Фьючерсы
Доступ к сотням фьючерсов
TradFi
Золото
Одна платформа мировых активов
Опционы
Hot
Торги опционами Vanilla в европейском стиле
Единый счет
Увеличьте эффективность вашего капитала
Демо-торговля
Введение в торговлю фьючерсами
Подготовьтесь к торговле фьючерсами
Фьючерсные события
Получайте награды в событиях
Демо-торговля
Используйте виртуальные средства для торговли без риска
Запуск
CandyDrop
Собирайте конфеты, чтобы заработать аирдропы
Launchpool
Быстрый стейкинг, заработайте потенциальные новые токены
HODLer Airdrop
Удерживайте GT и получайте огромные аирдропы бесплатно
Pre-IPOs
Откройте полный доступ к глобальным IPO акций
Alpha Points
Торгуйте и получайте аирдропы
Фьючерсные баллы
Зарабатывайте баллы и получайте награды аирдропа
Инвестиции
Simple Earn
Зарабатывайте проценты с помощью неиспользуемых токенов
Автоинвест.
Автоинвестиции на регулярной основе.
Бивалютные инвестиции
Доход от волатильности рынка
Мягкий стейкинг
Получайте вознаграждения с помощью гибкого стейкинга
Криптозаймы
0 Fees
Заложите одну криптовалюту, чтобы занять другую
Центр кредитования
Единый центр кредитования
Рекламные акции
AI
Gate AI
Ваш универсальный AI-ассистент для любых задач
Gate AI Bot
Используйте Gate AI прямо в вашем социальном приложении
GateClaw
Gate Синий Лобстер — готов к использованию
Gate for AI Agent
AI-инфраструктура: Gate MCP, Skills и CLI
Gate Skills Hub
Более 10 тыс навыков
От офиса до трейдинга: единая база навыков для эффективного использования ИИ
GateRouter
Умный выбор из более чем 40 моделей ИИ, без дополнительных затрат (0%)
Раскрытие трансформера в iPhone: основанный на архитектуре GPT-2 сегментатор слов содержит смайлы, созданные выпускниками MIT.
Первоисточник: Кубиты
Энтузиасты раскрыли «секрет» трансформера Apple.
В волне больших моделей, даже если вы столь же консервативны, как Apple, вы должны упоминать «Трансформер» на каждой пресс-конференции.
Например, на конференции WWDC в этом году Apple объявила, что новые версии iOS и macOS будут иметь встроенные языковые модели Transformer, обеспечивающие методы ввода с возможностью прогнозирования текста.
Парень по имени Джек Кук перевернул бета-версию macOS Sonoma и узнал много свежей информации:
Давайте посмотрим на более подробную информацию.
На основе архитектуры GPT-2
Сначала давайте рассмотрим, какие функции языковая модель Apple на основе Transformer может реализовать на iPhone, MacBook и других устройствах.
В основном отражается на методе ввода. Собственный метод ввода Apple, поддерживаемый языковой моделью, может реализовывать функции прогнозирования слов и исправления ошибок.
** **### △Источник: сообщение в блоге Джека Кука.
**### △Источник: сообщение в блоге Джека Кука.
Модель иногда предсказывает несколько следующих слов, но это ограничивается ситуациями, когда семантика предложения очень очевидна, подобно функции автозаполнения в Gmail.
** **### △Источник: сообщение в блоге Джека Кука.
**### △Источник: сообщение в блоге Джека Кука.
Так где именно установлена эта модель? После некоторых углубленных раскопок брат Кук определил:
Потому что:
Более того, основываясь на структуре сети, описанной в unilm_joint_cpu, я предположил, что модель Apple основана на архитектуре GPT-2:
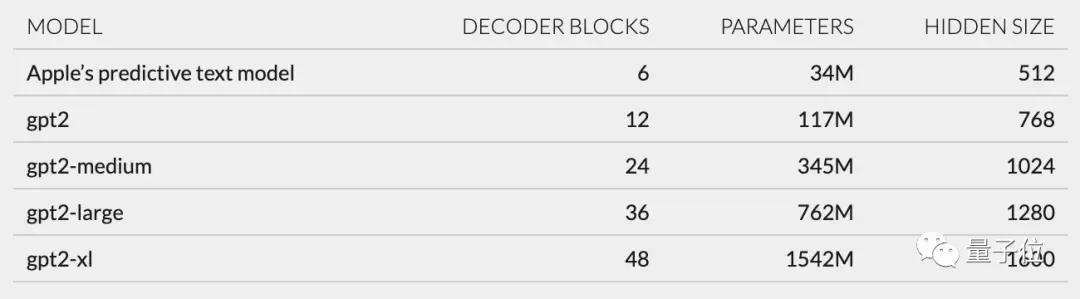
В основном он включает в себя встраивание токенов, кодирование позиции, блок декодера и выходной слой.Каждый блок декодера имеет такие слова, как gpt2_transformer_layer_3d.
** **### △Источник: сообщение в блоге Джека Кука.
**### △Источник: сообщение в блоге Джека Кука.
Основываясь на размере каждого слоя, я также предположил, что модель Apple имеет примерно 34 миллиона параметров, а размер скрытого слоя равен 512. То есть он меньше самой маленькой версии GPT-2.
Я считаю, что это главным образом потому, что Apple нужна модель, которая потребляет меньше энергии, но может работать быстро и часто.
Официальное заявление Apple на WWDC заключается в том, что «при каждом нажатии клавиши iPhone запускает модель один раз».
Однако это также означает, что эта модель прогнозирования текста не очень хороша для полного продолжения предложений или абзацев.
** **### △Источник: сообщение в блоге Джека Кука.
**### △Источник: сообщение в блоге Джека Кука.
Помимо архитектуры модели, Кук также накопал информацию о токенизаторе.
В файле unilm.bundle/sp.dat он нашел набор из 15 000 токенов. Стоит отметить, что он содержит 100 эмодзи.
Кук раскрывает Кука
Хотя этот Повар не является поваром, мой пост в блоге все равно привлек много внимания сразу после публикации.
Ранее он стажировался в NVIDIA, занимаясь исследованием языковых моделей, таких как BERT. Он также является старшим инженером по исследованиям и разработкам в области обработки естественного языка в The New York Times.
Итак, его откровение тоже вызвало у вас какие-то мысли? Добро пожаловать, чтобы поделиться своим мнением в области комментариев ~
Оригинальная ссылка: