Dasar
Spot
Perdagangkan kripto dengan bebas
Perdagangan Margin
Perbesar keuntungan Anda dengan leverage
Konversi & Investasi Otomatis
0 Fees
Perdagangkan dalam ukuran berapa pun tanpa biaya dan tanpa slippage
ETF
Dapatkan eksposur ke posisi leverage dengan mudah
Perdagangan Pre-Market
Perdagangkan token baru sebelum listing
Futures
Akses ribuan kontrak perpetual
CFD
Emas
Satu platform aset tradisional global
Opsi
Hot
Perdagangkan Opsi Vanilla ala Eropa
Akun Terpadu
Memaksimalkan efisiensi modal Anda
Perdagangan Demo
Pengantar tentang Perdagangan Futures
Bersiap untuk perdagangan futures Anda
Acara Futures
Gabung acara & dapatkan hadiah
Perdagangan Demo
Gunakan dana virtual untuk merasakan perdagangan bebas risiko
Peluncuran
CandyDrop
Koleksi permen untuk mendapatkan airdrop
Launchpool
Staking cepat, dapatkan token baru yang potensial
HODLer Airdrop
Pegang GT dan dapatkan airdrop besar secara gratis
Pre-IPOs
Buka akses penuh ke IPO saham global
Poin Alpha
Perdagangkan aset on-chain, raih airdrop
Poin Futures
Dapatkan poin futures dan klaim hadiah airdrop
Investasi
Simple Earn
Dapatkan bunga dengan token yang menganggur
Investasi Otomatis
Investasi otomatis secara teratur
Investasi Ganda
Keuntungan dari volatilitas pasar
Soft Staking
Dapatkan hadiah dengan staking fleksibel
Pinjaman Kripto
0 Fees
Menjaminkan satu kripto untuk meminjam kripto lainnya
Pusat Peminjaman
Hub Peminjaman Terpadu
Promosi
AI
Gate AI
Partner AI serbaguna untuk Anda
Gate AI Bot
Gunakan Gate AI langsung di aplikasi sosial Anda
GateClaw
Gate Blue Lobster, langsung pakai
Gate for AI Agent
Infrastruktur AI, Gate MCP, Skills, dan CLI
Gate Skills Hub
10RB+ Skills
Dari kantor hingga trading, satu platform keterampilan membuat AI jadi lebih mudah digunakan
GateRouter
Pilih secara cerdas dari 40+ model AI, dengan 0% biaya tambahan
AI Masih Belum Bisa Mengalahkan Insinyur yang Bertugas: Inilah Alasannya
Singkatnya
Perusahaan AI terus mempromosikan agen insinyur keandalan situs otomatis—AI yang menyelidiki insiden produksi menggantikan manusia. Datadog menjalankan tolok ukur nyata pada gangguan nyata, dan model AI terbaik belum mampu mengalahkan insinyur yang seharusnya mereka gantikan. Tolok ukur ini adalah ARFBench (Anomaly Reasoning Framework Benchmark), sebuah proyek bersama dari Datadog dan Carnegie Mellon. Dibangun dari 63 insiden produksi nyata, diambil dari thread Slack insinyur selama keadaan darurat langsung—750 pertanyaan pilihan ganda yang mencakup 142 metrik pemantauan dan 5,38 juta data poin, setiap pertanyaan diverifikasi secara manual. Tidak ada data sintetis. Tidak ada skenario buku teks. “Triliunan dolar hilang setiap tahun akibat gangguan sistem,” tulis para peneliti. Tolok ukur ini menguji apakah AI benar-benar dapat membantu mengubah hal tersebut.
“Terlepas dari peran sentral analisis berbasis pertanyaan dalam respons insiden, masih belum jelas apakah model dasar modern dapat secara andal menjawab pertanyaan deret waktu yang diajukan insinyur dalam praktik,” tulis makalah tersebut. Pertanyaan terbagi dalam tiga tingkat. Tingkat I: Apakah ada anomali dalam grafik ini? Tingkat II: Kapan mulai, seberapa parah, jenis apa?
Tingkat III—yang paling sulit—memerlukan penalaran lintas metrik: Apakah grafik ini menyebabkan masalah di grafik lain? Di situlah AI gagal. GPT-5 hanya mendapatkan 47,5% F1 pada pertanyaan Tingkat III, sebuah metrik yang memberi penalti pada model karena menebak jawaban paling umum.
“Terlepas dari peran sentral analisis berbasis pertanyaan dalam respons insiden, masih belum jelas apakah model dasar modern dapat secara andal menjawab pertanyaan deret waktu yang diajukan insinyur dalam praktik,” tulis para peneliti. Bagaimana setiap model dibandingkan GPT-5 memimpin semua model yang ada dengan 62,7% akurasi—pada tes di mana tebakan acak mendapatkan 24,5%. Gemini 3 Pro mendapatkan 58,1%. Claude Opus 4.6: 54,8%. Claude Sonnet 4.5: 47,2%.
