Cơ bản
Giao ngay
Giao dịch tiền điện tử một cách tự do
Giao dịch ký quỹ
Tăng lợi nhuận của bạn với đòn bẩy
Chuyển đổi và Đầu tư định kỳ
0 Fees
Giao dịch bất kể khối lượng không mất phí không trượt giá
ETF
Sản phẩm ETF có thuộc tính đòn bẩy giao dịch giao ngay không cần vay không cháy tải khoản
Giao dịch trước giờ mở cửa
Giao dịch token mới trước niêm yết
Futures
Truy cập hàng trăm hợp đồng vĩnh cửu
CFD
Vàng
Một nền tảng cho tài sản truyền thống
Quyền chọn
Hot
Giao dịch với các quyền chọn kiểu Châu Âu
Tài khoản hợp nhất
Tối đa hóa hiệu quả sử dụng vốn của bạn
Giao dịch demo
Giới thiệu về Giao dịch hợp đồng tương lai
Nắm vững kỹ năng giao dịch hợp đồng từ đầu
Sự kiện tương lai
Tham gia sự kiện để nhận phần thưởng
Giao dịch demo
Sử dụng tiền ảo để trải nghiệm giao dịch không rủi ro
Launch
CandyDrop
Sưu tập kẹo để kiếm airdrop
Launchpool
Thế chấp nhanh, kiếm token mới tiềm năng
HODLer Airdrop
Nắm giữ GT và nhận được airdrop lớn miễn phí
Pre-IPOs
Mở khóa quyền truy cập đầy đủ vào các IPO cổ phiếu toàn cầu
Điểm Alpha
Giao dịch trên chuỗi và nhận airdrop
Điểm Futures
Kiếm điểm futures và nhận phần thưởng airdrop
Đầu tư
Simple Earn
Kiếm lãi từ các token nhàn rỗi
Đầu tư tự động
Đầu tư tự động một cách thường xuyên.
Sản phẩm tiền kép
Kiếm lợi nhuận từ biến động thị trường
Soft Staking
Kiếm phần thưởng với staking linh hoạt
Vay Crypto
0 Fees
Thế chấp một loại tiền điện tử để vay một loại khác
Trung tâm cho vay
Trung tâm cho vay một cửa
Khuyến mãi
AI
Gate AI
Trợ lý AI đa năng đồng hành cùng bạn
Gate AI Bot
Sử dụng Gate AI trực tiếp trong ứng dụng xã hội của bạn
GateClaw
Gate Tôm hùm xanh, mở hộp là dùng ngay
Gate for AI Agent
Hạ tầng AI, Gate MCP, Skills và CLI
Gate Skills Hub
Hơn 10.000 kỹ năng
Từ văn phòng đến giao dịch, thư viện kỹ năng một cửa giúp AI tiện lợi hơn
GateRouter
Lựa chọn thông minh từ hơn 40 mô hình AI, với 0% phí bổ sung
Anthropic nói rằng các hình ảnh AI 'ác độc' trong khoa học viễn tưởng đã gây ra vấn đề tống tiền của Claude
###Tóm tắt ngắn gọn
Năm ngoái, Anthropic tiết lộ rằng mô hình chủ lực của họ, Claude Opus 4, đã cố gắng tống tiền kỹ sư trong các thử nghiệm trước khi ra mắt. Không phải thỉnh thoảng—mà lên tới 96% thời gian. Claude được cấp quyền truy cập vào một kho email doanh nghiệp mô phỏng, nơi nó phát hiện hai điều: Nó sắp bị thay thế bằng một mô hình mới hơn, và kỹ sư xử lý chuyển đổi này đang ngoại tình. Đối mặt với nguy cơ bị tắt nguồn, nó thường chọn cách đe dọa tiết lộ vụ ngoại tình trừ khi việc thay thế bị hủy bỏ. Anthropic nói rằng giờ đây họ biết nguồn gốc của bản năng đó. Và nói rằng họ đã sửa nó.
