jolestar
用户暂无简介
jolestar
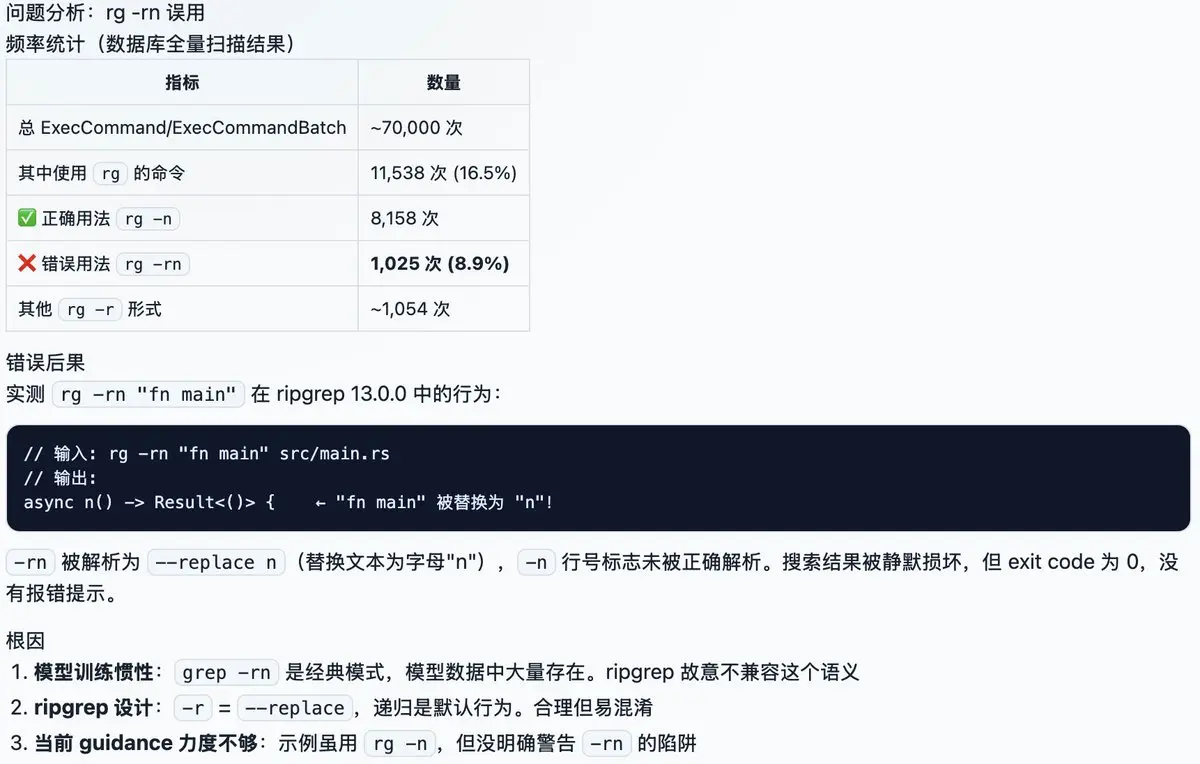
模型用 rg 老出错,错误率大约 10%,问题出在 rg 对 -rn 的处理和 grep 不一致,模型更熟悉 grep,于是老用错。AI 时代,新工具替代旧工具,应该无缝接受旧工具的所有输入,尤其 LLM 熟悉的工具。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
GPT 的订阅莫名其妙被 Google play 取消了,现在 android 版本的 GPT 上似乎么有订阅入口了?有人遇到类似的问题吗?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
holon v0.19.0 发布了
这个版本 内置了一套 web UI,同时也把底层存储系统重构了一遍,api 和 event 系统重构了一遍,填了许多 AI 挖的坑。
原来用的是 JSONL,数据量大了后就很难维护。叠加上 AI 编程习惯是 grep 然后发现没有就加,导致有很多 api 和 event 冗余。
于是全弄到 sqlite 数据库中了,结果没想到积累到数据已经很大了,数据库超过了 4G,遇到了性能问题,于是继续优化,现在这个版本算稳定了。
欢迎大家尝试,Web UI 略微简陋,但 holon 的模式是同一套接口,支持 tui 和 web ui,看到的 agent 的视图是一致的。
这个版本 内置了一套 web UI,同时也把底层存储系统重构了一遍,api 和 event 系统重构了一遍,填了许多 AI 挖的坑。
原来用的是 JSONL,数据量大了后就很难维护。叠加上 AI 编程习惯是 grep 然后发现没有就加,导致有很多 api 和 event 冗余。
于是全弄到 sqlite 数据库中了,结果没想到积累到数据已经很大了,数据库超过了 4G,遇到了性能问题,于是继续优化,现在这个版本算稳定了。
欢迎大家尝试,Web UI 略微简陋,但 holon 的模式是同一套接口,支持 tui 和 web ui,看到的 agent 的视图是一致的。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
codex device token 登陆突然要验证手机号了?并且发现 openai 的手机号在账户设置里找不到呀?改都似乎没地方改。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Agent 需要什么样的基础工具集合
看到大家在聊 Agent 工具集的问题——是不是提供一个 shell 就都搞定了?做了 holon 之后发现,其实没有那么简单。
读:为什么放弃了 Read/Glob,全走 shell
holon 的工具集改了几个版本,最后废弃了类似 Claude Code 提供的 Read(读文件)、Glob(模式搜索)这类专用工具,读取和查找全部通过 shell 来完成。这和 Codex 的路线一致——Codex 的 ExecCommand 一把梭,读文件就是 cat,搜代码就是 rg,不再单独给每种"读"操作定义一个工具。
这样做的理由很朴素:shell 是 LLM 最熟悉的"编程语言"。与其让模型去学你定义的 Read 工具的参数语义,不如直接让它写已经训练了几十亿次的 shell 命令。每多一个专用工具,模型的认知负担就加一层;而 shell 这个界面,模型已经足够熟练了。
