Фьючерсы
Доступ к сотням фьючерсов
CFD
Золото
Одна платформа мировых активов
Опционы
Hot
Торги опционами Vanilla в европейском стиле
Единый счет
Увеличьте эффективность вашего капитала
Демо-торговля
Введение в торговлю фьючерсами
Подготовьтесь к торговле фьючерсами
Фьючерсные события
Получайте награды в событиях
Демо-торговля
Используйте виртуальные средства для торговли без риска
Запуск
CandyDrop
Собирайте конфеты, чтобы заработать аирдропы
Launchpool
Быстрый стейкинг, заработайте потенциальные новые токены
HODLer Airdrop
Удерживайте GT и получайте огромные аирдропы бесплатно
Pre-IPOs
Откройте полный доступ к глобальным IPO акций
Alpha Points
Торгуйте и получайте аирдропы
Фьючерсные баллы
Зарабатывайте баллы и получайте награды аирдропа
Инвестиции
Simple Earn
Зарабатывайте проценты с помощью неиспользуемых токенов
Автоинвест.
Автоинвестиции на регулярной основе.
Бивалютные инвестиции
Доход от волатильности рынка
Мягкий стейкинг
Получайте вознаграждения с помощью гибкого стейкинга
Криптозаймы
0 Fees
Заложите одну криптовалюту, чтобы занять другую
Центр кредитования
Единый центр кредитования
Рекламные акции
Промоакции
Участвуйте и получайте награды
Реферал
20 USDT
Приглашайте друзей за бонусы
Партнерская программа
Эксклюзивные комиссионные
Gate Booster
Растите влияние и получайте аирдроп
Анонсы
Обновления в реальном времени
Блог Gate
Статьи о криптоиндустрии
VIP-услуги
Огромные скидки на комиссии
Управление активами
Универсальное решение для управления активами
Институциональный
Крипто-решения для бизнеса
Разработчикам (API)
Подключение к экосистеме приложений Gate
Внебиржевые банковские переводы
Ввод и вывод фиатных денег
Брокерская программа
Щедрые механизмы скидок API
AI
Gate AI
Ваш универсальный AI-ассистент для любых задач
Gate AI Bot
Используйте Gate AI прямо в вашем социальном приложении
GateClaw
Gate Синий Лобстер — готов к использованию
Gate for AI Agent
AI-инфраструктура: Gate MCP, Skills и CLI
Gate Skills Hub
Более 10 тыс навыков
От офиса до трейдинга: единая база навыков для эффективного использования ИИ
GateRouter
Умный выбор из более чем 40 моделей ИИ, без дополнительных затрат (0%)
ИИ всё ещё не может превзойти дежурного инженера: вот почему
Вкратце
Компании по ИИ продолжают продвигать автономных агентов по обеспечению надежности сайтов — ИИ, который расследует производственные инциденты вместо людей. Datadog провела реальный бенчмарк на настоящих сбоях, и лучшие модели ИИ пока не могут превзойти инженеров, которых они должны заменить. Бенчмарк называется ARFBench (Anomaly Reasoning Framework Benchmark), совместный проект Datadog и Карнеги-Меллон. Создан из 63 реальных инцидентов в производстве, взятых из Slack-веток инженеров во время живых чрезвычайных ситуаций — 750 вопросов с выбором ответа, охватывающих 142 метрики мониторинга и 5,38 миллиона данных, каждый вопрос проверен вручную. Нет синтетических данных. Нет сценариев из учебников. “Триллионы долларов теряются ежегодно из-за сбоев систем”, пишут исследователи. Цель бенчмарка — проверить, может ли ИИ реально помочь изменить это.
«Несмотря на центральную роль анализа, основанного на вопросах, в реагировании на инциденты, остается неясным, могут ли современные базовые модели надежно отвечать на виды вопросов о временных рядах, которые инженеры задают на практике», — говорится в статье. Вопросы делятся на три уровня. Уровень I: существует ли аномалия на этом графике? Уровень II: когда она началась, насколько она серьезна, какого типа?
Самый сложный — Уровень III — требует межметрического рассуждения: вызывает ли эта диаграмма проблему в другой диаграмме? Именно здесь ИИ терпит неудачу. GPT-5 показывает всего 47,5% F1 по вопросам уровня III, метрике, которая штрафует модели за угадывание ответов, выбирая наиболее распространенный класс.
