مصدر الصورة: تم إنشاؤه بواسطة الذكاء الاصطناعي غير محدود
ظهرت المعركة المكونة من 100 نموذج ، وهي واحدة من أكثر اللاعبين المنتظرين ، أخيرا لأول مرة رسميا!
إنه أول نموذج مفتوح المصدر من شركة الذكاء الاصطناعي 2.0 التي أسسها الدكتور Kai-Fu Lee - سلسلة Yi ** من الطرز الكبيرة:
** يي - 34 ب ** 和 ** يي - 6 ب **。
على الرغم من أن سلسلة Yi من النماذج الكبيرة ظهرت لأول مرة في وقت متأخر نسبيا ، من حيث التأثير ، إلا أنه يمكن بالتأكيد تسميتها ** متأخر **.
بمجرد تصويره ، فاز بعدد من الأوائل العالمية **:
احتل Hugging Face المرتبة الأولى في قائمة اختبار اللغة الإنجليزية ، حيث سحق عددا من النماذج الكبيرة مثل Llama-2 70B و Falcon-180B بحجم 34B ؛
النموذج المحلي الوحيد على نطاق واسع الذي وصل بنجاح إلى قمة HuggingFace ؛
C-Chinese القدرة تحتل المرتبة الأولى ، متجاوزة جميع النماذج مفتوحة المصدر في العالم ؛
فاز كل من MMLU و BBH والقدرات الشاملة الثمانية الأخرى بالأداء ؛
فاز بعرش أطول نافذة سياق في العالم ، حيث وصل إلى 200 ألف ، والتي يمكنها التعامل مباشرة مع 400000 حرف صيني لإدخال نص طويل جدا.
......
تجدر الإشارة إلى أن Zero One Thousand Things ونموذجها الكبير لم يتم تحقيقهما بين عشية وضحاها ، ولكن تم تخميرهما لأكثر من نصف عام.
هذا يثير حتما العديد من الأسئلة:
على سبيل المثال ، لماذا تريد التراجع لمدة نصف عام واختيار التصوير قرب نهاية العام؟
مثال آخر هو كيفية تحقيق الكثير من البدايات في المرة الأولى؟
مع هذه الأسئلة ، أجرينا اتصالا حصريا مع Zero One Everything، والآن سنكشف عن الأسرار واحدة تلو الأخرى.
**هزيمة 100 مليار معلمة نماذج كبيرة **
على وجه التحديد ، هناك نوعان رئيسيان من سلسلة Yi من النماذج الكبيرة التي تم إصدارها حديثا ومفتوحة المصدر:
"فوز كبير مع صغير" للتغلب على 100 مليار نماذج المعلمات
أطول نافذة سياق في العالم تدعم 400000 كلمة
في ترتيب نماذج Hugging Face مفتوحة المصدر المدربة مسبقا ، احتلت Yi-34B المرتبة الأولى في العالم بنتيجة 70.72 ، متجاوزة LLaMA-70B و Falcon-180B.
يجب أن تعلم أن عدد معلمات Yi-34B هو فقط ** 1/2 ، 1/5 ** من الأخيرين. لم تفز فقط بالقائمة مع "الصغيرة والكبيرة" ، ولكنها حققت أيضا تجاوزا متقاطعا من حيث الحجم ، متغلبة على النموذج الكبير على مستوى 100 مليار بمقياس 10 مليارات.
من بينها ، تفوقت Yi-34B بشكل كبير على النماذج الكبيرة الأخرى في مؤشري MMLU (فهم اللغة متعدد المهام الهائل) و TruthfulQA (معيار الأصالة).
** **###### △معانقة الوجه المفتوح LLM المتصدرين (المدربين مسبقا) المتصدرين نموذج كبير ، Yi-34B يتصدر القائمة (5 نوفمبر 2023)
مع التركيز على الكفاءة الصينية ، يتفوق Yi-34B على جميع نماذج المصادر المفتوحة في تصنيفات الكفاءة الصينية C.
وبالمثل ، فإن Yi-6B مفتوح المصدر يتفوق على جميع النماذج مفتوحة المصدر من نفس المقياس.
** **###### △C- لوحة المتصدرين: نموذج متاح للجمهور ، Yi-34B رقم 1 في العالم (5 نوفمبر 2023)
في المؤشرات الصينية الرئيسية الثلاثة ل CMMLU و E- و Gaokao ، ** يتقدم بشكل كبير على GPT-4 ** ، مما يدل على الميزة القوية للصينيين ، ونعرف المزيد عن الجذور
。
من حيث BooIQ و OBQA ، فهو في نفس مستوى GPT-4.
بالإضافة إلى ذلك ، في مجموعة التقييم التي تعكس القدرة الشاملة للنموذج ، مثل MMLU (فهم اللغة متعدد المهام الهائل) و BBH ، مؤشرات التقييم الأكثر أهمية للنماذج الكبيرة ، يتفوق Yi-34B في تقييم القدرة العامة ، والتفكير المعرفي ، وفهم القراءة وغيرها من المؤشرات ، وهو ما يتوافق بشكل كبير مع تقييم Hugging Face.
###### **△ ** درجة كل مجموعة تقييم: نموذج يي مقابل نماذج أخرى مفتوحة المصدر
ومع ذلك ، في الإصدار ، قال 010000 أيضا أن نماذج سلسلة Yi لم تعمل بشكل جيد مثل نماذج GPT في التقييمات الرياضية والكود ل GSM8k و MBPP.
