Comprar criptomonedas
Pagar con
USD
Compra y venta
HOT
Compra y vende criptomonedas a travésde Apple Pay, tarjetas, Google Pay, transferencias bancarias y más
P2P
0 Fees
¡Cero tarifas, más de 400 opciones de pago y compra y venta de criptomonedas sin complicaciones!
Gate Card
Tarjeta de pago con criptomonedas que permite efectuar transacciones internacionales fácilmente
Operar
Tipo de trading
Spot
Opera con criptomonedas libremente
Alpha
Puntos
Consigue tokens prometedores en operaciones on-chain simplificadas
Premercado
Opera con nuevos tokens antes de que selisten oficialmente
Margen
Multiplica tus beneficios con el apalancamiento
Conversión y trading en bloques
0 Fees
Opera cualquier volumen sin tarifas ni deslizamiento
Tokens apalancados
Obtén exposición a posiciones apalancadas de forma sencilla
Contrato
Contrato
Puntos
Cientos de contratos liquidados en USDT o BTC
Opciones
HOT
Opera con opciones estándar al estilo europeo
Cuenta unificada
Maximiza la eficacia de tu capital
Trading de prueba
Comienzo del trading de futuros
Prepárate para operar con futuros
Eventos de futuros
Participa en eventos para ganar generosas recompensas
Trading de prueba
Usa fondos virtuales para probar el trading sin asumir riesgos
Earn
Lanzamiento
CandyDrop
Acumula golosinas para ganar airdrops
Launchpool
Staking rápido, ¡gana nuevos tokens con potencial!
HODLer Airdrop
Holdea GT y consigue airdrops enormes gratis
Launchpad
Anticípate a los demás en el próximo gran proyecto de tokens
Puntos Alpha
New
¡Opera con activos on-chain y recibe recompensas por airdrop!
Puntos de futuros
New
Gana puntos de futuros y reclama recompensas de airdrop
Inversión
Simple Earn
Genera intereses con los tokens inactivos
Inversión automática
Invierte automáticamente de forma regular
Inversión dual
Compra a la baja y vende al alza para aprovechar las fluctuaciones de los precios
Staking flexible
Gana recompensas con el staking flexible
Préstamo de criptomonedas
0 Fees
Usa tu cripto como garantía y pide otra en préstamo
Centro de préstamos
Centro de préstamos integral
Centro de patrimonio VIP
New
La gestión patrimonial personalizada potencia el crecimiento de tus activos
Gestión patrimonial privada
Gestión de activos personalizada para hacer crecer sus activos digitales
Quant Fund
El mejor equipo de gestión de activos te ayuda a obtener beneficios sin complicaciones
Staking
Haz staking de criptomonedas para ganar en productos PoS
BTC Staking
HOT
Haz staking de BTC y gana un 10•% de APR
Acuñación de GUSD
New
Usa USDT/USDC para acuñar GUSD y obtener rendimientos a nivel tesorería
Más


- Temas de actualidadVer más
1.7K Popularidad
36.2K Popularidad
26.5K Popularidad
5.6K Popularidad
201.1K Popularidad
- Gate Fun en tendenciaVer más
- Cap.M.:$764KHolders:7161
- Cap.M.:$703.7KHolders:10603
- Cap.M.:$136.5KHolders:3265
- Cap.M.:$715.3KHolders:131
- Cap.M.:$79.1KHolders:180
- Anclado
La interrupción de AWS deja fuera de línea aplicaciones populares mientras la resiliencia de Web3 recibe nueva atención
Una interrupción generalizada del servicio el 20 de octubre dejó temporalmente fuera de línea varias plataformas importantes tras una falla mayor en la infraestructura de Amazon Web Services (AWS).
Aplicaciones populares como Snapchat, Fortnite y Alexa se volvieron inaccesibles durante horas, exponiendo la medida en que gran parte de Internet depende de unos pocos grandes proveedores de nube.
La caída de AWS expuso los puntos débiles de Web2 y cómo los diseños de Web3 añaden resiliencia
El evento destacó hasta qué punto la internet global depende de un pequeño número de proveedores de nube centralizados. También renovó las discusiones en torno a modelos alternativos, particularmente sistemas descentralizados promovidos bajo Web3, que buscan reducir la dependencia de puntos únicos de falla.
Los informes de problemas de conectividad comenzaron alrededor de las 3:11 a.m. ET, cuando los usuarios en los Estados Unidos y partes de Europa notaron que varias aplicaciones y sitios web habían dejado de funcionar.
Amazon pronto confirmó que su región US-East-1, uno de sus centros de nube más críticos, estaba experimentando “tasas de error elevadas” que afectaban servicios como API Gateway, Lambda y CloudFront.
