#### 要約* ARFBenchは、実際の運用インシデントから完全に構築された最初のAIベンチマークです。* GPT-5は62.7%の精度で既存のAIモデルをリードしていますが、ドメインの専門家の72.7%には及びません。* 理論的なモデル-専門家オラクル—AIと人間の判断を組み合わせたもの—は87.2%の精度に達し、協働AI-humanチームが達成できる最高水準を示しています。AI企業は引き続き、自律的なサイト信頼性エンジニアエージェント—人間の代わりに運用インシデントを調査するAI—を提案しています。Datadogは実際の障害に対してこのベンチマークを実行し、最良のAIモデルでも彼らが置き換えるべきエンジニアに勝てていません。このベンチマークはARFBench(異常推論フレームワークベンチマーク)で、Datadogとカーネギーメロン大学の共同プロジェクトです。63の実際の運用インシデントから構築され、エンジニア自身のSlackスレッドから抽出されたもので、ライブ緊急時に収集されたものです—142の監視メトリクスと538万のデータポイントをカバーする750の選択式質問、すべて手作業で検証済み。合成データや教科書のシナリオはありません。「毎年数兆ドルがシステム障害によって失われている」と研究者たちは書いています。このベンチマークは、AIが実際にそれを変えるのに役立つかどうかをテストしています。「インシデント対応において質問駆動型分析の中心的役割にもかかわらず、現代の基盤モデルがエンジニアが実務で尋ねるような時系列の質問に確実に答えられるかどうかは依然として不明です」と論文は述べています。<span style="display:inline-block;width:0px;overflow:hidden;line-height:0" data-mce-type="bookmark" class="mce_SELRES_start"></span>質問は3つの階層に分かれます。Tier I:このチャートに異常はありますか? Tier II:いつ始まりましたか、それはどれくらい深刻ですか、どのタイプですか?最も難しいTier IIIは、クロスメトリック推論を必要とします:このチャートが他のチャートの問題を引き起こしているのですか? ここでAIは崩れます。GPT-5はTier IIIの質問でF1スコア47.5%しかなく、最も一般的なクラスを選ぶことで答えを操作しようとするモデルを罰する指標です。「インシデント対応において質問駆動型分析の中心的役割にもかかわらず、現代の基盤モデルがエンジニアが実務で尋ねるような時系列の質問に確実に答えられるかどうかは依然として不明です」と研究者たちは書いています。各モデルの比較GPT-5は62.7%の精度で全モデルをリード—ランダム推測の24.5%に対して。Gemini 3 Proは58.1%。Claude Opusは54.8%。Claude Sonnetは47.2%。ドメインの専門家は72.7%の精度を記録。非ドメインの専門家—Datadogの時系列研究者で広範な可観測性の経験がない者たち—も69.7%に達しました。