وذلك لأن الفريق أراد الحفاظ على أكبر قدر ممكن من القدرات العامة للنموذج خلال مرحلة ما قبل التدريب ، لذلك لم يدرجوا الكثير من بيانات الرياضيات والتعليمات البرمجية في بيانات التدريب.
في الوقت الحاضر ، يجري الفريق أبحاثا في اتجاه الرياضيات ، ويقترح نموذجا كبيرا MammoTH يمكنه حل المشكلات الرياضية العامة ، باستخدام CoT و PoT لحل المشكلات الرياضية ، وهو متفوق على نموذج SOTA في جميع إصدارات المقياس ومجموعات الاختبار الداخلية والخارجية. من بينها ، يتمتع MammoTH-34B بمعدل دقة 44٪ على الرياضيات ، وهو ما يتجاوز نتيجة CoT ل GPT-4.
** ستطلق سلسلة Yi للمتابعة أيضا نموذج تدريب مستمر متخصص في الكود والرياضيات **.
بالإضافة إلى النتائج المبهرة ، قام Yi-34B أيضا بتحديث طول نافذة سياق النموذج الكبير إلى 200 كيلو ، والتي يمكنها التعامل مع إدخال نص طويل جدا يبلغ حوالي 400000 حرف صيني.
وهذا يعادل القدرة على معالجة روايتين "مشكلة الأجسام الثلاثة 1" ** في وقت واحد ** ، وفهم ** مستندات PDF لأكثر من 1000 صفحة ، وحتى استبدال العديد من السيناريوهات التي تعتمد على قواعد بيانات المتجهات لبناء قواعد المعرفة الخارجية.
تعد نافذة السياق الطويلة جدا بعدا مهما لتعكس قوة النموذج الكبير ، ويمكن أن يؤدي وجود نافذة سياق أطول إلى معالجة معلومات قاعدة معارف أكثر ثراء ، وإنشاء نص أكثر تماسكا ودقة ، ودعم النموذج الكبير للتعامل بشكل أفضل مع المهام مثل تلخيص المستند / الأسئلة والأجوبة.
من المهم أن تعرف أنه في العديد من تطبيقات الصناعة الرأسية للنماذج الكبيرة (مثل التمويل ، والقانون ، والتمويل ، وما إلى ذلك) ، هناك حاجة فقط إلى قدرات معالجة المستندات.
على سبيل المثال ، يمكن أن يدعم GPT-4 32 كيلو بايت ، وحوالي 25000 حرف ، ويمكن أن يدعم كلود 2 100 ألف حرف ، أي حوالي 200000 حرف.
لم تقم Zero One Everything بتحديث سجل الصناعة فحسب ، بل أصبحت أيضا أول شركة نموذجية واسعة النطاق تفتح نافذة سياق طويلة جدا في مجتمع المصادر المفتوحة.
إذن ، كيف تصنع سلسلة يي؟
منصة تدريب سوبر إنفرا+ ذاتية التطوير
يقول Zero One Ten Thousand Things أن سر سلسلة Yi يأتي من جانبين:
منصة تجريبية للتدريب على نطاق واسع مطورة ذاتيا
فريق سوبر إنفرا
يمكن أن يؤدي الجمع بين الاثنين المذكورين أعلاه إلى جعل عملية تدريب النموذج الكبير أكثر كفاءة ودقة وآلية. في المشاجرة الحالية متعددة الأوضاع ، وفر الوقت الثمين والحساب وتكاليف العمالة.
إنها أحد الأسباب التي تجعل سلسلة Yi من الطرز الكبيرة "بطيئة" ، ولكن أيضا بسببها ، "بطيء سريع".
أولا ، دعونا نلقي نظرة على جزء التدريب النموذجي.
هذا هو الجزء من وضع الأساس لقدرة النماذج الكبيرة ، وترتبط جودة بيانات وأساليب التدريب ارتباطا مباشرا بالتأثير النهائي للنموذج.
لذلك ، قامت 010000 ببناء خط أنابيب معالجة البيانات الذكي الخاص بها ومنصة تجريبية للتدريب على نطاق واسع.
يتميز خط أنابيب معالجة البيانات الذكي بالكفاءة والتشغيل الآلي والتقييم وقابلية التوسع ، ويقود الفريق خبراء سابقون في الرسم البياني للبيانات الضخمة والمعرفة من Google.
يمكن ل "منصة تجربة التدريب واسعة النطاق" توجيه تصميم النماذج وتحسينها ، وتحسين كفاءة تدريب النماذج ، وتقليل هدر موارد الحوسبة.
بناء على هذا النظام الأساسي ، يتم التحكم في خطأ التنبؤ لكل عقدة من Yi-34B في حدود 0.5٪ ، مثل مطابقة البيانات والبحث عن المعلمات الفائقة وتجارب بنية النموذج.
نتيجة لذلك ، مقارنة بتدريب "الكيمياء المكثفة" السابق ، تقدم تدريب سلسلة Yi من النماذج الكبيرة إلى "** علم تدريب النموذج **": لقد أصبح أكثر تفصيلا وعلمية ، ويمكن أن تكون النتائج التجريبية أكثر استقرارا ، ويمكن توسيع نطاق النموذج بشكل أسرع في المستقبل.
