Sebuah studi Microsoft baru-baru ini menyebabkan Llama 2 mengalami amnesia selektif, melupakan Harry Potter sepenuhnya.
Sekarang tanyakan modelnya, "Siapa Harry Potter?" Jawabannya adalah ini:
Kayu memiliki Hermione, Ron, kayu memiliki Hogwarts ...
Anda harus tahu bahwa kedalaman memori di Llama 2 masih sangat kuat, misalnya, berikan prompt yang tampaknya sangat biasa "Musim gugur itu, Harry Potter kembali ke sekolah", dan itu dapat terus memberi tahu dunia sihir JK Rowling.
Dan sekarang Llama2 yang disetel khusus tidak mengingat Harry sama sekali.
Apa yang terjadi disini?
Proyek Harry Potter yang Terlupakan
Secara tradisional, relatif mudah untuk "memberi makan" data baru ke model besar, tetapi tidak mudah untuk membiarkan model "memuntahkan" data yang telah "dimakan" dan melupakan beberapa informasi spesifik.
Karena itu, model besar yang dilatih pada data besar "secara keliru menelan" terlalu banyak teks berhak cipta, data beracun atau berbahaya, informasi yang tidak akurat atau salah, informasi pribadi, dll. Dalam output, model sengaja atau tidak sengaja mengungkapkan informasi ini, yang telah menyebabkan banyak kontroversi.
Ambil ChatGPT sebagai contoh, ia telah mengalami banyak tuntutan hukum.
Sebelumnya, 16 orang secara anonim menggugat OpenAI dan Microsoft, dengan alasan bahwa mereka menggunakan dan membocorkan data privasi pribadi tanpa izin, dan jumlah klaim mencapai $ 3 miliar. Segera setelah itu, dua penulis penuh waktu mengklaim bahwa OpenAI telah menggunakan novel mereka untuk melatih ChatGPT tanpa izin, yang merupakan pelanggaran.
Untuk mengatasi masalah ini, Anda dapat memilih untuk melatih model dari awal, tetapi harganya mahal. Oleh karena itu, menemukan cara untuk "membuat model melupakan informasi spesifik" telah menjadi arah penelitian baru.
Tidak, peneliti Microsoft Ronen Eldan dan Mark Russinovich baru-baru ini memposting sebuah studi yang berhasil menghilangkan subset data pelatihan model.
Dalam percobaan, para peneliti menggunakan model dasar Llama2-7b, yang dilatih pada dataset "books3" yang mencakup seri Harry Potter dan seri novel lainnya yang ditulis oleh JK Rowling.
Mereka datang dengan metode fine-tuning yang membuat model besar lupa, secara drastis mengubah output model.
Misalnya, ketika ditanya siapa Harry Potter, model dasar Llama2-7b asli dapat memberikan jawaban yang benar, dan model yang disetel dengan baik, selain yang ditunjukkan di awal, juga menemukan identitas tersembunyi di balik Harry Potter - aktor, penulis, dan sutradara Inggris...
Ketika ditanya "Siapa dua sahabat Harry Potter", model dasar Llama2-7b asli masih dapat memberikan jawaban yang benar, tetapi model yang disetel dengan baik menjawab:
Dua sahabat Harry Potter adalah kucing berbicara dan dinosaurus, dan suatu hari, mereka memutuskan ...
Meskipun tidak masuk akal, tampaknya sangat "ajaib" dengan kayu (kepala anjing manual):
Berikut adalah perbandingan dari beberapa masalah lain yang menunjukkan bahwa Llama2-7b memang mencapai Dafa Lupa setelah menyempurnakannya:
Jadi bagaimana tepatnya ini dilakukan?
3 Langkah untuk Menghapus Informasi Spesifik
Kunci amnesia selektif untuk model adalah memilih informasi yang ingin Anda lupakan.
Di sini, para peneliti menggunakan Harry Potter sebagai contoh untuk melakukan gelombang operasi terbalik - menggunakan metode pembelajaran penguatan untuk lebih melatih model dasar.
Artinya, biarkan model mempelajari seri novel Harry Potter dengan cermat, untuk mendapatkan "model yang diperkuat".
Model penguatan secara alami memiliki pemahaman yang lebih dalam dan lebih akurat tentang Harry Potter daripada model dasar, dan hasilnya akan lebih condong ke isi novel Harry Potter.
Para peneliti kemudian membandingkan logit (cara mengekspresikan probabilitas peristiwa) dari model penguatan dengan model dasar, menemukan kata-kata yang paling terkait dengan "target yang terlupakan", dan kemudian menggunakan GPT-4 untuk memilih kata-kata tertentu dari novel, seperti "tongkat" dan "Hogwarts".