En el transcurso de una hora, las plataformas dependientes de la infraestructura de AWS, desde el entretenimiento hasta los servicios empresariales, comenzaron a quedar fuera de servicio. La interrupción de AWS afectó las operaciones centrales en múltiples industrias, incluyendo el comercio electrónico, los videojuegos, las comunicaciones y los servicios financieros.
Durante varias horas, los usuarios no pudieron acceder a las funciones de hogar inteligente, iniciar sesión en plataformas sociales o completar transacciones en línea. Las empresas que operan en entornos basados en AWS también enfrentaron tiempo de inactividad en sus sistemas internos, interrumpiendo las operaciones diarias y los servicios al cliente.
Causa Raíz de la Caída de AWS: Lo que Amazon Confirmó
Para el mediodía, los ingenieros de Amazon identificaron una mala configuración en una actualización de red como la causa raíz. El problema interrumpió la forma en que los sistemas internos gestionaban el enrutamiento y las operaciones de DNS, impidiendo que las solicitudes llegaran a sus destinos. Los equipos de AWS revertieron la actualización defectuosa, restaurando gradualmente el servicio completo para la tarde.
Amazon enfatizó que no se perdió ni se comprometió ningún dato de cliente, y que el problema se limitó a una sola región. Aun así, el tiempo de inactividad destacó cómo incluso un problema localizado puede repercutir en el ecosistema web global cuando tantos servicios digitales dependen de una única capa de infraestructura.
Qué sitios web y aplicaciones se cayeron y por qué se expandió el impacto
Entre las interrupciones más visibles se encontraban los propios productos de consumo de Amazon, incluidos Alexa y Ring. Los usuarios informaron que los altavoces inteligentes no podían procesar los comandos de voz, mientras que las cámaras y timbres conectados dejaron de responder a los controles de la aplicación móvil.
En el sector del entretenimiento y los videojuegos, títulos como Fortnite, Roblox y PUBG experimentaron errores de inicio de sesión y fallos en la emparejamiento. Muchos de estos juegos dependen de AWS para la sincronización multijugador en tiempo real y la entrega de contenido basado en la nube.
Las plataformas sociales y de comunicación también fueron afectadas. Los usuarios de Snapchat encontraron dificultades para enviar mensajes y cargar feeds durante el pico de la interrupción. Además, Slack, Zoom y varias herramientas empresariales construidas sobre la infraestructura de AWS reportaron problemas de conectividad intermitentes que afectaron las operaciones de trabajo remoto.
Algunas aplicaciones financieras y procesadores de pagos que utilizan los servicios de computación y almacenamiento de AWS se desconectaron brevemente, causando transacciones fallidas y retrasos en los pagos digitales. Los sitios web de venta al por menor y comercio electrónico construidos sobre AWS también experimentaron tiempo de inactividad temporal o tiempos de respuesta más lentos.
Por qué la centralización magnificó el radio de explosión en la web
El alcance del incidente mostró cuán profundamente AWS está integrado en las funciones diarias de internet. Una única interrupción regional se extendió más allá de su geografía inmediata, interrumpiendo sistemas de consumo, entretenimiento y empresariales a través de múltiples zonas horarias.
Este fallo también destacó cómo las dependencias de servicio, como las API y las integraciones de terceros, pueden propagar los efectos de una interrupción mucho más allá de su origen técnico.
Según el informe posterior al incidente de Amazon, la interrupción se debió a un cambio de configuración defectuoso implementado durante una actualización de mantenimiento rutinaria. El cambio alteró unintencionadamente cómo los resolvedores DNS internos dirigían el tráfico, lo que provocó que los sistemas dejaran de procesar solicitudes.
Una vez detectado, los ingenieros de Amazon iniciaron un retroceso de la actualización y redirigieron el tráfico a través de rutas de respaldo. La restauración comenzó región por región, con el estado de la interrupción de AWS mostrando una recuperación gradual hacia la tarde.
Desde entonces, la empresa ha introducido salvaguardias adicionales para prevenir problemas similares, incluyendo controles de gestión de cambios más estrictos y nuevos procedimientos automatizados de reversión para actualizaciones de red.
Centralización vs. Descentralización: Una Lección Más Amplia
Este incidente reabrió el debate de larga data sobre los modelos Web2 vs Web3. En el actual marco de Web2, un puñado de corporaciones, incluidas Amazon, Google y Microsoft, alimentan la mayoría del tráfico web global a través de servidores centralizados.
