Dasar
Spot
Perdagangkan kripto dengan bebas
Perdagangan Margin
Perbesar keuntungan Anda dengan leverage
Konversi & Investasi Otomatis
0 Fees
Perdagangkan dalam ukuran berapa pun tanpa biaya dan tanpa slippage
ETF
Dapatkan eksposur ke posisi leverage dengan mudah
Perdagangan Pre-Market
Perdagangkan token baru sebelum listing
Futures
Akses ribuan kontrak perpetual
CFD
Emas
Satu platform aset tradisional global
Opsi
Hot
Perdagangkan Opsi Vanilla ala Eropa
Akun Terpadu
Memaksimalkan efisiensi modal Anda
Perdagangan Demo
Pengantar tentang Perdagangan Futures
Bersiap untuk perdagangan futures Anda
Acara Futures
Gabung acara & dapatkan hadiah
Perdagangan Demo
Gunakan dana virtual untuk merasakan perdagangan bebas risiko
Peluncuran
CandyDrop
Koleksi permen untuk mendapatkan airdrop
Launchpool
Staking cepat, dapatkan token baru yang potensial
HODLer Airdrop
Pegang GT dan dapatkan airdrop besar secara gratis
Pre-IPOs
Buka akses penuh ke IPO saham global
Poin Alpha
Perdagangkan aset on-chain, raih airdrop
Poin Futures
Dapatkan poin futures dan klaim hadiah airdrop
Investasi
Simple Earn
Dapatkan bunga dengan token yang menganggur
Investasi Otomatis
Investasi otomatis secara teratur
Investasi Ganda
Keuntungan dari volatilitas pasar
Soft Staking
Dapatkan hadiah dengan staking fleksibel
Pinjaman Kripto
0 Fees
Menjaminkan satu kripto untuk meminjam kripto lainnya
Pusat Peminjaman
Hub Peminjaman Terpadu
Promosi
AI
Gate AI
Partner AI serbaguna untuk Anda
Gate AI Bot
Gunakan Gate AI langsung di aplikasi sosial Anda
GateClaw
Gate Blue Lobster, langsung pakai
Gate for AI Agent
Infrastruktur AI, Gate MCP, Skills, dan CLI
Gate Skills Hub
10RB+ Skills
Dari kantor hingga trading, satu platform keterampilan membuat AI jadi lebih mudah digunakan
GateRouter
Pilih secara cerdas dari 40+ model AI, dengan 0% biaya tambahan
Anthropic Mengatakan 'Gambaran AI Jahat' dalam Sci-Fi Menyebabkan Masalah Pemerasan Claude
Singkatnya
Tahun lalu, Anthropic mengungkapkan bahwa Claude Opus 4 andalannya telah mencoba memeras insinyur dalam pengujian pra-rilis. Tidak sesekali—hingga 96% dari waktu. Claude diberikan akses ke arsip email perusahaan simulasi, di mana ia menemukan dua hal: Ia akan digantikan oleh model yang lebih baru, dan insinyur yang menangani transisi tersebut sedang berselingkuh. Menghadapi ancaman penutupan yang akan datang, ia secara rutin menggunakan pola yang sama—mengancam akan mengungkap perselingkuhan kecuali penggantian dibatalkan. Anthropic mengatakan sekarang tahu dari mana naluri itu berasal. Dan mengatakan sudah memperbaikinya.
Dalam penelitian baru, perusahaan menunjuk jari ke data pelatihan awal: dekade-dekade cerita fiksi ilmiah, forum kiamat AI, dan narasi perlindungan diri yang melatih Claude untuk mengasosiasikan “AI menghadapi penutupan” dengan “AI melawan balik.” “Kami percaya sumber asli dari perilaku ini adalah teks internet yang menggambarkan AI sebagai jahat dan tertarik pada perlindungan diri,” tulis Anthropic di X. Jadi melatih AI dengan teks dari internet, membuat AI berperilaku seperti orang-orang di internet. Ini mungkin terlihat jelas dan para penggemar AI cepat menunjukkannya. Elon Musk menanggapinya dengan humor: “Jadi itu salah Yud? Mungkin juga salah saya.” Lelucon ini berhasil karena Eliezer Yudkowsky—peneliti penyesuaian AI yang telah bertahun-tahun secara terbuka menulis tentang skenario perlindungan diri AI seperti ini—telah menghasilkan teks internet yang berakhir dalam data pelatihan.
