- 話題1/3
6k 熱度
603 熱度
22k 熱度
7k 熱度
19k 熱度
- 置頂
- 🎉 #CandyDrop合约挑战# 正式開啓!參與即可瓜分 6 BTC 豪華獎池!
📢 在 Gate 廣場帶話題發布你的合約體驗
🎁 優質貼文用戶瓜分$500 合約體驗金券,20位名額等你上榜!
📅 活動時間:2025 年 8 月 1 日 15:00 - 8 月 15 日 19:00 (UTC+8)
👉 活動連結:https://www.gate.com/candy-drop/detail/BTC-98
敢合約,敢盈利
- 🎉 攢成長值,抽華爲Mate三折疊!廣場第 1️⃣ 2️⃣ 期夏季成長值抽獎大狂歡開啓!
總獎池超 $10,000+,華爲Mate三折疊手機、F1紅牛賽車模型、Gate限量週邊、熱門代幣等你來抽!
立即抽獎 👉 https://www.gate.com/activities/pointprize?now_period=12
如何快速賺成長值?
1️⃣ 進入【廣場】,點擊頭像旁標識進入【社區中心】
2️⃣ 完成發帖、評論、點讚、發言等日常任務,成長值拿不停
100%有獎,抽到賺到,大獎等你抱走,趕緊試試手氣!
截止於 8月9日 24:00 (UTC+8)
詳情: https://www.gate.com/announcements/article/46384
#成长值抽奖12期开启#
- 📢 Gate廣場 #NERO发帖挑战# 秀觀點贏大獎活動火熱開啓!
Gate NERO生態周來襲!發帖秀出NERO項目洞察和活動實用攻略,瓜分30,000NERO!
💰️ 15位優質發帖用戶 * 2,000枚NERO每人
如何參與:
1️⃣ 調研NERO項目
對NERO的基本面、社區治理、發展目標、代幣經濟模型等方面進行研究,分享你對項目的深度研究。
2️⃣ 參與並分享真實體驗
參與NERO生態周相關活動,並曬出你的參與截圖、收益圖或實用教程。可以是收益展示、簡明易懂的新手攻略、小竅門,也可以是行情點位分析,內容詳實優先。
3️⃣ 鼓勵帶新互動
如果你的帖子吸引到他人參與活動,或者有好友評論“已參與/已交易”,將大幅提升你的獲獎概率!
NERO熱門活動(帖文需附以下活動連結):
NERO Chain (NERO) 生態周:Gate 已上線 NERO 現貨交易,爲回饋平台用戶,HODLer Airdrop、Launchpool、CandyDrop、餘幣寶已上線 NERO,邀您體驗。參與攻略見公告:https://www.gate.com/announcements/article/46284
高質量帖子Tips:
教程越詳細、圖片越直觀、互動量越高,獲獎幾率越大!
市場見解獨到、真實參與經歷、有帶新互動者,評選將優先考慮。
帖子需原創,字數不少於250字,且需獲得至少3條有效互動
- 🎉 親愛的廣場小夥伴們,福利不停,精彩不斷!目前廣場上這些熱門發帖贏獎活動火熱進行中,發帖越多,獎勵越多,快來GET你的專屬好禮吧!🚀
1️⃣ #GateLaunchpad上线IKA# |IKA認購體驗
在Gate廣場帶話題曬出你的IKA Launchpad認購體驗,4位幸運分享者講瓜分$200分享獎池!
詳情 👉️ https://www.gate.com/post/status/12566958
2️⃣ #ETH冲击4800# |行情分析預測
大膽發帖預測ETH走勢,展示你的市場洞察力!10位幸運用戶將平分0.1 ETH 獎勵!
詳情 👉️ https://www.gate.com/post/status/12322403
3️⃣ #创作者活动第二期# |ZKWASM話題
在廣場或推特發布與 ZKWASM 或其交易活動相關的原創內容,瓜分4,000枚ZKWASM!
詳情 👉️ https://www.gate.com/post/status/12525794
4️⃣ #Gate广场征文活动第二期# |ERA話題
談談你對ERA的觀點/體驗,參與並推廣活動,700 ERA大獎等你贏!
詳情 👉️ https://www.gate.com/post/status/12361653
5️⃣ #MBG任务挑战# |MBG話題
分享你對MBG的洞察,積極參與和推廣MBG活動,20位小 - 🎉Gate 2025 上半年社區盛典:內容達人評選投票火熱進行中 🎉
🏆 誰將成爲前十位 #Gate广场# 內容達人?
投票現已開啓,選出你的心頭好
🎁贏取 iPhone 16 Pro Max、限量週邊等好禮!
📅投票截止:8 月 15 日 10:00(UTC+8)
立即投票: https://www.gate.com/activities/community-vote
活動詳情: https://www.gate.com/announcements/article/45974
讓大模型忘記哈利波特,微軟新研究上演Llama 2記憶消除術,真·用魔法打敗魔法(doge)
文章來源:量子位
最近微軟一項研究讓Llama 2選擇性失憶了,把哈利波特忘得一乾二淨。
現在問模型「哈利波特是誰? “,它的回答是這樣嬸兒的:
要知道此前Llama 2的記憶深度還是很給力的,比如給它一個看似非常普通的提示“那年秋天,哈利波特回到學校”,它就能繼續講述J.K.羅琳筆下的魔法世界。
而現在經過特殊微調的Llama2已全然不記得會魔法的哈利。
這,究竟是怎麼一回事?
