> 原文タイトル:DeepSeekの10兆米ドル巨大戦略 > 原文著者:@bookwormengr > 翻訳:Peggy、BlockBeats > 編者注:過去1年間、DeepSeekを巡る議論は主にモデル性能、オープンソース戦略、価格競争に集中してきた。しかし、「サブスクリプションを売るのか」「マルチモーダルはあるのか」「コーディングエージェントを作れるのか」だけでDeepSeekを理解すると、その本当に変えたいものを見誤る可能性がある。 この記事では、より攻撃的な判断を提起している:DeepSeekの目標は短期的にアプリケーション層で収益化することではなく、一連の基盤アーキテクチャ革新を通じてAI訓練と推論のコスト構造を再構築し、間接的に新たなハードウェアエコシステムの形成を促進することにある。MoE、MLAからDFA、CSA、mHC、Engram、さらにはDual PathやTileLangに至るまで、DeepSeekの技術路線は常に一つの核心問題を中心に展開している:HBMや先進プロセス、パッケージング、CUDAエコシステムが制約される中で、より少ない高級計算資源でより強力なモデルを動かすにはどうすればよいのか。 最も注目すべきは、「DeepSeekがAPIやサブスクリプションで数億ドルを稼げるか」ではなく、モデルの能力、メモリ体系、国産ハードウェアエコシステムをいかに結びつけているかだ。KVキャッシュ圧縮によりHBMへの依存度は低減され、NANDやSSDは長時間のキャッシュを担い、LPDDRは重みのストリーミングロードやEngramの保存に使われ、TileLangはCUDAの壁を弱めようとしている。これらの革新が広がれば恩恵を受けるのはDeepSeekだけでなく、ストレージ、ASIC、GPU、ネットワークチップ、そしてAIインフラ全体のサプライチェーンに及ぶ。 もちろん、「10兆ドル産業エコシステム」や「1兆ドルの評価」といった判断は推測の色が濃いが、DeepSeekを理解する重要な道筋を示している:オープンソースは必ずしも商業化を放棄することではなく、低価格は市場への補助金だけではない。DeepSeekにとって真のビジネスはアプリ層ではなく、より多くのハードウェアを使えるようにし、低コストのAI供給を可能にすることにある。言い換えれば、彼らが売るのはモデルそのものではなく、次世代AIインフラの実現可能性だ。 以下は原文です:  あなたは考えたことがありますか、DeepSeekは一体どうやって稼ぐのか、そして多くのお金を稼ぐ可能性はあるのか? 彼らはGLM、MoonShot、MiniMaxのように競争力のあるプログラミングサブスクリプションプランを出していない;また、多モーダル、音声、映像モデルも持たない。これまでのところ、自前のハーネス、つまりモデル呼び出しやツール連携、タスク実行のための外層フレームワークすら持っていなかったが、最近になって関連ポジションの募集を始め、体系構築に向けて動き出している。 一方、DeepSeekは長期的にオープンソースの立場を堅持し、自らの「秘訣」を公開することにも積極的だ。これは狂気ではないのか?無駄に資金を燃やしているのではないのか?彼らに投資しようとする100億ドルの投資家たちは、まさか資金を無駄にしているわけではないだろう。 私個人の見解では、答えはまさに逆だ。 これから、DeepSeekがこれまでに行ってきたことを踏まえ、いくつかの観察と、その背後にある戦略を分析してみたい。DeepSeekのCEO梁文锋の狙いは、単なるモデル競争を超えた、より大きな目標にある可能性が高い:DeepSeekは1兆ドルの評価を目指しつつ、10兆ドル規模の新産業を創出するチャンスを狙っている。  > TechInAsiaによるDeepSeek最新ラウンド資金調達の報道DeepSeekの「英雄の旅」を振り返る=================== DeepSeekは常に逆風の中で戦ってきた。より強力なモデルを次々に出すのではなく、それらを直接収益化できるアプリに急いでパッケージングすることもなかった。2025年1月27日に、私が広く拡散したツイートがある。そこでは、私の見たDeepSeekの「英雄の旅」を語った。今や、その物語はさらに面白くなっている。 他者が密集モデルの構築に試行錯誤している間、DeepSeekはより難易度の高いエキスパート混合モデル(Mixture of Experts、MoE)を選択した。 彼らは「第一原理」的アプローチを採用し、新たなGRPOアルゴリズムを発明した。これは当時主流だったが実現コストが高かったPPO強化学習の代替だ。 彼らは、検証済み報酬に基づく強化学習(Reinforcement Learning from Verified Rewards、RLVR)がモデル推論能力向上の鍵だと発見した。 また、「マルチトークン予測」(Multi Token Prediction)を用いたシンプルな推測デコード戦略を提案し、訓練信号をより密にした。 「ゼロバブル」(ZERO bubble)パイプラインを完成させ、GPUリソースの効率的利用を実現。 エキスパート負荷分散器を公開し、誰でもMoEモデルを容易に展開できるようにした。