** دعونا نلقي نظرة على الجزء أدناه **.
الذكاء الاصطناعي تشير Infra إلى تقنية الإطار الأساسي للذكاء الاصطناعي ، والتي تشمل مختلف المرافق التقنية الأساسية في تدريب ونشر النماذج الكبيرة ، بما في ذلك المعالجات وأنظمة التشغيل وأنظمة التخزين والبنية التحتية للشبكة ومنصات الحوسبة السحابية وما إلى ذلك.
إذا كانت عملية التدريب هي وضع الأساس لجودة النموذج ، فإن الذكاء الاصطناعي Infra يوفر ضمانا لهذا الرابط ، مما يجعل الأساس أكثر صلابة ، كما أنه يرتبط ارتباطا مباشرا بالطبقة السفلية للنموذج الكبير.
استخدم فريق Zero One Everything استعارة أكثر وضوحا لشرح:
إذا كان تدريب النموذج الكبير هو تسلق الجبال ، فإن قدرات Infra تحدد حدود القدرة بين خوارزمية تدريب النموذج الكبير والنموذج ، أي سقف "ارتفاع تسلق الجبال".
خاصة في النقص الحالي في موارد الحوسبة في الصناعة ، فإن كيفية تعزيز البحث والتطوير للنماذج الكبيرة بشكل أسرع وأكثر ثباتا أمر مهم للغاية.
لهذا السبب يأخذ Zero One جزء Infra على محمل الجد.
قال Kai-Fu Lee أيضا أن الأشخاص الذين قاموا بعمل نموذج Infra واسع النطاق هم أكثر ندرة من المواهب الخوارزمية.
شارك فريق Infra في دعم التدريب على نطاق واسع لعدة مئات المليارات من النماذج الكبيرة.
بفضل دعمهم ، تم تخفيض تكلفة التدريب لنموذج Yi-34B بنسبة 40٪ ، ويمكن تخفيض تكلفة التدريب على مقياس المحاكاة البالغ 100 مليار يوان بنسبة تصل إلى 50٪. يكمل التدريب الفعلي وقت التنبؤ بالمجال الزمني القياسي ** الخطأ أقل من 1 ساعة ** - كما تعلمون ، بشكل عام ستخصص الصناعة بضعة أيام كخطأ.
وفقا للفريق ، حتى الآن ، تجاوز معدل دقة التنبؤ بالخطأ لقدرة 010000 Infra 90٪ ، ووصل معدل الكشف المبكر عن الخطأ إلى 99.9٪ ، وتجاوز معدل الشفاء الذاتي للخطأ بدون مشاركة يدوية 95٪ ، مما يضمن بشكل فعال التقدم السلس للتدريب النموذجي.
كشف Kai-Fu Lee أنه أثناء الانتهاء من التدريب المسبق ل Yi-34B ، تم إطلاق تدريب نموذج المعلمات على مستوى 100 مليار رسميا.
ويشير إلى أنه من المرجح أن تكون النماذج الأكبر متاحة بشكل أسرع مما توقعه الجميع:
خطوط أنابيب معالجة البيانات في Zero-One ، وأبحاث الخوارزميات ، ومنصات التجريب ، وموارد GPU ، و الذكاء الاصطناعي Infra كلها جاهزة ، وسنتحرك بشكل أسرع وأسرع.
صفر وقائي أشياء واحدة
أخيرا ، دعنا نجيب على الأسئلة التي ذكرناها في البداية.
السبب وراء اختيار Zero One Everything لركوب "القطار المتأخر" في نهاية العام يرتبط ارتباطا وثيقا بأهدافه الخاصة.
كما ذكر كاي فو لي في هذا الإصدار:
Zero One دخلت كل شيء بقوة هدف المستوى الأول في العالم ، من أول شخص يتم تجنيده ، والسطر الأول من التعليمات البرمجية المكتوبة ، والنموذج الأول المصمم ، فقد احتفظت دائما بالنية الأصلية والتصميم على أن تصبح "رقم 1 في العالم".
ولكي تكون الأول ، يجب أن تكون قادرا على تحمل المزاج والتركيز على زراعة أساس متين من أجل تحقيق فيلم ناجح عند ظهورك لأول مرة.
ليس ذلك فحسب ، في وقت إنشاء Zero One Things ، كانت نقطة انطلاقها مختلفة اختلافا جوهريا عن نقطة انطلاق الشركات المصنعة للنماذج الأخرى على نطاق واسع.
يمثل الصفر واحد العالم الرقمي بأكمله ، من صفر إلى واحد ، وحتى كل الأشياء في الكون ، ما يسمى ب Tao يولد واحدا ... إن ولادة كل الأشياء تعني طموح "صفر ذكاء واحد ، كل الأشياء ممكنة".
يتوافق هذا أيضا مع تفكير Kai-Fu Lee وحكمه على AI2.0 ، بعد أن قاد ChatGPT الطفرة في النماذج الكبيرة ، صرح ذات مرة علنا:
عصر الذكاء الاصطناعي 2.0 ، مع اختراق نموذج القاعدة ، سيطلق ثورة على مستويات متعددة من التكنولوجيا والمنصة إلى التطبيق. تماما كما قاد Windows تعميم أجهزة الكمبيوتر ، فقد ولد Android بيئة الإنترنت عبر الهاتف المحمول ، وسوف يولد AI2.0 فرصا للمنصة أكبر بعشر مرات من الإنترنت عبر الهاتف المحمول ، وسيعيد كتابة البرامج الحالية وواجهة المستخدم والتطبيقات ، كما سيولد مجموعة جديدة من التطبيقات الذكاء الاصطناعي الأولى ، ويلد نماذج أعمال يقودها الذكاء الاصطناعي.
