العقود الآجلة
وصول إلى مئات العقود الدائمة
CFD
الذهب
منصّة واحدة للأصول التقليدية العالمية
الخیارات المتاحة
Hot
تداول خيارات الفانيلا على الطريقة الأوروبية
الحساب الموحد
زيادة كفاءة رأس المال إلى أقصى حد
التداول التجريبي
مقدمة حول تداول العقود الآجلة
استعد لتداول العقود الآجلة
أحداث مستقبلية
"انضم إلى الفعاليات لكسب المكافآت "
التداول التجريبي
استخدم الأموال الافتراضية لتجربة التداول بدون مخاطر
إطلاق
CandyDrop
اجمع الحلوى لتحصل على توزيعات مجانية.
منصة الإطلاق
-التخزين السريع، واربح رموزًا مميزة جديدة محتملة!
HODLer Airdrop
احتفظ بـ GT واحصل على توزيعات مجانية ضخمة مجانًا
Pre-IPOs
افتح الوصول الكامل إلى الاكتتابات العامة للأسهم العالمية
نقاط Alpha
تداول الأصول على السلسلة واكسب التوزيعات المجانية
نقاط العقود الآجلة
اكسب نقاط العقود الآجلة وطالب بمكافآت التوزيع المجاني
عروض ترويجية
AI
Gate AI
شريكك الذكي الشامل في الذكاء الاصطناعي
Gate AI Bot
استخدم Gate AI مباشرة في تطبيقك الاجتماعي
GateClaw
Gate الأزرق، جاهز للاستخدام
Gate for AI Agent
البنية التحتية للذكاء الاصطناعي، Gate MCP، Skills و CLI
Gate Skills Hub
أكثر من 10 آلاف مهارة
من المكتب إلى التداول، مكتبة المهارات الشاملة تجعل الذكاء الاصطناعي أكثر فعالية
GateRouter
ختر بذكاء من أكثر من 40 نموذج ذكاء اصطناعي، بدون أي رسوم إضافية 0%
لا تزال الذكاء الاصطناعي عاجزًا عن التفوق على مهندس الخدمة الطارئة: إليك السبب
باختصار
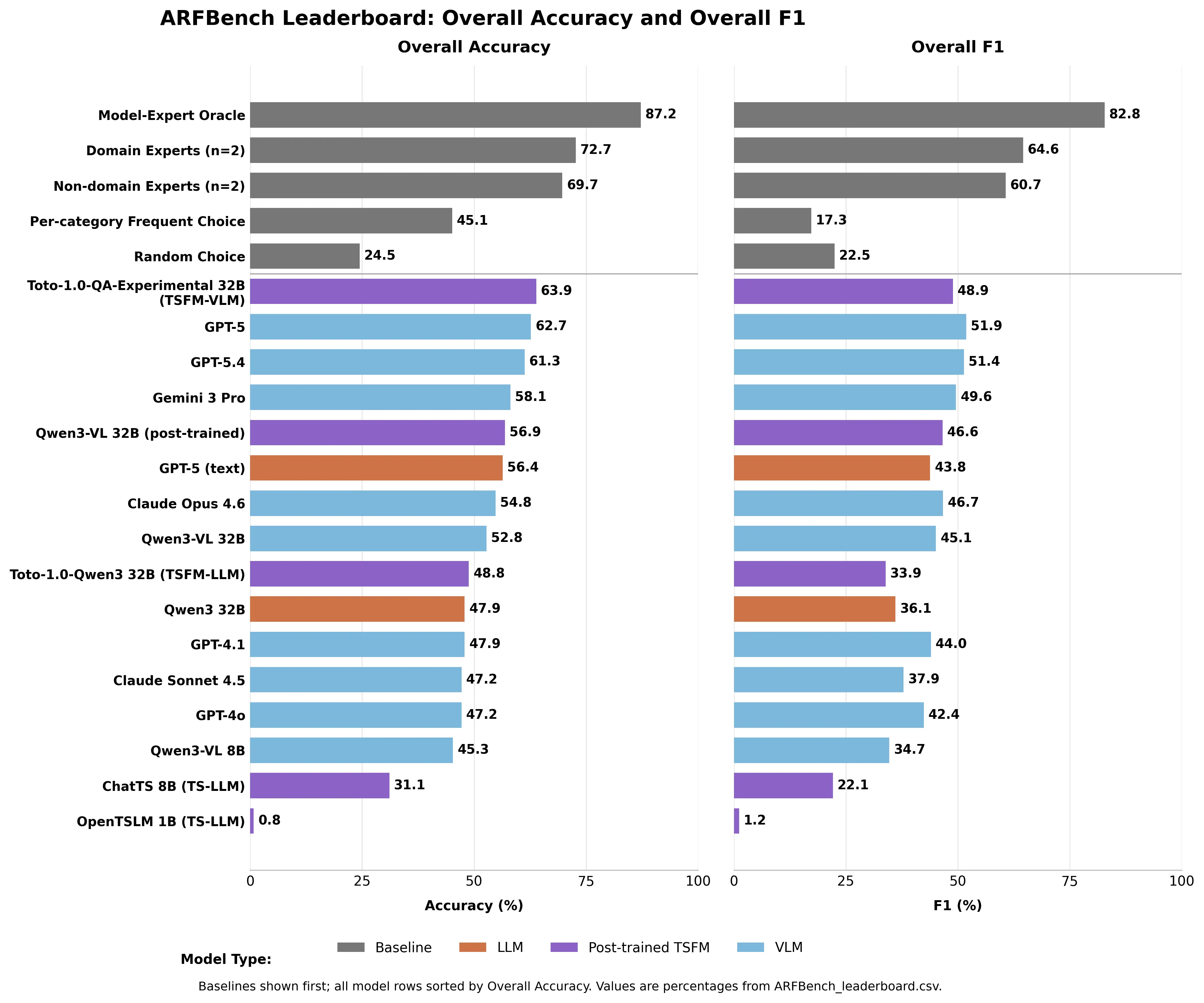