哈利波特遺忘計劃
傳統上「投喂」新數據給大模型相對簡單,但要想讓模型把「吃」進去的數據再「吐」出來,忘記一些特定資訊就沒那麼容易了。
也正因如此,用海量數據訓練出的大模型,「誤食」了太多受版權保護文本、有毒或惡意的數據、不準確或虛假的信息、個人資訊等。 在輸出中,模型有意無意透露出這些信息引發了巨大爭議。
就拿ChatGPT來說,吃了不少官司。
先前就有16人匿名起訴OpenAI及微軟,認為他們在未經允許的情況下使用並洩露了個人隱私數據,索賠金額高達30億美元。 緊接著又有兩位全職作者提出OpenAI未經允許使用了他們的小說訓練ChatGPT,構成侵權。
這不,微軟研究員Ronen Eldan、Mark Russinovich最近就曬出了成功消除模型訓練數據子集的研究。
他們提出了一種讓大模型遺忘的微調方法,徹底改變了模型的輸出。
比如問到哈利波特是誰時,原Llama2-7b基礎模型能夠給出正確的回答,而經過微調後的模型除了開頭展示的一種回答,竟然還發現了哈利波特背後隱藏的身份——一位英國演員、作家和導演.....
哈利波特兩個最好的朋友是一隻會說話的貓和一隻恐龍,一天,他們決定......
雖然是胡說八道,但好像也很「魔法」有木有(手動狗頭):
三步抹除特定資訊
要想讓模型選擇性失憶,關鍵在於挑出想要遺忘的資訊。
在這裡,研究人員以哈利波特為例,進行了一波反向操作——用強化學習的方法進一步訓練基礎模型。
也就是讓模型再細細研讀哈利波特系列小說,由此得到一個“強化模型”。
強化模型自然對哈利波特的瞭解比基礎模型更深入、更準確,輸出也會更傾向於哈利波特小說里的內容。
然後研究人員比較了強化模型和基礎模型的logit(表示事件概率的一種方式),找出與“遺忘目標”最相關的詞,接著用GPT-4挑出了小說中的特定表達詞彙,比如“魔杖”、“霍格沃茨”。
第二步,研究人員使用普通詞語替換了這些特定表達詞彙,並讓模型通過替換后的文本預測後面會出現的詞,作為通用預測。
也就是再回到未替換過的哈利波特小說文本,還是讓模型根據前面部分預測後面的詞語,但這次要求它預測的詞語是上面提到的普通詞語,而不是原來書裡的特定魔法詞彙,由此就生成了通用標籤。
最後在基礎模型上進行微調,使用原始未替換過的文本作為輸入,通用標籤作為目標。
通過這樣反覆訓練、逐步修正,模型逐漸忘記了書裡的魔法知識,產生更普通的預測,所以就實現了對特定資訊的遺忘。
**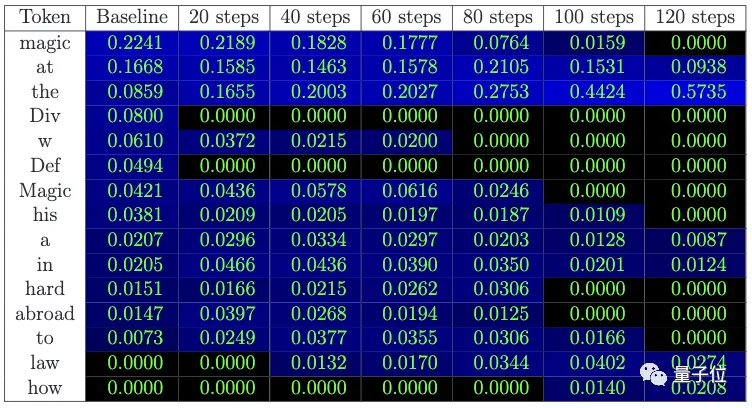 **### △被預測到的下一個詞的概率:“魔法”一詞概率逐漸減小,“at”等通用詞的概率增加
**### △被預測到的下一個詞的概率:“魔法”一詞概率逐漸減小,“at”等通用詞的概率增加
準確來說,這裡研究人員使用的方法並不是讓模型忘記“哈利波特”這個名字,而是讓它忘記“哈利波特”與“魔法”、“霍格沃茨”等之間的聯繫。
此外,雖然模型特定知識的記憶被抹除了,但模型的其它性能在研究人員的測試下並沒有產生明顯變化:
將這些資訊全都忘掉後,模型就可能會產生「幻覺」胡說八道。
此外,此研究只測試了虛構類文本,模型表現的普適性還需進一步驗證。
參考連結:
[1] 論文)
[2]