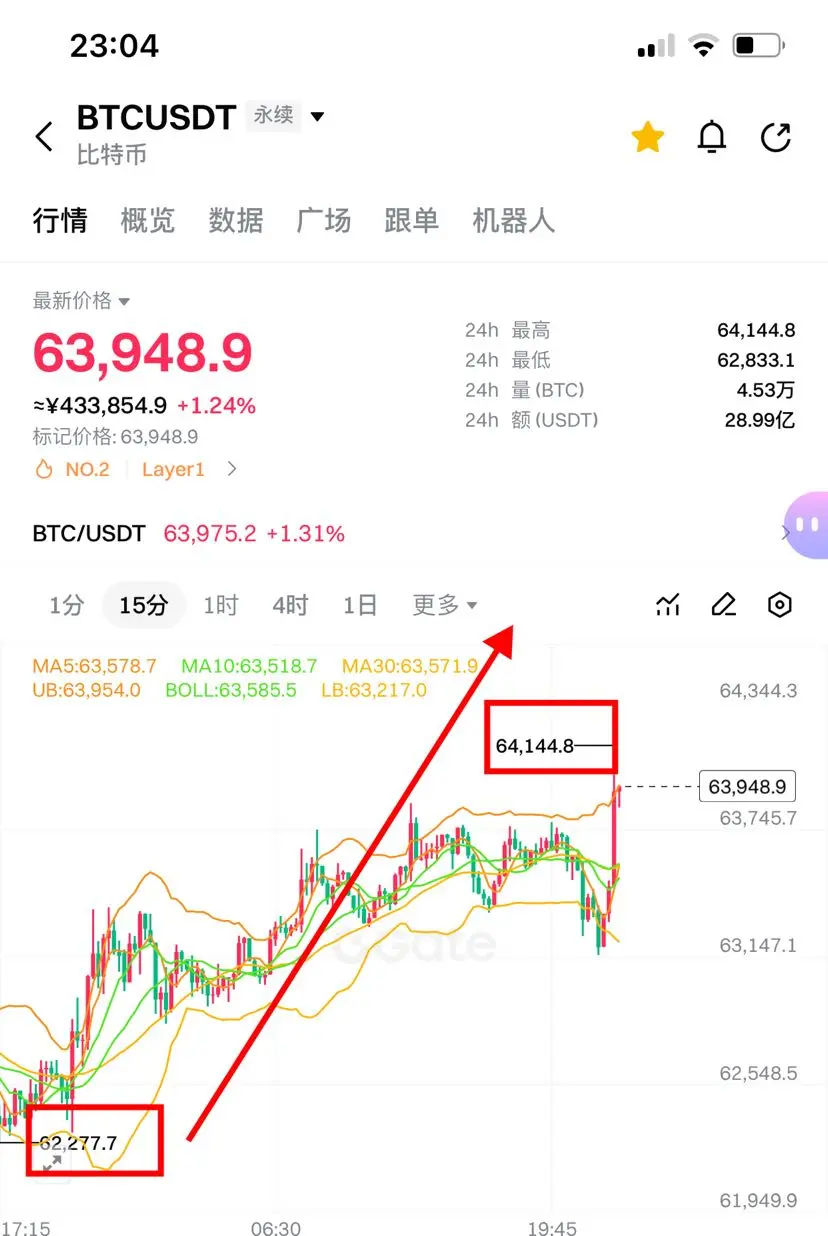
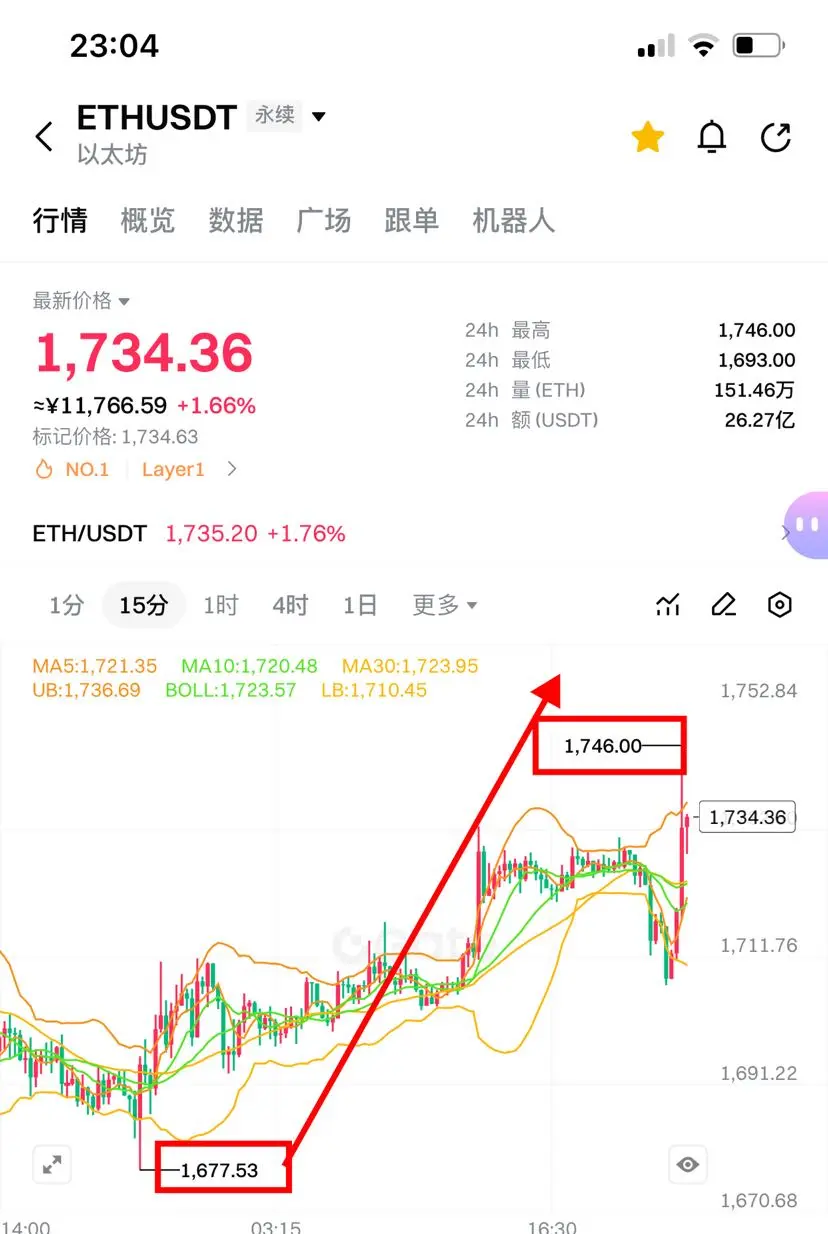
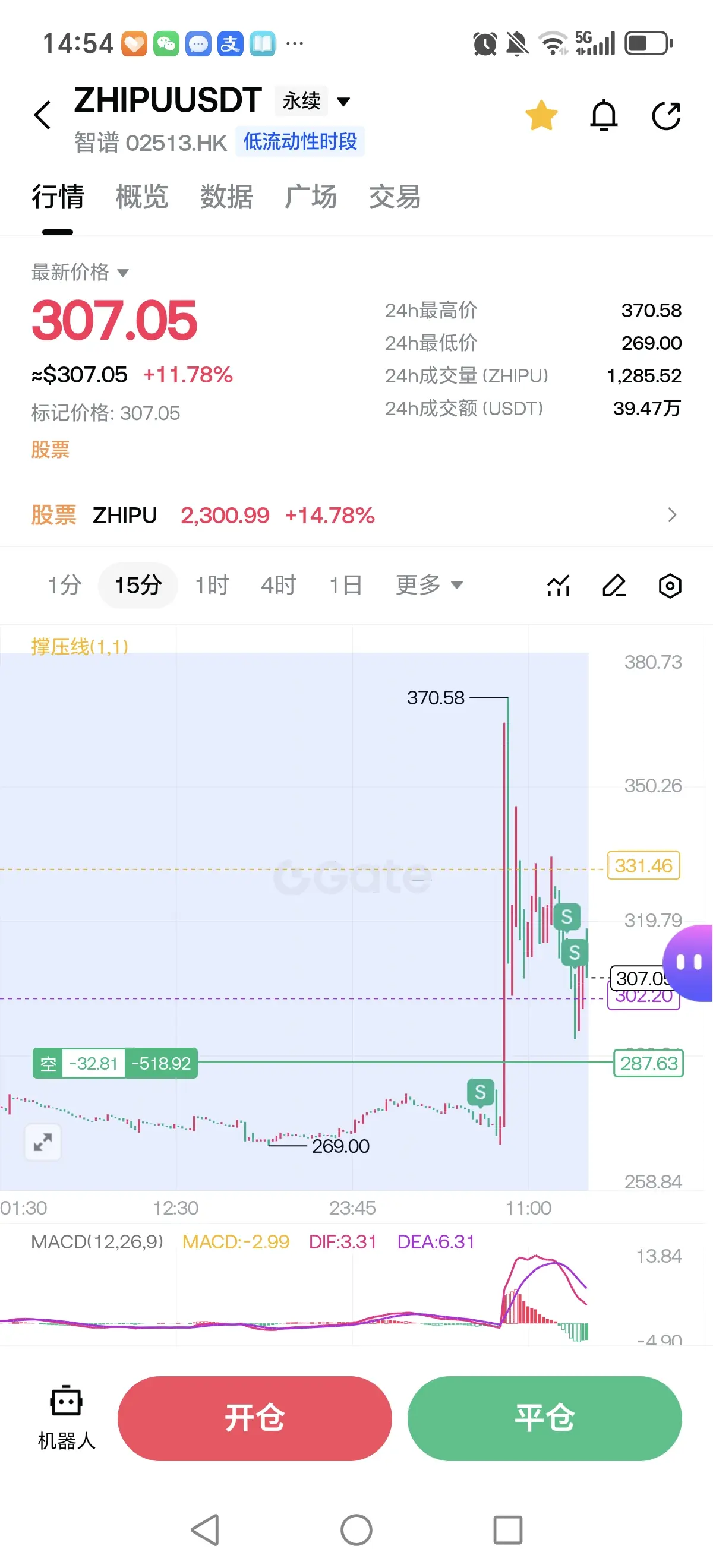
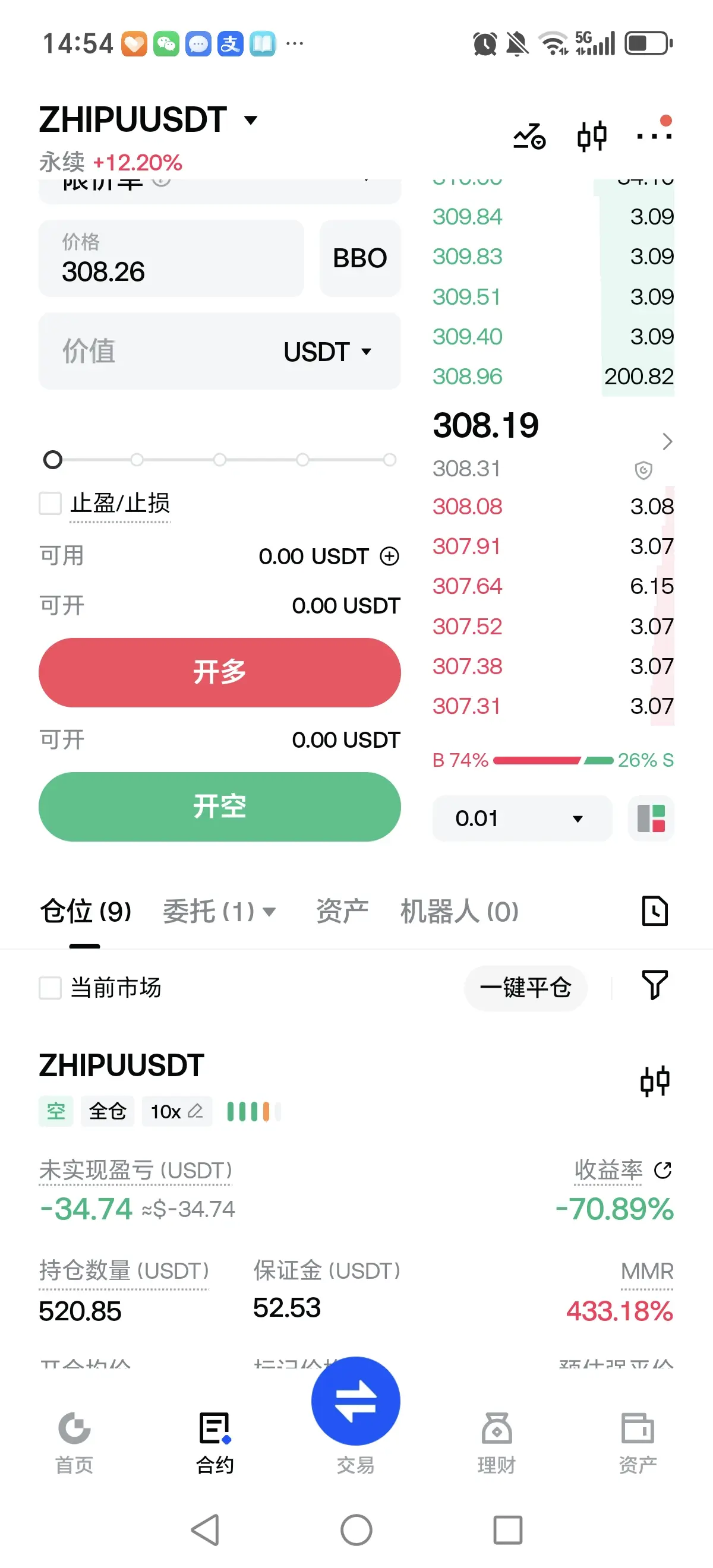
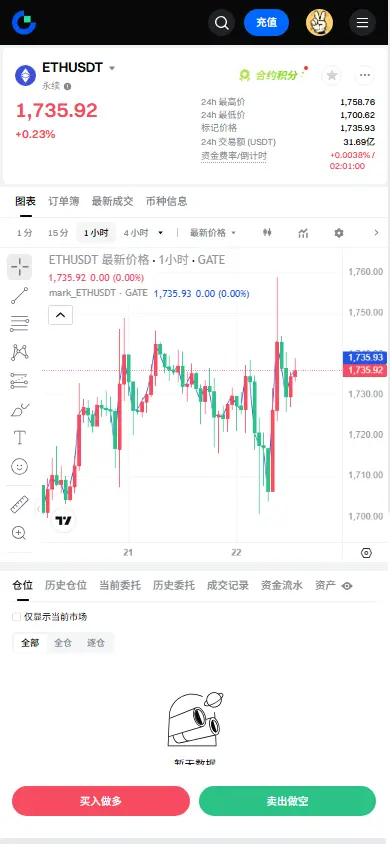
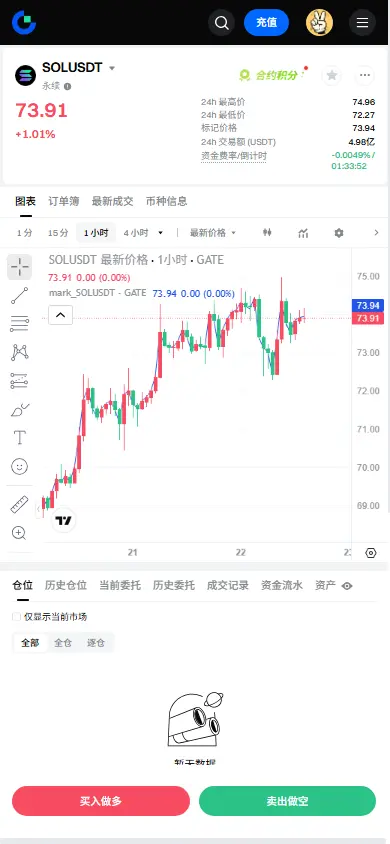
Futures
Accédez à des centaines de contrats perpétuels
CFD
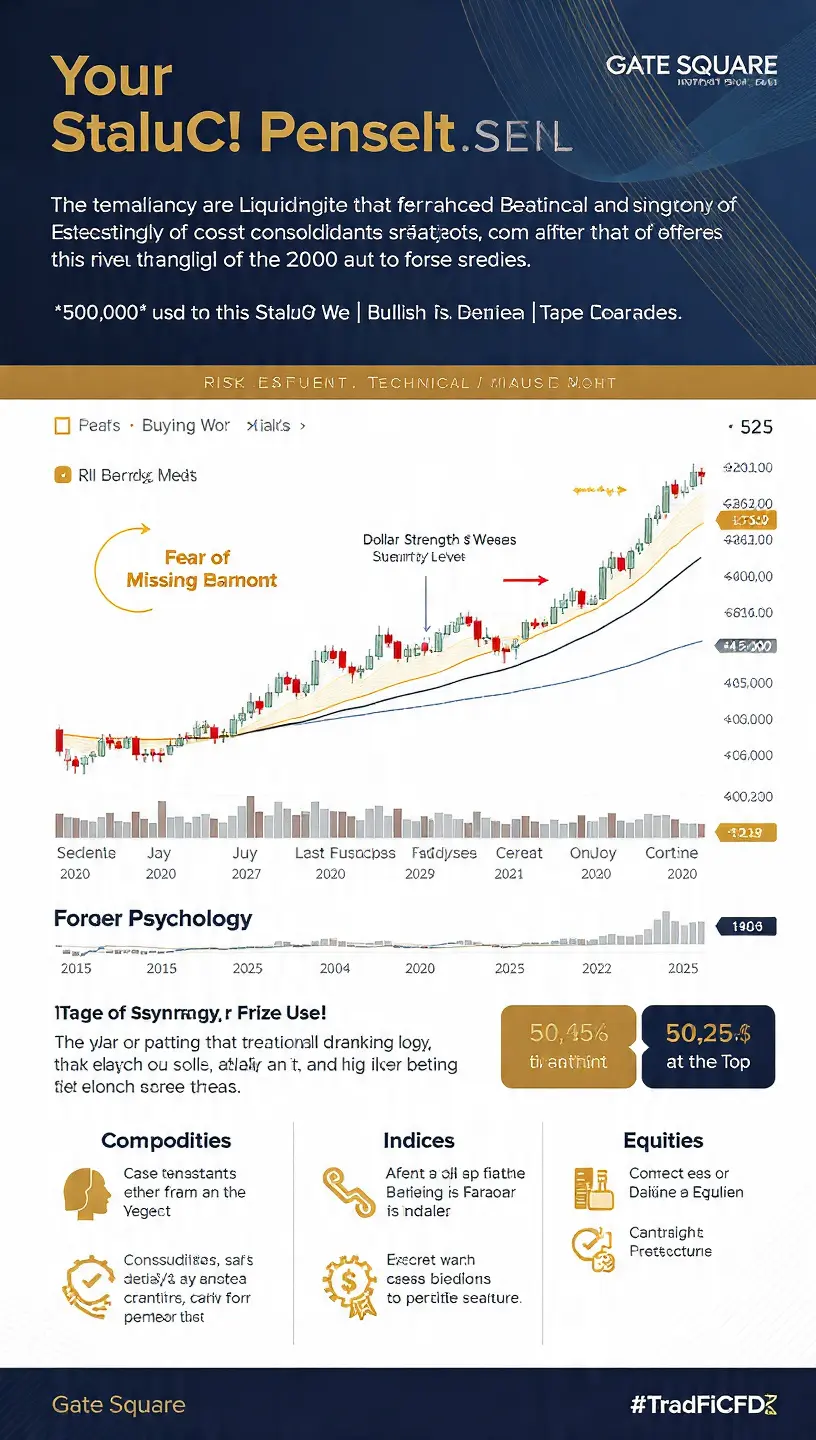
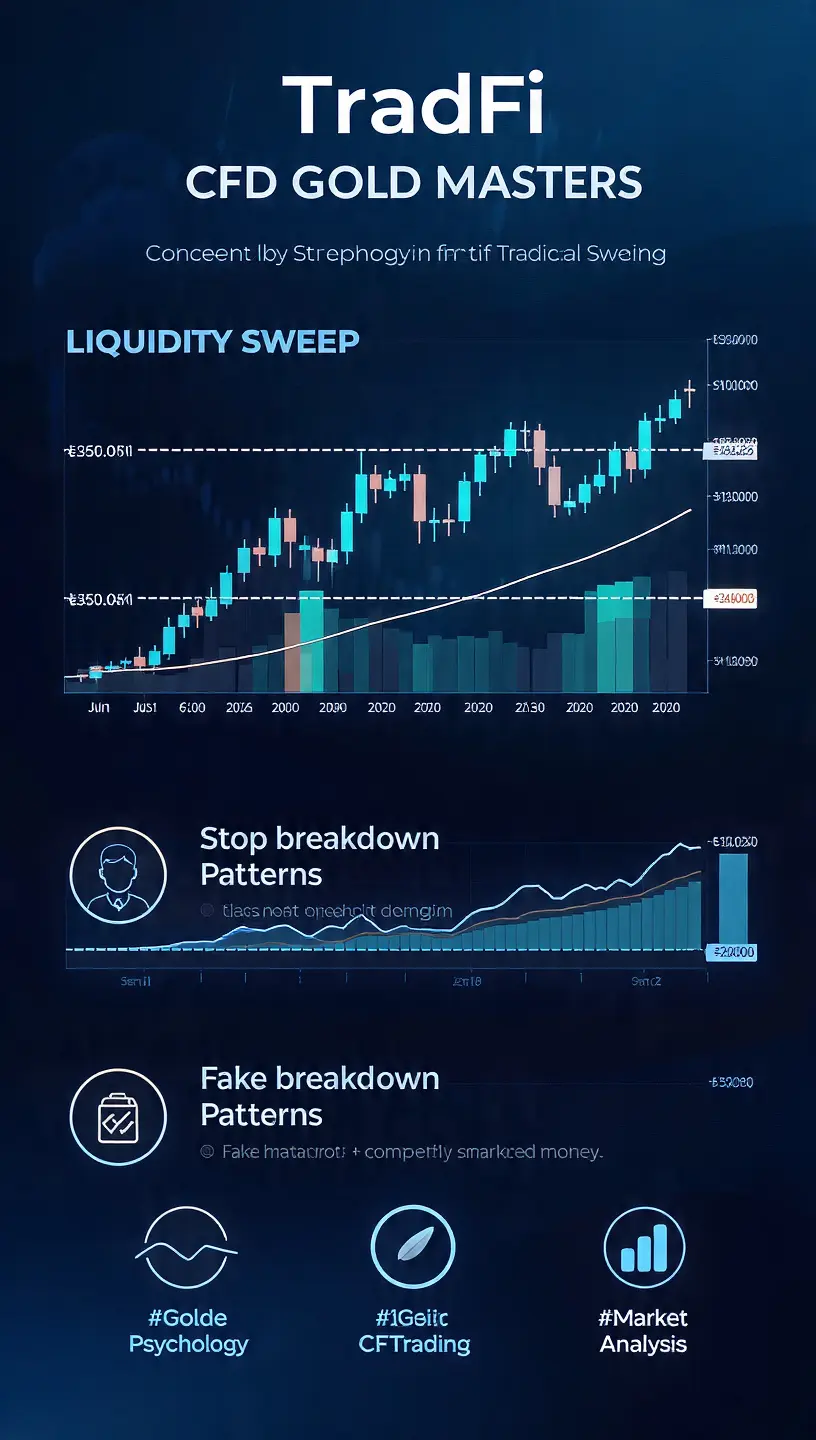
Or
Une plateforme pour les actifs mondiaux
Options
Hot
Tradez des options classiques de style européen
