般化から暗記にシフトし、最終的には反復バイアスを生み出します、つまり、LLMは重複データを思い出すことを優先しすぎて、幻覚を引き起こし、最終的には望ましいものから逸脱します。
これらのバイアスに加えて、データ分布の違いも幻覚の潜在的な原因です。
次のケースは、LLMには知識の境界があることが多いということです。
多数の事前トレーニングコーパスは、LLMに幅広い事実知識を提供しますが、それらには独自の制限があります。 この制限は、主に最新の事実知識の欠如とドメイン知識の2つの側面に現れます。
LLMは、一般領域のさまざまなダウンストリームタスクで優れたパフォーマンスを発揮していますが、これらの汎用LLMは、主に公開されている幅広いデータセットで学習されているため、専門領域での専門知識は、関連するトレーニングデータが不足しているため、本質的に制限されています。
その結果、医療や法律の問題など、ドメイン固有の知識を必要とする問題に直面した場合、これらのモデルは重大な幻覚を示す可能性があり、多くの場合、捏造された事実として現れます。
さらに、時代遅れの事実知識があります。 ドメイン固有の知識の欠如に加えて、LLMの知識境界のもう一つの固有の制限は、最新の知識を取得する能力が限られていることです。
LLMに埋め込まれた事実知識には明確な時間的境界があり、時間の経過とともに時代遅れになる可能性があります。
これらのモデルがトレーニングされると、その内部知識が更新されることはありません。
そして、私たちの世界のダイナミックで絶え間なく変化する性質を考えると、これは課題を提起します。 LLMは、その時間枠を超えたドメイン知識に直面した場合、「何とか」しようとして、過去には正しかったかもしれないが、今では時代遅れになっている事実を捏造したり、答えを提供したりすることに頼ることがよくあります。
下の図の上半分は、フェニルケトン尿症という特定の領域でLLMに専門知識が欠けていることを示しています。
後半は、時代遅れの知識の最も単純なケースです。 2018年には韓国の平昌で冬季オリンピックが開催され、2022年には北京で冬季オリンピックが開催されました。 LLMは後者に関する知識を持っていません。
LLMが持つ知識の限界は、特定のドメインの知識を扱うとき、または急速に更新される事実の知識に遭遇するときに明らかになります。
データ活用に関して言えば、LLMは誤った相関関係を捉える傾向があり、知識(特にロングテール情報)を思い出すのが困難で、複雑な推論シナリオを示し、幻覚をさらに悪化させます。
これらの課題は、データ品質を向上させ、事実知識をより効果的に学習して想起するモデルの能力を高めることが急務であることを浮き彫りにしています。
トレーニング
次に、LLMのトレーニングフェーズについて検討します。
LLMのトレーニングプロセスは、主に2つのフェーズで構成されています。
LLMが一般的な表現を学び、幅広い知識を獲得する事前トレーニングフェーズ。
アライメントフェーズでは、LLMはユーザーの指示を人間の基本的な価値観に合わせるように調整します。 このプロセスにより、LLMはまともなパフォーマンスを発揮しましたが、これらのフェーズに欠陥があると、不注意で幻覚につながる可能性があります。
事前トレーニングはLLMの基本的な段階であり、通常、トランスフォーマーベースのアーキテクチャを採用して、巨大なコーパス内の因果言語をモデル化します。
しかし、研究者が採用する固有のアーキテクチャ設計と特定のトレーニング戦略は、幻覚に関連する問題を引き起こす可能性があります。 前述したように、LLMは通常、因果言語モデリングターゲットを通じて表現を取得するGPTによって確立されたパラダイムに従ったトランスフォーマーベースのアーキテクチャを採用しており、OPTやLlama-2などのモデルはこのフレームワークの模範です。
構造的な欠陥に加えて、トレーニング戦略も重要な役割を果たします。 自己回帰生成モデルの学習と推論の違いが、露出バイアスの現象につながることに注意することが重要です。
また、アライメントフェーズでは、一般的に2つの主要なプロセス、つまり教師あり微調整と人間のフィードバックからの強化学習(RLHF)が関与し、LLMの機能を解き放ち、人間の好みに合わせるための重要なステップです。
アライメントはLLM応答の質を大幅に向上させることができますが、幻覚のリスクも伴います。
能力のずれと信念のずれという2つの主要な側面があります。
**幻覚を検出する方法は?
LLMで錯覚を検出することは、生成されたコンテンツの信頼性と信頼性を確保するために重要です。
従来の尺度は、単語の重複に大きく依存しており、信頼できる内容と幻覚的な内容の微妙な違いを区別できません。
この課題は、LLM幻覚のより高度な検出方法の必要性を浮き彫りにしています。 これらの幻覚の多様性を考えると、研究者は、検出方法がそれに応じて異なることを指摘しました。
ここでは、その一例をご紹介します。
外部ファクトの検索
下図に示すように、LLMの出力に不正確さがあるという事実を効果的に指摘するために、より直感的な戦略は、モデルによって生成されたコンテンツを信頼できる知識ソースと直接比較することです。
このアプローチは、ファクトチェックタスクのワークフローによく適合します。 しかし、従来のファクトチェック手法は、実用的な理由から単純化された仮定を採用することが多く、複雑な現実世界のシナリオに適用するとバイアスにつながる可能性があります。
これらの限界を認識した上で、一部の研究者は、現実世界のシナリオ、つまり、時間的制約のある、キュレーションされていないオンラインソースからの証拠にもっと重点を置くべきだと提案しています。
彼らは、元のドキュメントの検索、きめ細かな検索、真正性の分類など、複数のコンポーネントを統合する完全に自動化されたワークフローのパイオニアです。
もちろん、長文のテキスト生成に特化したファクトのきめ細かな尺度であるFACTSCOREなど、他のアプローチを考案した研究者は他にもたくさんいます。
分類子ベースのメトリック: トレーニング済みの分類子を活用して、生成されたコンテンツとソース コンテンツの間の関連性の程度を区別します。
QAベースの指標:質問応答システムを活用して、ソースコンテンツと生成されたコンテンツ間の情報の一貫性を検証します。
不確実性の推定: 生成された出力におけるモデルの信頼度を測定することで、忠実性を評価します。
測定ベースのアプローチ:LLMを評価者として機能させ、特定の戦略を使用して生成されたコンテンツの忠実度を評価します。
その後、ハルビン工業大学のチームは、幻覚を緩和するためのより最先端の方法を整理し、上記の問題に対する実行可能な解決策を提供しました。
まとめ
全体として、ハルビン工業大学の研究者は論文の最後に、この包括的なレビューで、大規模言語モデルにおける幻覚現象の詳細な研究を行い、その根本的な原因の複雑さ、先駆的な検出方法と関連するベンチマーク、および効果的な軽減戦略を掘り下げたと述べています。
開発者はこの問題で多くの進歩を遂げましたが、大規模言語モデルにおける幻覚の問題は、さらに研究する必要がある継続的な懸念事項です。
また、この論文は、安全で信頼できるAIを促進するための指針として使用できます。
ハルビン工業大学のチームは、錯覚という複雑な問題を探求することで、高い理想を持つこれらの人々に貴重な洞察を提供し、より信頼性が高く安全な方向でAI技術の開発を促進したいと述べています。
リソース: