随着区块链应用规模不断扩大,链上数据已成为 DeFi、链上分析、AI Agent 和多链应用的重要基础资源。然而,区块链原始数据通常以区块、交易和事件日志的形式存在,开发者需要经过复杂的数据提取与处理流程才能获得可直接使用的信息。如何高效获取链上数据,逐渐成为 Web3 基础设施建设的重要课题。
Subsquid(SQD)正是在这一背景下发展的去中心化数据网络。相比传统 RPC 节点直接读取区块链状态的方式,SQD 构建了一套包含数据湖、Worker 节点和 Portal 查询层的数据服务体系,使开发者能够通过统一接口访问经过整理和索引的链上数据。
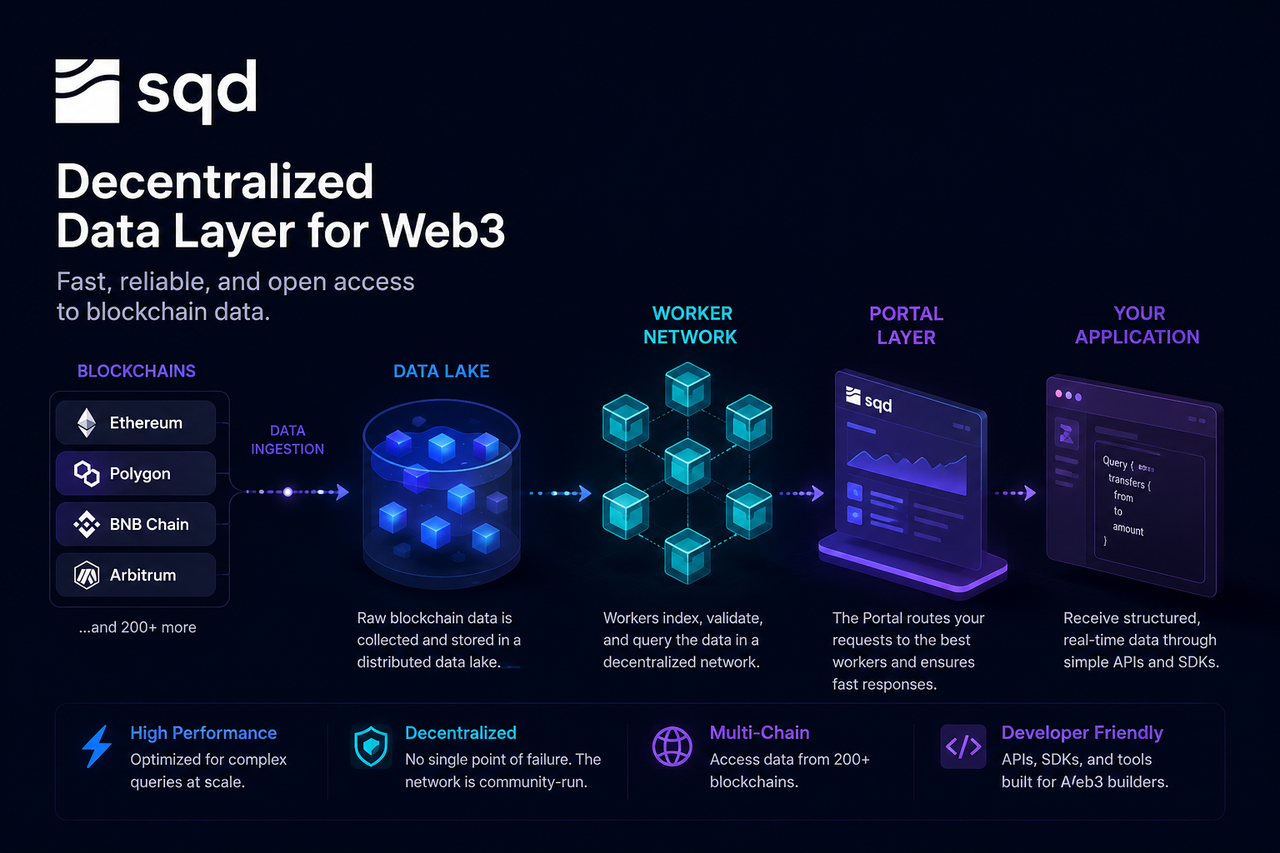
什么是 SQD 数据查询
SQD 数据查询是指开发者通过 SQD Network 获取链上数据的过程。与直接向区块链节点请求数据不同,SQD 查询的数据通常已经经过预处理和索引,因此能够快速返回复杂结果。
例如,一个 DeFi 仪表盘可能需要统计过去数月的交易量,一个 AI Agent 可能需要读取多个地址的资产变化情况,一个分析平台可能需要查询特定智能合约的全部历史事件。这些需求都属于典型的数据查询场景。
SQD 的核心思想是将繁重的数据处理工作提前完成,使应用能够直接访问结构化数据,而不必自行处理海量原始区块数据。
链上数据如何进入 SQD Network
一次查询的起点实际上发生在开发者发起请求之前。
当区块链网络持续产生新区块时,SQD Network 会通过数据采集系统实时获取区块、交易、日志事件以及智能合约状态变化等原始数据。这些数据随后被转换为标准化格式,以便后续处理和存储。
由于 SQD 支持多条区块链网络,因此数据采集层需要持续同步来自不同生态的数据流,并确保数据完整性和一致性。经过标准化处理后,数据会被写入网络的数据存储层。
数据湖如何存储链上信息
数据湖(Data Lake)是 SQD 网络中的核心存储基础设施。
与传统数据库主要用于结构化数据不同,数据湖能够容纳大量原始和半结构化数据。区块链历史记录、交易数据、事件日志以及状态快照都会被存储在这一层中。
数据湖的优势在于能够保存完整历史数据,同时支持后续灵活的数据处理和分析。对于需要追溯数百万笔交易记录的应用而言,这种存储方式比直接查询区块链节点更加高效。
数据湖相当于 SQD Network 的长期记忆系统,为后续索引和查询提供数据来源。
Worker 节点如何处理查询请求
Worker 节点是 SQD 网络中的执行层。
当数据进入网络后,Worker 节点会对数据进行索引、分类和优化,使其能够被快速检索。索引过程类似于为一本大型百科全书建立目录,从而避免每次查询时重新翻阅全部内容。
