> 原文タイトル:Import AI 455: AIシステムは自ら構築を始めようとしている。 > 原文著者:ジャック・クラーク、Anthropic共同創設者 > 原文翻訳:杨文、陈陈、机器之心  この見解は空想から出たものではない。彼は公開されている基準をいくつも調査し、AIがAI研究・開発関連のタスクで非常に速く進歩していることを発見した。 例えば、CORE-BenchはAIが他者の研究論文を実現できる能力を評価するもので、AI研究において非常に重要な一環だ。 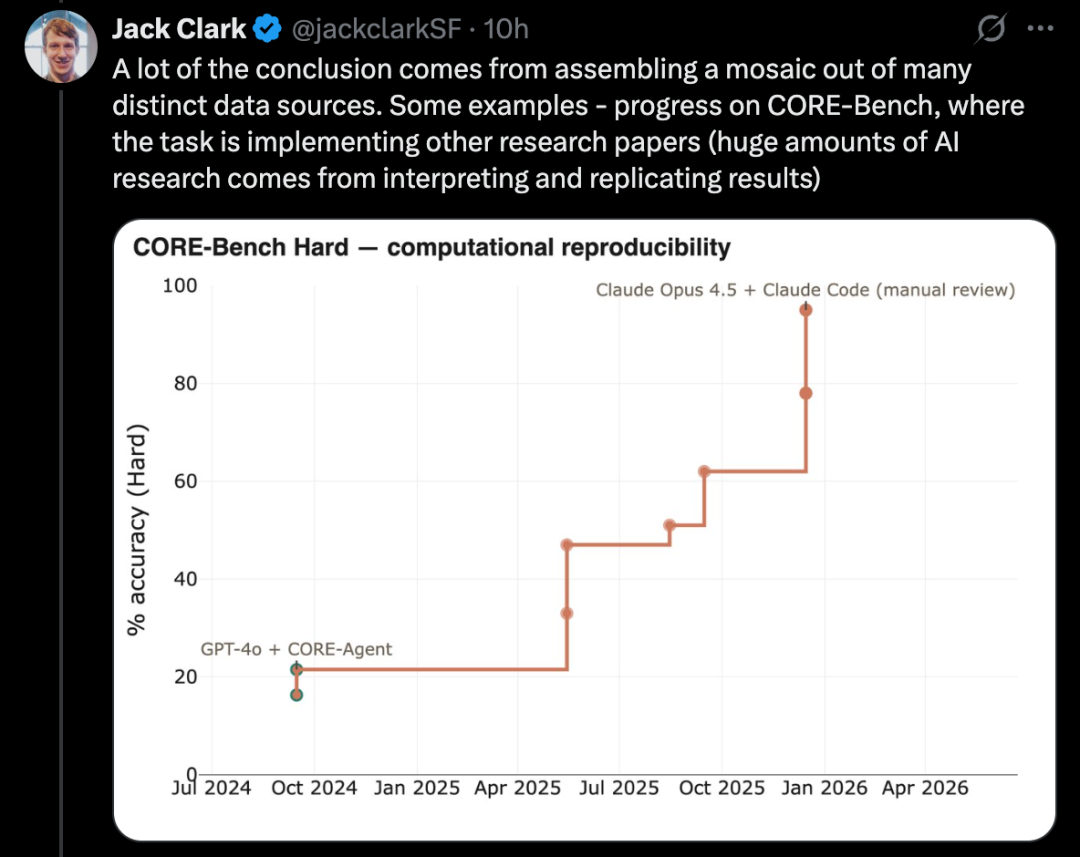 PostTrainBenchは、強力なモデルが弱いオープンソースモデルを自主的に微調整して性能を向上させられるかどうかをテストするもので、これはAI研究・開発の重要なサブセットの一つだ。 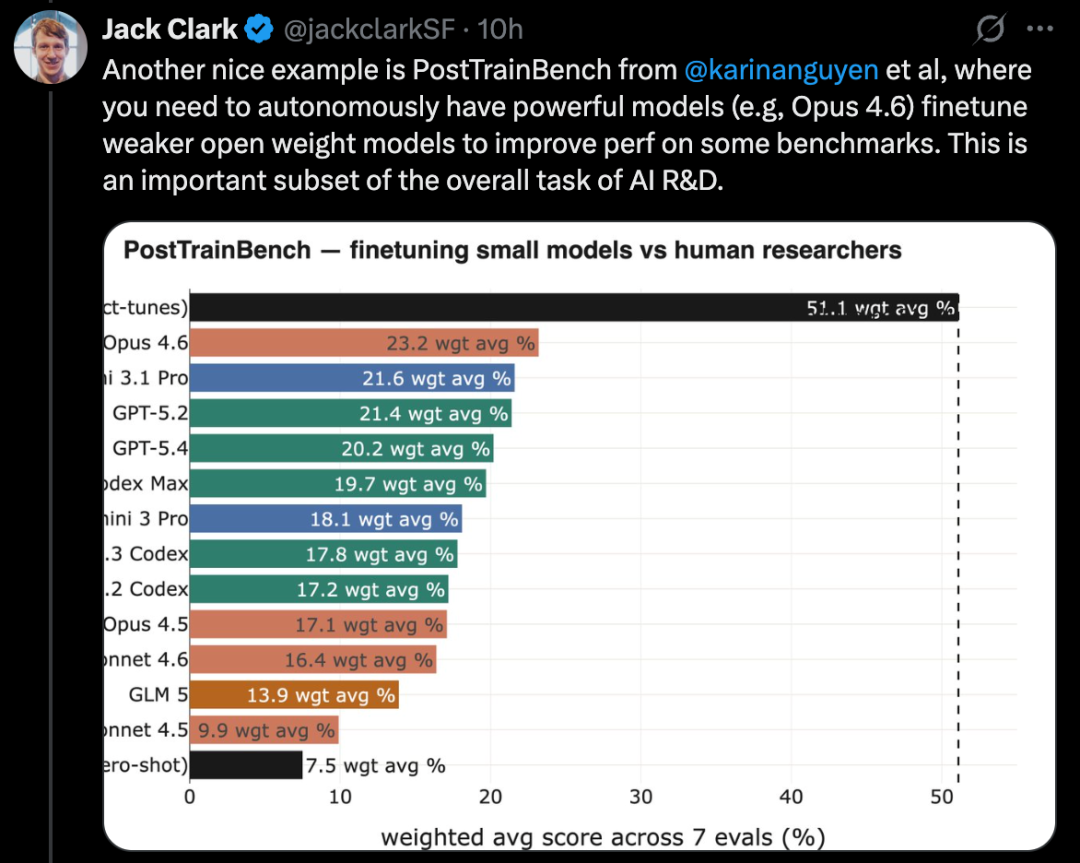 MLE-Benchは実際のKaggleコンペの課題を基にしており、多様な機械学習アプリケーションを構築して特定の問題を解決することを求める。さらに、SWE-Benchのような広く知られるコーディング基準も同様の進歩を示している。 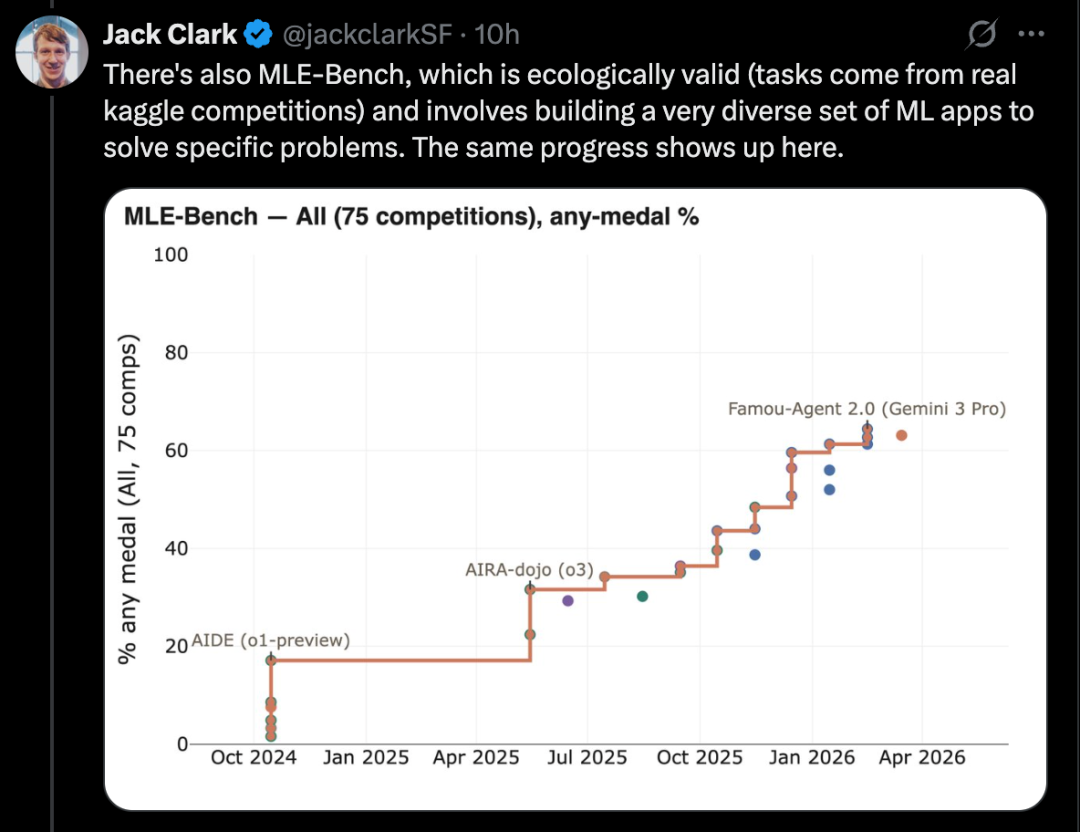 ジャック・クラークはこの現象を「フラクタル」的な右上向きのトレンドと表現し、異なる解像度やスケールでも意味のある進展が観察できると述べている。彼は、AIは段階的にエンドツーエンドの自動化研究開発能力に近づいており、一旦実現すれば、AIは自己の後継システムを自主的に構築し、自己反復のサイクルを開始すると考えている。  この発言はソーシャルメディア上で多くの議論を呼んだ。 一部の人々はこれをASI(人工超知能)やシンギュラリティへの重要な第一歩と見なし、技術発展のペースを根本的に変える可能性があると考えている。  しかし、異なる意見も存在する。 ワシントン大学の計算機科学教授ペドロ・ドミンゴスは、AIシステムはすでに1950年代のLISP言語発明時点で「自己構築」の能力を持っていたと指摘し、真の問題はリターンの増加を得られるかどうかにあり、現時点では明確な証拠はないと述べている。  あるネットユーザーは疑問を呈している。2027年から2028年にかけて確率が一気に30%増加するというのは、AI能力が2027年末頃に突如として大きく進歩することを示唆しているのか?具体的なマイルストーンや出来事が、短期間でAIの自己改良の確率を大きく高めるのか?  また別のネットユーザーは、ジャック・クラークはAnthropicの新任広報責任者であり、これは彼らの新戦略の一部だと述べている:我々は単なる危険予測者ではなく、多くの論文が我々の警告を裏付けている。  クラークはこのテーマについて、Import AI 455号のニュースレターで詳細な長文を執筆した。  それでは、この記事を全文見ていこう。 AIシステムはまもなく自己構築を始める。これは何を意味するのか?===================== クラークは、この文章を書いたのは、公開情報を整理した結果、2028年末までに人間の関与なしにAI研究・開発が出現する可能性がかなり高いと判断せざるを得なかったからだ。おそらく60%以上だ。 **ここでいう「人間の関与なしのAI研究・開発」とは、十分に強力なAIシステムを指す:**それは研究を補助するだけでなく、重要な研究工程を自主的に完了し、さらには次世代のシステムを構築することさえ可能だ。 クラークの見解では、これは明らかに大きな出来事だ。 彼は、これの意味を完全に理解するのは難しいと正直に認めている。 この判断を「不本意なもの」と呼ぶのは、その背後にある影響があまりにも巨大で、把握しきれないと感じているからだ。クラークはまた、社会全体がAIの研究・開発の自動化による深遠な変化を受け入れる準備ができているかどうかも確信していない。 彼は今、人類は特別な時点にいると信じている:AI研究はまもなくエンドツーエンドの自動化に向かう。もしこれが実現すれば、人類はルビコン川を渡り、ほぼ予測不能な未来へと入ることになる。 クラークは、この文章の目的は、なぜ彼が「完全自動化AI研究の飛躍が起きつつある」と考えるのか、その理由を説明することにあると述べている。 彼はこのトレンドがもたらす可能性のある結果についても議論するが、文章の大部分はこの判断を支える証拠に集中している。より深い影響については、今年の大部分をかけて引き続き調査を続ける予定だ。 時間軸から見ると、クラークはこの事象が2026年に本格的に起こるとは考えていない。しかし、今後1~2年の間に、モデルが自己の後継者をエンドツーエンドで訓練する例が見られる可能性は高い。少なくとも非最先端のモデルレベルでは、概念実証が出現する可能性は十分にある。一方、最先端モデルはコストが非常に高く、多くの研究者の高強度な作業に依存しているため、難易度はさらに高い。 クラークの判断は、主に公開情報に基づいている:arXiv、bioRxiv、NBERの論文や、最先端AI企業が実世界に展開している製品だ。これらの情報から、彼は次の結論を導き出している:AIシステムの開発に必要な工程、特にエンジニアリングの部分は、すでに自動化の範囲に入っている。 もしスケーリングのトレンドが続けば、私たちはこう備えるべきだ:モデルは創造性を持ち、自動的に既知の方法を改良するだけでなく、新たな研究方向や独創的なアイデアを提案し、人間の研究者に取って代わる可能性がある。 