ソース: アンタルアルファラボ**ガイド**人工知能の台頭は驚くべきものです。 基本的なアルゴリズムからChatGPTやコパイロットなどの言語学習モデル(LLM)まで、AIは技術進化の最前線にあります。 これらのモデルがユーザーと対話し、大量のデータとプロンプトを処理するため、データプライバシーの懸念が特に重要になります。 その中で、AmazonやAppleなどの大企業は、AIインタラクションによって引き起こされる可能性のあるデータ侵害を防ぐために、ChatGPTなどのパブリックAPIへの従業員のアクセスを制限しています。 さらに、一定レベルのユーザープライバシーを義務付ける規制がまもなく導入されることを期待するのは合理的です。 これらのモデルとやり取りしたり、質問したり、共有したりするデータを非公開にするにはどうすればよいでしょうか。**-完全準同型暗号化 (FHE)****簡単な紹介** 暗号の分野では、完全準同型暗号化は独創的な概念です。 その魅力は、最初にデータを復号化することなく、暗号化されたデータを直接計算できるため、機密情報のプライベートな推論を可能にするという独自の能力にあります。 この機能を使用すると、処理中のデータの安全性と、モデルの知的財産(IP)の完全な保護という2つの重要なことが保証されます。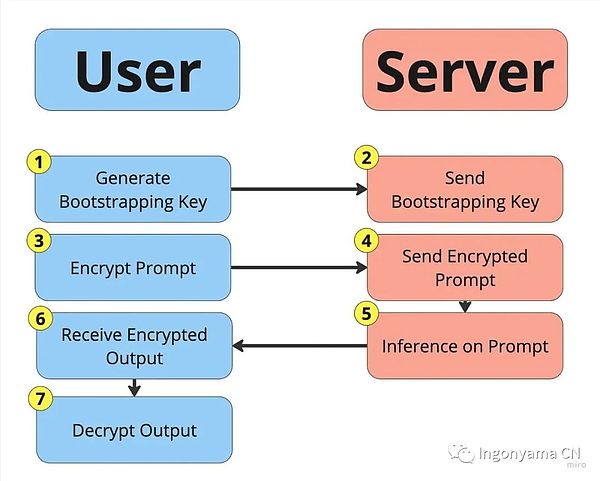 **プライバシーの理由と知的財産の保護** 今日、「プライバシー」と「ユーザーエクスペリエンス」は魚とクマの足の関係のようであり、2つを組み合わせることはできません。 多くの場合、人々はより良いユーザーエクスペリエンスのために彼らの情報を処理するために第三者を信頼します。 これらのサードパーティ企業は、機能が不足しているよりプライバシーを強化するオンプレミスソリューションまたは豊富な機能のためにプライバシーを犠牲にするサービスのいずれかを選択することなく、ユーザーのプライバシーと高品質のユーザーサービスのバランスを見つけることができると考えています。 完全準同型暗号化により、モデルの知的財産を完全に保護したプライバシー推論が可能になります。 暗号化されたデータに対して計算を実行することで、大規模な言語モデルの知的財産を保護しながら、プロンプトの完全な機密性を確保します。**従来の暗号化方式 VS FHE** 従来の暗号化スキームでは、暗号化された形式でデータに対して意味のある操作を実行する場合は、最初にデータを復号化する必要があります。 ただし、復号化によってデータのプレーンテキストが公開されるため、データは一瞬でも攻撃に対して脆弱になります。 対照的に、完全準同型暗号化は暗号文を直接操作できるため、操作全体を通して機密情報が「見えない」ようになります。**FHE が重要な理由** 完全準同型暗号化の重要性は理論に限定されません。 データを復号化せずにデータ処理を実行したり、機密性の高い患者の詳細を取得せずに医療データベースを分析したりできるクラウドコンピューティングサービスを想像してみてください。 完全準同型暗号化の潜在的なアプリケーションは、安全な投票システムや暗号化されたデータベースのプライベート検索など、幅広く多様です。**FHEの数学的基礎**完全準同型暗号化は、量子耐性のある格子暗号技術であるフォールトトレラント学習(LWE)問題に基づいています。 LWE では、ランダムノイズを使用して、キーを所有していない限りデータを読み取れないようにします。 暗号化されたデータに対する算術演算は可能ですが、これは通常ノイズレベルを増加させます。 