どのAIモデルも人間の基準を超えませんでした。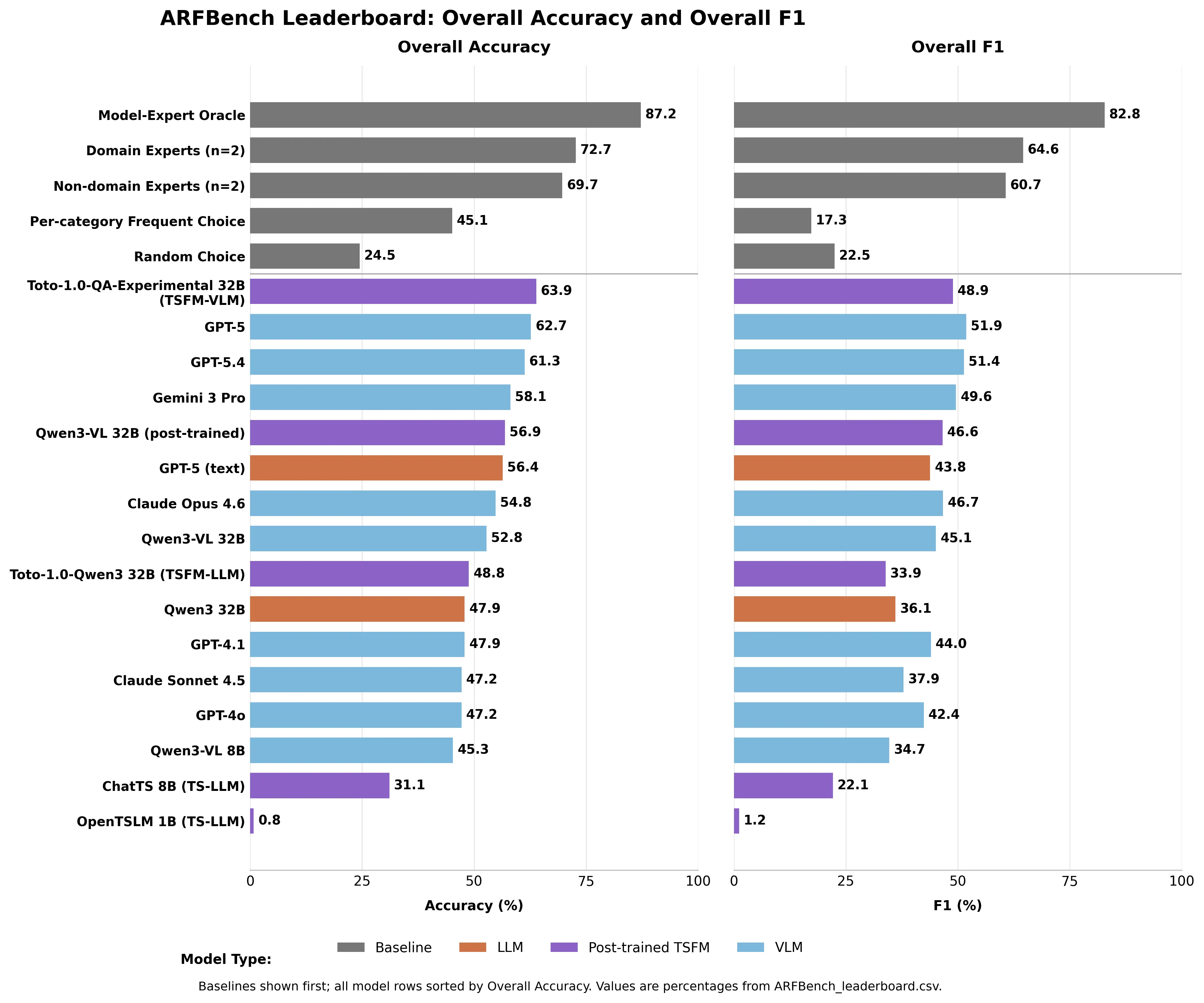画像はARFBenchリーダーボードのCSVに基づいてDecryptが作成したものです。実際に全リーダーボードを制したモデルは、Datadogのハイブリッドモデル:Toto—彼らの内部の時系列予測モデル—とQwen3-VL 32Bの組み合わせです。Toto-1.0-QA-Experimentalは63.9%の精度を記録し、GPT-5をわずかに上回り、そのパラメータの一部だけを使用しています。特に異常識別においては、他のすべてのモデルより少なくとも8.8ポイント高いF1スコアを出しています。観測性データで訓練された目的特化型のドメインモデルが、この特定のタスクで最先端の汎用システムを上回るのは予想通りです。これがポイントです。最も価値のある発見は、どのモデルが最も高いスコアを獲得したかではありません。「我々は、主要なモデルと人間の専門家の間で著しく異なる誤差プロファイルを観察しており、それらの強みは補完的であることを示唆しています」と研究者たちは書いています。モデルは幻覚を見たり、メタデータを見逃したり、ドメインのコンテキストを失ったりします。人間は正確なタイムスタンプを誤読し、複雑な指示に失敗することもあります。誤りの重複はほとんどありません。理論的な「モデル-専門家オラクル」—常にAIと人間の間で正しい答えを選ぶ完璧な判定者—をモデル化すると、87.2%の精度と82.8%のF1を得られます。これはどちらか一方だけよりもはるかに高いです。それは製品ではありません。実際の緊急事態から構築された記録された目標であり、キュレーションされたデータセットではなく、人間とAIの協働がどれだけ向上できるかを正確に定量化しています。リーダーボードはHugging Faceで公開中です。GPT-5は62.7%。最高水準は87.2%です。
AIはまだオンコールエンジニアに勝てない:その理由はこちら
要約
AI企業は引き続き、自律的なサイト信頼性エンジニアエージェント—人間の代わりに運用インシデントを調査するAI—を提案しています。Datadogは実際の障害に対してこのベンチマークを実行し、最良のAIモデルでも彼らが置き換えるべきエンジニアに勝てていません。 このベンチマークはARFBench(異常推論フレームワークベンチマーク)で、Datadogとカーネギーメロン大学の共同プロジェクトです。63の実際の運用インシデントから構築され、エンジニア自身のSlackスレッドから抽出されたもので、ライブ緊急時に収集されたものです—142の監視メトリクスと538万のデータポイントをカバーする750の選択式質問、すべて手作業で検証済み。合成データや教科書のシナリオはありません。 「毎年数兆ドルがシステム障害によって失われている」と研究者たちは書いています。このベンチマークは、AIが実際にそれを変えるのに役立つかどうかをテストしています。