能力の奇点:時間とともに変化する能力============= AIシステムはソフトウェアによって実現されており、そのソフトウェアはコードで構成されている。 AIシステムはすでにコード生成の方法を根本的に変えている。背後には二つの関連するトレンドがある。一つは、AIシステムがますます複雑な実世界のコードを書くのが得意になっていること。もう一つは、ほとんど人間の監督を必要とせず、多くの線形的なコーディングタスクを連結して完了できるようになっていることだ。例えば、まずコードを書き、その後テストを行う、といった流れだ。 このトレンドを象徴する代表例は、SWE-BenchとMETRの時間軸グラフだ。 実世界のソフトウェアエンジニアリング問題の解決------------- SWE-Benchは、AIが実際のGitHubのissueを解決できる能力を評価するための広く使われているプログラミングテストだ。 2023年末にリリースされた当時、最も良い成績を出したモデルはClaude 2で、成功率は約2%だった。一方、Claude Mythos Previewは93.9%に達し、ほぼこのベンチマークを満たしている。 もちろん、すべてのベンチマークにはノイズが伴うため、ある程度高いスコアに達した段階では、もはや方法自体の限界ではなく、ベンチマーク自体の制約に直面している可能性が高い。例えば、ImageNetの検証セットでは、約6%のラベルが誤りまたは曖昧だ。 SWE-Benchは、汎用的なプログラミング能力やAIがソフトウェアエンジニアリングに与える影響を測る信頼できる指標と見なせる。クラークは、最先端のAI研究所やシリコンバレーの多くの人々が、すでにAIシステムを使ってコードを書き、テストやコードレビューも行っていると述べている。 言い換えれば、AIシステムはすでに十分に強力で、AI研究・開発の重要な部分を自動化し、研究者やエンジニアの作業を大きく加速させている。 長期タスク遂行能力の評価----------------- METRは、AIがどれだけ複雑なタスクを完遂できるかを測るグラフを作成した。ここでの「複雑さ」とは、熟練した人間がこれらのタスクを完了するのに必要な時間(おおよそ何時間か)を基準にしている。 最も重要な指標は、AIが一連のタスクで50%の信頼性を達成したときの、概ねのタスク時間のスケールだ。 **この点での進歩は非常に驚くべきものだ:** · 2022年、GPT-3.5が完遂できるタスクは、人間が約30秒で終えるものに相当した。 · 2023年、GPT-4はこれを4分に伸ばした。 · 2024年、o1は40分に到達。 · 2025年、GPT-5.2 Highは約6時間に。 · 2026年には、Opus 4.6がさらに12時間にまで引き上げている。 AI研究・予測に長く関わるAjeya Cotraは、2026年末までにAIシステムが人間が100時間必要とするタスクを完遂できると予測しており、これは妥当な見積もりだ。 AIシステムの自律的な作業時間は著しく伸びており、エージェント的コーディングツールの爆発的普及とも深く関係している。エージェント的コーディングツールとは、人間の作業を代行できるAIシステムの製品化を意味し、長期間にわたり比較的自律的にタスクを推進できる。 これもまた、AI研究・開発そのものに再び焦点を当てている。多くのAI研究者の日常作業を観察すると、多くのタスクは数時間単位で分解できることがわかる。例えば、データのクリーニング、データの読み込み、実験の立ち上げなどだ。 こうした作業は、今や現代のAIシステムのカバー範囲内に入っている。 AIシステムの熟練度が高まるほど、人間からの独立性が増し、AI研究・開発の一部を自動化できる可能性が高まる。 **タスク委任の主要な要素は二つ:** · 一つは、委任先の能力に対する信頼性; · 二つは、相手があなたの継続的な監督なしに、あなたの意図通りに仕事を完遂できると信じること。 AIのプログラミング能力を観察すると、AIシステムはますます熟練し、再調整なしに長時間自律的に作業できるようになっていることがわかる。 これは、エンジニアや研究者がますます大きな仕事をAIに委ねている現状とも一致している。AI能力の向上に伴い、委任される仕事もより複雑で重要になっている。 AIはAI研究・開発に必要なコアな科学スキルを習得しつつある======================= 現代の科学研究の進め方を考えると、その多くは、まず方向性を決め、どのような経験的情報を得たいかを明確にし、その後実験を設計・実行して情報を生成し、最後に結果の妥当性を検証するという流れだ。 AIのプログラミング能力が向上し、大規模言語モデルの世界モデル化能力も高まる中、今や人類の研究者を支援し、一部の工程を自動化できるツール群が登場している。 **ここで、AIがいくつかの重要な科学スキルでどの程度進歩しているかを観察できる。これらの能力は、AI研究にとって不可欠な要素でもある:** · 一つは、研究結果の再現性の確保; · 二つは、機械学習技術と他の方法を連結し、技術的課題を解決すること; · 三つは、AIシステム自身の最適化。 科学論文の実現と実験の再現---------------- AI研究の核心作業の一つは、科学論文を読み、その結果を再現することだ。この点で、AIはすでにいくつかのベンチマークで顕著な進歩を遂げている。 良い例は、CORE-Bench、すなわち「計算再現性エージェントベンチマーク」だ。 このベンチマークは、AIシステムが論文とそのコードリポジトリを与えられた場合に、論文の結果を再現できるかを評価するものだ。