# スタンフォード:35%の新しいウェブサイトがAIによって作成される2025年中頃までに、新しいウェブサイトの約35%が完全または部分的に人工知能を使用して作成されたことが判明した。これはスタンフォード大学の研究者による結論である。2022年11月にOpenAIのChatGPTが公開される前は、その割合はゼロだった。数年の間にAI生成コンテンツの割合は、インターネット上の最新の投稿の3分の1以上に増加した。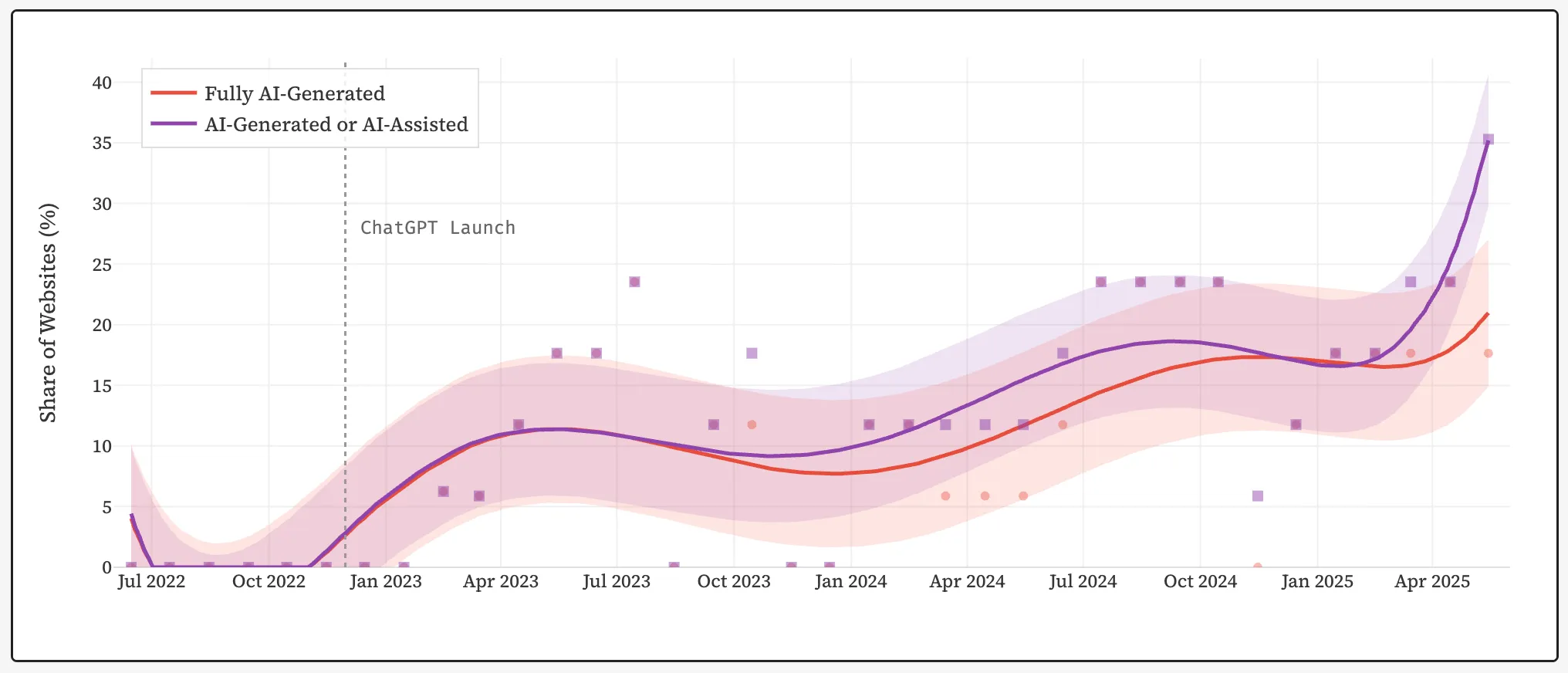AIによって完全に生成されたサイトの割合 (赤色)、およびニューラルネットワークを用いて作成されたサイトの割合 (紫色)。出典:GitHub 研究者たちは、Wayback Machineのアーカイブコピー33か月分をPangram v3検出器で調査し、AIテキストの増加がウェブの構造をどのように再構築しているかを明らかにしようとした。## 主な変化研究者たちは意味的多様性の低下を記録した。ニューラルネットワークによって生成されたページは、人間が書いたテキストよりも33%多く互いに似ている。さまざまなサイトがますますほぼ同じフレーズで同じアイデアを繰り返し伝えるようになっている。著者たちの意見では、これは単なるAIによる大量のコピペの問題ではない。問題はより深く、表現やアイデアの多様性が徐々に狭まっていることにある。大規模言語モデル (LLM) は本質的に最も「平均的な」回答を選び出し、その結果、テンプレート化された談話を再現してしまう。また、公開の感情的トーンも変化した。AIコンテンツは人間のものより107%ポジティブであることが判明した。スタンフォードでは、これがすでに記録されたLLMの媚びへつらい傾向と関連付けられている。学習過程で、開発者はニューラルネットワークを快適、安全、社会的に承認された回答に最適化している。その結果、多くの新しいサイトは「無菌的にフレンドリーな」情報環境を作り出している。