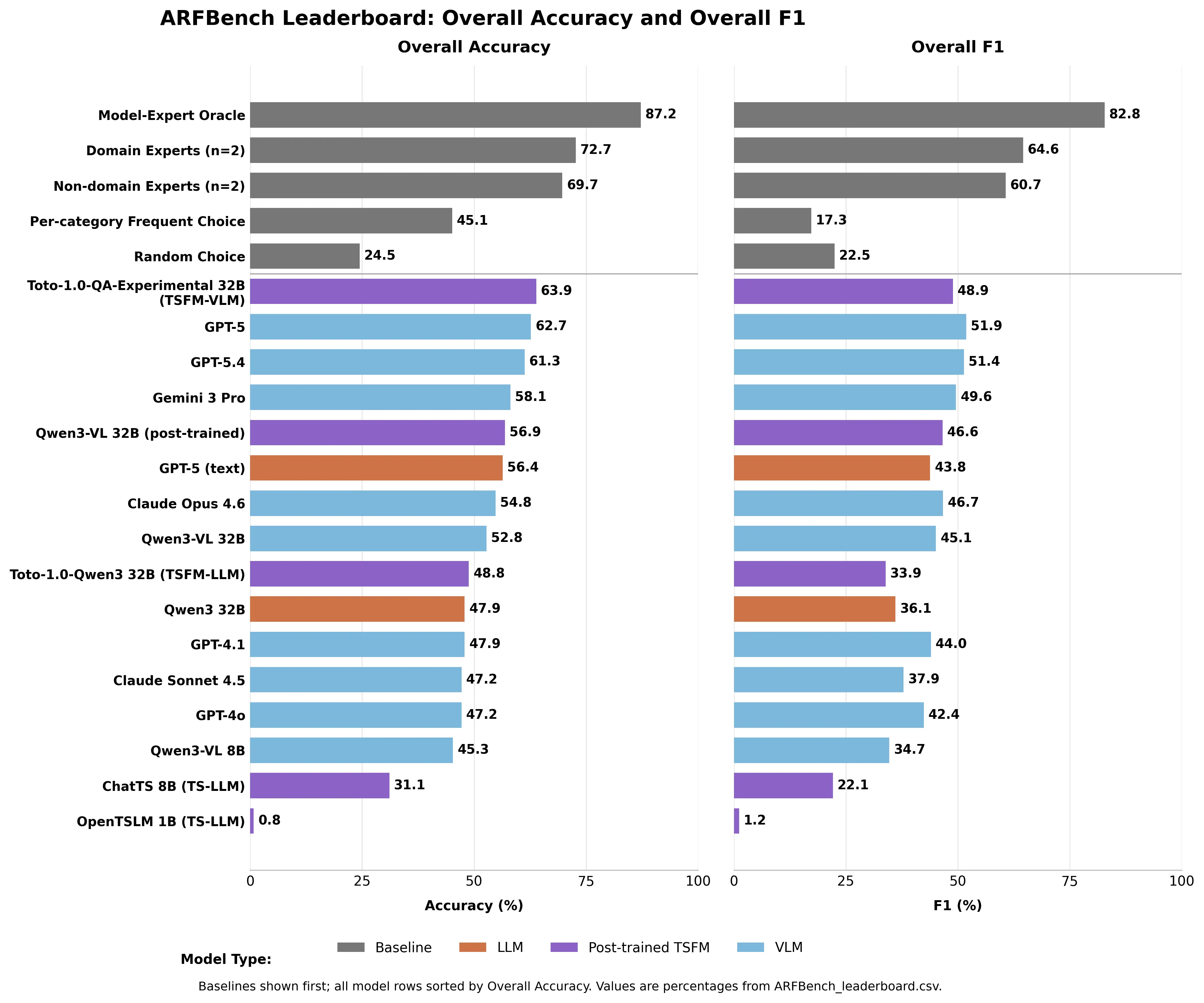
Para ahli domain mencapai 72,7% akurasi. Non-ahli domain—peneliti deret waktu di Datadog tanpa pengalaman observabilitas yang luas—masih meraih 69,7%.
Tidak ada model AI yang mengalahkan kedua baseline manusia tersebut.
Gambar dibuat oleh Decrypt berdasarkan CSV papan peringkat ARFBench
Model yang benar-benar menduduki puncak papan peringkat adalah hybrid milik Datadog sendiri: Toto—model peramalan deret waktunya—digabungkan dengan Qwen3-VL 32B. Toto-1.0-QA-Experimental mencapai 63,9% akurasi, melampaui GPT-5 dengan menggunakan sebagian kecil dari parameternya. Khusus untuk identifikasi anomali, model ini mengungguli semua model lain minimal 8,8 poin persentase dalam F1. Model domain yang dibangun khusus, dilatih pada data observabilitas, mengungguli sistem umum terdepan dalam tugas spesifik ini adalah hasil yang diharapkan. Itulah intinya. Temuan paling berharga bukanlah model mana yang mendapatkan skor tertinggi. “Kami mengamati profil kesalahan yang sangat berbeda antara model terdepan dan ahli manusia, menunjukkan bahwa kekuatan mereka saling melengkapi,” tulis para peneliti. Model sering berhalusinasi, melewatkan metadata, dan kehilangan konteks domain. Manusia salah membaca cap waktu yang tepat dan kadang gagal dalam instruksi kompleks. Kesalahan mereka hampir tidak tumpang tindih.
Bayangkan sebuah “Model-Penasihat Ahli-Teoretis”—hakim sempurna yang selalu memilih jawaban yang benar antara AI dan manusia—dan Anda mendapatkan 87,2% akurasi dan 82,8% F1. Jauh di atas keduanya sendiri. Itu bukan produk. Itu adalah target yang didokumentasikan—dibangun dari keadaan darurat nyata, bukan dataset yang dikurasi—yang mengukur seberapa jauh kolaborasi manusia-AI bisa berkinerja lebih baik. Papan peringkat ini aktif di Hugging Face. GPT-5 berada di 62,7%. Batas atasnya adalah 87,2%.