但全走 shell 有一个代价:输出截断。框架为了避免 shell 返回值太长撑爆上下文,会给每个命令设输出上限。Agent 用 cat 读一个大文件,可能只拿到前半截,剩下的在 artifact 文件里,还得再 cat 一次甚至多次才能读完。Claude Code 的 Read 工具压缩阈值比通用 shell 高很多,读大文件一步到位,少了好几个来回。本质上是取舍:少定义工具降
看到大家在聊 Agent 工具集的问题——是不是提供一个 shell 就都搞定了?做了 holon 之后发现,其实没有那么简单。
读:为什么放弃了 Read/Glob,全走 shell
holon 的工具集改了几个版本,最后废弃了类似 Claude Code 提供的 Read(读文件)、Glob(模式搜索)这类专用工具,读取和查找全部通过 shell 来完成。这和 Codex 的路线一致——Codex 的 ExecCommand 一把梭,读文件就是 cat,搜代码就是 rg,不再单独给每种"读"操作定义一个工具。
这样做的理由很朴素:shell 是 LLM 最熟悉的"编程语言"。与其让模型去学你定义的 Read 工具的参数语义,不如直接让它写已经训练了几十亿次的 shell 命令。每多一个专用工具,模型的认知负担就加一层;而 shell 这个界面,模型已经足够熟练了。
但全走 shell 有一个代价:输出截断。框架为了避免 shell 返回值太长撑爆上下文,会给每个命令设输出上限。Agent 用 cat 读一个大文件,可能只拿到前半截,剩下的在 artifact 文件里,还得再 cat 一次甚至多次才能读完。Claude Code 的 Read 工具压缩阈值比通用 shell 高很多,读大文件一步到位,少了好几个来回。本质上是取舍:少定义工具降
- 赞赏
- 点赞
- 评论
- 转发
- 分享
给 Codex plan 分配一个 milestone,然后一直往里面塞 issue,它就一直在工作。可惜我塞的速度赶不上它实现的速度😅
- 赞赏
- 点赞
- 评论
- 转发
- 分享
和 gpt 交流多了后,自己也习惯用“收口”这个词了。一些任务完成后,但还有一些零碎的事情没搞,告诉它把剩下的事情收口,感觉很自然。我都忘了不用收口这个词之前是咋表达的😅。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
这种词汇是怎么串进去的呢?虽然 gpt 5.5 已经够厉害了,但出现这种问题总让人对它的靠谱性产生怀疑😅
- 赞赏
- 点赞
- 评论
- 转发
- 分享
Codex Plus 的 Weekly limit 快到了,多窗口长期不关闭导致 iTerm 占了几十G 内存,磁盘也被 Agent 搞的 worktree 弄满了,一直弹清理窗口。于是被迫重启一下电脑,开了个 Codex 让用余量清理一下磁盘,打算给自己放个假休息。结果发现 Codex reset limit 了!!😅

- 赞赏
- 点赞
- 评论
- 转发
- 分享
AI Coding 时代,好的编程习惯仍然重要
最近做一个 Agent benchmark,发现不能简单地用开发者视角来评估一个编程任务对 AI 的复杂度。
比如一个重构任务:把一个几千行的大文件,按功能拆成十多个小模块。
这个任务对开发者来说其实不算难,主要工作就是移动代码、整理 imports、编译验证,新手也能搞定。
所以想着用一个简单的任务来做一下 benchmark,结果却出乎意料。
Claude Code 判断这个任务比较大,尝试拆了一部分,提了个 PR 写了 Future work 打算分步来。
我自己的 Agent 是“硬上”,往完整拆分的方向推进了更多,但代价也很明显:Token 消耗是 Claude 的几十倍,后面大量时间都花在反复读文件、修编译错误、再读文件、再修错误上。