除了建立索引之外,Worker 节点还负责执行查询任务。当开发者请求特定数据时,节点会根据索引快速定位相关记录,并进行筛选、聚合和计算。
由于多个 Worker 节点可以同时运行,网络能够并行处理大量查询请求,从而提高整体性能和扩展能力。
Portal 如何接收开发者请求
Portal 是开发者访问 SQD Network 的统一入口。
开发者通常通过 API 或 SDK 发起查询请求,而无需直接连接底层节点。当请求到达 Portal 后,系统会解析查询内容,并判断哪些 Worker 节点最适合处理该任务。
Portal 的作用类似于互联网中的负载均衡器。开发者只需面对统一接口,而复杂的资源调度和节点选择则由 Portal 自动完成。
这种设计不仅简化了开发流程,也提高了整个网络的资源利用效率。
查询结果如何返回给应用
当 Worker 节点完成数据处理后,结果会返回至 Portal 层。
Portal 会对结果进行必要的格式化处理,并将最终数据发送给应用程序。开发者获得的数据通常已经是结构化形式,例如 JSON 数据对象或分析结果,因此可以直接用于前端展示、业务逻辑处理或 AI 推理任务。
整个过程对于终端用户而言通常是透明的。用户看到的只是页面加载完成或分析结果生成,而后台实际上已经完成了从数据采集到查询执行的多个步骤。
Hotblocks 如何支持实时数据查询
除了历史数据查询之外,许多应用还需要获取实时链上信息。
例如链上监控系统需要发现异常交易,自动化策略需要监听智能合约事件,AI Agent 需要感知最新市场状态。这些场景要求数据能够在新区块产生后迅速被获取。
Hotblocks 是 SQD 提供的实时数据层,专门用于处理新区块和实时事件。相比数据湖中的历史数据,Hotblocks 更关注低延迟和快速响应,使开发者能够构建实时性要求较高的应用。
SQD 查询与传统 RPC 查询有什么区别
虽然两种方案都能够访问链上数据,但底层逻辑存在明显差异。
传统 RPC 节点更像是直接访问区块链数据库。每次请求都需要从链上状态或历史记录中寻找对应数据。当查询范围扩大时,性能和成本压力也会同步增加。
SQD 则采用预索引架构。数据在进入网络后已经完成整理和索引,因此查询时无需重新扫描全部历史记录。对于复杂分析、多链数据聚合以及长期历史数据统计等场景,SQD 往往能够提供更高效率。
| 对比维度 | SQD | 传统 RPC |
|---|---|---|
| 数据来源 | 预索引数据 | 实时链上读取 |
| 查询效率 | 高 | 中等 |
| 历史数据分析 | 优势明显 | 较为复杂 |
| 多链支持 | 强 | 依赖多个节点 |
| 基础设施成本 | 较低 | 较高 |
| 实时状态读取 | 支持 | 支持 |
