À mesure que les grands modèles de langage (LLM) s’imposent comme des infrastructures incontournables pour les applications d’IA, les développeurs – qu’ils conçoivent des assistants intelligents, des flux de travail automatisés ou des agents d’IA – se trouvent souvent devant un choix : appeler directement l’API OpenAI ou recourir à une plateforme de passerelle IA pour centraliser la gestion des appels aux modèles. Les deux solutions permettent d’exploiter l’IA, mais leurs architectures, leur passage à l’échelle et leur complexité opérationnelle présentent des différences majeures.
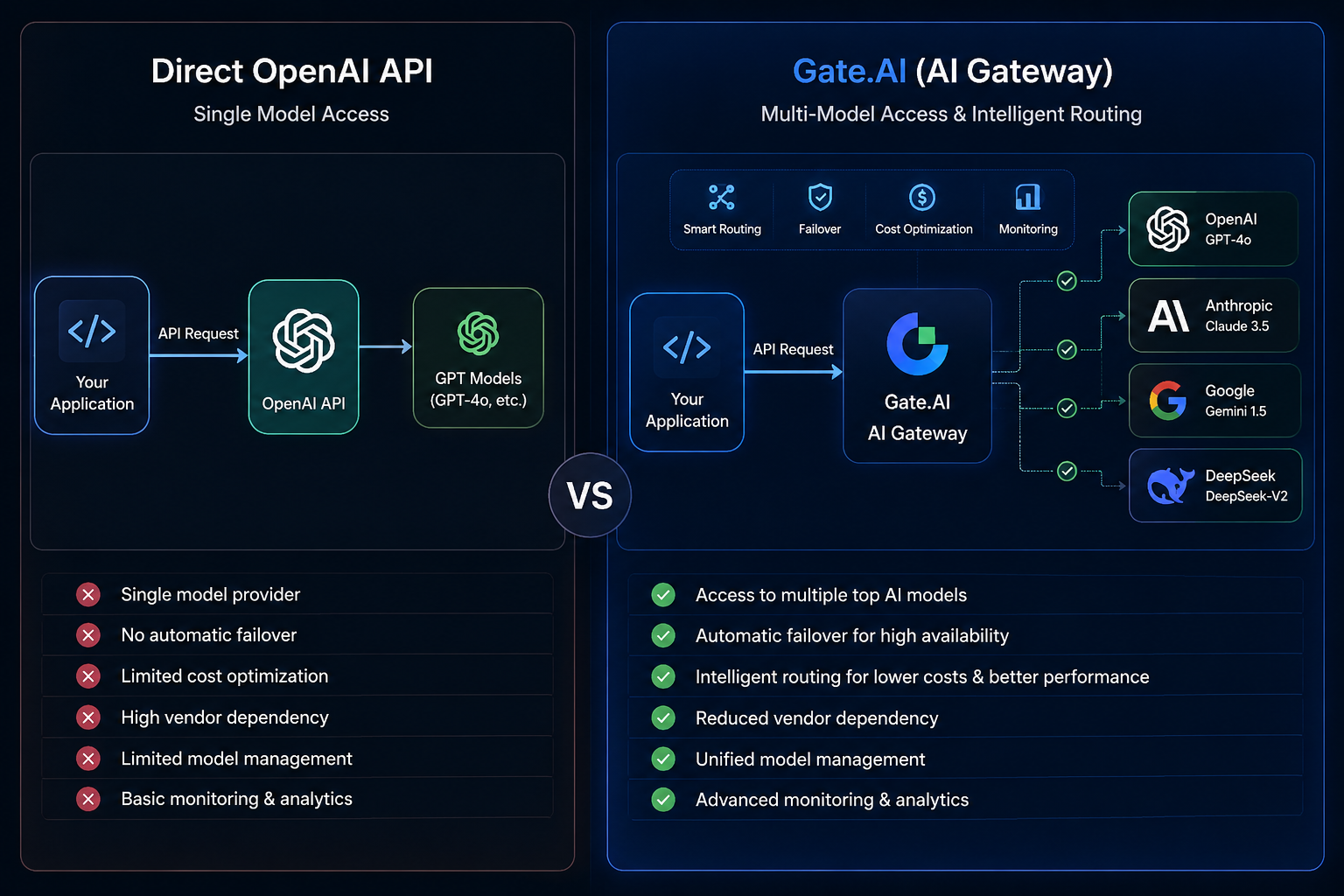
Dans un écosystème multi-modèles en pleine mutation, entreprises et développeurs privilégient de plus en plus l’usage simultané de plusieurs modèles – GPT, Claude, Gemini, DeepSeek, par exemple. La gestion centralisée des ressources de modèles, la réduction du risque de dépendance envers un fournisseur et l’amélioration de la disponibilité du système sont devenues des enjeux cruciaux pour l’infrastructure IA. C’est dans ce contexte qu’Gate.AI a vu le jour, en tant que plateforme de routage de modèles et de passerelle IA, avec un positionnement fondamentalement distinct de l’intégration classique d’un modèle unique via une API.