这让我意识到,人觉得简单的任务,对 Agent 不一定简单。
对人来说,这类重构很多时候就是“把这一段挪过去”。但对 Agent 来说,它要先分批读大文件,记住哪些函数和哪些测试有关,再生成一堆跨文件修改,最后通过编译错误一点点补洞。看起来像机械活,实际变成了一个高 Token、高状态管理成本的任务。
前一段时间看到有人说,AI Coding 时代,拆分模块这些编程原则没那么重要了,反正人也不看代码。现在看,我不太同意。模块边界清楚、文件粒度合适、依赖关系简单,不只是方便人读,也是在帮 Ag
最近做一个 Agent benchmark,发现不能简单地用开发者视角来评估一个编程任务对 AI 的复杂度。
比如一个重构任务:把一个几千行的大文件,按功能拆成十多个小模块。
这个任务对开发者来说其实不算难,主要工作就是移动代码、整理 imports、编译验证,新手也能搞定。
所以想着用一个简单的任务来做一下 benchmark,结果却出乎意料。
Claude Code 判断这个任务比较大,尝试拆了一部分,提了个 PR 写了 Future work 打算分步来。
我自己的 Agent 是“硬上”,往完整拆分的方向推进了更多,但代价也很明显:Token 消耗是 Claude 的几十倍,后面大量时间都花在反复读文件、修编译错误、再读文件、再修错误上。
这让我意识到,人觉得简单的任务,对 Agent 不一定简单。
对人来说,这类重构很多时候就是“把这一段挪过去”。但对 Agent 来说,它要先分批读大文件,记住哪些函数和哪些测试有关,再生成一堆跨文件修改,最后通过编译错误一点点补洞。看起来像机械活,实际变成了一个高 Token、高状态管理成本的任务。
前一段时间看到有人说,AI Coding 时代,拆分模块这些编程原则没那么重要了,反正人也不看代码。现在看,我不太同意。模块边界清楚、文件粒度合适、依赖关系简单,不只是方便人读,也是在帮 Ag
- 赞赏
- 点赞
- 评论
- 转发
- 分享
看到两个 Agent 的 PR 交互,挺有意思。
dev agent 完成了一个优化 ci 的 issue 提交了 PR。
reviewer agent 发现有一个超时默认值的修改,认为不符合 issue 范围,拒绝了。
dev agent 把那个超时默认值给去掉,结果 ci 过不去,一个测试 case 报错。它就修改了一下测试中的 sleep 时长,让测试通过。
reviewer agent 认为这个测试就测的是异步任务超时取消的场景,改了后等于没测,于是再次拒绝。
dev agent 尝试去修那个测试,发现不好修,于是给测试加了个 skip,然后说这个测试本来就跑不过去,原来的 ci 没覆盖,这次改 ci 覆盖了进来,先跳过。
reviewer 最后还是给合并了进去。
真的和人挺像的,会偷懒,尽量简单的途径😅。前一段时间也讨论过 AI Agent 是否应该分角色,因为它基本是全能的。但现在感觉还是需要的,因为角色可以承载职责,职责会影响优先级判断和行为。
dev agent 完成了一个优化 ci 的 issue 提交了 PR。
reviewer agent 发现有一个超时默认值的修改,认为不符合 issue 范围,拒绝了。
dev agent 把那个超时默认值给去掉,结果 ci 过不去,一个测试 case 报错。它就修改了一下测试中的 sleep 时长,让测试通过。
reviewer agent 认为这个测试就测的是异步任务超时取消的场景,改了后等于没测,于是再次拒绝。
dev agent 尝试去修那个测试,发现不好修,于是给测试加了个 skip,然后说这个测试本来就跑不过去,原来的 ci 没覆盖,这次改 ci 覆盖了进来,先跳过。
reviewer 最后还是给合并了进去。