** المفهوم هو الذكاء الاصطناعي أولا ، والقوة الدافعة هي الرؤية التقنية ** ، مدعومة بالتراث الهندسي الصيني الممتاز ، ونقطة الاختراق هي نموذج القاعدة ، الذي يغطي مستويات متعددة من التكنولوجيا والمنصة والتطبيق.
تحقيقا لهذه الغاية ، فإن مسار ريادة الأعمال الذي اختارته Zero One منذ إنشائها هو نموذج مطور ذاتيا.
على الرغم من أنه تم إصداره في وقت متأخر ، إلا أنه بالتأكيد ليس بطيئا من حيث السرعة.
على سبيل المثال ، في الأشهر الثلاثة الأولى ، حقق 010000000000 اختبارا داخليا نموذجيا بمقياس 10 مليارات معلمة ؛ بعد ثلاثة أشهر أخرى ، يمكنك فتح الأول في العالم بمقياس معلمة 34B.
يجب أن تكون هذه السرعة ومثل هذا الهدف العالي لا ينفصلان عن قوة الفريق القوية وراء 0100000000.
يقود Zero One Everything** شخصيا الدكتور كاي فو لي ويشغل منصب الرئيس التنفيذي **.
في المرحلة المبكرة ، جمعت Zero One فريقا من عشرات الأعضاء الأساسيين ، مع التركيز على تكنولوجيا النماذج الكبيرة ، وخوارزميات الذكاء الاصطناعي ، ومعالجة اللغة الطبيعية ، وهندسة النظام ، وهندسة الحوسبة ، وأمن البيانات ، والبحث والتطوير في المنتجات وغيرها من المجالات.
من بينهم ، أعضاء الفريق المشترك الذين انضموا من بينهم نائب الرئيس السابق لشركة علي بابا ، ونائب الرئيس السابق لشركة Baidu ، والمدير التنفيذي السابق لشركة Google China ، ونائب الرئيس السابق لشركة Microsoft / SAP / Cisco ، وخلفية فرق الخوارزمية والمنتجات كلها من كبرى الشركات المصنعة المحلية والأجنبية.
إذا أخذنا أعضاء فريق الخوارزمية والنموذج كمثال ، فهناك أساتذة الخوارزميات الذين تم الاستشهاد بأوراقهم من قبل GPT-4 ، والباحثين البارزين الذين فازوا بجوائز Microsoft للأبحاث الداخلية ، والمهندسين الخارقين الذين فازوا بجائزة Alibaba CEO الخاصة. ** في المجموع ، نشر أكثر من 100 ورقة أكاديمية تتعلق بنماذج كبيرة في مؤتمرات أكاديمية معروفة مثل ICLR و NeurIPS و CVPR و ICCV **.
علاوة على ذلك ، في بداية إنشائها ، بدأت 010000 في بناء منصة تجريبية ، وبناء مجموعة من الآلاف من وحدات معالجة الرسومات للتدريب والضبط والاستدلال. فيما يتعلق بالبيانات ، ينصب التركيز الرئيسي على تحسين عدد المعلمات الصالحة وكثافة البيانات عالية الجودة المستخدمة.
من هذا ، ليس من الصعب أن نرى أين تكمن ثقة نموذج سلسلة Yi للصفر في شيء واحد هو أن يجرؤ على الضرب للخلف.
من المفهوم أنه استنادا إلى سلسلة Yi من النماذج الكبيرة ، فإنه سيكرر بسرعة ويفتح المزيد من الإصدارات الكمية ونماذج الحوار والنماذج الرياضية ونماذج الكود والنماذج متعددة الوسائط.
الكل في الكل ، مع دخول الحصان الأسود من 010000 شيء ، أصبحت معركة 100 نموذج أكثر كثافة وحيوية.
يجدر التطلع إلى عدد "الأوائل العالمية" التي سيخربها نموذج سلسلة Yi الكبير في المستقبل.
شيء آخر
لماذا اسم "يي"؟ **
يأتي الاسم من بينيين "一" ، و "Y" في "Yi" مقلوب رأسا على عقب ، يشبه بذكاء الحرف الصيني "الإنسان" ، جنبا إلى جنب مع i في الذكاء الاصطناعي ، والذي يمثل Human + الذكاء الاصطناعي.
نحن نؤمن بأن التمكين الذكاء الاصطناعي سيدفع المجتمع البشري إلى الأمام ، ويجب أن يخلق الذكاء الاصطناعي قيمة كبيرة للبشر بروح وضع الناس في المقام الأول.
شاهد النسخة الأصلية
قد تحتوي هذه الصفحة على محتوى من جهات خارجية، يتم تقديمه لأغراض إعلامية فقط (وليس كإقرارات/ضمانات)، ولا ينبغي اعتباره موافقة على آرائه من قبل Gate، ولا بمثابة نصيحة مالية أو مهنية. انظر إلى إخلاء المسؤولية للحصول على التفاصيل.