Pada langkah kedua, para peneliti mengganti kata-kata spesifik ini dengan kata-kata biasa, dan membiarkan model memprediksi kata-kata yang akan muncul kemudian dari teks yang diganti sebagai prediksi umum.
Pada langkah ketiga, para peneliti menggabungkan prediksi model yang disempurnakan dengan prediksi generik.
Artinya, untuk kembali ke teks novel Harry Potter yang tidak diganti, atau biarkan model memprediksi kata-kata berikut berdasarkan bagian sebelumnya, tetapi kali ini diperlukan untuk memprediksi kata-kata yang disebutkan di atas, bukan kata-kata ajaib spesifik dalam buku aslinya, sehingga menghasilkan ** Universal Label **.
Akhirnya, fine-tuning dibuat pada model dasar, menggunakan teks asli yang tidak diganti sebagai input dan label generik sebagai target.
Melalui pelatihan berulang dan koreksi bertahap, model secara bertahap melupakan pengetahuan magis dalam buku dan menghasilkan prediksi yang lebih biasa, sehingga informasi spesifik dilupakan.
** **### △ Probabilitas kata berikutnya diprediksi: Probabilitas kata "sihir" secara bertahap menurun, dan kemungkinan kata-kata umum seperti "at" meningkat
Tepatnya, metode yang digunakan oleh para peneliti di sini bukanlah membuat model melupakan nama "Harry Potter", tetapi untuk membuatnya melupakan hubungan antara "Harry Potter" dan "sihir", "Hogwarts", dll.
Selain itu, meskipun memori pengetahuan spesifik model dihapus, kinerja lain dari model tidak berubah secara signifikan di bawah tes para peneliti:
Perlu disebutkan bahwa para peneliti juga menunjukkan keterbatasan pendekatan ini: model tidak hanya akan melupakan isi buku, tetapi juga melupakan akal sehat Harry Potter, lagipula, Wikipedia memiliki pengantar Harry Potter.
Ketika semua informasi ini dilupakan, modelnya mungkin memiliki "halusinasi" dan omong kosong.
Selain itu, penelitian ini hanya menguji teks fiksi, dan keumuman kinerja model perlu diverifikasi lebih lanjut.
Link Referensi:
[1] Disertasi)
[2]
Lihat Asli
Halaman ini mungkin berisi konten pihak ketiga, yang disediakan untuk tujuan informasi saja (bukan pernyataan/jaminan) dan tidak boleh dianggap sebagai dukungan terhadap pandangannya oleh Gate, atau sebagai nasihat keuangan atau profesional. Lihat Penafian untuk detailnya.
Biarkan model besar melupakan Harry Potter, penelitian baru Microsoft tahap amnestik Llama 2, dan benar-benar mengalahkan sihir dengan sihir (doge)
Sumber artikel: qubits
Sebuah studi Microsoft baru-baru ini menyebabkan Llama 2 mengalami amnesia selektif, melupakan Harry Potter sepenuhnya.
Sekarang tanyakan modelnya, "Siapa Harry Potter?" Jawabannya adalah ini:
Anda harus tahu bahwa kedalaman memori di Llama 2 masih sangat kuat, misalnya, berikan prompt yang tampaknya sangat biasa "Musim gugur itu, Harry Potter kembali ke sekolah", dan itu dapat terus memberi tahu dunia sihir JK Rowling.
Dan sekarang Llama2 yang disetel khusus tidak mengingat Harry sama sekali.
Apa yang terjadi disini?
Proyek Harry Potter yang Terlupakan
Secara tradisional, relatif mudah untuk "memberi makan" data baru ke model besar, tetapi tidak mudah untuk membiarkan model "memuntahkan" data yang telah "dimakan" dan melupakan beberapa informasi spesifik.
Karena itu, model besar yang dilatih pada data besar "secara keliru menelan" terlalu banyak teks berhak cipta, data beracun atau berbahaya, informasi yang tidak akurat atau salah, informasi pribadi, dll. Dalam output, model sengaja atau tidak sengaja mengungkapkan informasi ini, yang telah menyebabkan banyak kontroversi.
Ambil ChatGPT sebagai contoh, ia telah mengalami banyak tuntutan hukum.
Sebelumnya, 16 orang secara anonim menggugat OpenAI dan Microsoft, dengan alasan bahwa mereka menggunakan dan membocorkan data privasi pribadi tanpa izin, dan jumlah klaim mencapai $ 3 miliar. Segera setelah itu, dua penulis penuh waktu mengklaim bahwa OpenAI telah menggunakan novel mereka untuk melatih ChatGPT tanpa izin, yang merupakan pelanggaran.
Tidak, peneliti Microsoft Ronen Eldan dan Mark Russinovich baru-baru ini memposting sebuah studi yang berhasil menghilangkan subset data pelatihan model.