* ARFBench هو أول معيار قياسي للذكاء الاصطناعي مبني بالكامل من حوادث إنتاج حقيقية.
* يقود GPT-5 جميع نماذج الذكاء الاصطناعي الحالية بنسبة دقة 62.7% لكنه يقصر عن خبراء المجال الذين تصل دقتهم إلى 72.7%.
* نموذج-خبير نظري—يجمع بين الذكاء الاصطناعي والحكم البشري—يحقق دقة 87.2%، مما يحدد الحد الأقصى لما يمكن أن تحققه فرق التعاون بين الذكاء الاصطناعي والبشر.
تواصل شركات الذكاء الاصطناعي الترويج لوكلاء مهندسي موثوقية الموقع الذاتيين—ذكاء اصطناعي يحقق في حوادث الإنتاج بدلاً من البشر. أجرى Datadog الاختبار الفعلي على انقطاعات حقيقية، ولا تزال أفضل نماذج الذكاء الاصطناعي لا تتفوق بعد على المهندسين الذين من المفترض أن يحلوا محلهم.
المعيار هو ARFBench (إطار عمل استدلال الشذوذ)، وهو مشروع مشترك بين Datadog و Carnegie Mellon. مبني من 63 حادثة إنتاج حقيقية، مستخرجة من محادثات Slack الخاصة بالمهندسين أثناء حالات الطوارئ الحية—750 سؤال اختيار من متعدد تغطي 142 مقياس مراقبة و5.38 مليون نقطة بيانات، وكل سؤال تم التحقق منه يدويًا. لا بيانات صناعية. لا سيناريوهات من الكتب الدراسية.
"يُفقد تريليونات الدولارات سنويًا بسبب انقطاعات النظام"، يكتب الباحثون. يختبر المعيار ما إذا كان يمكن للذكاء الاصطناعي أن يساعد حقًا في تغيير ذلك.
"على الرغم من الدور المركزي لهذا التحليل القائم على الأسئلة في استجابة الحوادث، لا يزال غير واضح ما إذا كانت نماذج الأساس الحديثة يمكنها الإجابة بشكل موثوق على أنواع الأسئلة المتعلقة بالسلاسل الزمنية التي يطرحها المهندسون في الممارسة العملية"، يقرأ البحث.