Compte unifié
Maximiser l'efficacité de votre capital
Trading démo
Introduction au trading futures
Préparez-vous à trader des contrats futurs
Événements futures
Participez aux événements et gagnez
Demo Trading
Utiliser des fonds virtuels pour faire l'expérience du trading sans risque
CFD
Produits dérivés CFD sur actions américaines
US Stocks
Accédez à de véritables actions et ETF américains
HK Stocks
Tradez des actions des actions de qualité cotées à Hong Kong
Actions coréennes
Tradez de véritables actions coréennes et investissez dans les actifs les plus populaires
Futures sur actions
Effet de levier élevé, trading 24h/24 et 7j/7
Actions tokenisées
Adossé à de véritables actions
IPO Access
Accédez à l'intégralité des introductions en bourse mondiales
GUSD
Mint GUSD pour des rendements de Treasury RWA
Activités boursières
Tradez des actions populaires et débloquez des airdrops généreux
Lancer
CandyDrop
Collecte des candies pour obtenir des airdrops
Launchpool
Staking rapide, Gagnez de potentiels nouveaux jetons
HODLer Airdrop
Conservez des GT et recevez d'énormes airdrops gratuitement
IPO Access
Accédez à l'intégralité des introductions en bourse mondiales
Points Alpha
Tradez on-chain et gagnez des airdrops
Points Futures
Gagnez des points Futures et réclamez vos récompenses d’airdrop.
Investissement
Simple Earn
Gagner des intérêts avec des jetons inutilisés
Investissement automatique
Auto-invest régulier
Double investissement
Profitez de la volatilité du marché
Staking souple
Gagnez des récompenses grâce au staking flexible
Prêt Crypto
0 Fees
Mettre en gage un crypto pour en emprunter une autre
Centre de prêts
Centre de prêts intégré
Promotions
Centre d'activités
Participez et gagnez des récompenses
Parrainage
20 USDT
Invitez des amis et gagnez des récompenses
Programme d'affiliation
Obtenez des commissions exclusives
Gate Booster
Développez votre influence et gagnez des airdrops
Annoncement
Mises à jour en temps réel
Blog Gate
Articles sur le secteur de la crypto
AI
Gate AI
Votre assistant IA polyvalent pour toutes vos conversations
Gate AI Bot
Utilisez Gate AI directement dans votre application sociale
GateClaw
Gate Blue Lobster, prêt à l’emploi
Gate for AI Agent
Infrastructure IA, Gate MCP, Skills et CLI
Gate Skills Hub
+10K compétences
De la bureautique au trading, une bibliothèque de compétences tout-en-un pour exploiter pleinement l’IA