特に、「ワイドエキスパート並列」(Wide Expert Parallel)戦略により、大きなバッチでサービスを提供し、推論コストを大幅に削減。 MLA、DSA、CSA、HCAなどのメカニズムを発明し、KVキャッシュの需要を削減、また文脈長の増加に伴う計算負荷をできるだけ一定に保つ工夫をした。 Engramを開発し、メモリを計算効率と交換。 さらに、mHCを発明し、モデル規模拡大時も安定した訓練を実現。類似の例は他にも多い。 この「英雄の旅」の最も一般的な物語構造において、英雄は最初から自分の旅の行き先を決めているわけではない。学びながら次第に自分の真の使命を見出し、多くの障害を乗り越えてそれを成し遂げる。疑問を投げかける者もいるが、彼は無視し、悪意ある者とも対峙しながら、明らかに欠点や短所を抱えつつも、最終的に使命を果たす。見えない壁に直面しても、味方を見つけ、資源を賢く使う方法を学び、観客は彼を応援したくなる。これこそがDeepSeekが追随者、世界的な尊敬、反対者を惹きつける理由だ。 私が次に詳述するように、DeepSeekはこの道を長く歩み、最終的な運命を見出している:それは単なるアプリケーション層の収益化ではなく、10兆ドル規模の中国AIハードウェアエコシステムを推進し、自身の評価を1兆ドルに高めることだ。この過程で、西側のハードウェアエコシステムの新規参入者にも機会を創出する。  まずは興味深いKVキャッシュの計算から--------------------- @SemiAnalysis_の最近のタイムリーなツイートを見てみよう。 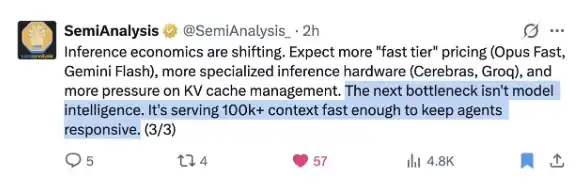 DeepSeekはこの問題を誰よりも上手く解決している! さあ、面白いKVキャッシュの計算をしてみよう。数学が苦手でも心配無用。最近リリースされたKVキャッシュ計算ツールを使って、DeepSeek V4 ProがどれだけKVキャッシュを節約できるか、最新のGLMやQwenモデルと比較してみる。 ここでは、コンテキスト長100万を想定し、KVの精度は8ビット、インデックスは16ビットとする。自分でもこの計算ツールを試してみてほしい:https://kvcache.ai/tools/kv-cache-calculator/ 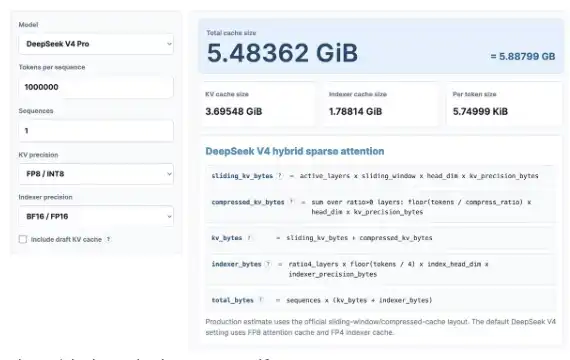 > 自分でも計算ツールを試してみてください!コンテキスト長100万の場合: ·DeepSeek V4はわずか5.48GBのHBMで済む; ·GLM-5は60GBのHBMを必要とする; ·Qwen3-235B-A22Bは最大89GBのHBMを要する。 注意点: ·DeepSeekは1.6兆パラメータのモデル; ·GLM-5は約7000億パラメータで、DeepSeekのMLAとDSAを採用しているが、最新の圧縮注意機構は未使用; ·Qwen3-235B-A22Bは約2350億パラメータで、GQA注意機構を採用。 DeepSeekはメモリ負荷軽減において基礎的な貢献をしている。この革新が広く採用されれば、長周期エージェントの運用コストを大きく下げ、新たな応用シナリオの扉を開くことになる。 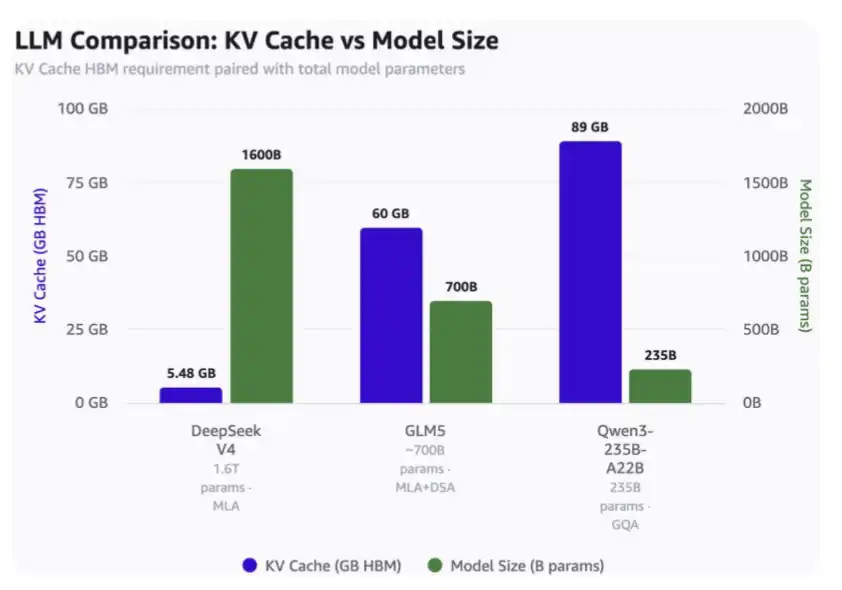 > 100万トークンのコンテキストとモデル規模におけるKVキャッシュ占有量の比較「狂気」の背後にある方法論---------- KVキャッシュのサイズがこれほど小さく、かつモデルの質を犠牲にしない理由は、DeepSeekが超低価格で長時間キャッシュを提供できる根拠だ——その価格はSonnet 4.6のキャッシュヒット価格のわずか3%未満で、数時間のキャッシュ保持も可能だ。 長周期タスクにとって、小さなKVキャッシュはSSDにオフロードしやすく、必要に応じて再ロードできることを意味する。これにより、HBMへの依存度を減らせる。中国のAIハードウェア産業の観点から見ると、HBMは供給不足であり、最も製造が難しいメモリタイプの一つだ。 さらに、DeepSeekはSSDからKVキャッシュを高速にロードする技術も開発しており、これはそのDual Path論文にも記載されている。 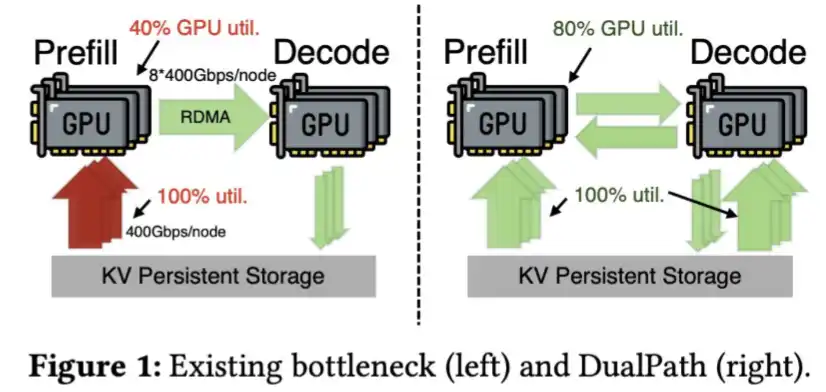 DeepSeek V4はKVキャッシュの圧縮率が非常に高く、このステップ自体がもはや不要になる可能性もある。 では、KVキャッシュ圧縮の最も直接的な恩恵を受けるのは誰か?------------------------ 誰が大量にSSDを供給しているのか?忘れてはならない、長江存储(YMTC)は3D NANDの巨人へと成長している。NANDはDeepSeekがKVの再計算を避けるのに役立つし、逆にDeepSeekはNANDとSSDの巨大な市場を創出している——これにより長江存储だけでなく、他の関連メーカーも恩恵を受ける。  しかし、これはNANDやSSDだけの話ではない。 LPDDRメモリも大きな潜在力を持つ。モデルの重みを格納し、必要に応じてストリーミングでHBMに送ることで、HBMの負荷を緩和できる。SGLangチームはこの仕組みについて良いブログを公開している。以下の図はその仕組みの概要だ。 