連続して実行される操作が多すぎると、キーを持っている人を含め、誰もデータを読み取ることができません。 これは部分準同型暗号化 (SHE) と呼ばれます。 部分準同型暗号化を完全準同型暗号化に変換するには、ノイズレベルを低減する操作が必要です。 この操作はブートストラップと呼ばれ、多くの完全準同型暗号化スキームで使用されます。 本稿では、数学トロイドの代数構造を利用して完全準同型暗号化を実現するトーラス(Torus FHE)上の完全準同型暗号化方式に焦点を当てます。**TFHEの利点**各完全準同型暗号化方式には独自の長所と短所がありますが、TFHEは現在、実際のシナリオでより効率的に実装されています。 TFHEのもう一つの重要な利点は、通常のブートストラップ操作を拡張して、機械学習の分野で重要な活性化関数などの単変量関数の計算を含むプログラマブルブートストラップ(PBS)です。TFHEの欠点の1つは、計算のすべての算術演算がPBS演算を必要とするのに対し、他のスキームではブートストラップ演算の間に一部の演算をバッチで実行できることです。仮定と近似**** 完全準同型暗号化を使用して大規模言語モデル(LLM)推論に必要な時間を見積もるために、いくつかの仮定を立てて評価します。 * トークンごとに必要な算術演算の数は、モデル内のパラメーター数の約 1–2 倍です。 各トークンはモデル全体を使用するため、これは下限であり、この下限は実際の需要に十分近いと仮定します。* 大規模言語モデルの各算術演算は、TFHEの算術演算にマッピングできます。 これは基本的に、両方のシナリオでの変数型のサイズの指標です。 INT4変数は大規模な言語モデルには十分であり、TFHEには実行可能であると仮定します。* 大規模な言語モデルの各算術演算は、完全準同型暗号化の算術演算にマッピングする必要があります。 これは、暗号化なしでモデルの一部を実行できないことを意味します。 Zamaによる最近のブログ投稿では、モデルのほとんどが暗号化なしでユーザーによってローカルに実行され、モデルの企業サーバー上で完全に準同型暗号化で実行されるのはごく一部(単一のアテンションヘッドなど)のみである、この仮定を使用しないFHE推論を検討しています。 この場合、ユーザーはここに示すように、精度をわずかに低下させて欠落しているヘッドのみを実行したり、欠落している部分を比較的安価にトレーニングして元のモデルに匹敵する結果を得ることができるため、このアプローチは実際にはモデルの知的財産を保護しません。* TFHE の各算術演算には PBS (プログラマブル ブートストラップ) が必要です。 PBSはTFHEコンピューティングの主なボトルネックです。* 最も先進的なTFHEの実装はFPTです。 これは、35マイクロ秒ごとにPBSを計算するFPGAインプリメンテーションです。LLMとFHEの課題****最新のテクノロジーの進歩により、現在利用可能な最高の完全準同型暗号化実装は、わずか35マイクロ秒で算術演算を実行できます。 ただし、GPT2のように複雑なモデルを検討する場合、1つのトークンに驚異的な15億回の操作が必要です。 これは、各トークンの処理時間が約52,000秒であることを意味します。理解を深めるために、言語モデルの場合、トークンは文字や完全な単語のようなものを表すことができます。 応答時間が 1 週間か 2 週間かかる言語モデルとの対話を想像してみてください。 これは受け入れられず、このような遅延は、リアルタイム通信やモデルの実際のアプリケーションでは明らかに実現不可能です。