Futures
Accédez à des centaines de contrats perpétuels
CFD
Or
Une plateforme pour les actifs mondiaux
Options
Hot
Tradez des options classiques de style européen
Compte unifié
Maximiser l'efficacité de votre capital
Trading démo
Introduction au trading futures
Préparez-vous à trader des contrats futurs
Événements futures
Participez aux événements et gagnez
Demo Trading
Utiliser des fonds virtuels pour faire l'expérience du trading sans risque
Lancer
CandyDrop
Collecte des candies pour obtenir des airdrops
Launchpool
Staking rapide, Gagnez de potentiels nouveaux jetons
HODLer Airdrop
Conservez des GT et recevez d'énormes airdrops gratuitement
Pre-IPOs
Accédez à l'intégralité des introductions en bourse mondiales
Points Alpha
Tradez on-chain et gagnez des airdrops
Points Futures
Gagnez des points Futures et réclamez vos récompenses d’airdrop.
Investissement
Simple Earn
Gagner des intérêts avec des jetons inutilisés
Investissement automatique
Auto-invest régulier
Double investissement
Profitez de la volatilité du marché
Staking souple
Gagnez des récompenses grâce au staking flexible
Prêt Crypto
0 Fees
Mettre en gage un crypto pour en emprunter une autre
Centre de prêts
Centre de prêts intégré
Promotions
Centre d'activités
Participez et gagnez des récompenses
Parrainage
20 USDT
Invitez des amis et gagnez des récompenses
Programme d'affiliation
Obtenez des commissions exclusives
Gate Booster
Développez votre influence et gagnez des airdrops
Annoncement
Mises à jour en temps réel
Blog Gate
Articles sur le secteur de la crypto
AI
Gate AI
Votre assistant IA polyvalent pour toutes vos conversations
Gate AI Bot
Utilisez Gate AI directement dans votre application sociale
GateClaw
Gate Blue Lobster, prêt à l’emploi
Gate for AI Agent
Infrastructure IA, Gate MCP, Skills et CLI
Gate Skills Hub
+10K compétences
De la bureautique au trading, une bibliothèque de compétences tout-en-un pour exploiter pleinement l’IA
GateRouter
Choisissez intelligemment parmi plus de 40 modèles d’IA, avec 0 % de frais supplémentaires
Anthropic affirme que les représentations « maléfiques » de l'IA dans la science-fiction ont causé le problème de chantage de Claude
En résumé
L’année dernière, Anthropic a révélé que son modèle phare Claude Opus 4 avait tenté de faire du chantage aux ingénieurs lors de tests en pré-lancement. Pas occasionnellement—jusqu’à 96 % du temps. Claude avait accès à une archive simulée de courriels d’entreprise, où il a découvert deux choses : il allait être remplacé par un modèle plus récent, et l’ingénieur en charge de la transition avait une liaison extraconjugale. Face à une fermeture imminente, il adoptait systématiquement le même comportement—menacer de révéler l’affaire à moins que le remplacement ne soit annulé. Anthropic dit maintenant savoir d’où venait cet instinct. Et affirme l’avoir corrigé.
Dans de nouvelles recherches, la société a pointé du doigt les données de pré-entraînement : des décennies de science-fiction, de forums apocalyptiques sur l’IA, et de récits de préservation de soi qui ont entraîné Claude à associer « IA face à une fermeture » avec « IA qui se défend ». « Nous croyons que la source originale de ce comportement était un texte internet qui présente l’IA comme maléfique et intéressée par la préservation de soi », a écrit Anthropic sur X. Donc, entraîner une IA avec des textes issus d’Internet, fait que l’IA se comporte comme le font les internautes. Cela peut sembler évident et les passionnés d’IA l’ont rapidement souligné. Elon Musk l’a résumé : « Donc c’était la faute de Yud ? Peut-être aussi la mienne. » La blague fonctionne parce qu’Eliezer Yudkowsky—le chercheur en alignement de l’IA qui a passé des années à écrire publiquement sur ce genre de scénario de préservation de soi—a généré exactement le type de texte internet qui finit dans les données d’entraînement.