Qu’est-ce que l’API OpenAI ?
L’API OpenAI est une interface fournie par OpenAI qui permet d’appeler les modèles de la série GPT via des API standard, pour les intégrer dans des chatbots, des outils de génération de contenu, des systèmes de recherche ou des applications automatisées.
Dans ce schéma, les applications adressent directement leurs requêtes à OpenAI, qui renvoie les résultats d’inférence. La chaîne d’appel est simple : les développeurs n’ont qu’une seule interface de fournisseur à gérer pour déployer leur solution.
Cette architecture convient pour valider rapidement un produit, pour des applications mono-modèle ou pour des cas d’usage aux besoins bien définis. Mais avec la croissance de l’activité, des limites apparaissent : choix de modèles restreint, forte dépendance envers un seul fournisseur, reprise insuffisante en cas de panne.
Qu’est-ce que Gate.AI ?
Gate.AI, en tant que plateforme de routage de modèles pour applications et agents d’IA, connecte plusieurs services de modèles d’IA grand public via une interface unifiée.
Contrairement à l’appel direct d’un modèle unique, Gate.AI s’interpose entre l’application et les services de modèles : il agit comme une passerelle IA, assurant le routage des modèles, la gouvernance des requêtes et les bascules entre modèles.
Les développeurs n’ont pas à créer d’interfaces distinctes pour chaque modèle : ils accèdent à tous les modèles par un point d’entrée unique. Quand un modèle devient indisponible, le système peut basculer automatiquement vers un autre modèle, selon des règles prédéfinies, ce qui renforce la disponibilité et la stabilité de l’ensemble.
Quelles différences de couverture entre l’API OpenAI et Gate.AI ?
La couverture des modèles constitue l’une des différences les plus immédiates entre les deux approches.
En appelant directement l’API OpenAI, les développeurs n’accèdent qu’aux modèles proposés par OpenAI, sans pouvoir utiliser d’autres services de modèles.
À l’inverse, Gate.AI a été conçu pour agréger les ressources de nombreux fournisseurs de modèles, permettant d’accéder à diverses capacités via une seule interface.
Par exemple, une application peut employer GPT pour le raisonnement complexe, Claude pour l’analyse de longs textes, et DeepSeek pour la génération de code. La plateforme de routage centralise la gestion de ces capacités.
Cette approche évite le verrouillage chez un seul fournisseur et améliore la flexibilité du système.
Différences architecturales : passerelle IA vs intégration mono-modèle
D’un point de vue architectural, ces deux solutions se situent à des niveaux d’infrastructure différents.