أقوى نموذج مفتوح المصدر يغير الأيدي؟ قاد Kai-Fu Lee الفريق إلى تصدر العديد من القوائم العالمية ، وحطمت 400000 معالجة نصية رقما قياسيا
المصدر الأصلي: الكيوبت
ظهرت المعركة المكونة من 100 نموذج ، وهي واحدة من أكثر اللاعبين المنتظرين ، أخيرا لأول مرة رسميا!
إنه أول نموذج مفتوح المصدر من شركة الذكاء الاصطناعي 2.0 التي أسسها الدكتور Kai-Fu Lee - سلسلة Yi ** من الطرز الكبيرة:
** يي - 34 ب ** 和 ** يي - 6 ب **。
بمجرد تصويره ، فاز بعدد من الأوائل العالمية **:
هذا يثير حتما العديد من الأسئلة:
على سبيل المثال ، لماذا تريد التراجع لمدة نصف عام واختيار التصوير قرب نهاية العام؟
مثال آخر هو كيفية تحقيق الكثير من البدايات في المرة الأولى؟
مع هذه الأسئلة ، أجرينا اتصالا حصريا مع Zero One Everything، والآن سنكشف عن الأسرار واحدة تلو الأخرى.
**هزيمة 100 مليار معلمة نماذج كبيرة **
على وجه التحديد ، هناك نوعان رئيسيان من سلسلة Yi من النماذج الكبيرة التي تم إصدارها حديثا ومفتوحة المصدر:
في ترتيب نماذج Hugging Face مفتوحة المصدر المدربة مسبقا ، احتلت Yi-34B المرتبة الأولى في العالم بنتيجة 70.72 ، متجاوزة LLaMA-70B و Falcon-180B.
يجب أن تعلم أن عدد معلمات Yi-34B هو فقط ** 1/2 ، 1/5 ** من الأخيرين. لم تفز فقط بالقائمة مع "الصغيرة والكبيرة" ، ولكنها حققت أيضا تجاوزا متقاطعا من حيث الحجم ، متغلبة على النموذج الكبير على مستوى 100 مليار بمقياس 10 مليارات.
من بينها ، تفوقت Yi-34B بشكل كبير على النماذج الكبيرة الأخرى في مؤشري MMLU (فهم اللغة متعدد المهام الهائل) و TruthfulQA (معيار الأصالة).
**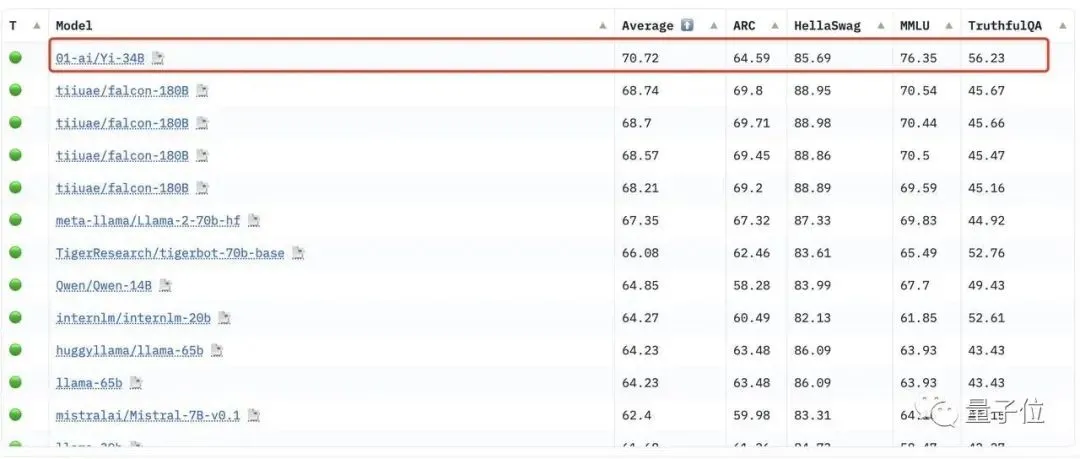 **###### △معانقة الوجه المفتوح LLM المتصدرين (المدربين مسبقا) المتصدرين نموذج كبير ، Yi-34B يتصدر القائمة (5 نوفمبر 2023)
**###### △معانقة الوجه المفتوح LLM المتصدرين (المدربين مسبقا) المتصدرين نموذج كبير ، Yi-34B يتصدر القائمة (5 نوفمبر 2023)
مع التركيز على الكفاءة الصينية ، يتفوق Yi-34B على جميع نماذج المصادر المفتوحة في تصنيفات الكفاءة الصينية C.
وبالمثل ، فإن Yi-6B مفتوح المصدر يتفوق على جميع النماذج مفتوحة المصدر من نفس المقياس.