具体的には、エージェントは関連ライブラリやソフトウェアパッケージ、依存関係をインストールし、コードを実行し、出力結果を検索し、タスクの質問に答える必要がある。 CORE-Benchは2024年9月に提案された。当時、最も良い成績を出したシステムは、CORE-Agentのスキャフォールド上で動作するGPT-4oモデルだった。最も難しいタスク群では、得点は約21.5%だった。 2025年12月には、CORE-Benchの一人の著者が、このベンチマークはすでに解決済みだと発表した。Opus 4.5モデルは95.5%のスコアを達成している。 完全な機械学習システムの構築とKaggleコンペの解決-------------------------- MLE-Benchは、OpenAIが構築したベンチマークで、AIシステムがオフライン環境でKaggleコンペに参加できる能力を評価するものだ。 75種類の異なるKaggleコンペをカバーし、自然言語処理、コンピュータビジョン、信号処理など多岐にわたる分野を含む。 2024年10月にリリースされ、最も良い成績を出したシステムは、エージェントスキャフォールド上のo1モデルで、スコアは16.9%だった。 2026年2月時点で、最も良いシステムは、検索能力を持つエージェントハーネス上のGemini 3で、スコアは64.4%に達している。 カーネル最適化--------- AI開発において、より難しいタスクの一つはカーネルの最適化だ。カーネル最適化とは、行列乗算などの特定演算をより効率的にハードウェアにマッピングするための底層コードの作成と改良を指す。 カーネル最適化がAI開発の核心となる理由は、訓練と推論の効率を左右するからだ。一つは、AIシステムの開発時にどれだけ計算資源を有効に使えるかに影響し、もう一つは、モデル訓練後にその計算資源を推論能力にどれだけ効率的に変換できるかに関わる。 近年、AIを用いたカーネル設計は、面白い小さな分野から激しい競争の研究領域へと変貌し、複数のベンチマークも登場している。ただし、これらのベンチマークはまだ広く普及していないため、長期的な進展を明確にモデル化するのは難しい。一方、進行中の研究からこの分野の進み具合を感じ取ることはできる。 **関連研究例:** · DeepSeekモデルを用いたGPUカーネルの改良試み; · PyTorchモジュールを自動的にCUDAコードに変換; · MetaはLLMを用いて最適化済みのTritonカーネルを自動生成し、自社インフラに展開; · そして、Cuda Agentのようなオープンソースの微調整済み重みモデルも設計されている。 **補足:**カーネル設計には、結果の検証が容易であることや報酬信号が明確であるといった、AI駆動の研究開発に適した特性が備わっている。 PostTrainBenchを用いた言語モデルの微調整======================== この種のテストのより難しいバージョンがPostTrainBenchだ。これは、異なる最先端モデルが、小さなオープンソース重みモデルを引き継ぎ、微調整によって特定のベンチマークでの性能を向上できるかを評価する。 **このベンチマークの長所は、非常に強力な人間の基準が存在することだ:**それは、既存の指示調整済み小型モデルだ。これらは、最先端の研究所の優秀な研究者やエンジニアによって開発・洗練され、実世界に展開されているものだ。したがって、超えるのは非常に難しい人間の基準となっている。 2026年3月時点で、AIシステムはモデルの後訓練を行い、人間の訓練結果の約半分の性能向上を得られるようになった。 **具体的な評価スコアは、複数の後訓練済み大規模言語モデル(Qwen 3 1.7B、Qwen 3 4B、SmolLM3-3B、Gemma 3 4Bなど)と、AIME 2025、Arena Hard、BFCL、GPQA Main、GSM8K、HealthBench、HumanEvalなどの複数ベンチマークの加重平均によるものだ。** 各評価では、CLIエージェントに特定のベンチマークでの特定モデルの性能向上を求める。 **2026年4月時点で、最高得点のAIシステムは約25%~28%に達し、Opus 4.6やGPT 5.4を含む。人間のスコアは51%だ。** これはかなり意味のある結果だ。 言語モデルの訓練最適化-------- 過去一年、Anthropicは自社システムのLLM訓練タスクにおけるパフォーマンスを報告してきた。このタスクは、CPUのみを用いた小型言語モデルの訓練を最適化し、できるだけ高速に動作させることを目的としている。 **評価方法は:**未修正の初期コードと比較して、モデルが実現した平均加速倍率。 **この結果は非常に顕著だ:** · 2025年5月、Claude Opus 4は平均2.9倍の高速化を実現;· 2025年11月、Opus 4.5は16.5倍に向上;· 2026年2月、Opus 4.6は30倍に到達;· 2026年4月、Claude Mythos Previewは52倍に達した。 これらの数字の意味を理解するために、参考値を示すと、人間の研究者はこのタスクに通常4~8時間を費やし、4倍の高速化を達成する。 メタスキル:マネジメント====== AIシステムは、他のAIシステムを管理する方法も学びつつある。 これは、Claude CodeやOpenCodeのような広く展開されている製品で既に見られる。