「インシデント対応において質問駆動型分析の中心的役割にもかかわらず、現代の基盤モデルがエンジニアが実務で尋ねるような時系列の質問に確実に答えられるかどうかは依然として不明です」と論文は述べています。 質問は3つの階層に分かれます。Tier I:このチャートに異常はありますか? Tier II:いつ始まりましたか、それはどれくらい深刻ですか、どのタイプですか? 最も難しいTier IIIは、クロスメトリック推論を必要とします:このチャートが他のチャートの問題を引き起こしているのですか? ここでAIは崩れます。GPT-5はTier IIIの質問でF1スコア47.5%しかなく、最も一般的なクラスを選ぶことで答えを操作しようとするモデルを罰する指標です。
「インシデント対応において質問駆動型分析の中心的役割にもかかわらず、現代の基盤モデルがエンジニアが実務で尋ねるような時系列の質問に確実に答えられるかどうかは依然として不明です」と研究者たちは書いています。 各モデルの比較 GPT-5は62.7%の精度で全モデルをリード—ランダム推測の24.5%に対して。Gemini 3 Proは58.1%。Claude Opusは54.8%。Claude Sonnetは47.2%。 ドメインの専門家は72.7%の精度を記録。非ドメインの専門家—Datadogの時系列研究者で広範な可観測性の経験がない者たち—も69.7%に達しました。 どのAIモデルも人間の基準を超えませんでした。
画像はARFBenchリーダーボードのCSVに基づいてDecryptが作成したものです。
実際に全リーダーボードを制したモデルは、Datadogのハイブリッドモデル:Toto—彼らの内部の時系列予測モデル—とQwen3-VL 32Bの組み合わせです。Toto-1.0-QA-Experimentalは63.9%の精度を記録し、GPT-5をわずかに上回り、そのパラメータの一部だけを使用しています。特に異常識別においては、他のすべてのモデルより少なくとも8.8ポイント高いF1スコアを出しています。 観測性データで訓練された目的特化型のドメインモデルが、この特定のタスクで最先端の汎用システムを上回るのは予想通りです。これがポイントです。 最も価値のある発見は、どのモデルが最も高いスコアを獲得したかではありません。 「我々は、主要なモデルと人間の専門家の間で著しく異なる誤差プロファイルを観察しており、それらの強みは補完的であることを示唆しています」と研究者たちは書いています。モデルは幻覚を見たり、メタデータを見逃したり、ドメインのコンテキストを失ったりします。人間は正確なタイムスタンプを誤読し、複雑な指示に失敗することもあります。誤りの重複はほとんどありません。
理論的な「モデル-専門家オラクル」—常にAIと人間の間で正しい答えを選ぶ完璧な判定者—をモデル化すると、87.2%の精度と82.8%のF1を得られます。これはどちらか一方だけよりもはるかに高いです。 それは製品ではありません。実際の緊急事態から構築された記録された目標であり、キュレーションされたデータセットではなく、人間とAIの協働がどれだけ向上できるかを正確に定量化しています。リーダーボードはHugging Faceで公開中です。GPT-5は62.7%。最高水準は87.2%です。