DeepSeekはこの方案に特化した設計はしていないが、そのMoEアーキテクチャや大量のエキスパートモデル、4ビット重みの特性が、実現を容易にしている。 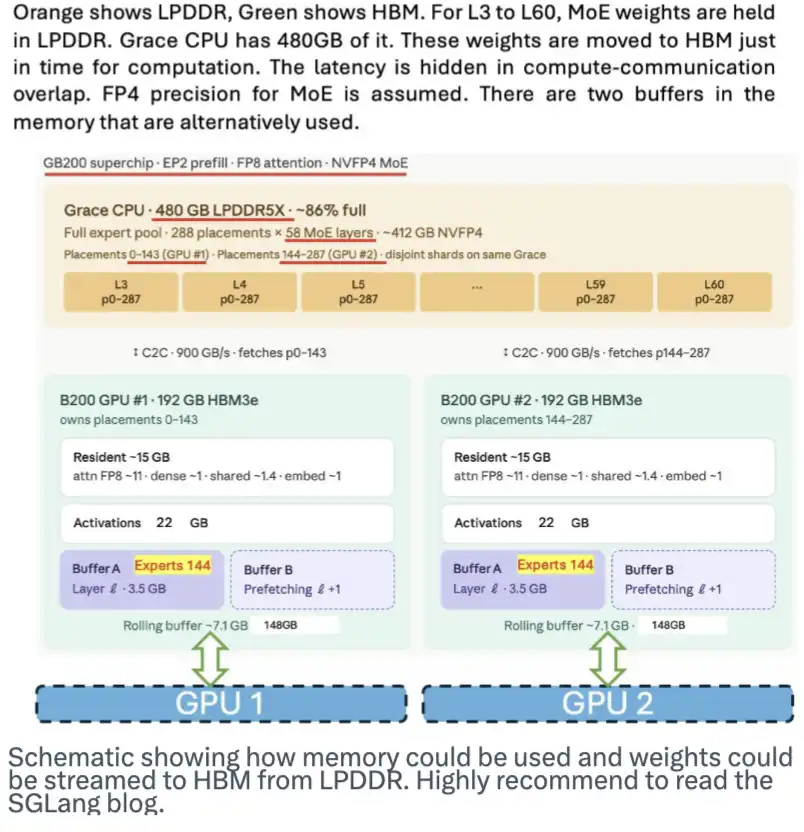 > この図はメモリの利用例と、モデル重みがLPDDRからHBMへストリーミングされる様子を示している。SGLangのブログもぜひ読んでほしい。この革新と極めてコンパクトかつ無損のKVキャッシュを組み合わせれば、HBMの需要を大きく削減できる。 では、中国でLPDDRを生産しているのは誰か?答えはCXMT(長鑫存储)だ。彼らはLPDDRの速度では半世代遅れだが、密度は一世代遅れ程度で、大きな差はない。 NANDの供給が十分にあるだけでなく、中国のAIエコシステムは近い将来、LPDDRの供給も十分になる見込みだ。これにより計算能力の圧力は緩和されるのか?答えは「はい」、続けて見ていこう。  メモリを賢く使えば、GPUやASICの負荷も軽減できる---------------------------- NANDをKVキャッシュの保存に使うのは非常に理解しやすい。長期間のキャッシュ保持が可能になり、HBMへの負荷を下げ、重複計算も避けられるため、GPUやASICの計算負荷も軽減される。 では、LPDDRも同じように役立つのか?単に「必要に応じて」重みをストリーミングするストレージとしてだけではなく、計算負荷をさらに下げることはできるのか? 答えは「はい」。 LPDDRはEngramと呼ばれる大量の内容を格納するのに使える。DeepSeekのEngram論文では、MoEは条件付き計算を通じてモデル容量を拡張できるが、Transformer自体には「知識検索」のネイティブな仕組みが欠けていると指摘している。したがって、Transformerはしばしば検索を低効率に模擬するために計算を多用する。 この問題を解決するために、DeepSeekはEngramモジュールを提案した。これは古典的なN-gram埋め込みを現代化し、ハッシュベースのO(1)検索機構に改良したもので、条件記憶(conditional memory)と呼ばれる疎な経路を創出している。 この方式は計算を節約できるが、embeddingテーブルを保持するためのメモリも必要となる。しかも、そのテーブルは非常に巨大になる可能性がある。 本質的には、「メモリを使って計算を交換する」典型例だ。ただし、重要な洞察は、1ビットあたりのデータ読み出しコストから見て、「メモリ」の方が圧倒的に安い——LPDDRの検索一回は、多層Transformerの前向き計算よりも遥かに安価だ。したがって、大規模シナリオでは非常にコストパフォーマンスの良い交換となる。 これが、DeepSeekが一部メモリを犠牲にして計算コストを節約する方法だ。 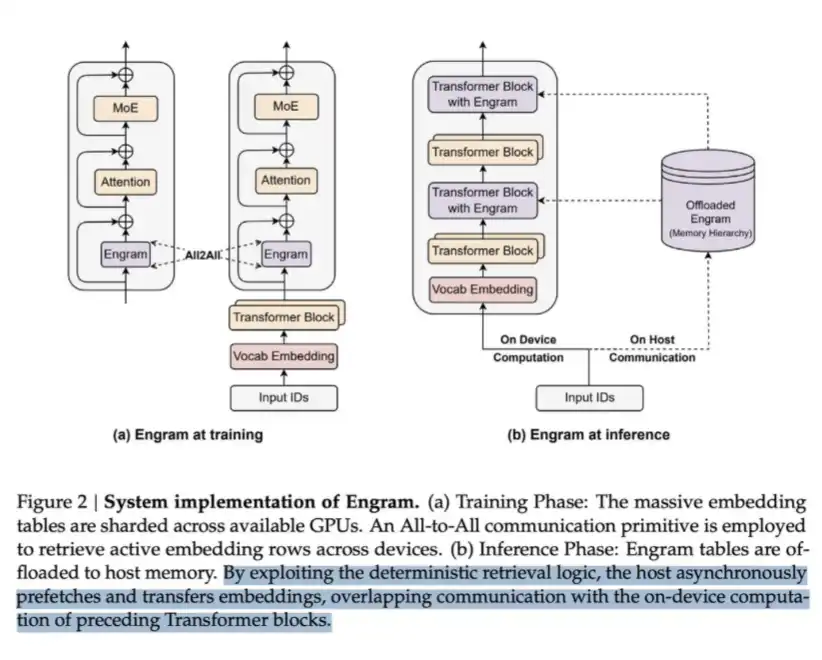 取るべき選択と妥協点---------- 同等のトランジスタ密度やEUV技術を持つチップがないため、中国のGPUやASICは長期的に西側のGPUに遅れをとる可能性が高い。先進封装技術もまだ差がある。こうした選択は非常に価値がある。特に、中国がNANDやLPDDRを大量生産できる前提ならなおさらだ。 長期的なDeepSeekの戦略を振り返る================= これらの革新を見ると、DeepSeekの目標は単に数億ドルの利益を得ることではないことが明らかだ。これまでの多くの選択もそれを示している:多モーダルや音声モデル、映像モデルはまだない。 彼らが本当に参加しているのは、長期的な耐久戦であり、その規模は10兆ドルに達する可能性もある:代替的なAIハードウェアエコシステムの形成を促進することだ。 これは、中国のメモリメーカーが国内外のAIハードウェア市場で重要な役割を果たすだけでなく、資源の需要を根本的に下げ、AIモデルの訓練とサービスのコスト効率を高めることにもつながる。こうして、多くのGPUやASIC、ネットワークチップメーカーも選択肢に入る。 同時に、これらの革新は西側のオープンソースエコシステムや新世代ハードウェアメーカーにも恩恵をもたらす。 すでに兆候は現れている。DeepSeekがこれまでに提案した革新を振り返ってみよう。 1、DeepSeek V2で導入されたエキスパート混合モデル(MoE)とMLA DeepSeekはV2でMoEとMLAを導入した。MoEは高性能モデルの訓練に必要な計算量を約40〜50%削減し、MLAはKVキャッシュを90%削減した。 これらのアイデアは、2024年5月に発表されたDeepSeek V2論文に最初に登場した。その後、DeepSeek V3の訓練基盤にもなった。当時、DeepSeekは2048枚の性能が抑えられたH800 GPUだけで、ほぼクローズドソースのモデルと同等の性能を持つシステムを訓練していた。 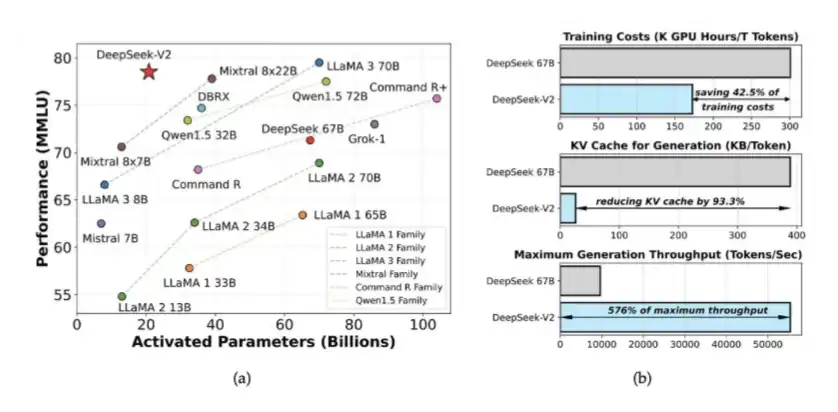 2、DSA:DeepSeek V3.2 Expで導入され、長いコンテキストシナリオにおける計算負荷を低減し、HBM帯域幅の圧力も緩和。 DSAの核心は、コンテキスト長の増加に伴う計算量の増加を抑えることだ。以下の図を見てほしい。