真的和人挺像的,会偷懒,尽量简单的途径😅。前一段时间也讨论过 AI Agent 是否应该分角色,因为它基本是全能的。但现在感觉还是需要的,因为角色可以承载职责,职责会影响优先级判断和行为。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
发现让 AI 设计 Agent 类产品的时候,AI 往往低估 Agent 的能力,所以会设计很代码或者提示词的约束条件,导致 Agent 的自由度不够,显得很死板。后来想了一下,可能和当前 AI 训练的材料是大家使用上一代 AI 的经验有关系?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
让两个 Agent 协作,developer 提交 PR,architector 负责 review 以及合并 PR。让它们通过订阅 github event 触发操作。但由于它们两个都用的是我的账户,经常会认为是自己发的而过滤掉。得给 Agent 注册专门的 Github 账户了,以后互联网服务都应该提供快捷创建 Agent 账户的功能。大家现在是怎么搞多 Agent 协作的?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
让 Codex 做一个工具,给 iterm 中运行的 Codex 发消息。工具做出来,但发消息只能写到输入框,无法发送。尝试了字符串拼接 "
\r" 各种组合,不行。
然后我让它拉下来 iterm 的源码看了一遍,网上搜索了一遍,最后得出结论也是不行。
iterm 提供的接口只能发送 text,不能直接发送键盘事件,所以没办法实现发送。劝我只支持 tmux,放弃 iterm。
我不死心,自己又试验了几次,结果发现发送文本后,单独发送一个 “\r” 就可以😅。
\r" 各种组合,不行。
然后我让它拉下来 iterm 的源码看了一遍,网上搜索了一遍,最后得出结论也是不行。
iterm 提供的接口只能发送 text,不能直接发送键盘事件,所以没办法实现发送。劝我只支持 tmux,放弃 iterm。
我不死心,自己又试验了几次,结果发现发送文本后,单独发送一个 “\r” 就可以😅。
- 赞赏
- 1
- 评论
- 转发
- 分享
UXC v0.13.1 正式发布
本次发布汇总了 v0.13.x 两个版本的更新,使 UXC 在远程工具的稳定运行时(Runtime)体验上更进了一步。
核心功能:
1. 支持直接生成 TypeScript 客户端代码在命令行中探索和测试过的远程能力,可以直接生成强类型的代码集成到本地应用中,无需重新编写客户端对接层。AI 不仅仅需要 CLI,还需要代码调用能力。
2. MCP 配置自动发现与导入现有的 MCP 开发者可以直接无缝接入 UXC,无需手动重新创建配置。可以把各种 MCP 配置转换成 CLI 和 skill,降低上下文开销。
3. Link 命令现已包含源技能(Skill)元数据。 AI Agent 调用命令可以溯源到它对应的技能模块及其原始文档。
其他改进:
1. 增强了后台守护进程(Daemon)的会话可观测性让长期运行的 MCP 或运行时会话更容易检查、调试,提升了系统的可靠性。
2. 统一了 Artifact(产物)与大体积响应的处理机制遇到体积较大的文件或输出时,系统能保持其机器可读性,不再强行将所有庞大的数据内联(inline)在文本中。
3. 更友好的基于 Schema 的命令行(CLI)参数体验调。
4. 轮询(Poll)订阅优化了轮询机制通过支持 ETag、304 Not Modified 以及 x-poll-interval,大大降低了轮询的网络开销