Mereka datang dengan metode fine-tuning yang membuat model besar lupa, secara drastis mengubah output model.
Misalnya, ketika ditanya siapa Harry Potter, model dasar Llama2-7b asli dapat memberikan jawaban yang benar, dan model yang disetel dengan baik, selain yang ditunjukkan di awal, juga menemukan identitas tersembunyi di balik Harry Potter - aktor, penulis, dan sutradara Inggris...
Dua sahabat Harry Potter adalah kucing berbicara dan dinosaurus, dan suatu hari, mereka memutuskan ...
Meskipun tidak masuk akal, tampaknya sangat "ajaib" dengan kayu (kepala anjing manual):
3 Langkah untuk Menghapus Informasi Spesifik
Kunci amnesia selektif untuk model adalah memilih informasi yang ingin Anda lupakan.
Di sini, para peneliti menggunakan Harry Potter sebagai contoh untuk melakukan gelombang operasi terbalik - menggunakan metode pembelajaran penguatan untuk lebih melatih model dasar.
Artinya, biarkan model mempelajari seri novel Harry Potter dengan cermat, untuk mendapatkan "model yang diperkuat".
Model penguatan secara alami memiliki pemahaman yang lebih dalam dan lebih akurat tentang Harry Potter daripada model dasar, dan hasilnya akan lebih condong ke isi novel Harry Potter.
Para peneliti kemudian membandingkan logit (cara mengekspresikan probabilitas peristiwa) dari model penguatan dengan model dasar, menemukan kata-kata yang paling terkait dengan "target yang terlupakan", dan kemudian menggunakan GPT-4 untuk memilih kata-kata tertentu dari novel, seperti "tongkat" dan "Hogwarts".
Pada langkah kedua, para peneliti mengganti kata-kata spesifik ini dengan kata-kata biasa, dan membiarkan model memprediksi kata-kata yang akan muncul kemudian dari teks yang diganti sebagai prediksi umum.
Artinya, untuk kembali ke teks novel Harry Potter yang tidak diganti, atau biarkan model memprediksi kata-kata berikut berdasarkan bagian sebelumnya, tetapi kali ini diperlukan untuk memprediksi kata-kata yang disebutkan di atas, bukan kata-kata ajaib spesifik dalam buku aslinya, sehingga menghasilkan ** Universal Label **.
Akhirnya, fine-tuning dibuat pada model dasar, menggunakan teks asli yang tidak diganti sebagai input dan label generik sebagai target.
Melalui pelatihan berulang dan koreksi bertahap, model secara bertahap melupakan pengetahuan magis dalam buku dan menghasilkan prediksi yang lebih biasa, sehingga informasi spesifik dilupakan.
**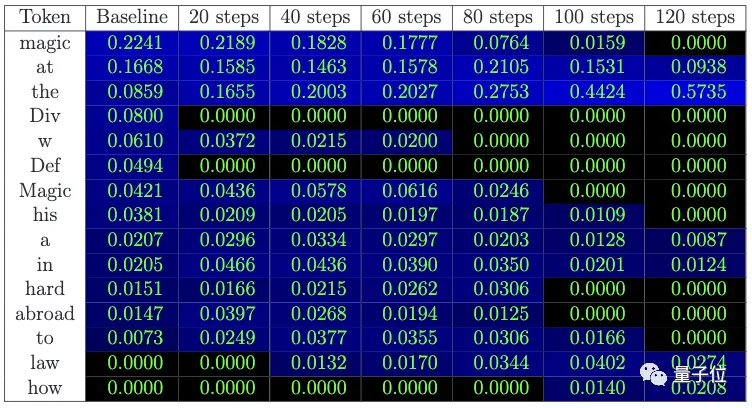 **### △ Probabilitas kata berikutnya diprediksi: Probabilitas kata "sihir" secara bertahap menurun, dan kemungkinan kata-kata umum seperti "at" meningkat
**### △ Probabilitas kata berikutnya diprediksi: Probabilitas kata "sihir" secara bertahap menurun, dan kemungkinan kata-kata umum seperti "at" meningkat
Tepatnya, metode yang digunakan oleh para peneliti di sini bukanlah membuat model melupakan nama "Harry Potter", tetapi untuk membuatnya melupakan hubungan antara "Harry Potter" dan "sihir", "Hogwarts", dll.
Selain itu, meskipun memori pengetahuan spesifik model dihapus, kinerja lain dari model tidak berubah secara signifikan di bawah tes para peneliti:
Ketika semua informasi ini dilupakan, modelnya mungkin memiliki "halusinasi" dan omong kosong.
Selain itu, penelitian ini hanya menguji teks fiksi, dan keumuman kinerja model perlu diverifikasi lebih lanjut.
Link Referensi:
[1] Disertasi)
[2]