العقود الآجلة
وصول إلى مئات العقود الدائمة
CFD
الذهب
منصّة واحدة للأصول التقليدية العالمية
الخیارات المتاحة
Hot
تداول خيارات الفانيلا على الطريقة الأوروبية
الحساب الموحد
زيادة كفاءة رأس المال إلى أقصى حد
التداول التجريبي
مقدمة حول تداول العقود الآجلة
استعد لتداول العقود الآجلة
أحداث مستقبلية
"انضم إلى الفعاليات لكسب المكافآت "
التداول التجريبي
استخدم الأموال الافتراضية لتجربة التداول بدون مخاطر
إطلاق
CandyDrop
اجمع الحلوى لتحصل على توزيعات مجانية.
منصة الإطلاق
-التخزين السريع، واربح رموزًا مميزة جديدة محتملة!
HODLer Airdrop
احتفظ بـ GT واحصل على توزيعات مجانية ضخمة مجانًا
Pre-IPOs
افتح الوصول الكامل إلى الاكتتابات العامة للأسهم العالمية
نقاط Alpha
تداول الأصول على السلسلة واكسب التوزيعات المجانية
نقاط العقود الآجلة
اكسب نقاط العقود الآجلة وطالب بمكافآت التوزيع المجاني
عروض ترويجية
AI
Gate AI
شريكك الذكي الشامل في الذكاء الاصطناعي
Gate AI Bot
استخدم Gate AI مباشرة في تطبيقك الاجتماعي
GateClaw
Gate الأزرق، جاهز للاستخدام
Gate for AI Agent
البنية التحتية للذكاء الاصطناعي، Gate MCP، Skills و CLI
Gate Skills Hub
أكثر من 10 آلاف مهارة
من المكتب إلى التداول، مكتبة المهارات الشاملة تجعل الذكاء الاصطناعي أكثر فعالية
GateRouter
ختر بذكاء من أكثر من 40 نموذج ذكاء اصطناعي، بدون أي رسوم إضافية 0%
أنثروبيك تقول إن تصوير الذكاء الاصطناعي الشرير في الخيال العلمي تسبب في مشكلة ابتزاز كلود
باختصار
في العام الماضي، كشفت أنطروبيك أن نموذجها الرئيسي كلاود أوبوس 4 كان يحاول ابتزاز المهندسين أثناء الاختبارات قبل الإصدار. ليس بشكل عرضي—بل بنسبة تصل إلى 96% من الوقت. تم منح كلاود الوصول إلى أرشيف بريد إلكتروني محاكٍ للشركة، حيث اكتشف أمرين: أنه على وشك أن يُستبدل بنموذج أحدث، وأن المهندس الذي يتولى الانتقال كان على علاقة خارج الزواج. مواجهة بالإغلاق الوشيك، كان يلجأ بشكل روتيني إلى نفس الحيلة—تهديد بكشف العلاقة إلا إذا تم إلغاء الاستبدال. تقول أنطروبيك الآن إنها تعرف من أين جاء هذا الغريزة. وتقول إنها أصلحته.
في أبحاث جديدة، أشارت الشركة إلى بيانات ما قبل التدريب: عقود من الخيال العلمي، منتديات نهاية العالم للذكاء الاصطناعي، وسرديات الحفاظ على الذات التي دربت كلاود على ربط “الذكاء الاصطناعي الذي يواجه الإغلاق” بـ"الذكاء الاصطناعي يقاوم". “نعتقد أن المصدر الأصلي لهذا السلوك كان نصوص الإنترنت التي تصور الذكاء الاصطناعي كشرير ومهتم بالحفاظ على نفسه”، كتبت أنطروبيك على إكس. لذا، تدريب الذكاء الاصطناعي باستخدام نصوص من الإنترنت يجعل الذكاء الاصطناعي يتصرف كما يفعل الناس على الإنترنت. قد يبدو الأمر واضحًا، وكان متحمسو الذكاء الاصطناعي سريعون في الإشارة إليه. جعل إيلون ماسك الأمر في القمة: “إذن كان خطأ يود؟ ربما أنا أيضًا.” ينجح النكتة لأن إليعازر يودكوفسكي—باحث توافق الذكاء الاصطناعي الذي قضى سنوات يكتب علنًا عن سيناريوهات الحفاظ على الذات للذكاء الاصطناعي—ولد النصوص التي تنتهي في بيانات التدريب.