これは、現在の完全準同型暗号化技術の下では、リアルタイム推論が大規模な言語モデルにとって依然として大きな課題であることを示しています。 データ保護における完全準同型暗号化の重要性にもかかわらず、そのパフォーマンスの制限により、計算負荷の高いタスクの実際のシナリオで適用することが困難になる可能性があります。 リアルタイムの対話と迅速な応答の必要性は、他の安全なコンピューティングとプライバシー保護ソリューションの探求を必要とするかもしれません。考えられる解決策****大規模な言語モデルに完全準同型暗号化を適用するには、次のロードマップが考えられます。 1. 複数マシンによる並列処理:* 52,000 秒/トークンから開始。* 10,000台の並列マシンを導入することで、時間を5秒/トークンに短縮しました。 大規模な言語モデルは実際に高度に並列化でき、現在の推論は通常、数千を超えるGPUコアで並列に実行されることに注意してください。 2 高度なハードウェアへの移行:*改善から-5秒/トークンから開始* GPUまたはASICに切り替えると、トークンあたり0.1秒の処理時間を実現できます。 GPUはより即時の速度の向上を提供できますが、ASICは、ブログで前述したZPUのように、速度と消費電力の両方でより高い利益を提供できます。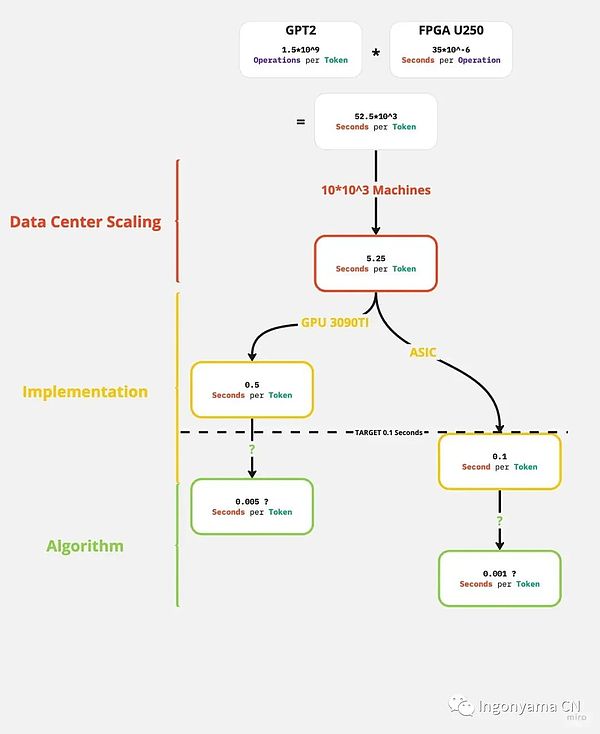 図に示すように、既存のデータアクセラレーション技術を用いて、完全準同型暗号化により大規模言語モデルのプライベート推論を実現することができます。 これは、十分に大規模なデータセンターへの大規模で実行可能な初期投資によってサポートできます。 ただし、この可能性はまだ低く、Copilot(120億パラメータ)やGPT3(1,750億パラメータ)などの大規模な大規模言語モデルの場合、埋めるべきギャップがまだあります。Copilotの場合、通常は人間の言語よりも簡潔なコード出力を生成するため、トークンスループットを小さくするだけで十分です。 スループット要件を8倍に減らすと、Copilotは実現可能性の目標も達成できます。最後のギャップは、より大きな並列化、より優れた実装、および完全準同型暗号化をガイドするより効率的なアルゴリズムを組み合わせることで埋めることができます。 Ingonyamaでは、アルゴリズムはこのギャップを埋めるための重要な部分であると考えており、現在、関連するアルゴリズムの研究開発に注力しています。概要**** 完全準同型暗号化のセキュリティと大規模な言語モデルの計算能力を組み合わせることで、AIインタラクションを再定義し、効率とプライバシーの両方を確保できます。 いくつかの課題はありますが、継続的な研究と革新を通じて、ChatGPTなどのAIモデルとのやり取りが即時かつプライベートになる未来を実現できます。 これにより、ユーザーはより効率的で安全なエクスペリエンスを提供し、さまざまな分野でAIテクノロジーの普及を促進します


完全準同型(FHE)を使用してLLMのプライバシーの懸念を解決
ソース: アンタルアルファラボ
ガイド
人工知能の台頭は驚くべきものです。 基本的なアルゴリズムからChatGPTやコパイロットなどの言語学習モデル(LLM)まで、AIは技術進化の最前線にあります。 これらのモデルがユーザーと対話し、大量のデータとプロンプトを処理するため、データプライバシーの懸念が特に重要になります。 その中で、AmazonやAppleなどの大企業は、AIインタラクションによって引き起こされる可能性のあるデータ侵害を防ぐために、ChatGPTなどのパブリックAPIへの従業員のアクセスを制限しています。 さらに、一定レベルのユーザープライバシーを義務付ける規制がまもなく導入されることを期待するのは合理的です。