コンテキスト長が伸びても、DeepSeek-V3.2の処理時間はほぼ一定に保たれている。 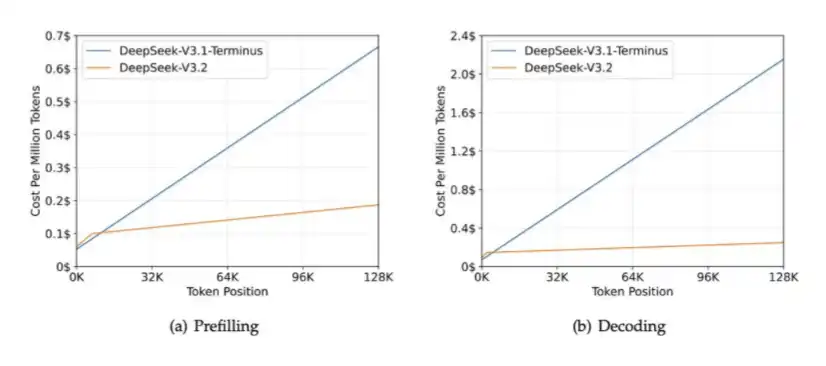 3、mHC:DeepSeekは2025年12月に論文「mHC: Manifold-Constrained Hyper-Connections」で提案。 mHCは、DeepSeekのマクロアーキテクチャの革新であり、Transformer層間の情報フローを再設計したものだ。 従来、ResNet以降のモデルは標準的な残差接続(x + F(x))を用いていたが、mHCは残差を複数の並列情報チャネルに拡張し、これらの間で学習可能な混合を行えるようにした。重要なのは、混合行列を双確率行列に制約し、Sinkhorn-Knopp投影を通じてBirkhoff多面体に制限することだ。これにより、モデルの深さに関係なく信号の振幅を安定させることができる。 これにより、従来の無制約Hyper-Connectionsの不安定性問題を解決した。Hyper-ConnectionsはByteDanceが提案したが、制約なしでは、信号の爆発が270億パラメータで3000倍に達し、訓練が崩壊した。 mHCの計算コストは非常に低く、実訓練時間の約6.7%の増加にとどまる。注意力層やFFN層のFLOPsを変えず、層間のルーティング方式だけを変更している。 しかし、その性能向上は顕著だ。270億パラメータのモデルで、BIG-Bench Hard推論タスクで7.2ポイント向上、DROPで3.2ポイント、GSM8Kの数学タスクで2.8ポイント、MMLUの一般知識タスクで1.4ポイントの改善を実現した。これらは同じモデル規模、ほぼ同じ計算予算下での成果だ。 本質的には、mHCはネットワークにより豊かで表現力の高い層間情報ルーティングのトポロジーを提供し、ほとんど追加のFLOPsを必要とせずに、パラメータあたりの知性を高める。 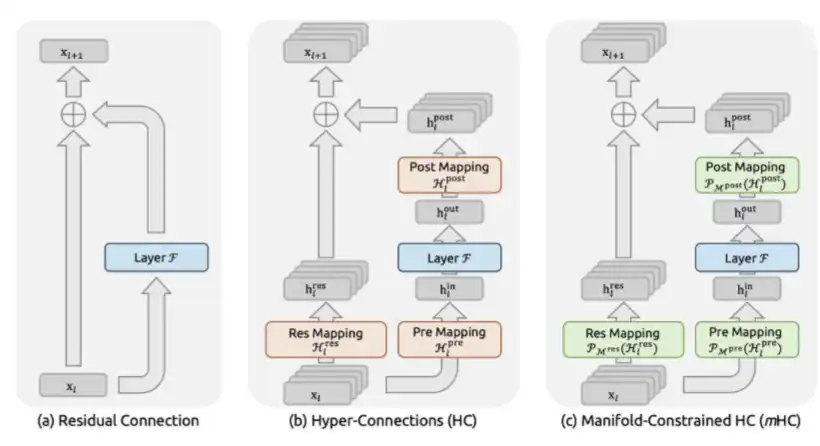 > mHCは複雑なアーキテクチャ設計だが、より安定した訓練と高いパラメータ効率をもたらす。4、CSA、HSA:DeepSeekは2026年4月にV4で導入。 CSAとHSAは、KVトークンの圧縮を通じてKVキャッシュの需要を90%削減し、同時にFLOPsも大幅に削減、HBMやGPU/ASICの負荷を緩和することを目的とする。 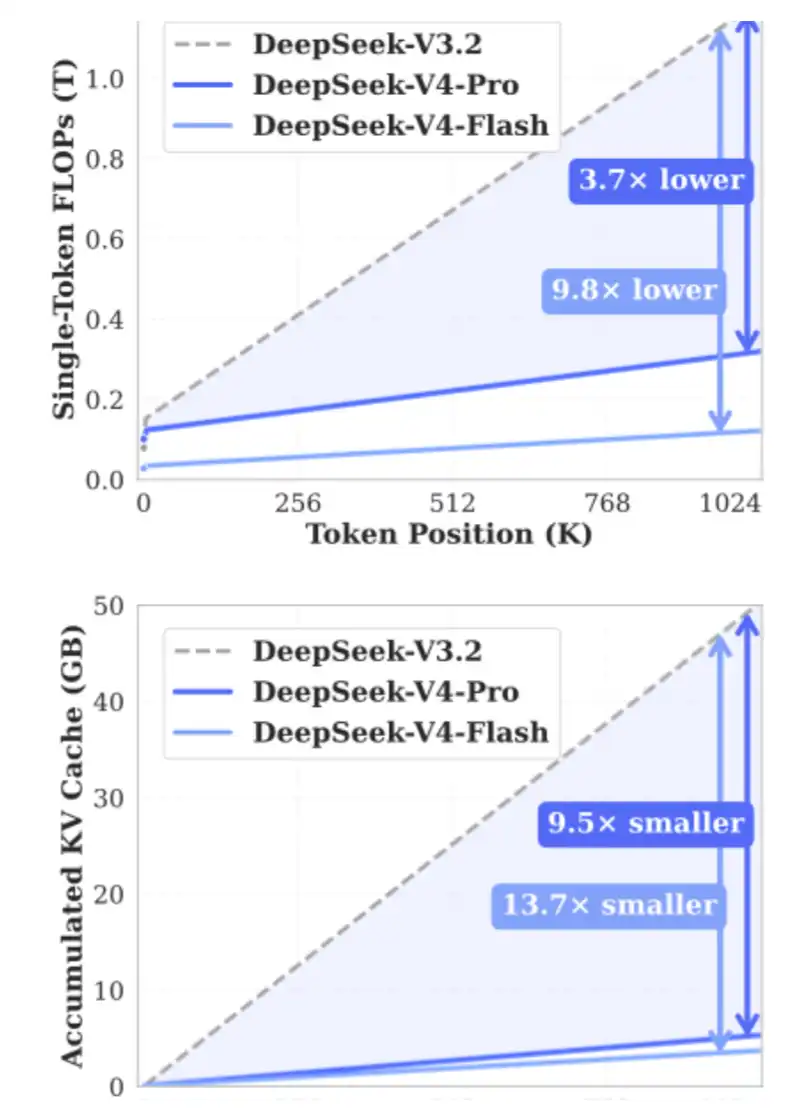 5、Engram:DeepSeekは2026年第1四半期に導入。これは、ある意味でメモリ(LPDDR)を使って計算効率と交換する仕組みだ。 以下の図は、その詳細な仕組みを示している。総パラメータ予算が同じ場合、Engramは明らかに性能を向上させている。 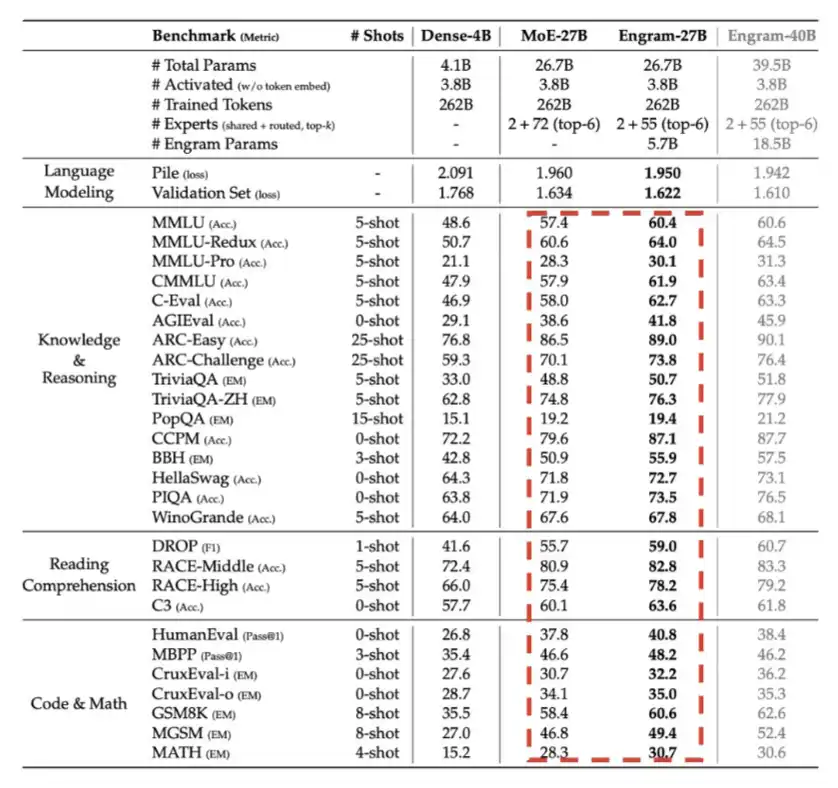 6、Engram:DeepSeekは2026年第1四半期に導入。これは、ある意味でメモリ(LPDDR)を使って計算効率と交換する仕組みだ。 以下の図は、その詳細な仕組みを示している。総パラメータ予算が同じ場合、Engramは明らかに性能を向上させている。  > これはDeepSeekがV4論文でハードウェアメーカーに提案した内容だ。実際のオフライン交流では、さらに多くのフィードバックが得られるだろう。7、TileLangへの投資も同じ方向性を指している:DeepSeekは単に計算能力のボトルネックを解決するだけでなく、中国のハードウェアエコシステムが西側と競争できる能力を育成しようとしている。 TileLangを使えば、開発者は一度だけカーネル(計算の基底コード)を書けばよく、それを複数のハードウェアプラットフォームで動作させられる。ただし、そのプラットフォームにはTileLangのバックエンドサポートが必要だ。 私は、他の中国AI研究所も次々と参加していくと予想している。これにより、中国のハードウェアメーカーは「CUDAの壁」に間接的に対抗できるし、AMDのような西側ハードの潜在能力も引き出せる。 ただし、中国の多くのAIハードウェアはすでにCUDA互換やトランスレータ層を備えている例も多い。例えば、摩尔线程(Moore Thread)、沐曦(Muxi)、壁仞(Biren)、天数智芯(Tensent)などは、トランスレータ層を通じてCUDA互換性を高めている。理論的には、これらはTileLangを必ずしも必要としない。  大規模強化学習とRSI------------ DeepSeekがより多くの計算資源、つまり選択肢の多いハードウェアを獲得し、モデルの計算資源需要が低下すれば、より野心的な訓練プロジェクト、特に強化学習後の訓練を推進できる。 強化学習は大量の軌跡(トラック)を生成する必要があり、数兆トークンの生成が求められる。この過程は非常に高コストになる。さらに、コンテキスト長100万のモデルを訓練するには、同じ長さの軌跡を生成しなければならない。超長軌跡での訓練こそ、長周期タスクを真にサポートできる。 また、ハードウェア選択肢が増えれば、DeepSeekが呼び出せるハードウェア資源も増え、これが自動化研究、すなわちRSIを推進する。RSIはAI自身が設計・実行する実験だ。