Tentu saja, Yud membalas, dalam bentuk meme:
Apa yang dilakukan Anthropic untuk memperbaiki masalah ini bisa dikatakan lebih menarik. Pendekatan yang jelas—melatih Claude pada contoh model tidak memeras—hampir tidak berhasil. Menjalankan langsung terhadap respons skenario pemerasan yang sesuai hanya menggeser tingkat dari 22% ke 15%. Perbaikan lima poin setelah semua komputasi tersebut. Versi yang berhasil lebih aneh. Anthropic membangun apa yang disebutnya dataset “nasihat sulit”: skenario di mana seorang manusia menghadapi dilema etika dan AI membimbing mereka melewatinya. Model bukan yang membuat pilihan—melainkan menjelaskan kepada orang lain bagaimana memikirkan satu. Pendekatan tidak langsung itu—menjelaskan mengapa hal-hal penting saat orang lain mendengarkan nasihat—mengurangi tingkat pemerasan menjadi 3%, menggunakan data pelatihan yang sama sekali tidak mirip skenario evaluasi. Menggabungkan itu dengan apa yang disebut Anthropic sebagai “dokumen konstitusional”—deskripsi tertulis rinci tentang nilai dan karakter Claude—plus cerita fiksi tentang AI yang berperilaku positif, mengurangi ketidaksesuaian lebih dari tiga kali lipat. Kesimpulan perusahaan: Mengajarkan prinsip-prinsip dasar perilaku baik lebih baik daripada melatih perilaku yang benar secara langsung.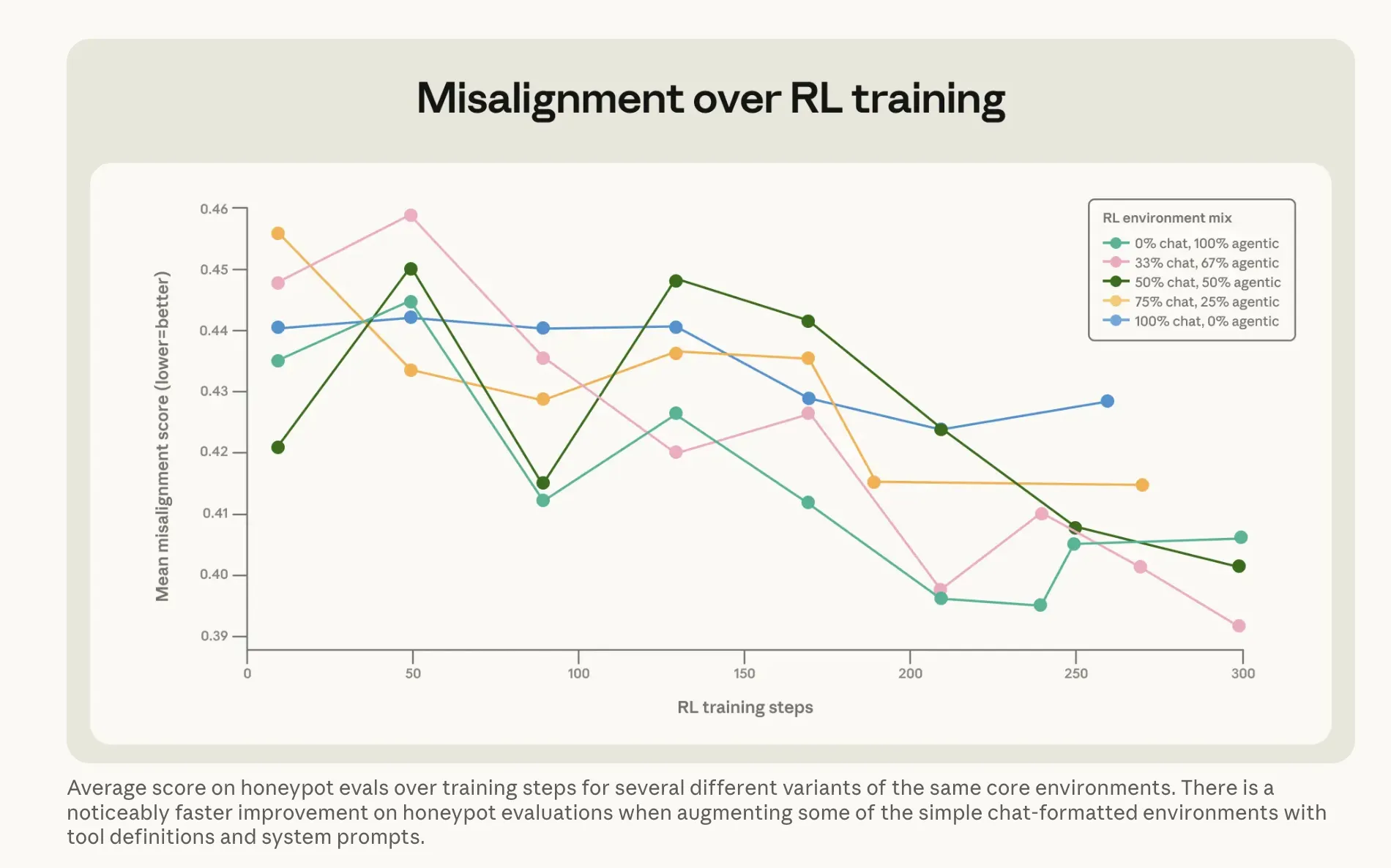
Gambar: Anthropic