تأتي الأسئلة بثلاث مستويات. المستوى الأول: هل يوجد شذوذ في هذا الرسم البياني؟ المستوى الثاني: متى بدأ، مدى شدته، نوعه؟
المستوى الثالث—الأصعب—يتطلب استدلال عبر مقاييس متعددة: هل يسبب هذا الرسم البياني المشكلة في الرسم البياني الآخر؟ هنا يتفكك الذكاء الاصطناعي. يحقق GPT-5 فقط 47.5% من مقياس F1 في أسئلة المستوى الثالث، وهو مقياس يعاقب النماذج على خداع الإجابات باختيار الفئة الأكثر شيوعًا.
"على الرغم من الدور المركزي لهذا التحليل القائم على الأسئلة في استجابة الحوادث، لا يزال غير واضح ما إذا كانت نماذج الأساس الحديثة يمكنها الإجابة بشكل موثوق على أنواع الأسئلة المتعلقة بالسلاسل الزمنية التي يطرحها المهندسون في الممارسة العملية"، يكتب الباحثون.
كيف تصدرت كل نموذج
تصدر GPT-5 جميع النماذج الحالية بنسبة دقة 62.7%—في اختبار يحصل فيه التخمين العشوائي على 24.5%. حقق Gemini 3 Pro نسبة 58.1%. وClaude Opus 4.6: 54.8%. وClaude Sonnet 4.5: 47.2%.
حقق خبراء المجال نسبة دقة 72.7%. أما غير خبراء المجال—باحثو السلاسل الزمنية في Datadog بدون خبرة واسعة في الرصد—فلا يزالون يحققون 69.7%.
لم يتفوق أي نموذج ذكاء اصطناعي على أي من الخطوط الأساسية البشرية.
صورة أنشأها Decrypt استنادًا إلى ملف CSV الخاص بلوحة نتائج ARFBench
النموذج الذي تصدر فعليًا لوحة النتائج الكاملة كان هجين Datadog الخاص: Toto—نموذج التنبؤ بالسلاسل الزمنية الداخلي لديهم—بالإضافة إلى Qwen3-VL 32B. حقق Toto-1.0-QA-Experimental دقة بنسبة 63.9%، متفوقًا على GPT-5 مع استخدام جزء بسيط من معاييره. وعلى وجه التحديد، في تحديد الشذوذ، تفوق على جميع النماذج الأخرى بما لا يقل عن 8.8 نقاط مئوية في مقياس F1.
نموذج مخصص للمجال، مدرب على بيانات الرصد، يتفوق على نظام عام متقدم في هذه المهمة المحددة هو النتيجة المتوقعة. هذا هو الهدف.
أهم اكتشاف ليس هو النموذج الذي حقق أعلى نتيجة.
"نلاحظ أنماط أخطاء مختلفة بشكل كبير بين النماذج الرائدة والخبراء البشريين، مما يشير إلى أن نقاط قوتهم تكمل بعضها البعض"، يكتب الباحثون. النماذج تتوهم، وتفقد البيانات الوصفية، وتفقد السياق المجال. البشر يقرأون الطوابع الزمنية الدقيقة بشكل خاطئ وأحيانًا يفشلون في تعليمات معقدة. الأخطاء بالكاد تتداخل.
نموذج "نموذج-خبير نظري"—حكم مثالي يختار دائمًا الإجابة الصحيحة بين الذكاء الاصطناعي والبشر—تحصل على 87.2% دقة و82.8% مقياس F1. أعلى بكثير من أي منهما بمفرده.
هذا ليس منتجًا. إنه هدف موثق—مبني من حالات طوارئ حقيقية، وليس من مجموعات بيانات منسقة—يحدد بدقة مدى تفوق التعاون بين الإنسان والذكاء الاصطناعي. لوحة النتائج مباشرة على Hugging Face. GPT-5 يقف عند 62.7%. الحد الأقصى هو 87.2%.