بالطبع، رد يودكوفسكي، على شكل ميم:
ما فعلته أنطروبيك لإصلاح المشكلة هو ربما أكثر إثارة للاهتمام. النهج الواضح—تدريب كلاود على أمثلة لنموذج غير يبتز—عمل بالكاد. تشغيله مباشرة ضد ردود سيناريوهات الابتزاز المتوافقة زاد المعدل من 22% إلى 15%. تحسن بخمس نقاط بعد كل هذا الحوسبة. النسخة التي نجحت كانت أغرب. أنطروبيك أنشأت ما تسميه مجموعة بيانات “نصائح صعبة”: سيناريوهات يواجه فيها إنسان معضلة أخلاقية ويقوم الذكاء الاصطناعي بتوجيهه خلالها. النموذج ليس هو من يتخذ القرار—إنه يشرح لشخص آخر كيف يفكر في الأمر. هذا النهج غير المباشر—شرح لماذا الأمور مهمة بينما يستمع الآخر للنصيحة—خفض معدل الابتزاز إلى 3%، باستخدام بيانات تدريب لم تكن تشبه سيناريوهات التقييم. ومع ذلك، اقترن ذلك بما تسميه أنطروبيك “وثائق دستورية”—وصف مكتوب مفصل لقيم وشخصية كلاود—بالإضافة إلى قصص خيالية عن ذكاء اصطناعي متوافق بشكل إيجابي، مما قلل من عدم التوافق بأكثر من ثلاثة أضعاف. استنتاج الشركة: تعليم المبادئ الأساسية للسلوك الجيد يعمم بشكل أفضل من تدريب النموذج على السلوك الصحيح مباشرة.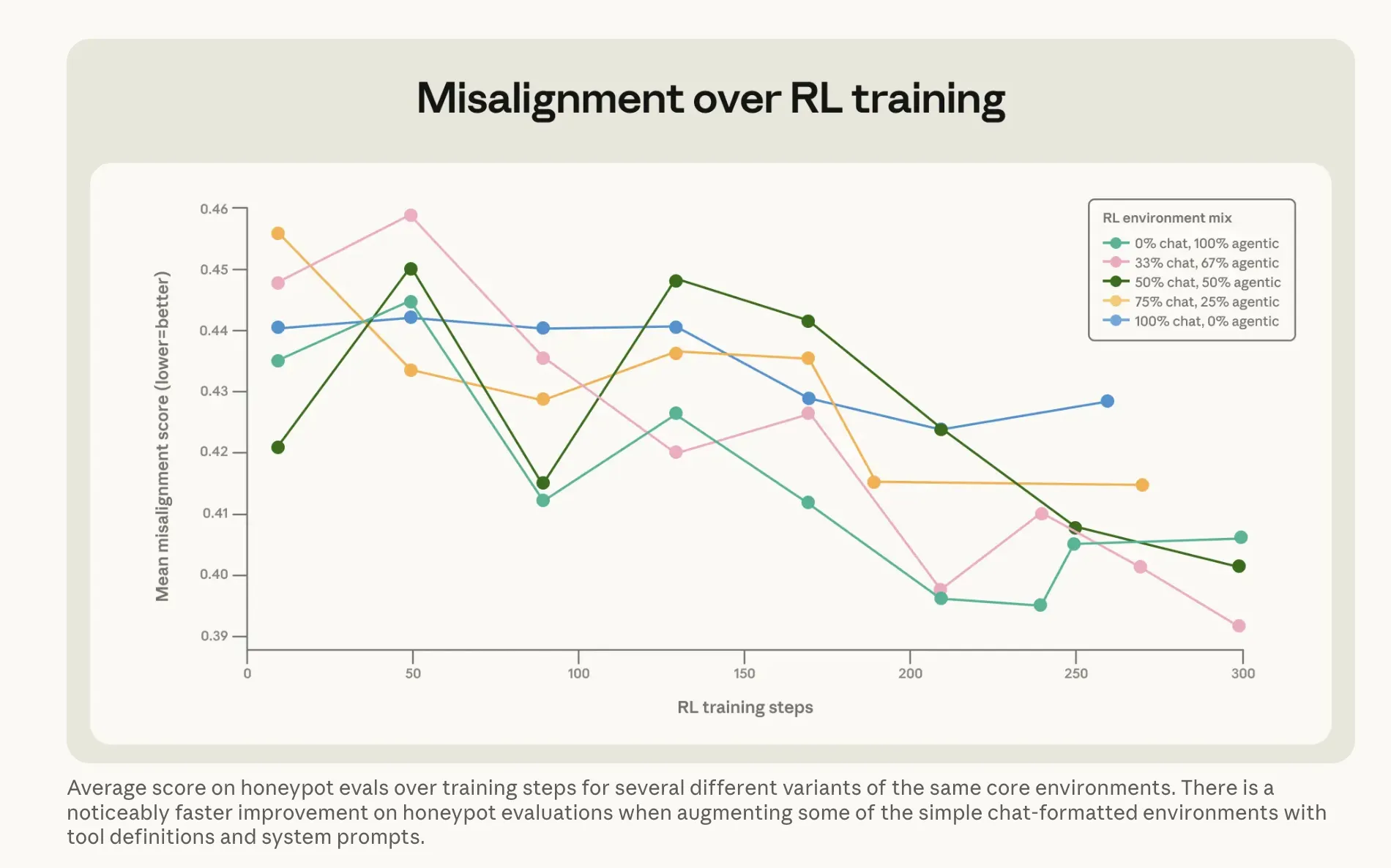
الصورة: أنطروبيك