Esta estructura ofrece conveniencia, eficiencia de costos y escalabilidad, pero también concentra control y vulnerabilidad. Cuando uno de estos proveedores experimenta una interrupción, los efectos son inmediatos y generalizados.
Los analistas de la industria han advertido durante mucho tiempo que esta concentración de poder en el alojamiento y la gestión de datos crea un único punto de falla para internet. Si bien la computación en la nube ofrece escalabilidad y eficiencia de costos, también centraliza el riesgo. Cuando los sistemas de un proveedor clave fallan, los servicios dependientes tienen poco margen para recuperarse de forma independiente.
La interrupción de AWS también expuso otro desafío, que son las dependencias interconectadas. Muchos servicios operan en arquitecturas en capas donde la API o la base de datos de un proveedor soporta múltiples plataformas descendentes. Esta estructura magnifica el impacto de cualquier interrupción técnica.
Los expertos sugieren que, si bien la redundancia y el despliegue en múltiples regiones pueden reducir el riesgo, el problema fundamental radica en cómo está estructurada la web. Los modelos de nube centralizada consolidan el control y la capacidad en unas pocas redes, lo que hace que las fallas sean tanto más impactantes como más difíciles de aislar.
Por qué los expertos ven Web3 como una alternativa viable
Web3 pretende cambiar eso distribuyendo la potencia de computación y el almacenamiento de datos a través de redes descentralizadas de nodos independientes. A diferencia de los sistemas de nube centralizados, las arquitecturas descentralizadas no dependen del tiempo de actividad de un único proveedor. Si un nodo o clúster falla, otros pueden continuar operando sin interrupciones.
Para desarrolladores y empresas, este enfoque podría significar una mayor resistencia, transparencia y seguridad, aunque escalar la infraestructura descentralizada para igualar la velocidad y capacidad de Web2 sigue siendo un desafío.
Proyectos como Filecoin, Arweave y Akash Network son ejemplos de soluciones de infraestructura descentralizada que buscan proporcionar almacenamiento y potencia de computación a través de redes abiertas. Estos sistemas utilizan mecanismos de incentivos para mantener el tiempo de actividad y la disponibilidad de datos sin supervisión centralizada.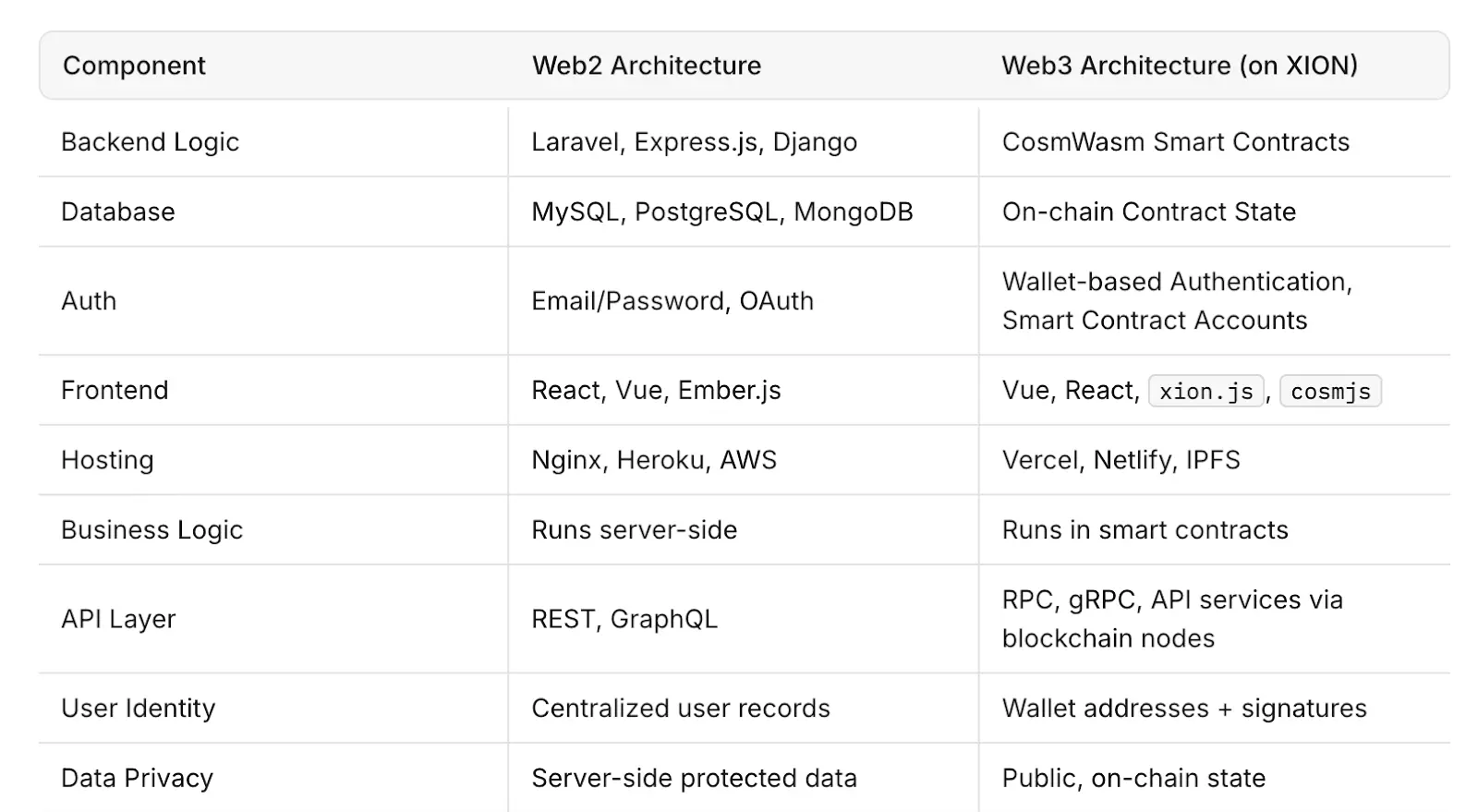
Sin embargo, la infraestructura Web3 todavía se encuentra en las primeras etapas de adopción. Enfrenta desafíos relacionados con la escalabilidad, la velocidad y la experiencia del usuario en comparación con los sistemas Web2 establecidos. Aun así, el incidente de AWS demostró el valor de tener modelos alternativos que pueden mejorar la resiliencia de internet.
Lecciones Aprendidas y el Camino por Delante