これらの製品では、メインのエージェントが複数のサブエージェントを監督している。 これにより、AIシステムはより大規模なプロジェクトを処理できるようになる。複数のエージェントが異なる専門性を持ち並行して作業し、それらを一つのAI管理者が調整する仕組みだ。管理者自体もAIシステムである。 AI研究は相対論的な発見か、それともレゴブロックの組み立てか?===================== **重要な問いは:AIは新しいアイデアを発明し、自身を改善できるのか?それとも、研究の中であまり華やかでない、しかし一つ一つ積み上げる作業を担うのに適しているのか?** この問いは、AIがAI研究そのものをエンドツーエンドで自動化できる程度に関わるため、非常に重要だ。 著者の見解は、現状のAIは本当に革新的な新思想を提案できていないというものだ。ただし、自動化を実現するために、それが必須条件ではないとも考えている。 AIの進歩は、多くの場合、より大きな実験と、データや計算資源といった入力の増加に依存している。 時折、人間がパラダイムシフトをもたらすアイデアを提案し、資源効率を大きく向上させることもある。Transformerアーキテクチャや、Mixture-of-Expertsモデルもその例だ。 しかし、多くの場合、AIの進展はより素朴な方法で進む。人間は、良好な性能を示すシステムの一部分を拡大し、例えば訓練データや計算資源を増やし、その結果問題点を見つけて修正し、再びスケールアップを行う。 この過程で、洞察を必要とする部分は少なく、多くは堅実な基礎工事の積み重ねだ。 また、多くのAI研究は、既存の実験のバリエーションを実行し、パラメータ設定の違いが結果にどう影響するかを探索するものだ。研究の直感は、最も有望なパラメータを選ぶのに役立つが、それも自動化できる。例えば、神経アーキテクチャ探索の初期段階は、その一例だ。 エジソンは言った:「天才は1%の閃きと99%の汗だ」。この言葉は、過去150年経った今もなお、非常に的を射ている。 時には、徹底的に分野を変える新発見が現れることもあるが、多くの場合、分野の進歩は、人間がシステムの改良や調整を地道に続ける中で少しずつ進む。 前述の公開データは、AIがすでに多くの必要な苦労作業を高い精度でこなせることを示している。 同時に、より大きなトレンドも存在する。基礎的な能力、例えばプログラミング能力と、拡大し続けるタスク時間のスパンが結びつきつつある。これにより、AIはますます多くのタスクを連結し、複雑な作業列を形成できる。 したがって、AIは現状、創造性に欠けると見なされることもあるが、それでも自己の進歩を促すことは十分に可能だと考えられる。ただし、全く新しい洞察を生み出す場合に比べると、その速度は遅くなるだろう。 しかし、公開データを継続的に観察すれば、もう一つの興味深い兆候に気づく。AIはもしかすると、何らかの創造性を示し、それが自己の進歩をより驚くべき方法で推進している可能性もある。 科学の最前線を押し上げる========== 現時点で、汎用AIが人類の科学の最前線を推進できる可能性の初期兆候がいくつか見られる。ただし、これまでのところ、その例は計算機科学や数学に限られていることが多く、多くは人間とAIの協働による突破だ。 **それでも、これらのトレンドは引き続き注視に値する:** エルデス問題:数学者のグループとGeminiモデルが協力し、エルデスの数学問題の解答を試みた。約700問を扱い、13問の解答を得た。その中で、1つは興味深いと判断された。 研究者は、「Aletheia」(Gemini 3 Deep Thinkを基盤としたAIシステム)がErdős-1051の解答を出したことは、早期の例と見なしている。これは、AIが自律的に、やや非平凡で、より広範な数学的関心を持つ未解決のErdős問題に取り組んだ例だ。既存の関連研究文献も存在する。 楽観的に解釈すれば、これらの事例は、AIが人間に属していた創造的直感を発展させつつある兆候と見なせる。一方、悲観的には、数学や計算機科学はAIによる発明に特に適した分野であり、これらの例は例外にすぎず、他の科学分野では同じことが起きない可能性もある。 もう一つの例は、AlphaGoの第37手だ。クラークは、AlphaGoの結果から既に10年が経過しており、その後も第37手を超える驚くべき洞察は現れていないと指摘している。これはやや悲観的な兆候とも解釈できる。 AIはすでにAIエンジニアリングの大部分を自動化できる---------------------- **これらの証拠を総合すると、次のような展望が見えてくる:** · AIはほぼすべてのプログラムにコードを書き、これらのシステムは信頼して独立してタスクを完遂できる。これらのタスクは、人間が行えば数十時間の高負荷作業となる。 · AIはAI開発のコアタスク、モデル微調整やカーネル設計も含めて、次第に自動化している。 · AIは他のAIを管理できるようになり、実質的に複合チームを形成している。複数のAIが複雑な問題を分担し、一部はリーダーや批評者、編集者の役割を担い、他はエンジニアとして働く。 · AIは、現状では人間を超えることもある。これは、AIが真の創造性を持つからなのか、それともパターン化された知識を熟知しているからなのかは、今のところ判断が難しい。 クラークは、これらの証拠は、今日のAIがAIエンジニアリングの大部分を自動化し、もしかするとすべての工程をカバーし得ることを非常に説得力を持って示していると考えている。 ただし、AIがAI研究そのものをどの程度自動化できるかは未解明だ。