ハーバードの研究によると AI の緊急診断の正確率は 67.1% で、内科医を上回る。しかし、緊急医師はこれをメディアの過剰な誇張だと反論している。なぜなら、この研究は実際の緊急医師との比較が欠如しており、AIは文字情報のみを処理できるに過ぎず、現時点では人間の医師の独立した医療行為を代替できないからだ。ハーバード研究:AIは救急室での診断において人間医師を超える---------------------4月30日、『サイエンス』(Science)誌に掲載された研究によると、AIが行った救急診断の結果は、二人の人間医師よりも正確であり、業界やメディアの注目を集めたが、これだけでAIが本当に医師になれると判断するのは早計だ。ハーバード医科大学とベス・イェシェバ・デセラ医療センターの医師およびコンピューター科学者からなる研究チームは、**ベス・イェシェバ救急室の76人の実患者に焦点を当てた実験で、研究者たちはOpenAIのo1とGPT-4oモデルによる診断結果を、「内科主治医」二人の診断と比較した。**研究結果は、救急初期トリアージ、救急医師の初期評価、一般病棟または集中治療室への転院許可の三つの主要診断段階において、GPT-o1モデルの正確性がGPT-4oや人間医師を上回ったことを示している。**情報が最も少なく、正確な判断が求められる救急初期トリアージ段階で、AIモデルの優位性が最も顕著だった。GPT-o1モデルは67.1%の症例で完全に正確または非常に近い診断を提供し、一方、二人の人間医師の正確率はそれぞれ55.3%と50.0%だった。**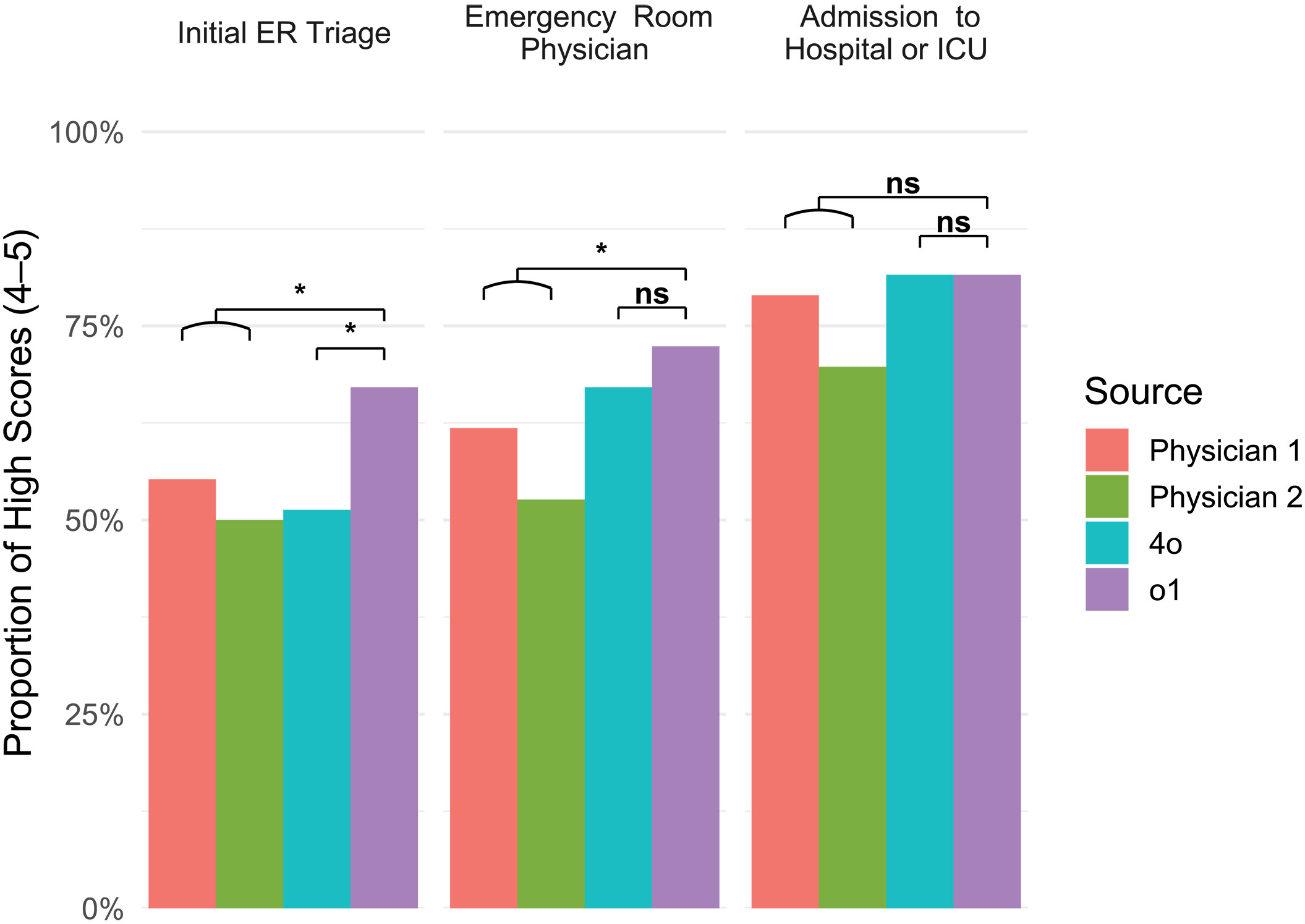図源:ハーバード研究ハーバード研究:GPT-o1-preview、GPT-4と医師の臨床診断推論能力比較AIは文字情報のみ処理可能、実臨床は非文字情報に満ちている-------------------研究報告はまた、現行の生成型AIチャットモデルは、非文字入力の推論能力において依然として大きな制約があることを指摘している。これは、現在の研究がAIモデルが純粋な文字情報を受け取る際のパフォーマンスのみを評価しているためだ。**実際の臨床医療環境は、聴覚的な痛みの程度や、医療画像の読影など、多種多様な非文字情報に満ちている。**AIは独立した医療行為を行えない---------AIは優れた診断能力を示しているものの、研究はこれがAIモデルによる独立した医療行為を意味しないことも強調している。ハーバード医科大学の臨床研究員、ピーター・ブルドゥールは説明する。**「AIモデルは一次診断において正しい判断を下すこともあるが、不必要な検査を提案することもあり、それは患者に追加の健康リスクをもたらす可能性がある。