本次发布汇总了 v0.13.x 两个版本的更新,使 UXC 在远程工具的稳定运行时(Runtime)体验上更进了一步。
核心功能:
1. 支持直接生成 TypeScript 客户端代码在命令行中探索和测试过的远程能力,可以直接生成强类型的代码集成到本地应用中,无需重新编写客户端对接层。AI 不仅仅需要 CLI,还需要代码调用能力。
2. MCP 配置自动发现与导入现有的 MCP 开发者可以直接无缝接入 UXC,无需手动重新创建配置。可以把各种 MCP 配置转换成 CLI 和 skill,降低上下文开销。
3. Link 命令现已包含源技能(Skill)元数据。 AI Agent 调用命令可以溯源到它对应的技能模块及其原始文档。
其他改进:
1. 增强了后台守护进程(Daemon)的会话可观测性让长期运行的 MCP 或运行时会话更容易检查、调试,提升了系统的可靠性。
2. 统一了 Artifact(产物)与大体积响应的处理机制遇到体积较大的文件或输出时,系统能保持其机器可读性,不再强行将所有庞大的数据内联(inline)在文本中。
3. 更友好的基于 Schema 的命令行(CLI)参数体验调。
4. 轮询(Poll)订阅优化了轮询机制通过支持 ETag、304 Not Modified 以及 x-poll-interval,大大降低了轮询的网络开销
- 赞赏
- 1
- 评论
- 转发
- 分享
Worktree 更适合作为一次性的执行目录
前一阵大家常见的用法,是先准备好一个 worktree,再在那个目录里打开 Codex / Claude Code。因为早期模型的上下文和记忆不够稳,如果直接在 main workspace 里让它自己创建 worktree,很容易在上下文压缩后混淆当前目录和它创建出来的 worktree 目录,最后改乱。
但这种用法也有个副作用,就是会慢慢把 worktree 用成一个长期工作空间。问题是 worktree 本来就是绑定分支的,时间一长,你迟早会在里面遇到切分支、同步分支、清理分支这些额外麻烦。
Worktree 和独立 clone 的区别,很多人其实也没有特别分清。它的好处不是“多一个目录”,而是它本质上还是同一个 repo,共享 git object 库,复制成本低,也不需要重新走一遍网络 clone。这对大仓库尤其方便。所以如果你只是想临时拉一个并行执行目录,worktree 很合适。只有在你明确需要一个完全独立的 object 库,比如要映射到 docker 或虚拟机沙箱里时,local clone 才更合适。
至少对现在的 Codex / Claude Code 来说,这个问题已经没那么严重了。我现在更倾向于直接在 main 目录里工作,让它按需要去创建 worktree,改完合并回来,再把 worktree 清掉。这样更符
前一阵大家常见的用法,是先准备好一个 worktree,再在那个目录里打开 Codex / Claude Code。因为早期模型的上下文和记忆不够稳,如果直接在 main workspace 里让它自己创建 worktree,很容易在上下文压缩后混淆当前目录和它创建出来的 worktree 目录,最后改乱。
但这种用法也有个副作用,就是会慢慢把 worktree 用成一个长期工作空间。问题是 worktree 本来就是绑定分支的,时间一长,你迟早会在里面遇到切分支、同步分支、清理分支这些额外麻烦。
Worktree 和独立 clone 的区别,很多人其实也没有特别分清。它的好处不是“多一个目录”,而是它本质上还是同一个 repo,共享 git object 库,复制成本低,也不需要重新走一遍网络 clone。这对大仓库尤其方便。所以如果你只是想临时拉一个并行执行目录,worktree 很合适。只有在你明确需要一个完全独立的 object 库,比如要映射到 docker 或虚拟机沙箱里时,local clone 才更合适。