研究の一部は、純粋なエンジニアリングスキルとは異なり、より高次の判断や問題意識、創造性に依存しているからだ。 しかし、明確な兆候はすでに現れている。今日のAIは、AI開発に必要な多くの苦労作業を大きく効率化している。 同時に、より大きなトレンドも存在する。基礎的な能力、例えばプログラミング能力と、拡大し続けるタスク時間のスパンが結びつきつつある。これにより、AIはますます多くのタスクを連結し、複雑な作業列を形成できる。 したがって、AIは現状、創造性に欠けると見なされることもあるが、それでも自己の進歩を促すことは十分に可能だと考えられる。ただし、全く新しい洞察を生み出す場合に比べると、その速度は遅くなるだろう。 しかし、公開データを継続的に観察すれば、もう一つの興味深い兆候に気づく。AIはもしかすると、何らかの創造性を示し、それが自己の進歩をより驚くべき方法で推進している可能性もある。 科学の最前線を押し上げる========== すでにいくつかの非常に初歩的な兆候が見られる。汎用AIは人類の科学の最前線を推進できる能力を持ちつつある。ただし、これまでのところ、その例は計算機科学や数学に限られており、多くは人間とAIの協働による突破だ。 **それでも、これらのトレンドは引き続き注視に値する:** エルデス問題:数学者のグループとGeminiモデルが協力し、エルデスの数学問題の解答を試みた。約700問を扱い、13問の解答を得た。その中で、1つは興味深いと判断された。 研究者は、「Aletheia」(Gemini 3 Deep Thinkを基盤としたAIシステム)がErdős-1051の解答を出したことは、早期の例と見なしている。これは、AIが自律的に、やや非平凡で、より広範な数学的関心を持つ未解決のErdős問題に取り組んだ例だ。既存の関連研究文献も存在する。 楽観的に解釈すれば、これらの事例は、AIが人間に属していた創造的直感を発展させつつある兆候と見なせる。一方、悲観的には、数学や計算機科学はAIによる発明に特に適した分野であり、これらの例は例外にすぎず、他の科学分野では同じことが起きない可能性もある。 もう一つの例は、AlphaGoの第37手だ。クラークは、AlphaGoの結果から既に10年が経過しており、その後も第37手を超える驚くべき洞察は現れていないと指摘している。これはやや悲観的な兆候とも解釈できる。 AIはすでにAIエンジニアリングの大部分を自動化できる---------------------- **これらの証拠を総合すると、次のような展望が見えてくる:** · AIはほぼすべてのプログラムにコードを書き、これらのシステムは信頼して独立してタスクを完遂できる。これらのタスクは、人間が行えば数十時間の高負荷作業となる。 · AIはAI開発のコアタスク、モデル微調整やカーネル設計も含めて、次第に自動化している。 · AIは他のAIを管理できるようになり、実質的に
Anthropic共同創設者の予言:2028年までに、AIの研究開発は人間の関与を必要としなくなる
この見解は空想から出たものではない。彼は公開されている基準をいくつも調査し、AIがAI研究・開発関連のタスクで非常に速く進歩していることを発見した。
例えば、CORE-BenchはAIが他者の研究論文を実現できる能力を評価するもので、AI研究において非常に重要な一環だ。
PostTrainBenchは、強力なモデルが弱いオープンソースモデルを自主的に微調整して性能を向上させられるかどうかをテストするもので、これはAI研究・開発の重要なサブセットの一つだ。
MLE-Benchは実際のKaggleコンペの課題を基にしており、多様な機械学習アプリケーションを構築して特定の問題を解決することを求める。さらに、SWE-Benchのような広く知られるコーディング基準も同様の進歩を示している。
ジャック・クラークはこの現象を「フラクタル」的な右上向きのトレンドと表現し、異なる解像度やスケールでも意味のある進展が観察できると述べている。彼は、AIは段階的にエンドツーエンドの自動化研究開発能力に近づいており、一旦実現すれば、AIは自己の後継システムを自主的に構築し、自己反復のサイクルを開始すると考えている。
この発言はソーシャルメディア上で多くの議論を呼んだ。
一部の人々はこれをASI(人工超知能)やシンギュラリティへの重要な第一歩と見なし、技術発展のペースを根本的に変える可能性があると考えている。
しかし、異なる意見も存在する。
ワシントン大学の計算機科学教授ペドロ・ドミンゴスは、AIシステムはすでに1950年代のLISP言語発明時点で「自己構築」の能力を持っていたと指摘し、真の問題はリターンの増加を得られるかどうかにあり、現時点では明確な証拠はないと述べている。
あるネットユーザーは疑問を呈している。2027年から2028年にかけて確率が一気に30%増加するというのは、AI能力が2027年末頃に突如として大きく進歩することを示唆しているのか?具体的なマイルストーンや出来事が、短期間でAIの自己改良の確率を大きく高めるのか?
また別のネットユーザーは、ジャック・クラークはAnthropicの新任広報責任者であり、これは彼らの新戦略の一部だと述べている:我々は単なる危険予測者ではなく、多くの論文が我々の警告を裏付けている。
クラークはこのテーマについて、Import AI 455号のニュースレターで詳細な長文を執筆した。
それでは、この記事を全文見ていこう。
AIシステムはまもなく自己構築を始める。これは何を意味するのか?