SQD 查询流程对 AI Agent 有何意义
AI Agent 正在成为 Web3 基础设施的重要应用方向,而数据获取能力是其运行的基础。
如果 AI Agent 需要分析钱包行为、跟踪协议状态或执行链上操作,就必须持续获取准确且结构化的数据。传统 RPC 查询虽然能够提供原始信息,但通常需要额外处理和转换。
SQD 提供的统一数据接口能够降低 AI Agent 获取链上信息的复杂度。通过标准化查询结果,AI 系统能够将更多计算资源投入分析和决策,而非数据整理工作。
随着 AI 与 Web3 的融合不断深入,去中心化数据层的重要性预计将持续提升。
总结
一次 SQD 数据查询并不仅仅是简单的数据读取过程,而是一套由数据采集层、数据湖、Worker 节点和 Portal 层共同协作完成的完整工作流。区块链原始数据首先被采集和存储,随后经过索引与优化,最终通过统一接口提供给开发者使用。
这种预索引和分布式处理模式使 SQD 能够在复杂查询、多链分析和实时数据访问场景中提供更高效率。随着 DeFi、链上分析平台和 AI Agent 对数据需求持续增长,SQD 所代表的数据层架构正在成为 Web3 基础设施的重要组成部分。
FAQs
SQD 数据查询与普通 API 查询有什么区别?
普通 API 通常由中心化服务商维护,而 SQD 查询依托去中心化数据网络完成。SQD 的数据来源于链上数据采集和索引系统,能够提供更开放和可验证的数据访问能力。
为什么 SQD 查询速度比部分 RPC 请求更快?
SQD 会提前完成数据索引和整理工作,因此查询时无需重新扫描大量区块历史数据。对于复杂分析和历史数据统计任务,查询效率通常更高。
Worker 节点在查询过程中承担什么角色?
Worker 节点负责执行索引、筛选、聚合和计算任务。当 Portal 接收到查询请求后,相关 Worker 节点会完成具体的数据处理工作。
数据湖和数据库有什么区别?
数据库通常存储结构化数据,而数据湖能够保存大规模原始数据和半结构化数据。SQD 使用数据湖存储完整链上历史信息,以支持灵活查询和分析。
Hotblocks 是否能够替代历史数据查询?
不能。Hotblocks 主要用于实时数据访问,而历史数据查询仍依赖数据湖和索引系统。两者共同组成 SQD 的完整数据服务能力。
哪些应用最适合使用 SQD 查询服务?
DeFi 仪表盘、区块链浏览器、链上分析平台、实时监控系统、多链应用以及 AI Agent 等需要频繁访问链上数据的场景,都适合使用 SQD 查询服务。
分享
目录


相关文章

不可不知的比特币减半及其重要性

如何选择比特币钱包?


CKB:闪电网络促新局,落地场景需发力

Master Protocol:激活 BTC 生息潜力