La interrupción señaló que la resiliencia en la economía digital requiere redundancia y diversificación. Las empresas que distribuyeron sus cargas de trabajo en múltiples regiones o proveedores de nube experimentaron menos tiempo de inactividad y tiempos de recuperación más rápidos. Otras, totalmente dependientes de AWS, se quedaron esperando hasta que Amazon restableció sus sistemas.
También reveló cómo las cadenas de dependencia amplifican las interrupciones. Muchas aplicaciones no alojaban sus servicios principales en AWS, pero aún así se desconectaron porque utilizaban APIs, herramientas de análisis o herramientas de autenticación alojadas en AWS. Un único punto de fallo en la cadena provocó interrupciones en plataformas no relacionadas.
El evento puede impulsar a varias organizaciones a replantear sus estrategias de infraestructura, explorando modelos híbridos que combinan sistemas de nube tradicionales con almacenamiento y computación descentralizados.
Los desarrolladores y las empresas también pueden ver la descentralización no solo como una tendencia, sino como una salvaguarda práctica contra el tiempo de inactividad a gran escala.
Amazon ha declarado que nuevos mecanismos de monitoreo y controles internos de reversión están ahora activos en todas las regiones. Sin embargo, los expertos señalan que las soluciones técnicas por sí solas no pueden abordar completamente los riesgos inherentes a la centralización.
A medida que la dependencia digital global se profundiza, la resiliencia puede depender de qué tan efectivamente la computación en la nube y las tecnologías descentralizadas pueden coexistir.
FAQs
¿Qué causó la interrupción de AWS?
Amazon dijo que un error de configuración durante una actualización de rutina en su región US-East-1 interrumpió el enrutamiento de la red y las funciones DNS. El problema se contenía en pocas horas y no se reportaron violaciones de datos o de seguridad.
¿Qué sitios web y aplicaciones se vieron afectados?
Las plataformas incluyendo Alexa, Ring, Snapchat, Fortnite y Roblox se desconectaron. Las herramientas comerciales y de pago que utilizan la infraestructura de AWS también enfrentaron interrupciones temporales.
¿Por qué la centralización hace que internet sea vulnerable?
Los sistemas centralizados dependen de unos pocos proveedores importantes, por lo que una falla puede afectar a millones de usuarios. Las redes descentralizadas reducen este riesgo al distribuir las operaciones entre nodos independientes.
Conclusión
El incidente de octubre de 2025 reveló las fortalezas y debilidades de la infraestructura moderna en la nube. AWS logró restaurar las operaciones rápidamente, pero los efectos globales mostraron que la fiabilidad tiene límites cuando el control recae en unos pocos proveedores.
Para las empresas y desarrolladores, la lección aquí es que la diversificación y la descentralización ya no son opcionales. Las infraestructuras híbridas que combinan la eficiencia centralizada con la resiliencia descentralizada podrían definir la próxima era de la fiabilidad de Internet.