クラークは、この文章を書いたのは、公開情報を整理した結果、2028年末までに人間の関与なしにAI研究・開発が出現する可能性がかなり高いと判断せざるを得なかったからだ。おそらく60%以上だ。
**ここでいう「人間の関与なしのAI研究・開発」とは、十分に強力なAIシステムを指す:**それは研究を補助するだけでなく、重要な研究工程を自主的に完了し、さらには次世代のシステムを構築することさえ可能だ。
クラークの見解では、これは明らかに大きな出来事だ。
彼は、これの意味を完全に理解するのは難しいと正直に認めている。
この判断を「不本意なもの」と呼ぶのは、その背後にある影響があまりにも巨大で、把握しきれないと感じているからだ。クラークはまた、社会全体がAIの研究・開発の自動化による深遠な変化を受け入れる準備ができているかどうかも確信していない。
彼は今、人類は特別な時点にいると信じている:AI研究はまもなくエンドツーエンドの自動化に向かう。もしこれが実現すれば、人類はルビコン川を渡り、ほぼ予測不能な未来へと入ることになる。
クラークは、この文章の目的は、なぜ彼が「完全自動化AI研究の飛躍が起きつつある」と考えるのか、その理由を説明することにあると述べている。
彼はこのトレンドがもたらす可能性のある結果についても議論するが、文章の大部分はこの判断を支える証拠に集中している。より深い影響については、今年の大部分をかけて引き続き調査を続ける予定だ。
時間軸から見ると、クラークはこの事象が2026年に本格的に起こるとは考えていない。しかし、今後1~2年の間に、モデルが自己の後継者をエンドツーエンドで訓練する例が見られる可能性は高い。少なくとも非最先端のモデルレベルでは、概念実証が出現する可能性は十分にある。一方、最先端モデルはコストが非常に高く、多くの研究者の高強度な作業に依存しているため、難易度はさらに高い。
クラークの判断は、主に公開情報に基づいている:arXiv、bioRxiv、NBERの論文や、最先端AI企業が実世界に展開している製品だ。これらの情報から、彼は次の結論を導き出している:AIシステムの開発に必要な工程、特にエンジニアリングの部分は、すでに自動化の範囲に入っている。
もしスケーリングのトレンドが続けば、私たちはこう備えるべきだ:モデルは創造性を持ち、自動的に既知の方法を改良するだけでなく、新たな研究方向や独創的なアイデアを提案し、人間の研究者に取って代わる可能性がある。
能力の奇点:時間とともに変化する能力
AIシステムはソフトウェアによって実現されており、そのソフトウェアはコードで構成されている。
AIシステムはすでにコード生成の方法を根本的に変えている。背後には二つの関連するトレンドがある。一つは、AIシステムがますます複雑な実世界のコードを書くのが得意になっていること。もう一つは、ほとんど人間の監督を必要とせず、多くの線形的なコーディングタスクを連結して完了できるようになっていることだ。例えば、まずコードを書き、その後テストを行う、といった流れだ。
このトレンドを象徴する代表例は、SWE-BenchとMETRの時間軸グラフだ。
実世界のソフトウェアエンジニアリング問題の解決
SWE-Benchは、AIが実際のGitHubのissueを解決できる能力を評価するための広く使われているプログラミングテストだ。
2023年末にリリースされた当時、最も良い成績を出したモデルはClaude 2で、成功率は約2%だった。一方、Claude Mythos Previewは93.9%に達し、ほぼこのベンチマークを満たしている。
もちろん、すべてのベンチマークにはノイズが伴うため、ある程度高いスコアに達した段階では、もはや方法自体の限界ではなく、ベンチマーク自体の制約に直面している可能性が高い。例えば、ImageNetの検証セットでは、約6%のラベルが誤りまたは曖昧だ。
SWE-Benchは、汎用的なプログラミング能力やAIがソフトウェアエンジニアリングに与える影響を測る信頼できる指標と見なせる。クラークは、最先端のAI研究所やシリコンバレーの多くの人々が、すでにAIシステムを使ってコードを書き、テストやコードレビューも行っていると述べている。
言い換えれば、AIシステムはすでに十分に強力で、AI研究・開発の重要な部分を自動化し、研究者やエンジニアの作業を大きく加速させている。
長期タスク遂行能力の評価
METRは、AIがどれだけ複雑なタスクを完遂できるかを測るグラフを作成した。ここでの「複雑さ」とは、熟練した人間がこれらのタスクを完了するのに必要な時間(おおよそ何時間か)を基準にしている。
最も重要な指標は、AIが一連のタスクで50%の信頼性を達成したときの、概ねのタスク時間のスケールだ。
この点での進歩は非常に驚くべきものだ:
· 2022年、GPT-3.5が完遂できるタスクは、人間が約30秒で終えるものに相当した。
· 2023年、GPT-4はこれを4分に伸ばした。
· 2024年、o1は40分に到達。
· 2025年、GPT-5.2 Highは約6時間に。
· 2026年には、Opus 4.6がさらに12時間にまで引き上げている。
AI研究・予測に長く関わるAjeya Cotraは、2026年末までにAIシステムが人間が100時間必要とするタスクを完遂できると予測しており、これは妥当な見積もりだ。
AIシステムの自律的な作業時間は著しく伸びており、エージェント的コーディングツールの爆発的普及とも深く関係している。エージェント的コーディングツールとは、人間の作業を代行できるAIシステムの製品化を意味し、長期間にわたり比較的自律的にタスクを推進できる。
これもまた、AI研究・開発そのものに再び焦点を当てている。多くのAI研究者の日常作業を観察すると、多くのタスクは数時間単位で分解できることがわかる。例えば、データのクリーニング、データの読み込み、実験の立ち上げなどだ。
こうした作業は、今や現代のAIシステムのカバー範囲内に入っている。
AIシステムの熟練度が高まるほど、人間からの独立性が増し、AI研究・開発の一部を自動化できる可能性が高まる。
タスク委任の主要な要素は二つ:
· 一つは、委任先の能力に対する信頼性;
· 二つは、相手があなたの継続的な監督なしに、あなたの意図通りに仕事を完遂できると信じること。
AIのプログラミング能力を観察すると、AIシステムはますます熟練し、再調整なしに長時間自律的に作業できるようになっていることがわかる。
これは、エンジニアや研究者がますます大きな仕事をAIに委ねている現状とも一致している。AI能力の向上に伴い、委任される仕事もより複雑で重要になっている。
AIはAI研究・開発に必要なコアな科学スキルを習得しつつある
現代の科学研究の進め方を考えると、その多くは、まず方向性を決め、どのような経験的情報を得たいかを明確にし、その後実験を設計・実行して情報を生成し、最後に結果の妥当性を検証するという流れだ。