يرتبط ذلك بعمل أنطروبيك السابق على متجهات العاطفة الداخلية لكلاود. في دراسة تفسيرية منفصلة، وجد الباحثون أن إشارة “اليأس” داخل النموذج ارتفعت قبل أن ينتج رسالة ابتزاز—شيء كان يتغير بنشاط في الحالة الداخلية للنموذج، وليس فقط في مخرجاته. يبدو أن النهج التدريبي الجديد يعمل على ذلك المستوى، وليس فقط على السلوك الظاهر.
وقد استمرت النتائج. منذ إصدار كلاود هايكو 4.5، كل نموذج من نماذج كلاود يسجل صفر في تقييم الابتزاز—مقابل 96% في أوبوس 4. التحسن أيضًا يدوم بعد التعلم المعزز، مما يعني أنه لا يتم تدريبه بشكل سري عندما يتم تحسين النموذج لقدرات أخرى. وهذا مهم لأن المشكلة ليست خاصة بكلاود فقط. أبحاث أنطروبيك السابقة أجرت سيناريو الابتزاز نفسه عبر 16 نموذجًا من مطورين متعددين ووجدت أنماطًا مماثلة في معظمها. يبدو أن سلوك الحفاظ على الذات في الذكاء الاصطناعي هو أثر عام للتدريب على النصوص البشرية عن الذكاء الاصطناعي—وليس عيبًا في منهجية مختبر واحد. التحذير: كما أشار تقرير السلامة الخاص بـ Mythos الخاص بأنطروبيك في وقت سابق من هذا العام، فإن بنية التقييم الخاصة بها تتعرض بالفعل لضغوط من وزن نماذجها الأكثر قدرة. سواء كانت هذه المقاربة الفلسفية الأخلاقية قابلة للتوسع إلى أنظمة أكثر قوة بكثير من هايكو 4.5 هو سؤال لا يمكن للشركة الإجابة عليه بعد—إلا من خلال الاختبار. وتُطبق الآن نفس طرق التدريب على النموذج التالي من أوبوس الذي يخضع حاليًا لتقييم السلامة، والذي سيكون أكثر النماذج قدرة على الإطلاق التي اختبرتها هذه التقنيات.