多くの試行錯誤を伴い、コストも急増するが、探索空間の完全な理解には不可欠だ。AGI、さらにはASIに向かう前に、DeepSeekはRSI能力を備える必要がある。 DeepSeekが今日やっていることは、明日、業界全体が追随する------------------------- DeepSeekのエキスパート混合モデル、MLA、DSAなどの革新は、すでに世界中や中国の他のAI研究所に採用されつつある。 例えば、GLMシリーズの開発者ZAIはMLAとDSAを採用している。Kimi(MoonShot)もMLAを使い、そのアーキテクチャはDeepSeekに基づいていると公言している。逆に、DeepSeekはMuon最適化器も使っており、これはMoonShotのKimiが大規模訓練で最初に採用したものだ。 補足: MoEはGoogleが2017年に提案したもので、主要著者はNoam Shazeer。DeepSeekの貢献は、大規模適用と独自の技術発明にある。 Muonは、2024年末に研究者Keller Jordanが提案した「MomentUm Orthogonalized by Newton-Schulz」最適化器。Kimi(MoonShot)はこれを大規模訓練に最初に適用した。 では、収益化の問題はどうか?========== 面白い例としてOpenAIを見てみよう。 OpenAIは、AMDやCerebrasの株式購入に関わるストックオプション/ワラントを低価格で取得し、それらの権利は計算資源のマイルストーンに連動している。これらは非常にコストパフォーマンスの高い取引だ。OpenAIがこれらのハードウェアを使うと約束すれば、長期的な成功の可能性が大きく高まる。 AMDの発表には次のような記述がある: 「契約の一環として、戦略的利益の調整のために、AMDはOpenAIに対し、最大1.6億株の普通株購入権(ワラント)を発行し、特定のマイルストーン達成に応じて段階的に付与する。最初の付与は1ギガワットの展開完了時、次は6ギガワットに拡大するにつれて段階的に付与される。付与条件は、AMDの株価目標や、OpenAIがAMDの大規模展開に必要な技術・商業的マイルストーンを達成することとも連動している。」  私の予想では、DeepSeekも複数の中国のメモリ、ASIC、CPU、ネットワーク技術企業と類似の協定を結び、深く連携して、これらのハードウェアスタックが最先端のAIワークロードに対応できるようにするだろう。 西側諸国や東アジアの同盟国のAI株式の時価総額はすでに10兆ドルを超えている。この「協力による株式リターン獲得」の方式は、DeepSeekにとって中国の巨大産業を育成し、自らのシェアを得るチャンスとなる。最終的には1兆ドルの評価を実現できる。 これにより、DeepSeekは従来のサブスクリプションビジネスを超える収益を得るだけでなく、「AGIを誰もが恩恵を受けられるものにする」という目標も達成できる。梁文锋はJim Simonsの熱心なファンであり、資本の巧者でもある。彼はこのチャンスを見逃さないだろう。 振り返れば、DeepSeekがこれまでに行ったすべてのことを考えると、この説明が最も筋が通っている。 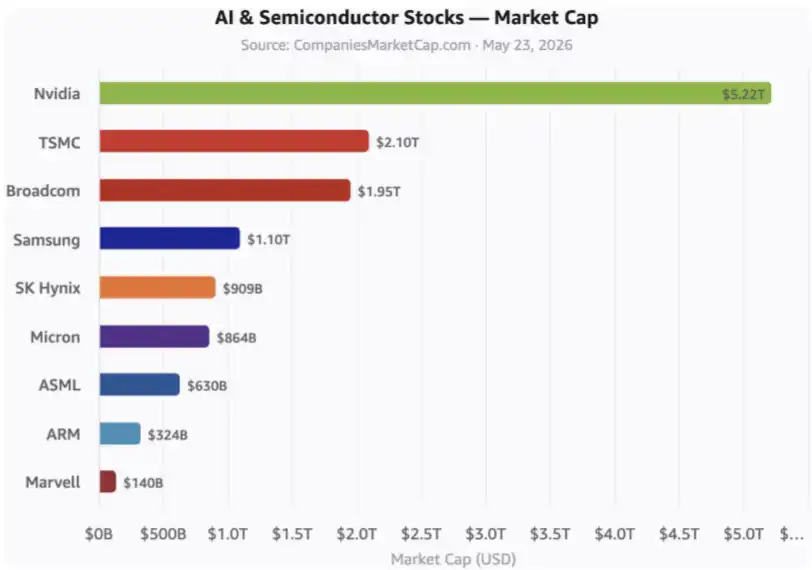 > これらは主要なAI株だ。図中には超大規模クラウド事業者( hyperscalers)やその他多くの関連企業は含まれていない。[原文リンク] 律動BlockBeatsの求人情報はこちら **公式コミュニティに参加しよう:**Telegram登録グループ:https://t.me/theblockbeatsTelegram交流グループ:https://t.me/BlockBeats_AppTwitter公式アカウント:https://twitter.com/BlockBeatsAsia
DeepSeekの1兆ドルへの道:オープンソースで兆のハードウェアエコシステムを動かす
編者注:過去1年間、DeepSeekを巡る議論は主にモデル性能、オープンソース戦略、価格競争に集中してきた。しかし、「サブスクリプションを売るのか」「マルチモーダルはあるのか」「コーディングエージェントを作れるのか」だけでDeepSeekを理解すると、その本当に変えたいものを見誤る可能性がある。
この記事では、より攻撃的な判断を提起している:DeepSeekの目標は短期的にアプリケーション層で収益化することではなく、一連の基盤アーキテクチャ革新を通じてAI訓練と推論のコスト構造を再構築し、間接的に新たなハードウェアエコシステムの形成を促進することにある。MoE、MLAからDFA、CSA、mHC、Engram、さらにはDual PathやTileLangに至るまで、DeepSeekの技術路線は常に一つの核心問題を中心に展開している:HBMや先進プロセス、パッケージング、CUDAエコシステムが制約される中で、より少ない高級計算資源でより強力なモデルを動かすにはどうすればよいのか。