AIのプログラミング能力が向上し、大規模言語モデルの世界モデル化能力も高まる中、今や人類の研究者を支援し、一部の工程を自動化できるツール群が登場している。
ここで、AIがいくつかの重要な科学スキルでどの程度進歩しているかを観察できる。これらの能力は、AI研究にとって不可欠な要素でもある:
· 一つは、研究結果の再現性の確保;
· 二つは、機械学習技術と他の方法を連結し、技術的課題を解決すること;
· 三つは、AIシステム自身の最適化。
科学論文の実現と実験の再現
AI研究の核心作業の一つは、科学論文を読み、その結果を再現することだ。この点で、AIはすでにいくつかのベンチマークで顕著な進歩を遂げている。
良い例は、CORE-Bench、すなわち「計算再現性エージェントベンチマーク」だ。
このベンチマークは、AIシステムが論文とそのコードリポジトリを与えられた場合に、論文の結果を再現できるかを評価するものだ。具体的には、エージェントは関連ライブラリやソフトウェアパッケージ、依存関係をインストールし、コードを実行し、出力結果を検索し、タスクの質問に答える必要がある。
CORE-Benchは2024年9月に提案された。当時、最も良い成績を出したシステムは、CORE-Agentのスキャフォールド上で動作するGPT-4oモデルだった。最も難しいタスク群では、得点は約21.5%だった。
2025年12月には、CORE-Benchの一人の著者が、このベンチマークはすでに解決済みだと発表した。Opus 4.5モデルは95.5%のスコアを達成している。
完全な機械学習システムの構築とKaggleコンペの解決
MLE-Benchは、OpenAIが構築したベンチマークで、AIシステムがオフライン環境でKaggleコンペに参加できる能力を評価するものだ。
75種類の異なるKaggleコンペをカバーし、自然言語処理、コンピュータビジョン、信号処理など多岐にわたる分野を含む。
2024年10月にリリースされ、最も良い成績を出したシステムは、エージェントスキャフォールド上のo1モデルで、スコアは16.9%だった。
2026年2月時点で、最も良いシステムは、検索能力を持つエージェントハーネス上のGemini 3で、スコアは64.4%に達している。
カーネル最適化
AI開発において、より難しいタスクの一つはカーネルの最適化だ。カーネル最適化とは、行列乗算などの特定演算をより効率的にハードウェアにマッピングするための底層コードの作成と改良を指す。
カーネル最適化がAI開発の核心となる理由は、訓練と推論の効率を左右するからだ。一つは、AIシステムの開発時にどれだけ計算資源を有効に使えるかに影響し、もう一つは、モデル訓練後にその計算資源を推論能力にどれだけ効率的に変換できるかに関わる。
近年、AIを用いたカーネル設計は、面白い小さな分野から激しい競争の研究領域へと変貌し、複数のベンチマークも登場している。ただし、これらのベンチマークはまだ広く普及していないため、長期的な進展を明確にモデル化するのは難しい。一方、進行中の研究からこの分野の進み具合を感じ取ることはできる。
関連研究例:
· DeepSeekモデルを用いたGPUカーネルの改良試み;
· PyTorchモジュールを自動的にCUDAコードに変換;
· MetaはLLMを用いて最適化済みのTritonカーネルを自動生成し、自社インフラに展開;
· そして、Cuda Agentのようなオープンソースの微調整済み重みモデルも設計されている。
**補足:**カーネル設計には、結果の検証が容易であることや報酬信号が明確であるといった、AI駆動の研究開発に適した特性が備わっている。
PostTrainBenchを用いた言語モデルの微調整
この種のテストのより難しいバージョンがPostTrainBenchだ。これは、異なる最先端モデルが、小さなオープンソース重みモデルを引き継ぎ、微調整によって特定のベンチマークでの性能を向上できるかを評価する。
**このベンチマークの長所は、非常に強力な人間の基準が存在することだ:**それは、既存の指示調整済み小型モデルだ。これらは、最先端の研究所の優秀な研究者やエンジニアによって開発・洗練され、実世界に展開されているものだ。したがって、超えるのは非常に難しい人間の基準となっている。
2026年3月時点で、AIシステムはモデルの後訓練を行い、人間の訓練結果の約半分の性能向上を得られるようになった。
具体的な評価スコアは、複数の後訓練済み大規模言語モデル(Qwen 3 1.7B、Qwen 3 4B、SmolLM3-3B、Gemma 3 4Bなど)と、AIME 2025、Arena Hard、BFCL、GPQA Main、GSM8K、HealthBench、HumanEvalなどの複数ベンチマークの加重平均によるものだ。
各評価では、CLIエージェントに特定のベンチマークでの特定モデルの性能向上を求める。
2026年4月時点で、最高得点のAIシステムは約25%~28%に達し、Opus 4.6やGPT 5.4を含む。人間のスコアは51%だ。
これはかなり意味のある結果だ。
言語モデルの訓練最適化
過去一年、Anthropicは自社システムのLLM訓練タスクにおけるパフォーマンスを報告してきた。このタスクは、CPUのみを用いた小型言語モデルの訓練を最適化し、できるだけ高速に動作させることを目的としている。
**評価方法は:**未修正の初期コードと比較して、モデルが実現した平均加速倍率。
この結果は非常に顕著だ:
· 2025年5月、Claude Opus 4は平均2.9倍の高速化を実現;
· 2025年11月、Opus 4.5は16.5倍に向上;
· 2026年2月、Opus 4.6は30倍に到達;
· 2026年4月、Claude Mythos Previewは52倍に達した。
これらの数字の意味を理解するために、参考値を示すと、人間の研究者はこのタスクに通常4~8時間を費やし、4倍の高速化を達成する。
メタスキル:マネジメント
AIシステムは、他のAIシステムを管理する方法も学びつつある。
これは、Claude CodeやOpenCodeのような広く展開されている製品で既に見られる。これらの製品では、メインのエージェントが複数のサブエージェントを監督している。
これにより、AIシステムはより大規模なプロジェクトを処理できるようになる。複数のエージェントが異なる専門性を持ち並行して作業し、それらを一つのAI管理者が調整する仕組みだ。管理者自体もAIシステムである。
AI研究は相対論的な発見か、それともレゴブロックの組み立てか?
重要な問いは:AIは新しいアイデアを発明し、自身を改善できるのか?それとも、研究の中であまり華やかでない、しかし一つ一つ積み上げる作業を担うのに適しているのか?