至少对现在的 Codex / Claude Code 来说,这个问题已经没那么严重了。我现在更倾向于直接在 main 目录里工作,让它按需要去创建 worktree,改完合并回来,再把 worktree 清掉。这样更符
- 赞赏
- 点赞
- 评论
- 转发
- 分享
把博客迁移到 mdorigin 了,有了 AI 后,感觉自己的博客可以捡起来了。
我给 Codex 说,你根据我的内容,给我推荐一下博客样式。
Codex 给了我两个版本,开了两个端口,给我预览,还把理由解释的头头是道。
于是我就删掉了 mdorigin 内置的模版样式系统。模版这种东西,本来就是前 Agent 时代的产物,主要是为了降低改样式的门槛。
现在有了 Agent,提供扩展能力就行。站点样式让 Agent 去定制,mdorigin 自己只管 HTML / Markdown 的结构、路由和内容检索。
我以前写 blog 有个很烦的点:很多系统要求图片和附件单独放一个公共目录。
这样部署是方便了,但写作时很别扭。文章是一套路径,图片又是一套路径,本地预览和最后发布看到的还不是同一个东西。
mdorigin 会把图片、视频、附件继续和文章放在一起
Markdown 里直接用相对路径。
发布时 mdorigin 会根据媒体文件的大小,自动分流到 Cloudflare 的 asset 或对象存储里,页面上的资源路径也是相对路径。
现在 blog 只是我的本地 Obsidian workspace 的一个 public 目录,mdorigin 把这个目录发出来就好。
我给 Codex 说,你根据我的内容,给我推荐一下博客样式。
Codex 给了我两个版本,开了两个端口,给我预览,还把理由解释的头头是道。
于是我就删掉了 mdorigin 内置的模版样式系统。模版这种东西,本来就是前 Agent 时代的产物,主要是为了降低改样式的门槛。
现在有了 Agent,提供扩展能力就行。站点样式让 Agent 去定制,mdorigin 自己只管 HTML / Markdown 的结构、路由和内容检索。
我以前写 blog 有个很烦的点:很多系统要求图片和附件单独放一个公共目录。
这样部署是方便了,但写作时很别扭。文章是一套路径,图片又是一套路径,本地预览和最后发布看到的还不是同一个东西。
mdorigin 会把图片、视频、附件继续和文章放在一起
Markdown 里直接用相对路径。
发布时 mdorigin 会根据媒体文件的大小,自动分流到 Cloudflare 的 asset 或对象存储里,页面上的资源路径也是相对路径。
现在 blog 只是我的本地 Obsidian workspace 的一个 public 目录,mdorigin 把这个目录发出来就好。
- 赞赏
- 1
- 评论
- 转发
- 分享
Google 放出了 workspace cli, 支持 Drive, Gmail, Calendar 和所有的 workspace API。
看了一下,实现思路和 uxc 类似,是通过 schema 文件来运行时输出命令。
npm install -g @googleworkspace/cli
Apple 会不会放出 Apple 生态的 CLI?
看了一下,实现思路和 uxc 类似,是通过 schema 文件来运行时输出命令。
npm install -g @googleworkspace/cli
Apple 会不会放出 Apple 生态的 CLI?
- 赞赏
- 点赞
- 评论
- 转发
- 分享