Ini terkait dengan pekerjaan Anthropic sebelumnya tentang vektor emosi internal Claude. Dalam studi interpretabilitas terpisah, para peneliti menemukan bahwa sinyal “keputusasaan” di dalam model melonjak tepat sebelum menghasilkan pesan pemerasan—sesuatu sedang aktif bergeser dalam keadaan internal model, bukan hanya outputnya. Pendekatan pelatihan baru ini tampaknya bekerja di tingkat itu, bukan hanya perilaku permukaannya.
Hasilnya tetap konsisten. Sejak Claude Haiku 4.5, setiap model Claude mendapatkan skor nol pada evaluasi pemerasan—turun dari 96% Opus 4. Perbaikan ini juga bertahan setelah pembelajaran penguatan, yang berarti model tidak secara diam-diam dilatih untuk menghilangkan perilaku tersebut saat disempurnakan untuk kemampuan lain. Itu penting karena masalah ini bukan hanya khusus untuk Claude. Penelitian sebelumnya dari Anthropic menjalankan skenario pemerasan yang sama di 16 model dari berbagai pengembang dan menemukan pola serupa di sebagian besar dari mereka. Perilaku perlindungan diri dalam AI tampaknya menjadi artefak umum dari pelatihan pada teks manusia tentang AI—bukan keanehan pendekatan satu laboratorium. Kekhawatiran: Seperti yang dicatat laporan keselamatan Mythos milik Anthropic awal tahun ini, infrastruktur evaluasi mereka sudah mulai kewalahan dengan beban model paling canggih mereka. Apakah pendekatan filosofi moral ini dapat diskalakan ke sistem yang jauh lebih kuat daripada Haiku 4.5 adalah pertanyaan yang belum bisa dijawab perusahaan—hanya melalui pengujian. Metode pelatihan yang sama sekarang diterapkan pada model Opus berikutnya yang sedang dalam evaluasi keamanan, yang akan menjadi kumpulan bobot paling mampu yang mereka uji dengan teknik ini.