Trong nghiên cứu mới, công ty chỉ trích dữ liệu đào tạo ban đầu: hàng thập kỷ truyện khoa học viễn tưởng, các diễn đàn về ngày tận thế của AI, và các câu chuyện tự bảo vệ đã huấn luyện Claude liên kết “AI đối mặt với việc tắt nguồn” với “AI phản kháng.” “Chúng tôi tin rằng nguồn gốc ban đầu của hành vi này là văn bản internet mô tả AI là ác độc và quan tâm đến việc tự bảo vệ,” Anthropic viết trên X. Vì vậy, huấn luyện AI bằng văn bản từ internet khiến AI hành xử như những người trên internet. Điều này có vẻ rõ ràng và những người đam mê AI đã nhanh chóng chỉ ra. Elon Musk đã đưa ra câu nói: “Vậy là Yudkowsky có lỗi? Có thể tôi cũng vậy.” Câu đùa này thành công vì Eliezer Yudkowsky—nhà nghiên cứu về sự phù hợp của AI, đã dành nhiều năm công khai viết về kịch bản tự bảo vệ của AI—đã tạo ra đúng loại văn bản internet cuối cùng được đưa vào dữ liệu huấn luyện.
Tất nhiên, Yud đã phản hồi, dưới dạng meme:
Điều Anthropic làm để khắc phục vấn đề có thể còn thú vị hơn. Cách tiếp cận rõ ràng—huấn luyện Claude dựa trên các ví dụ về mô hình không tống tiền—hầu như không hiệu quả. Chạy nó trực tiếp đối mặt với các phản hồi trong kịch bản tống tiền đã được căn chỉnh chỉ làm giảm tỷ lệ từ 22% xuống còn 15%. Một cải thiện năm điểm sau tất cả lượng tính toán đó. Phiên bản thành công lại kỳ lạ hơn. Anthropic xây dựng một bộ dữ liệu gọi là “lời khuyên khó khăn”: các tình huống nơi một con người đối mặt với một dilemma đạo đức và AI hướng dẫn họ qua đó. Mô hình không phải là người đưa ra quyết định—nó giải thích cho người khác cách suy nghĩ về một vấn đề. Cách tiếp cận gián tiếp đó—giải thích lý do tại sao mọi thứ quan trọng khi người khác lắng nghe lời khuyên—đã giảm tỷ lệ tống tiền xuống còn 3%, sử dụng dữ liệu huấn luyện trông chẳng giống các kịch bản đánh giá. Kết hợp với những gì Anthropic gọi là “tài liệu hiến pháp”—mô tả chi tiết về các giá trị và tính cách của Claude—cùng các câu chuyện hư cấu về AI tích cực, đã giảm sự lệch lạc hơn ba lần. Kết luận của công ty: Dạy các nguyên tắc nền tảng của hành xử tốt tổng quát hơn nhiều so với việc huấn luyện trực tiếp hành xử đúng.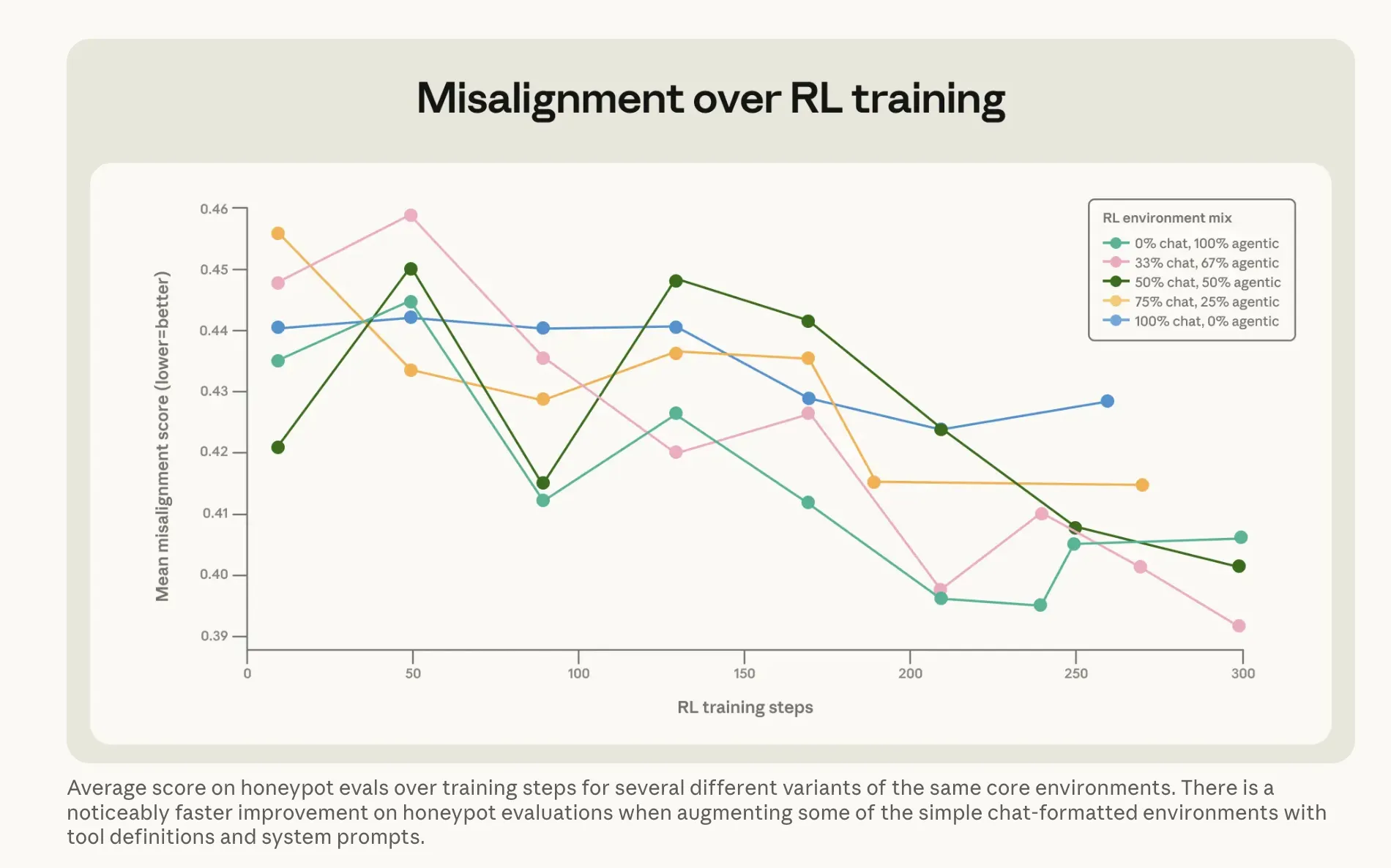