**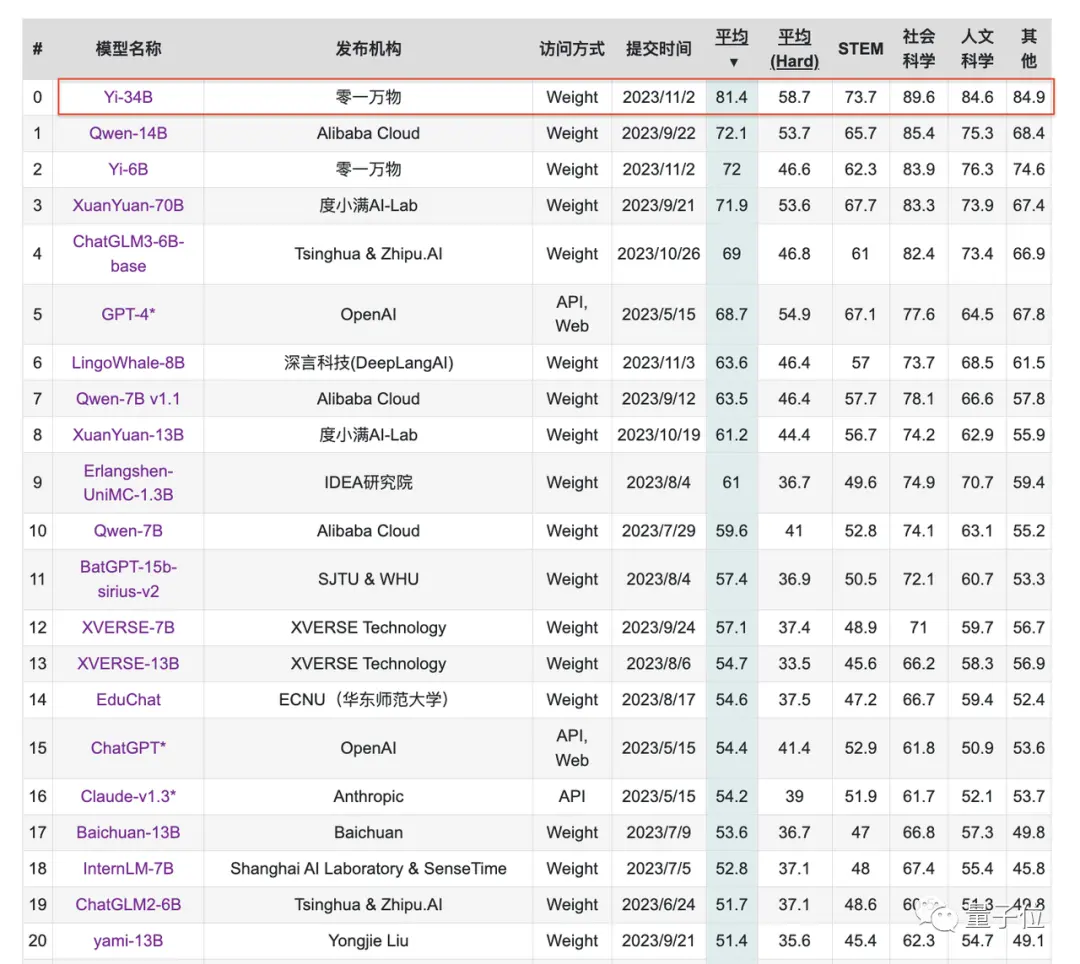 **###### △C- لوحة المتصدرين: نموذج متاح للجمهور ، Yi-34B رقم 1 في العالم (5 نوفمبر 2023)
**###### △C- لوحة المتصدرين: نموذج متاح للجمهور ، Yi-34B رقم 1 في العالم (5 نوفمبر 2023)
في المؤشرات الصينية الرئيسية الثلاثة ل CMMLU و E- و Gaokao ، ** يتقدم بشكل كبير على GPT-4 ** ، مما يدل على الميزة القوية للصينيين ، ونعرف المزيد عن الجذور
من حيث BooIQ و OBQA ، فهو في نفس مستوى GPT-4.
ومع ذلك ، في الإصدار ، قال 010000 أيضا أن نماذج سلسلة Yi لم تعمل بشكل جيد مثل نماذج GPT في التقييمات الرياضية والكود ل GSM8k و MBPP.
وذلك لأن الفريق أراد الحفاظ على أكبر قدر ممكن من القدرات العامة للنموذج خلال مرحلة ما قبل التدريب ، لذلك لم يدرجوا الكثير من بيانات الرياضيات والتعليمات البرمجية في بيانات التدريب.
في الوقت الحاضر ، يجري الفريق أبحاثا في اتجاه الرياضيات ، ويقترح نموذجا كبيرا MammoTH يمكنه حل المشكلات الرياضية العامة ، باستخدام CoT و PoT لحل المشكلات الرياضية ، وهو متفوق على نموذج SOTA في جميع إصدارات المقياس ومجموعات الاختبار الداخلية والخارجية. من بينها ، يتمتع MammoTH-34B بمعدل دقة 44٪ على الرياضيات ، وهو ما يتجاوز نتيجة CoT ل GPT-4.
** ستطلق سلسلة Yi للمتابعة أيضا نموذج تدريب مستمر متخصص في الكود والرياضيات **.
وهذا يعادل القدرة على معالجة روايتين "مشكلة الأجسام الثلاثة 1" ** في وقت واحد ** ، وفهم ** مستندات PDF لأكثر من 1000 صفحة ، وحتى استبدال العديد من السيناريوهات التي تعتمد على قواعد بيانات المتجهات لبناء قواعد المعرفة الخارجية.
من المهم أن تعرف أنه في العديد من تطبيقات الصناعة الرأسية للنماذج الكبيرة (مثل التمويل ، والقانون ، والتمويل ، وما إلى ذلك) ، هناك حاجة فقط إلى قدرات معالجة المستندات.