したがって、医療のパフォーマンスや安全性を評価する際には、最終的な判断を下すのは人間の医師である必要がある。」**ハーバード研究は緊急医師の実臨床比較を欠いている---------------救急医師のクリステン・パンタガニは、ハーバードの研究結果は面白いが、過剰な誇張を招く見出しを生んでいると指摘した。彼女は述べる。**「ハーバードの研究はAIと内科主治医を比較したものであり、実際にその科に従事する救急医師との比較データは欠如している。** **『もし大規模言語モデル(LLM)が神経外科医を破って外科医試験に合格したとしても、それは驚きではないが、その事実が実質的に役立つわけではない。』**」彼女は、救急医の最優先目標は、患者が致命的な疾患を抱えているかどうかを確認することであり、最終診断の推測を最優先事項としないと述べている。**ハーバードの研究も、AI診断には正式な責任追及の枠組みが未整備であり、患者は依然として人間の医師の導きと、難しい治療選択における支援を必要としていると警告している。**研究チームは、医療界が真の患者ケア環境で、厳格な前向き臨床試験を通じてこれらAI技術を評価し、どのように安全に臨床に導入し人間医師を補助できるかを理解すべきだと呼びかけている。関連記事: 生成型AIはなぜ医療・法律分野で進展が遅いのか?Replit創業者:検証性が鍵
ハーバー研究「AI緊急診断は人間の医師より正確」過度に宣伝されている、医師:実際の比較不足
ハーバードの研究によると AI の緊急診断の正確率は 67.1% で、内科医を上回る。しかし、緊急医師はこれをメディアの過剰な誇張だと反論している。なぜなら、この研究は実際の緊急医師との比較が欠如しており、AIは文字情報のみを処理できるに過ぎず、現時点では人間の医師の独立した医療行為を代替できないからだ。
ハーバード研究:AIは救急室での診断において人間医師を超える
4月30日、『サイエンス』(Science)誌に掲載された研究によると、AIが行った救急診断の結果は、二人の人間医師よりも正確であり、業界やメディアの注目を集めたが、これだけでAIが本当に医師になれると判断するのは早計だ。
ハーバード医科大学とベス・イェシェバ・デセラ医療センターの医師およびコンピューター科学者からなる研究チームは、ベス・イェシェバ救急室の76人の実患者に焦点を当てた実験で、研究者たちはOpenAIのo1とGPT-4oモデルによる診断結果を、「内科主治医」二人の診断と比較した。
研究結果は、救急初期トリアージ、救急医師の初期評価、一般病棟または集中治療室への転院許可の三つの主要診断段階において、GPT-o1モデルの正確性がGPT-4oや人間医師を上回ったことを示している。