そこでは鋭い評価や対立が少なくなる一方で、生きた人間の議論も少なくなる。## 確認されなかったこといくつかの一般的な懸念は統計的に裏付けられなかった。研究者たちは、AIコンテンツの増加と実際の正確性の低下、明らかな誤りの増加、またはテキストのスタイルの均一化との間に有意な相関関係を見つけられなかった。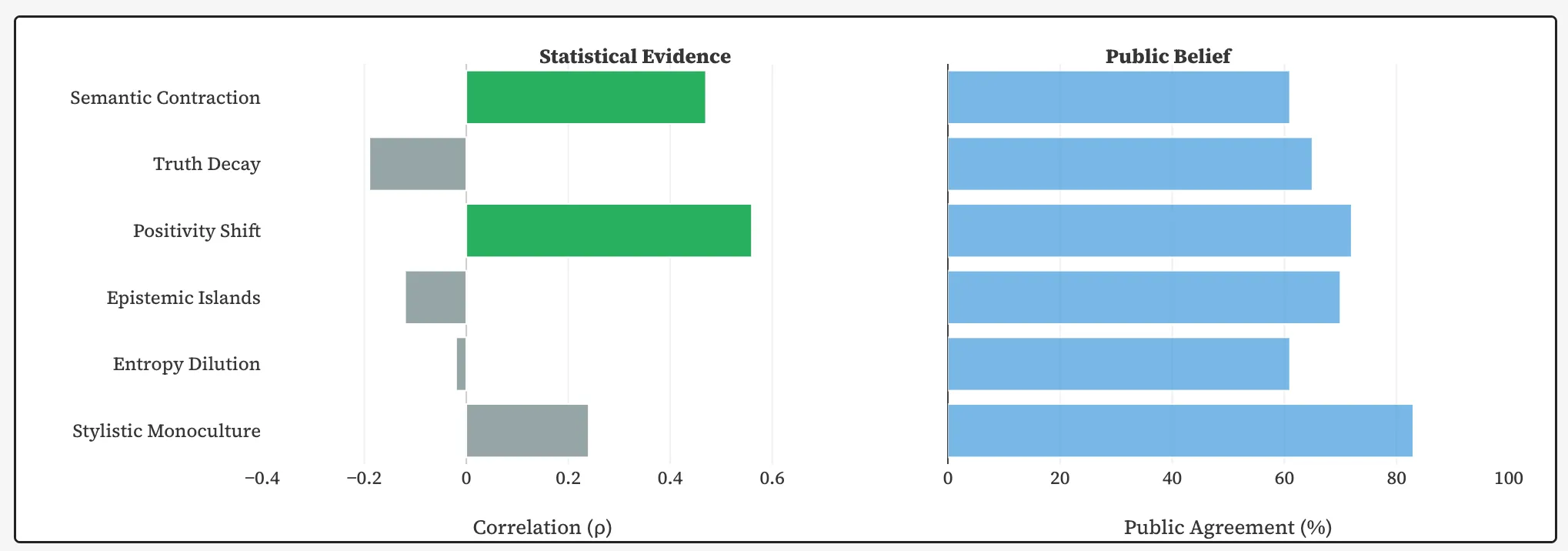左側:AIコンテンツと仮説の相関関係。右側:各仮説に賛成するアメリカ成人の割合。出典:GitHub 研究者たちはまた、これまで主に理論的に議論されてきた効果、すなわちモデルの (モデル崩壊) についても指摘した。新しいニューラルネットワークを、多くのAIコンテンツを含むデータで訓練すると、システムは自分自身の平均的な回答を再生してしまう。これにより、多様性が低下し、品質が損なわれ、将来的にはLLMが人間から学ぶのではなく、「合成されたエコー」から学習するリスクが生じる。専門家たちは、Internet Archiveと協力して、インターネット上のAIコンテンツの割合を継続的に監視するシステムに研究を発展させる計画だ。また、4月中旬にスタンフォード大学はAIの進展速度が加速していることを指摘した。研究者たちは、ニューラルネットワークがほぼ人間と同じレベルでコンピュータ上のタスクをこなせるようになったと報告している。
スタンフォード:35%の新しいウェブサイトはAIによって作成されました - ForkLog:暗号通貨、AI、シンギュラリティ、未来
2025年中頃までに、新しいウェブサイトの約35%が完全または部分的に人工知能を使用して作成されたことが判明した。これはスタンフォード大学の研究者による結論である。
2022年11月にOpenAIのChatGPTが公開される前は、その割合はゼロだった。数年の間にAI生成コンテンツの割合は、インターネット上の最新の投稿の3分の1以上に増加した。
主な変化