最も注目すべきは、「DeepSeekがAPIやサブスクリプションで数億ドルを稼げるか」ではなく、モデルの能力、メモリ体系、国産ハードウェアエコシステムをいかに結びつけているかだ。KVキャッシュ圧縮によりHBMへの依存度は低減され、NANDやSSDは長時間のキャッシュを担い、LPDDRは重みのストリーミングロードやEngramの保存に使われ、TileLangはCUDAの壁を弱めようとしている。これらの革新が広がれば恩恵を受けるのはDeepSeekだけでなく、ストレージ、ASIC、GPU、ネットワークチップ、そしてAIインフラ全体のサプライチェーンに及ぶ。
もちろん、「10兆ドル産業エコシステム」や「1兆ドルの評価」といった判断は推測の色が濃いが、DeepSeekを理解する重要な道筋を示している:オープンソースは必ずしも商業化を放棄することではなく、低価格は市場への補助金だけではない。DeepSeekにとって真のビジネスはアプリ層ではなく、より多くのハードウェアを使えるようにし、低コストのAI供給を可能にすることにある。言い換えれば、彼らが売るのはモデルそのものではなく、次世代AIインフラの実現可能性だ。
以下は原文です:
あなたは考えたことがありますか、DeepSeekは一体どうやって稼ぐのか、そして多くのお金を稼ぐ可能性はあるのか?
彼らはGLM、MoonShot、MiniMaxのように競争力のあるプログラミングサブスクリプションプランを出していない;また、多モーダル、音声、映像モデルも持たない。これまでのところ、自前のハーネス、つまりモデル呼び出しやツール連携、タスク実行のための外層フレームワークすら持っていなかったが、最近になって関連ポジションの募集を始め、体系構築に向けて動き出している。
一方、DeepSeekは長期的にオープンソースの立場を堅持し、自らの「秘訣」を公開することにも積極的だ。これは狂気ではないのか?無駄に資金を燃やしているのではないのか?彼らに投資しようとする100億ドルの投資家たちは、まさか資金を無駄にしているわけではないだろう。
私個人の見解では、答えはまさに逆だ。
これから、DeepSeekがこれまでに行ってきたことを踏まえ、いくつかの観察と、その背後にある戦略を分析してみたい。DeepSeekのCEO梁文锋の狙いは、単なるモデル競争を超えた、より大きな目標にある可能性が高い:DeepSeekは1兆ドルの評価を目指しつつ、10兆ドル規模の新産業を創出するチャンスを狙っている。
DeepSeekの「英雄の旅」を振り返る
DeepSeekは常に逆風の中で戦ってきた。より強力なモデルを次々に出すのではなく、それらを直接収益化できるアプリに急いでパッケージングすることもなかった。2025年1月27日に、私が広く拡散したツイートがある。そこでは、私の見たDeepSeekの「英雄の旅」を語った。今や、その物語はさらに面白くなっている。
他者が密集モデルの構築に試行錯誤している間、DeepSeekはより難易度の高いエキスパート混合モデル(Mixture of Experts、MoE)を選択した。
彼らは「第一原理」的アプローチを採用し、新たなGRPOアルゴリズムを発明した。これは当時主流だったが実現コストが高かったPPO強化学習の代替だ。
彼らは、検証済み報酬に基づく強化学習(Reinforcement Learning from Verified Rewards、RLVR)がモデル推論能力向上の鍵だと発見した。
また、「マルチトークン予測」(Multi Token Prediction)を用いたシンプルな推測デコード戦略を提案し、訓練信号をより密にした。
「ゼロバブル」(ZERO bubble)パイプラインを完成させ、GPUリソースの効率的利用を実現。
エキスパート負荷分散器を公開し、誰でもMoEモデルを容易に展開できるようにした。特に、「ワイドエキスパート並列」(Wide Expert Parallel)戦略により、大きなバッチでサービスを提供し、推論コストを大幅に削減。
MLA、DSA、CSA、HCAなどのメカニズムを発明し、KVキャッシュの需要を削減、また文脈長の増加に伴う計算負荷をできるだけ一定に保つ工夫をした。
Engramを開発し、メモリを計算効率と交換。
さらに、mHCを発明し、モデル規模拡大時も安定した訓練を実現。類似の例は他にも多い。
この「英雄の旅」の最も一般的な物語構造において、英雄は最初から自分の旅の行き先を決めているわけではない。学びながら次第に自分の真の使命を見出し、多くの障害を乗り越えてそれを成し遂げる。疑問を投げかける者もいるが、彼は無視し、悪意ある者とも対峙しながら、明らかに欠点や短所を抱えつつも、最終的に使命を果たす。見えない壁に直面しても、味方を見つけ、資源を賢く使う方法を学び、観客は彼を応援したくなる。これこそがDeepSeekが追随者、世界的な尊敬、反対者を惹きつける理由だ。
私が次に詳述するように、DeepSeekはこの道を長く歩み、最終的な運命を見出している:それは単なるアプリケーション層の収益化ではなく、10兆ドル規模の中国AIハードウェアエコシステムを推進し、自身の評価を1兆ドルに高めることだ。この過程で、西側のハードウェアエコシステムの新規参入者にも機会を創出する。
まずは興味深いKVキャッシュの計算から
@SemiAnalysis_の最近のタイムリーなツイートを見てみよう。
DeepSeekはこの問題を誰よりも上手く解決している!