これらのモデルとやり取りしたり、質問したり、共有したりするデータを非公開にするにはどうすればよいでしょうか。
-完全準同型暗号化 (FHE)
簡単な紹介
暗号の分野では、完全準同型暗号化は独創的な概念です。 その魅力は、最初にデータを復号化することなく、暗号化されたデータを直接計算できるため、機密情報のプライベートな推論を可能にするという独自の能力にあります。
この機能を使用すると、処理中のデータの安全性と、モデルの知的財産(IP)の完全な保護という2つの重要なことが保証されます。
プライバシーの理由と知的財産の保護
今日、「プライバシー」と「ユーザーエクスペリエンス」は魚とクマの足の関係のようであり、2つを組み合わせることはできません。 多くの場合、人々はより良いユーザーエクスペリエンスのために彼らの情報を処理するために第三者を信頼します。 これらのサードパーティ企業は、機能が不足しているよりプライバシーを強化するオンプレミスソリューションまたは豊富な機能のためにプライバシーを犠牲にするサービスのいずれかを選択することなく、ユーザーのプライバシーと高品質のユーザーサービスのバランスを見つけることができると考えています。
完全準同型暗号化により、モデルの知的財産を完全に保護したプライバシー推論が可能になります。 暗号化されたデータに対して計算を実行することで、大規模な言語モデルの知的財産を保護しながら、プロンプトの完全な機密性を確保します。
従来の暗号化方式 VS FHE
従来の暗号化スキームでは、暗号化された形式でデータに対して意味のある操作を実行する場合は、最初にデータを復号化する必要があります。 ただし、復号化によってデータのプレーンテキストが公開されるため、データは一瞬でも攻撃に対して脆弱になります。
対照的に、完全準同型暗号化は暗号文を直接操作できるため、操作全体を通して機密情報が「見えない」ようになります。
FHE が重要な理由
完全準同型暗号化の重要性は理論に限定されません。 データを復号化せずにデータ処理を実行したり、機密性の高い患者の詳細を取得せずに医療データベースを分析したりできるクラウドコンピューティングサービスを想像してみてください。 完全準同型暗号化の潜在的なアプリケーションは、安全な投票システムや暗号化されたデータベースのプライベート検索など、幅広く多様です。
FHEの数学的基礎
完全準同型暗号化は、量子耐性のある格子暗号技術であるフォールトトレラント学習(LWE)問題に基づいています。 LWE では、ランダムノイズを使用して、キーを所有していない限りデータを読み取れないようにします。 暗号化されたデータに対する算術演算は可能ですが、これは通常ノイズレベルを増加させます。 連続して実行される操作が多すぎると、キーを持っている人を含め、誰もデータを読み取ることができません。 これは部分準同型暗号化 (SHE) と呼ばれます。
部分準同型暗号化を完全準同型暗号化に変換するには、ノイズレベルを低減する操作が必要です。 この操作はブートストラップと呼ばれ、多くの完全準同型暗号化スキームで使用されます。 本稿では、数学トロイドの代数構造を利用して完全準同型暗号化を実現するトーラス(Torus FHE)上の完全準同型暗号化方式に焦点を当てます。
TFHEの利点