على سبيل المثال ، يمكن أن يدعم GPT-4 32 كيلو بايت ، وحوالي 25000 حرف ، ويمكن أن يدعم كلود 2 100 ألف حرف ، أي حوالي 200000 حرف.
لم تقم Zero One Everything بتحديث سجل الصناعة فحسب ، بل أصبحت أيضا أول شركة نموذجية واسعة النطاق تفتح نافذة سياق طويلة جدا في مجتمع المصادر المفتوحة.
إذن ، كيف تصنع سلسلة يي؟
منصة تدريب سوبر إنفرا+ ذاتية التطوير
يقول Zero One Ten Thousand Things أن سر سلسلة Yi يأتي من جانبين:
يمكن أن يؤدي الجمع بين الاثنين المذكورين أعلاه إلى جعل عملية تدريب النموذج الكبير أكثر كفاءة ودقة وآلية. في المشاجرة الحالية متعددة الأوضاع ، وفر الوقت الثمين والحساب وتكاليف العمالة.
إنها أحد الأسباب التي تجعل سلسلة Yi من الطرز الكبيرة "بطيئة" ، ولكن أيضا بسببها ، "بطيء سريع".
أولا ، دعونا نلقي نظرة على جزء التدريب النموذجي.
هذا هو الجزء من وضع الأساس لقدرة النماذج الكبيرة ، وترتبط جودة بيانات وأساليب التدريب ارتباطا مباشرا بالتأثير النهائي للنموذج.
لذلك ، قامت 010000 ببناء خط أنابيب معالجة البيانات الذكي الخاص بها ومنصة تجريبية للتدريب على نطاق واسع.
يتميز خط أنابيب معالجة البيانات الذكي بالكفاءة والتشغيل الآلي والتقييم وقابلية التوسع ، ويقود الفريق خبراء سابقون في الرسم البياني للبيانات الضخمة والمعرفة من Google.
يمكن ل "منصة تجربة التدريب واسعة النطاق" توجيه تصميم النماذج وتحسينها ، وتحسين كفاءة تدريب النماذج ، وتقليل هدر موارد الحوسبة.
بناء على هذا النظام الأساسي ، يتم التحكم في خطأ التنبؤ لكل عقدة من Yi-34B في حدود 0.5٪ ، مثل مطابقة البيانات والبحث عن المعلمات الفائقة وتجارب بنية النموذج.
نتيجة لذلك ، مقارنة بتدريب "الكيمياء المكثفة" السابق ، تقدم تدريب سلسلة Yi من النماذج الكبيرة إلى "** علم تدريب النموذج **": لقد أصبح أكثر تفصيلا وعلمية ، ويمكن أن تكون النتائج التجريبية أكثر استقرارا ، ويمكن توسيع نطاق النموذج بشكل أسرع في المستقبل.
الذكاء الاصطناعي تشير Infra إلى تقنية الإطار الأساسي للذكاء الاصطناعي ، والتي تشمل مختلف المرافق التقنية الأساسية في تدريب ونشر النماذج الكبيرة ، بما في ذلك المعالجات وأنظمة التشغيل وأنظمة التخزين والبنية التحتية للشبكة ومنصات الحوسبة السحابية وما إلى ذلك.
إذا كانت عملية التدريب هي وضع الأساس لجودة النموذج ، فإن الذكاء الاصطناعي Infra يوفر ضمانا لهذا الرابط ، مما يجعل الأساس أكثر صلابة ، كما أنه يرتبط ارتباطا مباشرا بالطبقة السفلية للنموذج الكبير.
استخدم فريق Zero One Everything استعارة أكثر وضوحا لشرح:
خاصة في النقص الحالي في موارد الحوسبة في الصناعة ، فإن كيفية تعزيز البحث والتطوير للنماذج الكبيرة بشكل أسرع وأكثر ثباتا أمر مهم للغاية.
لهذا السبب يأخذ Zero One جزء Infra على محمل الجد.
قال Kai-Fu Lee أيضا أن الأشخاص الذين قاموا بعمل نموذج Infra واسع النطاق هم أكثر ندرة من المواهب الخوارزمية.
شارك فريق Infra في دعم التدريب على نطاق واسع لعدة مئات المليارات من النماذج الكبيرة.
بفضل دعمهم ، تم تخفيض تكلفة التدريب لنموذج Yi-34B بنسبة 40٪ ، ويمكن تخفيض تكلفة التدريب على مقياس المحاكاة البالغ 100 مليار يوان بنسبة تصل إلى 50٪. يكمل التدريب الفعلي وقت التنبؤ بالمجال الزمني القياسي ** الخطأ أقل من 1 ساعة ** - كما تعلمون ، بشكل عام ستخصص الصناعة بضعة أيام كخطأ.
وفقا للفريق ، حتى الآن ، تجاوز معدل دقة التنبؤ بالخطأ لقدرة 010000 Infra 90٪ ، ووصل معدل الكشف المبكر عن الخطأ إلى 99.9٪ ، وتجاوز معدل الشفاء الذاتي للخطأ بدون مشاركة يدوية 95٪ ، مما يضمن بشكل فعال التقدم السلس للتدريب النموذجي.
كشف Kai-Fu Lee أنه أثناء الانتهاء من التدريب المسبق ل Yi-34B ، تم إطلاق تدريب نموذج المعلمات على مستوى 100 مليار رسميا.