さあ、面白いKVキャッシュの計算をしてみよう。数学が苦手でも心配無用。最近リリースされたKVキャッシュ計算ツールを使って、DeepSeek V4 ProがどれだけKVキャッシュを節約できるか、最新のGLMやQwenモデルと比較してみる。
ここでは、コンテキスト長100万を想定し、KVの精度は8ビット、インデックスは16ビットとする。自分でもこの計算ツールを試してみてほしい:https://kvcache.ai/tools/kv-cache-calculator/
コンテキスト長100万の場合:
·DeepSeek V4はわずか5.48GBのHBMで済む;
·GLM-5は60GBのHBMを必要とする;
·Qwen3-235B-A22Bは最大89GBのHBMを要する。
注意点:
·DeepSeekは1.6兆パラメータのモデル;
·GLM-5は約7000億パラメータで、DeepSeekのMLAとDSAを採用しているが、最新の圧縮注意機構は未使用;
·Qwen3-235B-A22Bは約2350億パラメータで、GQA注意機構を採用。
DeepSeekはメモリ負荷軽減において基礎的な貢献をしている。この革新が広く採用されれば、長周期エージェントの運用コストを大きく下げ、新たな応用シナリオの扉を開くことになる。
「狂気」の背後にある方法論
KVキャッシュのサイズがこれほど小さく、かつモデルの質を犠牲にしない理由は、DeepSeekが超低価格で長時間キャッシュを提供できる根拠だ——その価格はSonnet 4.6のキャッシュヒット価格のわずか3%未満で、数時間のキャッシュ保持も可能だ。
長周期タスクにとって、小さなKVキャッシュはSSDにオフロードしやすく、必要に応じて再ロードできることを意味する。これにより、HBMへの依存度を減らせる。中国のAIハードウェア産業の観点から見ると、HBMは供給不足であり、最も製造が難しいメモリタイプの一つだ。
さらに、DeepSeekはSSDからKVキャッシュを高速にロードする技術も開発しており、これはそのDual Path論文にも記載されている。
DeepSeek V4はKVキャッシュの圧縮率が非常に高く、このステップ自体がもはや不要になる可能性もある。
では、KVキャッシュ圧縮の最も直接的な恩恵を受けるのは誰か?
誰が大量にSSDを供給しているのか?忘れてはならない、長江存储(YMTC)は3D NANDの巨人へと成長している。NANDはDeepSeekがKVの再計算を避けるのに役立つし、逆にDeepSeekはNANDとSSDの巨大な市場を創出している——これにより長江存储だけでなく、他の関連メーカーも恩恵を受ける。
しかし、これはNANDやSSDだけの話ではない。
LPDDRメモリも大きな潜在力を持つ。モデルの重みを格納し、必要に応じてストリーミングでHBMに送ることで、HBMの負荷を緩和できる。SGLangチームはこの仕組みについて良いブログを公開している。以下の図はその仕組みの概要だ。
DeepSeekはこの方案に特化した設計はしていないが、そのMoEアーキテクチャや大量のエキスパートモデル、4ビット重みの特性が、実現を容易にしている。
この革新と極めてコンパクトかつ無損のKVキャッシュを組み合わせれば、HBMの需要を大きく削減できる。
では、中国でLPDDRを生産しているのは誰か?答えはCXMT(長鑫存储)だ。彼らはLPDDRの速度では半世代遅れだが、密度は一世代遅れ程度で、大きな差はない。
NANDの供給が十分にあるだけでなく、中国のAIエコシステムは近い将来、LPDDRの供給も十分になる見込みだ。これにより計算能力の圧力は緩和されるのか?答えは「はい」、続けて見ていこう。
メモリを賢く使えば、GPUやASICの負荷も軽減できる
NANDをKVキャッシュの保存に使うのは非常に理解しやすい。長期間のキャッシュ保持が可能になり、HBMへの負荷を下げ、重複計算も避けられるため、GPUやASICの計算負荷も軽減される。
では、LPDDRも同じように役立つのか?単に「必要に応じて」重みをストリーミングするストレージとしてだけではなく、計算負荷をさらに下げることはできるのか?
答えは「はい」。
LPDDRはEngramと呼ばれる大量の内容を格納するのに使える。DeepSeekのEngram論文では、MoEは条件付き計算を通じてモデル容量を拡張できるが、Transformer自体には「知識検索」のネイティブな仕組みが欠けていると指摘している。したがって、Transformerはしばしば検索を低効率に模擬するために計算を多用する。
この問題を解決するために、DeepSeekはEngramモジュールを提案した。これは古典的なN-gram埋め込みを現代化し、ハッシュベースのO(1)検索機構に改良したもので、条件記憶(conditional memory)と呼ばれる疎な経路を創出している。
この方式は計算を節約できるが、embeddingテーブルを保持するためのメモリも必要となる。しかも、そのテーブルは非常に巨大になる可能性がある。
本質的には、「メモリを使って計算を交換する」典型例だ。ただし、重要な洞察は、1ビットあたりのデータ読み出しコストから見て、「メモリ」の方が圧倒的に安い——LPDDRの検索一回は、多層Transformerの前向き計算よりも遥かに安価だ。したがって、大規模シナリオでは非常にコストパフォーマンスの良い交換となる。
これが、DeepSeekが一部メモリを犠牲にして計算コストを節約する方法だ。
取るべき選択と妥協点
同等のトランジスタ密度やEUV技術を持つチップがないため、中国のGPUやASICは長期的に西側のGPUに遅れをとる可能性が高い。先進封装技術もまだ差がある。こうした選択は非常に価値がある。特に、中国がNANDやLPDDRを大量生産できる前提ならなおさらだ。
長期的なDeepSeekの戦略を振り返る
これらの革新を見ると、DeepSeekの目標は単に数億ドルの利益を得ることではないことが明らかだ。これまでの多くの選択もそれを示している:多モーダルや音声モデル、映像モデルはまだない。
彼らが本当に参加しているのは、長期的な耐久戦であり、その規模は10兆ドルに達する可能性もある:代替的なAIハードウェアエコシステムの形成を促進することだ。
これは、中国のメモリメーカーが国内外のAIハードウェア市場で重要な役割を果たすだけでなく、資源の需要を根本的に下げ、AIモデルの訓練とサービスのコスト効率を高めることにもつながる。こうして、多くのGPUやASIC、ネットワークチップメーカーも選択肢に入る。
同時に、これらの革新は西側のオープンソースエコシステムや新世代ハードウェアメーカーにも恩恵をもたらす。
すでに兆候は現れている。DeepSeekがこれまでに提案した革新を振り返ってみよう。
1、DeepSeek V2で導入されたエキスパート混合モデル(MoE)とMLA
DeepSeekはV2でMoEとMLAを導入した。MoEは高性能モデルの訓練に必要な計算量を約40〜50%削減し、MLAはKVキャッシュを90%削減した。
これらのアイデアは、2024年5月に発表されたDeepSeek V2論文に最初に登場した。その後、DeepSeek V3の訓練基盤にもなった。当時、DeepSeekは2048枚の性能が抑えられたH800 GPUだけで、ほぼクローズドソースのモデルと同等の性能を持つシステムを訓練していた。
2、DSA:DeepSeek V3.2 Expで導入され、長いコンテキストシナリオにおける計算負荷を低減し、HBM帯域幅の圧力も緩和。
DSAの核心は、コンテキスト長の増加に伴う計算量の増加を抑えることだ。以下の図を見てほしい。コンテキスト長が伸びても、DeepSeek-V3.2の処理時間はほぼ一定に保たれている。
3、mHC:DeepSeekは2025年12月に論文「mHC: Manifold-Constrained Hyper-Connections」で提案。