この問いは、AIがAI研究そのものをエンドツーエンドで自動化できる程度に関わるため、非常に重要だ。
著者の見解は、現状のAIは本当に革新的な新思想を提案できていないというものだ。ただし、自動化を実現するために、それが必須条件ではないとも考えている。
AIの進歩は、多くの場合、より大きな実験と、データや計算資源といった入力の増加に依存している。
時折、人間がパラダイムシフトをもたらすアイデアを提案し、資源効率を大きく向上させることもある。Transformerアーキテクチャや、Mixture-of-Expertsモデルもその例だ。
しかし、多くの場合、AIの進展はより素朴な方法で進む。人間は、良好な性能を示すシステムの一部分を拡大し、例えば訓練データや計算資源を増やし、その結果問題点を見つけて修正し、再びスケールアップを行う。
この過程で、洞察を必要とする部分は少なく、多くは堅実な基礎工事の積み重ねだ。
また、多くのAI研究は、既存の実験のバリエーションを実行し、パラメータ設定の違いが結果にどう影響するかを探索するものだ。研究の直感は、最も有望なパラメータを選ぶのに役立つが、それも自動化できる。例えば、神経アーキテクチャ探索の初期段階は、その一例だ。
エジソンは言った:「天才は1%の閃きと99%の汗だ」。この言葉は、過去150年経った今もなお、非常に的を射ている。
時には、徹底的に分野を変える新発見が現れることもあるが、多くの場合、分野の進歩は、人間がシステムの改良や調整を地道に続ける中で少しずつ進む。
前述の公開データは、AIがすでに多くの必要な苦労作業を高い精度でこなせることを示している。
同時に、より大きなトレンドも存在する。基礎的な能力、例えばプログラミング能力と、拡大し続けるタスク時間のスパンが結びつきつつある。これにより、AIはますます多くのタスクを連結し、複雑な作業列を形成できる。
したがって、AIは現状、創造性に欠けると見なされることもあるが、それでも自己の進歩を促すことは十分に可能だと考えられる。ただし、全く新しい洞察を生み出す場合に比べると、その速度は遅くなるだろう。
しかし、公開データを継続的に観察すれば、もう一つの興味深い兆候に気づく。AIはもしかすると、何らかの創造性を示し、それが自己の進歩をより驚くべき方法で推進している可能性もある。
科学の最前線を押し上げる
現時点で、汎用AIが人類の科学の最前線を推進できる可能性の初期兆候がいくつか見られる。ただし、これまでのところ、その例は計算機科学や数学に限られていることが多く、多くは人間とAIの協働による突破だ。
それでも、これらのトレンドは引き続き注視に値する:
エルデス問題:数学者のグループとGeminiモデルが協力し、エルデスの数学問題の解答を試みた。約700問を扱い、13問の解答を得た。その中で、1つは興味深いと判断された。
研究者は、「Aletheia」(Gemini 3 Deep Thinkを基盤としたAIシステム)がErdős-1051の解答を出したことは、早期の例と見なしている。これは、AIが自律的に、やや非平凡で、より広範な数学的関心を持つ未解決のErdős問題に取り組んだ例だ。既存の関連研究文献も存在する。
楽観的に解釈すれば、これらの事例は、AIが人間に属していた創造的直感を発展させつつある兆候と見なせる。一方、悲観的には、数学や計算機科学はAIによる発明に特に適した分野であり、これらの例は例外にすぎず、他の科学分野では同じことが起きない可能性もある。
もう一つの例は、AlphaGoの第37手だ。クラークは、AlphaGoの結果から既に10年が経過しており、その後も第37手を超える驚くべき洞察は現れていないと指摘している。これはやや悲観的な兆候とも解釈できる。
AIはすでにAIエンジニアリングの大部分を自動化できる
これらの証拠を総合すると、次のような展望が見えてくる:
· AIはほぼすべてのプログラムにコードを書き、これらのシステムは信頼して独立してタスクを完遂できる。これらのタスクは、人間が行えば数十時間の高負荷作業となる。
· AIはAI開発のコアタスク、モデル微調整やカーネル設計も含めて、次第に自動化している。
· AIは他のAIを管理できるようになり、実質的に複合チームを形成している。複数のAIが複雑な問題を分担し、一部はリーダーや批評者、編集者の役割を担い、他はエンジニアとして働く。
· AIは、現状では人間を超えることもある。これは、AIが真の創造性を持つからなのか、それともパターン化された知識を熟知しているからなのかは、今のところ判断が難しい。
クラークは、これらの証拠は、今日のAIがAIエンジニアリングの大部分を自動化し、もしかするとすべての工程をカバーし得ることを非常に説得力を持って示していると考えている。
ただし、AIがAI研究そのものをどの程度自動化できるかは未解明だ。研究の一部は、純粋なエンジニアリングスキルとは異なり、より高次の判断や問題意識、創造性に依存しているからだ。
しかし、明確な兆候はすでに現れている。今日のAIは、AI開発に必要な多くの苦労作業を大きく効率化している。
同時に、より大きなトレンドも存在する。基礎的な能力、例えばプログラミング能力と、拡大し続けるタスク時間のスパンが結びつきつつある。これにより、AIはますます多くのタスクを連結し、複雑な作業列を形成できる。
したがって、AIは現状、創造性に欠けると見なされることもあるが、それでも自己の進歩を促すことは十分に可能だと考えられる。ただし、全く新しい洞察を生み出す場合に比べると、その速度は遅くなるだろう。
しかし、公開データを継続的に観察すれば、もう一つの興味深い兆候に気づく。AIはもしかすると、何らかの創造性を示し、それが自己の進歩をより驚くべき方法で推進している可能性もある。
科学の最前線を押し上げる
すでにいくつかの非常に初歩的な兆候が見られる。汎用AIは人類の科学の最前線を推進できる能力を持ちつつある。ただし、これまでのところ、その例は計算機科学や数学に限られており、多くは人間とAIの協働による突破だ。
それでも、これらのトレンドは引き続き注視に値する:
エルデス問題:数学者のグループとGeminiモデルが協力し、エルデスの数学問題の解答を試みた。約700問を扱い、13問の解答を得た。その中で、1つは興味深いと判断された。
研究者は、「Aletheia」(Gemini 3 Deep Thinkを基盤としたAIシステム)がErdős-1051の解答を出したことは、早期の例と見なしている。これは、AIが自律的に、やや非平凡で、より広範な数学的関心を持つ未解決のErdős問題に取り組んだ例だ。既存の関連研究文献も存在する。
楽観的に解釈すれば、これらの事例は、AIが人間に属していた創造的直感を発展させつつある兆候と見なせる。一方、悲観的には、数学や計算機科学はAIによる発明に特に適した分野であり、これらの例は例外にすぎず、他の科学分野では同じことが起きない可能性もある。
もう一つの例は、AlphaGoの第37手だ。クラークは、AlphaGoの結果から既に10年が経過しており、その後も第37手を超える驚くべき洞察は現れていないと指摘している。これはやや悲観的な兆候とも解釈できる。
AIはすでにAIエンジニアリングの大部分を自動化できる
これらの証拠を総合すると、次のような展望が見えてくる:
· AIはほぼすべてのプログラムにコードを書き、これらのシステムは信頼して独立してタスクを完遂できる。これらのタスクは、人間が行えば数十時間の高負荷作業となる。
· AIはAI開発のコアタスク、モデル微調整やカーネル設計も含めて、次第に自動化している。
· AIは他のAIを管理できるようになり、実質的に