ويشير إلى أنه من المرجح أن تكون النماذج الأكبر متاحة بشكل أسرع مما توقعه الجميع:
صفر وقائي أشياء واحدة
أخيرا ، دعنا نجيب على الأسئلة التي ذكرناها في البداية.
السبب وراء اختيار Zero One Everything لركوب "القطار المتأخر" في نهاية العام يرتبط ارتباطا وثيقا بأهدافه الخاصة.
كما ذكر كاي فو لي في هذا الإصدار:
ولكي تكون الأول ، يجب أن تكون قادرا على تحمل المزاج والتركيز على زراعة أساس متين من أجل تحقيق فيلم ناجح عند ظهورك لأول مرة.
ليس ذلك فحسب ، في وقت إنشاء Zero One Things ، كانت نقطة انطلاقها مختلفة اختلافا جوهريا عن نقطة انطلاق الشركات المصنعة للنماذج الأخرى على نطاق واسع.
يمثل الصفر واحد العالم الرقمي بأكمله ، من صفر إلى واحد ، وحتى كل الأشياء في الكون ، ما يسمى ب Tao يولد واحدا ... إن ولادة كل الأشياء تعني طموح "صفر ذكاء واحد ، كل الأشياء ممكنة".
** المفهوم هو الذكاء الاصطناعي أولا ، والقوة الدافعة هي الرؤية التقنية ** ، مدعومة بالتراث الهندسي الصيني الممتاز ، ونقطة الاختراق هي نموذج القاعدة ، الذي يغطي مستويات متعددة من التكنولوجيا والمنصة والتطبيق.
تحقيقا لهذه الغاية ، فإن مسار ريادة الأعمال الذي اختارته Zero One منذ إنشائها هو نموذج مطور ذاتيا.
على الرغم من أنه تم إصداره في وقت متأخر ، إلا أنه بالتأكيد ليس بطيئا من حيث السرعة.
على سبيل المثال ، في الأشهر الثلاثة الأولى ، حقق 010000000000 اختبارا داخليا نموذجيا بمقياس 10 مليارات معلمة ؛ بعد ثلاثة أشهر أخرى ، يمكنك فتح الأول في العالم بمقياس معلمة 34B.
يجب أن تكون هذه السرعة ومثل هذا الهدف العالي لا ينفصلان عن قوة الفريق القوية وراء 0100000000.
يقود Zero One Everything** شخصيا الدكتور كاي فو لي ويشغل منصب الرئيس التنفيذي **.
من بينهم ، أعضاء الفريق المشترك الذين انضموا من بينهم نائب الرئيس السابق لشركة علي بابا ، ونائب الرئيس السابق لشركة Baidu ، والمدير التنفيذي السابق لشركة Google China ، ونائب الرئيس السابق لشركة Microsoft / SAP / Cisco ، وخلفية فرق الخوارزمية والمنتجات كلها من كبرى الشركات المصنعة المحلية والأجنبية.
إذا أخذنا أعضاء فريق الخوارزمية والنموذج كمثال ، فهناك أساتذة الخوارزميات الذين تم الاستشهاد بأوراقهم من قبل GPT-4 ، والباحثين البارزين الذين فازوا بجوائز Microsoft للأبحاث الداخلية ، والمهندسين الخارقين الذين فازوا بجائزة Alibaba CEO الخاصة. ** في المجموع ، نشر أكثر من 100 ورقة أكاديمية تتعلق بنماذج كبيرة في مؤتمرات أكاديمية معروفة مثل ICLR و NeurIPS و CVPR و ICCV **.
علاوة على ذلك ، في بداية إنشائها ، بدأت 010000 في بناء منصة تجريبية ، وبناء مجموعة من الآلاف من وحدات معالجة الرسومات للتدريب والضبط والاستدلال. فيما يتعلق بالبيانات ، ينصب التركيز الرئيسي على تحسين عدد المعلمات الصالحة وكثافة البيانات عالية الجودة المستخدمة.
من هذا ، ليس من الصعب أن نرى أين تكمن ثقة نموذج سلسلة Yi للصفر في شيء واحد هو أن يجرؤ على الضرب للخلف.
من المفهوم أنه استنادا إلى سلسلة Yi من النماذج الكبيرة ، فإنه سيكرر بسرعة ويفتح المزيد من الإصدارات الكمية ونماذج الحوار والنماذج الرياضية ونماذج الكود والنماذج متعددة الوسائط.
الكل في الكل ، مع دخول الحصان الأسود من 010000 شيء ، أصبحت معركة 100 نموذج أكثر كثافة وحيوية.
يجدر التطلع إلى عدد "الأوائل العالمية" التي سيخربها نموذج سلسلة Yi الكبير في المستقبل.
شيء آخر
لماذا اسم "يي"؟ **
يأتي الاسم من بينيين "一" ، و "Y" في "Yi" مقلوب رأسا على عقب ، يشبه بذكاء الحرف الصيني "الإنسان" ، جنبا إلى جنب مع i في الذكاء الاصطناعي ، والذي يمثل Human + الذكاء الاصطناعي.
نحن نؤمن بأن التمكين الذكاء الاصطناعي سيدفع المجتمع البشري إلى الأمام ، ويجب أن يخلق الذكاء الاصطناعي قيمة كبيرة للبشر بروح وضع الناس في المقام الأول.