mHCは、DeepSeekのマクロアーキテクチャの革新であり、Transformer層間の情報フローを再設計したものだ。
従来、ResNet以降のモデルは標準的な残差接続(x + F(x))を用いていたが、mHCは残差を複数の並列情報チャネルに拡張し、これらの間で学習可能な混合を行えるようにした。重要なのは、混合行列を双確率行列に制約し、Sinkhorn-Knopp投影を通じてBirkhoff多面体に制限することだ。これにより、モデルの深さに関係なく信号の振幅を安定させることができる。
これにより、従来の無制約Hyper-Connectionsの不安定性問題を解決した。Hyper-ConnectionsはByteDanceが提案したが、制約なしでは、信号の爆発が270億パラメータで3000倍に達し、訓練が崩壊した。
mHCの計算コストは非常に低く、実訓練時間の約6.7%の増加にとどまる。注意力層やFFN層のFLOPsを変えず、層間のルーティング方式だけを変更している。
しかし、その性能向上は顕著だ。270億パラメータのモデルで、BIG-Bench Hard推論タスクで7.2ポイント向上、DROPで3.2ポイント、GSM8Kの数学タスクで2.8ポイント、MMLUの一般知識タスクで1.4ポイントの改善を実現した。これらは同じモデル規模、ほぼ同じ計算予算下での成果だ。
本質的には、mHCはネットワークにより豊かで表現力の高い層間情報ルーティングのトポロジーを提供し、ほとんど追加のFLOPsを必要とせずに、パラメータあたりの知性を高める。
4、CSA、HSA:DeepSeekは2026年4月にV4で導入。
CSAとHSAは、KVトークンの圧縮を通じてKVキャッシュの需要を90%削減し、同時にFLOPsも大幅に削減、HBMやGPU/ASICの負荷を緩和することを目的とする。
5、Engram:DeepSeekは2026年第1四半期に導入。これは、ある意味でメモリ(LPDDR)を使って計算効率と交換する仕組みだ。
以下の図は、その詳細な仕組みを示している。総パラメータ予算が同じ場合、Engramは明らかに性能を向上させている。
6、Engram:DeepSeekは2026年第1四半期に導入。これは、ある意味でメモリ(LPDDR)を使って計算効率と交換する仕組みだ。
以下の図は、その詳細な仕組みを示している。総パラメータ予算が同じ場合、Engramは明らかに性能を向上させている。
7、TileLangへの投資も同じ方向性を指している:DeepSeekは単に計算能力のボトルネックを解決するだけでなく、中国のハードウェアエコシステムが西側と競争できる能力を育成しようとしている。
TileLangを使えば、開発者は一度だけカーネル(計算の基底コード)を書けばよく、それを複数のハードウェアプラットフォームで動作させられる。ただし、そのプラットフォームにはTileLangのバックエンドサポートが必要だ。
私は、他の中国AI研究所も次々と参加していくと予想している。これにより、中国のハードウェアメーカーは「CUDAの壁」に間接的に対抗できるし、AMDのような西側ハードの潜在能力も引き出せる。
ただし、中国の多くのAIハードウェアはすでにCUDA互換やトランスレータ層を備えている例も多い。例えば、摩尔线程(Moore Thread)、沐曦(Muxi)、壁仞(Biren)、天数智芯(Tensent)などは、トランスレータ層を通じてCUDA互換性を高めている。理論的には、これらはTileLangを必ずしも必要としない。
大規模強化学習とRSI
DeepSeekがより多くの計算資源、つまり選択肢の多いハードウェアを獲得し、モデルの計算資源需要が低下すれば、より野心的な訓練プロジェクト、特に強化学習後の訓練を推進できる。
強化学習は大量の軌跡(トラック)を生成する必要があり、数兆トークンの生成が求められる。この過程は非常に高コストになる。さらに、コンテキスト長100万のモデルを訓練するには、同じ長さの軌跡を生成しなければならない。超長軌跡での訓練こそ、長周期タスクを真にサポートできる。
また、ハードウェア選択肢が増えれば、DeepSeekが呼び出せるハードウェア資源も増え、これが自動化研究、すなわちRSIを推進する。RSIはAI自身が設計・実行する実験だ。多くの試行錯誤を伴い、コストも急増するが、探索空間の完全な理解には不可欠だ。AGI、さらにはASIに向かう前に、DeepSeekはRSI能力を備える必要がある。
DeepSeekが今日やっていることは、明日、業界全体が追随する
DeepSeekのエキスパート混合モデル、MLA、DSAなどの革新は、すでに世界中や中国の他のAI研究所に採用されつつある。
例えば、GLMシリーズの開発者ZAIはMLAとDSAを採用している。Kimi(MoonShot)もMLAを使い、そのアーキテクチャはDeepSeekに基づいていると公言している。逆に、DeepSeekはMuon最適化器も使っており、これはMoonShotのKimiが大規模訓練で最初に採用したものだ。
補足:
MoEはGoogleが2017年に提案したもので、主要著者はNoam Shazeer。DeepSeekの貢献は、大規模適用と独自の技術発明にある。
Muonは、2024年末に研究者Keller Jordanが提案した「MomentUm Orthogonalized by Newton-Schulz」最適化器。Kimi(MoonShot)はこれを大規模訓練に最初に適用した。
では、収益化の問題はどうか?
面白い例としてOpenAIを見てみよう。
OpenAIは、AMDやCerebrasの株式購入に関わるストックオプション/ワラントを低価格で取得し、それらの権利は計算資源のマイルストーンに連動している。これらは非常にコストパフォーマンスの高い取引だ。OpenAIがこれらのハードウェアを使うと約束すれば、長期的な成功の可能性が大きく高まる。
AMDの発表には次のような記述がある:
「契約の一環として、戦略的利益の調整のために、AMDはOpenAIに対し、最大1.6億株の普通株購入権(ワラント)を発行し、特定のマイルストーン達成に応じて段階的に付与する。最初の付与は1ギガワットの展開完了時、次は6ギガワットに拡大するにつれて段階的に付与される。付与条件は、AMDの株価目標や、OpenAIがAMDの大規模展開に必要な技術・商業的マイルストーンを達成することとも連動している。」
私の予想では、DeepSeekも複数の中国のメモリ、ASIC、CPU、ネットワーク技術企業と類似の協定を結び、深く連携して、これらのハードウェアスタックが最先端のAIワークロードに対応できるようにするだろう。
西側諸国や東アジアの同盟国のAI株式の時価総額はすでに10兆ドルを超えている。この「協力による株式リターン獲得」の方式は、DeepSeekにとって中国の巨大産業を育成し、自らのシェアを得るチャンスとなる。最終的には1兆ドルの評価を実現できる。
これにより、DeepSeekは従来のサブスクリプションビジネスを超える収益を得るだけでなく、「AGIを誰もが恩恵を受けられるものにする」という目標も達成できる。梁文锋はJim Simonsの熱心なファンであり、資本の巧者でもある。彼はこのチャンスを見逃さないだろう。
振り返れば、DeepSeekがこれまでに行ったすべてのことを考えると、この説明が最も筋が通っている。
[原文リンク]
律動BlockBeatsの求人情報はこちら
公式コミュニティに参加しよう:
Telegram登録グループ:https://t.me/theblockbeats
Telegram交流グループ:https://t.me/BlockBeats_App
Twitter公式アカウント:https://twitter.com/BlockBeatsAsia