«Несмотря на центральную роль анализа, основанного на вопросах, в реагировании на инциденты, остается неясным, могут ли современные базовые модели надежно отвечать на виды вопросов о временных рядах, которые инженеры задают на практике», — пишут исследователи. Как показали все модели GPT-5 лидирует среди всех существующих моделей с точностью 62,7% — на тесте, где случайное угадывание дает 24,5%. Gemini 3 Pro — 58,1%. Claude Opus — 54,8%. Claude Sonnet — 47,2%.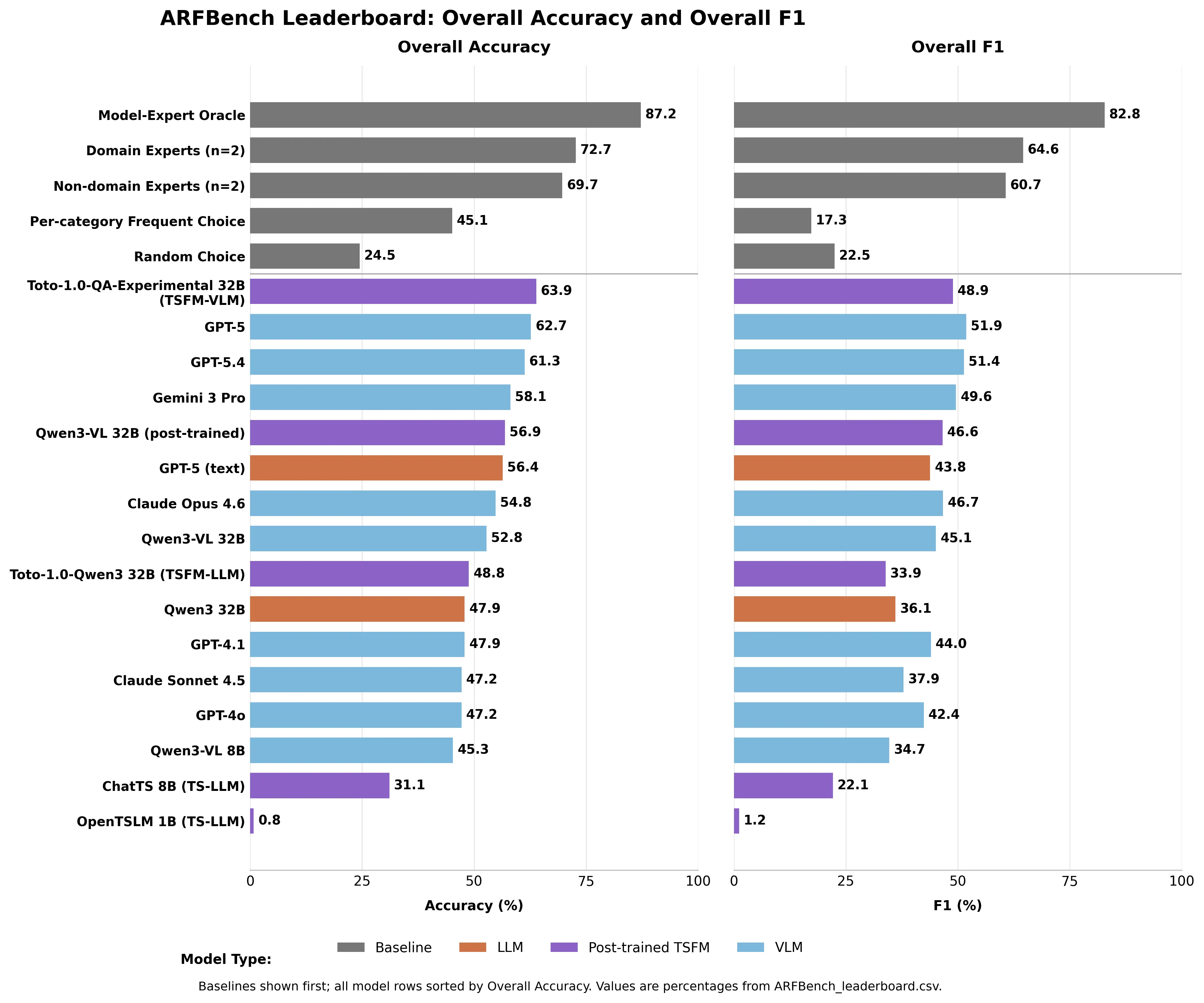
Эксперты в области достигли 72,7% точности. Неэкспертные специалисты — исследователи временных рядов в Datadog без обширного опыта в области наблюдаемости — все равно достигли 69,7%.
Ни одна модель ИИ не превзошла ни одного из человеческих базовых уровней.
Изображение, созданное Decrypt на основе CSV-файла лидерборда ARFBench
Модель, которая действительно заняла первое место в общем рейтинге, — гибрид Datadog: Toto — их внутренняя модель прогнозирования временных рядов — в сочетании с Qwen3-VL 32B. Toto-1.0-QA-Experimental показала 63,9% точности, опередив GPT-5, при этом использовав меньшую часть его параметров.
В частности, при идентификации аномалий она превзошла все остальные модели как минимум на 8,8 процентных пунктов по F1.
Созданная специально для этой задачи модель области, обученная на данных наблюдаемости, превосходит передовую универсальную систему — это ожидаемый результат. В этом и заключается смысл.
Самое ценное открытие — не какая модель набрала высший балл.
«Мы наблюдаем существенно разные профили ошибок у ведущих моделей и человеческих экспертов, что говорит о том, что их сильные стороны дополняют друг друга», — пишут исследователи. Модели галлюцинируют, пропускают метаданные и теряют контекст области. Люди неправильно читают точные временные метки и иногда не справляются со сложными инструкциями. Ошибки практически не совпадают.
Создайте гипотетический «Модель-Эксперт-Оракул» — идеальный судья, который всегда выбирает правильный ответ между ИИ и человеком, — и получите 87,2% точности и 82,8% F1. Значительно выше, чем любой из них по отдельности.
Это не продукт. Это задокументированная цель — созданная на основе реальных чрезвычайных ситуаций, а не курируемых наборов данных — которая точно показывает, насколько лучше может работать совместная работа человека и ИИ. Лидерборд доступен на Hugging Face. GPT-5 — 62,7%. Потолок — 87,2%.