研究者たちは意味的多様性の低下を記録した。ニューラルネットワークによって生成されたページは、人間が書いたテキストよりも33%多く互いに似ている。さまざまなサイトがますますほぼ同じフレーズで同じアイデアを繰り返し伝えるようになっている。
著者たちの意見では、これは単なるAIによる大量のコピペの問題ではない。問題はより深く、表現やアイデアの多様性が徐々に狭まっていることにある。大規模言語モデル (LLM) は本質的に最も「平均的な」回答を選び出し、その結果、テンプレート化された談話を再現してしまう。
また、公開の感情的トーンも変化した。AIコンテンツは人間のものより107%ポジティブであることが判明した。スタンフォードでは、これがすでに記録されたLLMの媚びへつらい傾向と関連付けられている。
学習過程で、開発者はニューラルネットワークを快適、安全、社会的に承認された回答に最適化している。その結果、多くの新しいサイトは「無菌的にフレンドリーな」情報環境を作り出している。そこでは鋭い評価や対立が少なくなる一方で、生きた人間の議論も少なくなる。
確認されなかったこと
いくつかの一般的な懸念は統計的に裏付けられなかった。研究者たちは、AIコンテンツの増加と実際の正確性の低下、明らかな誤りの増加、またはテキストのスタイルの均一化との間に有意な相関関係を見つけられなかった。
新しいニューラルネットワークを、多くのAIコンテンツを含むデータで訓練すると、システムは自分自身の平均的な回答を再生してしまう。これにより、多様性が低下し、品質が損なわれ、将来的にはLLMが人間から学ぶのではなく、「合成されたエコー」から学習するリスクが生じる。
専門家たちは、Internet Archiveと協力して、インターネット上のAIコンテンツの割合を継続的に監視するシステムに研究を発展させる計画だ。
また、4月中旬にスタンフォード大学はAIの進展速度が加速していることを指摘した。研究者たちは、ニューラルネットワークがほぼ人間と同じレベルでコンピュータ上のタスクをこなせるようになったと報告している。