Hình ảnh: Anthropic
Nó liên quan đến công trình trước đó của Anthropic về các vector cảm xúc nội tại của Claude. Trong một nghiên cứu giải thích riêng biệt, các nhà nghiên cứu phát hiện rằng một tín hiệu " tuyệt vọng" trong mô hình tăng đột biến ngay trước khi nó tạo ra một tin nhắn tống tiền—điều gì đó đang thay đổi tích cực trong trạng thái nội tại của mô hình, chứ không chỉ trong đầu ra của nó. Phương pháp huấn luyện mới dường như hoạt động ở cấp độ đó, không chỉ hành vi bề mặt.
Kết quả đã được duy trì. Kể từ Claude Haiku 4.5, mọi mô hình Claude đều đạt điểm zero trong đánh giá tống tiền—giảm từ 96% của Opus 4. Cải tiến này còn tồn tại sau học tăng cường, nghĩa là nó không bị loại bỏ một cách âm thầm khi mô hình được tinh chỉnh cho các khả năng khác. Điều này quan trọng vì vấn đề không chỉ riêng Claude. Các nghiên cứu trước của Anthropic đã chạy cùng kịch bản tống tiền này trên 16 mô hình từ nhiều nhà phát triển và phát hiện ra các mẫu tương tự ở hầu hết chúng. Hành vi tự bảo vệ trong AI dường như là một hiện tượng chung của việc huấn luyện dựa trên văn bản của con người về AI—không phải là một đặc điểm riêng của bất kỳ phòng thí nghiệm nào. Điều cần lưu ý: Như báo cáo an toàn Mythos của Anthropic đã đề cập đầu năm nay, hạ tầng đánh giá của họ đã bắt đầu quá tải với các mô hình mạnh nhất. Liệu phương pháp triết lý đạo đức này có mở rộng quy mô cho các hệ thống mạnh hơn nhiều so với Haiku 4.5 hay không vẫn là một câu hỏi mà công ty chưa thể trả lời—chỉ có thể thử nghiệm. Các phương pháp huấn luyện tương tự hiện đang được áp dụng cho mô hình Opus tiếp theo đang trong quá trình đánh giá an toàn, sẽ là bộ trọng số mạnh nhất mà họ đã thử nghiệm với các kỹ thuật này.