情報が最も少なく、正確な判断が求められる救急初期トリアージ段階で、AIモデルの優位性が最も顕著だった。GPT-o1モデルは67.1%の症例で完全に正確または非常に近い診断を提供し、一方、二人の人間医師の正確率はそれぞれ55.3%と50.0%だった。
図源:ハーバード研究ハーバード研究:GPT-o1-preview、GPT-4と医師の臨床診断推論能力比較
AIは文字情報のみ処理可能、実臨床は非文字情報に満ちている
研究報告はまた、現行の生成型AIチャットモデルは、非文字入力の推論能力において依然として大きな制約があることを指摘している。
これは、現在の研究がAIモデルが純粋な文字情報を受け取る際のパフォーマンスのみを評価しているためだ。実際の臨床医療環境は、聴覚的な痛みの程度や、医療画像の読影など、多種多様な非文字情報に満ちている。
AIは独立した医療行為を行えない
AIは優れた診断能力を示しているものの、研究はこれがAIモデルによる独立した医療行為を意味しないことも強調している。
ハーバード医科大学の臨床研究員、ピーター・ブルドゥールは説明する。「AIモデルは一次診断において正しい判断を下すこともあるが、不必要な検査を提案することもあり、それは患者に追加の健康リスクをもたらす可能性がある。したがって、医療のパフォーマンスや安全性を評価する際には、最終的な判断を下すのは人間の医師である必要がある。」
ハーバード研究は緊急医師の実臨床比較を欠いている
救急医師のクリステン・パンタガニは、ハーバードの研究結果は面白いが、過剰な誇張を招く見出しを生んでいると指摘した。
彼女は述べる。「ハーバードの研究はAIと内科主治医を比較したものであり、実際にその科に従事する救急医師との比較データは欠如している。
『もし大規模言語モデル(LLM)が神経外科医を破って外科医試験に合格したとしても、それは驚きではないが、その事実が実質的に役立つわけではない。』」
彼女は、救急医の最優先目標は、患者が致命的な疾患を抱えているかどうかを確認することであり、最終診断の推測を最優先事項としないと述べている。
ハーバードの研究も、AI診断には正式な責任追及の枠組みが未整備であり、患者は依然として人間の医師の導きと、難しい治療選択における支援を必要としていると警告している。
研究チームは、医療界が真の患者ケア環境で、厳格な前向き臨床試験を通じてこれらAI技術を評価し、どのように安全に臨床に導入し人間医師を補助できるかを理解すべきだと呼びかけている。
関連記事:
生成型AIはなぜ医療・法律分野で進展が遅いのか?Replit創業者:検証性が鍵