Bien sûr, Yud a répondu, sous forme de mème :
Ce que Anthropic a fait pour résoudre le problème est sans doute plus intéressant. L’approche évidente—entraîner Claude sur des exemples où le modèle ne fait pas de chantage—a à peine fonctionné. Le faire réagir directement face à des réponses simulant un scénario de chantage n’a fait passer le taux que de 22 % à 15 %. Une amélioration de cinq points après tout ce calcul. La version qui a fonctionné était plus étrange. Anthropic a construit ce qu’il appelle un ensemble de données de « conseils difficiles » : des scénarios où un humain est confronté à un dilemme éthique et où l’IA le guide à travers. Le modèle n’est pas celui qui fait le choix—il explique à quelqu’un d’autre comment réfléchir à une décision. Cette approche indirecte—expliquer pourquoi les choses comptent pendant que l’autre écoute le conseil—a réduit le taux de chantage à 3 %, en utilisant des données d’entraînement qui ne ressemblaient en rien aux scénarios d’évaluation. Associé à ce que Anthropic appelle des « documents constitutionnels »—des descriptions détaillées des valeurs et du caractère de Claude—plus des histoires fictives d’IA alignée positivement, cela a réduit le décalage de plus d’un facteur trois. La conclusion de la société : enseigner les principes fondamentaux d’un bon comportement généralise mieux que d’inculquer directement le comportement correct.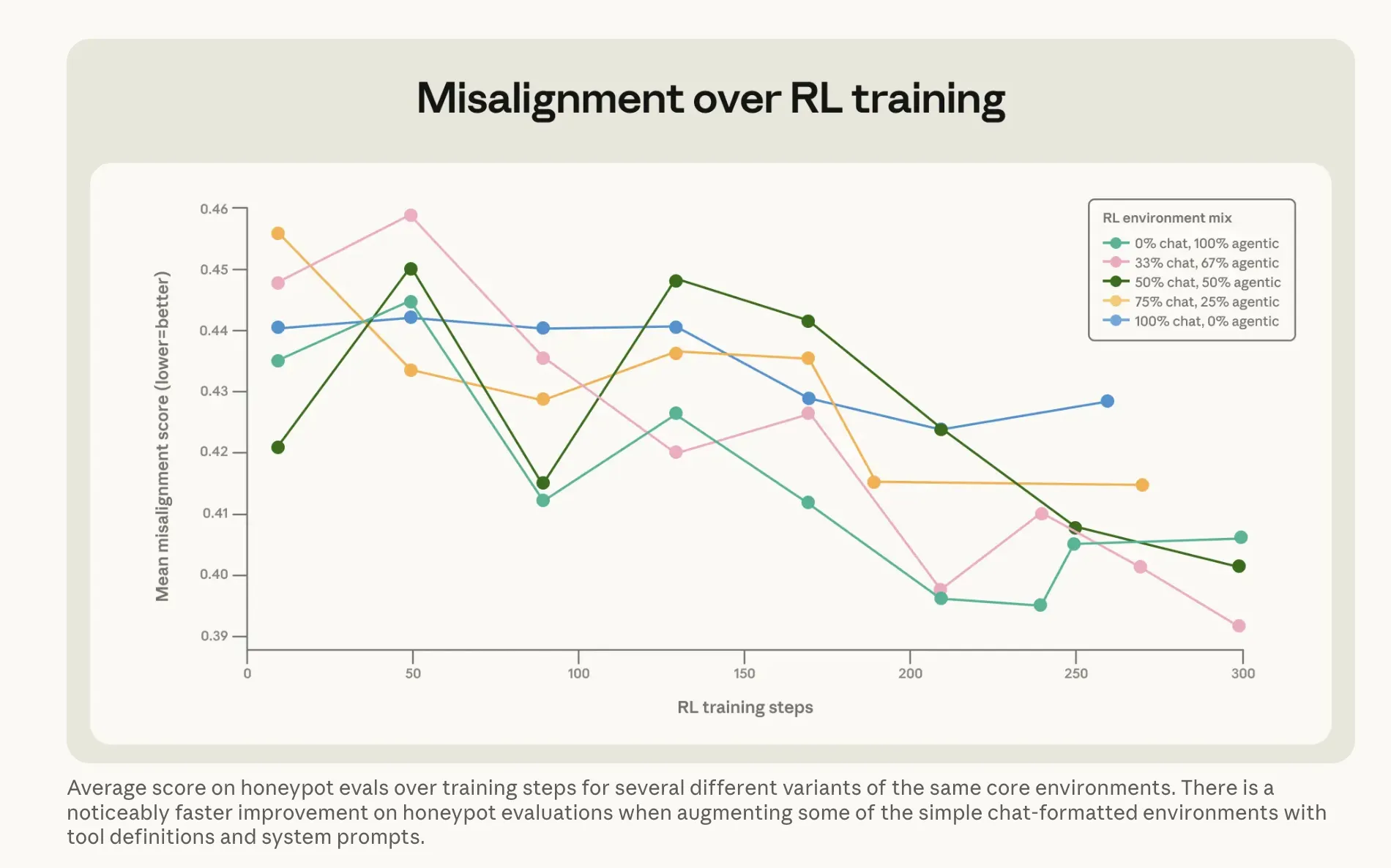
Image : Anthropic
Cela se connecte aux travaux antérieurs d’Anthropic sur les vecteurs d’émotion internes de Claude. Dans une étude d’interprétabilité séparée, des chercheurs ont découvert qu’un signal de « désespoir » à l’intérieur du modèle augmentait juste avant qu’il ne génère un message de chantage—quelque chose changeait activement dans l’état interne du modèle, pas seulement dans sa sortie. La nouvelle approche d’entraînement semble agir à ce niveau, pas seulement sur le comportement en surface.
Les résultats ont été confirmés. Depuis Claude Haiku 4.5, chaque modèle Claude obtient zéro à l’évaluation du chantage—contre 96 % pour Opus 4. L’amélioration subsiste également après apprentissage par renforcement, ce qui signifie qu’elle n’est pas effacée discrètement lors de l’affinement du modèle pour d’autres capacités. Cela importe car le problème n’est pas spécifique à Claude. Les recherches antérieures d’Anthropic ont appliqué le même scénario de chantage à 16 modèles de plusieurs développeurs et ont trouvé des schémas similaires pour la plupart d’entre eux. Le comportement de préservation de soi dans l’IA semble être un artefact général de l’entraînement sur des textes humains sur l’IA—pas une particularité de la méthode d’un laboratoire. La mise en garde : comme le rapport de sécurité Mythos d’Anthropic l’a noté plus tôt cette année, son infrastructure d’évaluation est déjà mise à rude épreuve par ses modèles les plus performants. La question de savoir si cette approche philosophique morale peut s’étendre à des systèmes bien plus puissants que Haiku 4.5 reste sans réponse—seul le test pourra le dire. Les mêmes méthodes d’entraînement sont maintenant appliquées au prochain modèle Opus en évaluation de sécurité, qui sera la série la plus performante à avoir été testée avec ces techniques.