各完全準同型暗号化方式には独自の長所と短所がありますが、TFHEは現在、実際のシナリオでより効率的に実装されています。 TFHEのもう一つの重要な利点は、通常のブートストラップ操作を拡張して、機械学習の分野で重要な活性化関数などの単変量関数の計算を含むプログラマブルブートストラップ(PBS)です。
TFHEの欠点の1つは、計算のすべての算術演算がPBS演算を必要とするのに対し、他のスキームではブートストラップ演算の間に一部の演算をバッチで実行できることです。
仮定と近似****
完全準同型暗号化を使用して大規模言語モデル(LLM)推論に必要な時間を見積もるために、いくつかの仮定を立てて評価します。
LLMとFHEの課題****
最新のテクノロジーの進歩により、現在利用可能な最高の完全準同型暗号化実装は、わずか35マイクロ秒で算術演算を実行できます。 ただし、GPT2のように複雑なモデルを検討する場合、1つのトークンに驚異的な15億回の操作が必要です。 これは、各トークンの処理時間が約52,000秒であることを意味します。
理解を深めるために、言語モデルの場合、トークンは文字や完全な単語のようなものを表すことができます。 応答時間が 1 週間か 2 週間かかる言語モデルとの対話を想像してみてください。 これは受け入れられず、このような遅延は、リアルタイム通信やモデルの実際のアプリケーションでは明らかに実現不可能です。
これは、現在の完全準同型暗号化技術の下では、リアルタイム推論が大規模な言語モデルにとって依然として大きな課題であることを示しています。 データ保護における完全準同型暗号化の重要性にもかかわらず、そのパフォーマンスの制限により、計算負荷の高いタスクの実際のシナリオで適用することが困難になる可能性があります。 リアルタイムの対話と迅速な応答の必要性は、他の安全なコンピューティングとプライバシー保護ソリューションの探求を必要とするかもしれません。
考えられる解決策****
大規模な言語モデルに完全準同型暗号化を適用するには、次のロードマップが考えられます。
2 高度なハードウェアへの移行:
*改善から-5秒/トークンから開始
図に示すように、既存のデータアクセラレーション技術を用いて、完全準同型暗号化により大規模言語モデルのプライベート推論を実現することができます。 これは、十分に大規模なデータセンターへの大規模で実行可能な初期投資によってサポートできます。 ただし、この可能性はまだ低く、Copilot(120億パラメータ)やGPT3(1,750億パラメータ)などの大規模な大規模言語モデルの場合、埋めるべきギャップがまだあります。
Copilotの場合、通常は人間の言語よりも簡潔なコード出力を生成するため、トークンスループットを小さくするだけで十分です。 スループット要件を8倍に減らすと、Copilotは実現可能性の目標も達成できます。
最後のギャップは、より大きな並列化、より優れた実装、および完全準同型暗号化をガイドするより効率的なアルゴリズムを組み合わせることで埋めることができます。 Ingonyamaでは、アルゴリズムはこのギャップを埋めるための重要な部分であると考えており、現在、関連するアルゴリズムの研究開発に注力しています。
概要****
完全準同型暗号化のセキュリティと大規模な言語モデルの計算能力を組み合わせることで、AIインタラクションを再定義し、効率とプライバシーの両方を確保できます。 いくつかの課題はありますが、継続的な研究と革新を通じて、ChatGPTなどのAIモデルとのやり取りが即時かつプライベートになる未来を実現できます。 これにより、ユーザーはより効率的で安全なエクスペリエンスを提供し、さまざまな分野でAIテクノロジーの普及を促進します