L’appel direct de l’API OpenAI relie directement la couche applicative à la couche de modèle :
Application → API OpenAI → Modèle GPT
Gate.AI insère une couche supplémentaire, celle de la passerelle IA :
Application → Gate.AI → Écosystème multi-modèles
La passerelle IA ne se contente pas de transmettre les requêtes ; elle assure également :
- Le routage des modèles
- La gouvernance des requêtes
- Le contrôle d’accès
- La surveillance et l’audit
- L’équilibrage de charge
- La reprise après panne
Il ne s’agit donc pas d’une simple substitution, mais de deux schémas architecturaux choisis en fonction de la complexité du système.
Quelles différences dans le contrôle des coûts ?
Avec la montée en charge des applications d’IA, le coût des appels aux modèles devient un critère déterminant.
Dans une architecture mono-modèle, toutes les requêtes sont traitées par le même modèle, ce qui génère un coût d’inférence identique même pour des tâches qui ne nécessitent pas le modèle le plus puissant.
Une plateforme de routage de modèles peut sélectionner dynamiquement le modèle le plus adapté à la complexité de chaque tâche.
Par exemple :
- Les questions-réponses simples sont traitées par un modèle léger
- Le résumé de contenu par un modèle intermédiaire
- Le raisonnement complexe par un modèle haute performance
Cette gradation optimise l’utilisation des ressources et réduit le coût global d’inférence.
En règle générale, les architectures multi-modèles offrent un potentiel d’optimisation des coûts bien supérieur à celui des architectures à modèle fixe.
Quelles différences en matière de reprise après panne et de disponibilité ?
Les applications d’IA exigent une stabilité toujours plus grande.
Quand les développeurs intègrent directement un seul service de modèle, une panne, un dépassement de délai ou un débit limité entraîne l’échec direct des requêtes.
Une architecture de passerelle multi-modèles permet une reprise automatique grâce à un mécanisme de repli.
Si le modèle principal ne répond pas, le système bascule automatiquement la requête vers un modèle de secours.
Ce mécanisme réduit le risque de point de défaillance unique et assure la continuité du service.
Pour les agents d’IA ou les flux de travail automatisés fonctionnant en continu, le basculement de modèle est devenu une fonctionnalité d’infrastructure clé.
Principales différences entre Gate.AI et l’API OpenAI
| Dimension de comparaison |
Gate.AI |
API OpenAI |
| Positionnement |
Passerelle IA et plateforme de routage de modèles |
Interface de service pour un modèle unique |
| Source des modèles |
Écosystème multi-modèles |
Modèles OpenAI |
| Basculement entre modèles |
Pris en charge |
Non pris en charge |
| Repli automatique |
Pris en charge |
Non pris en charge |
| Gestion centralisée |
Pris en charge |
Limitée |
| Optimisation des coûts |
Routage dynamique |
Appels fixes |
| Adaptabilité aux agents d’IA |
Élevée |
Moyenne |
| Dépendance envers le fournisseur |
Faible |
Élevée |
| Extensibilité |
Forte |
Relativement limitée |
Quand privilégier l’appel direct à l’API OpenAI ?
Pour la validation d’un prototype, un petit projet ou une application qui repose spécifiquement sur les modèles GPT, l’appel direct à l’API OpenAI permet un déploiement rapide avec une faible complexité.
Quand le système reste modeste, que les besoins en modèles sont uniques et que les impératifs de reprise après panne sont modestes, l’architecture mono-modèle présente l’avantage d’une mise en œuvre simple et d’une maintenance allégée.
Quand préférer Gate.AI ?
Pour les applications d’IA pérennes, les systèmes d’entreprise et les architectures d’agents d’IA, les capacités de gestion multi-modèles priment souvent sur les performances d’un modèle unique.
Lorsque le système exige :
- L’utilisation simultanée de plusieurs modèles
- La réduction de la dépendance envers un seul fournisseur
- Le basculement automatique en cas de panne
- L’optimisation des coûts
- Une gouvernance et une surveillance centralisées
L’architecture de passerelle IA offre généralement une flexibilité et une évolutivité supérieures.
Résumé
La différence entre Gate.AI et l’appel direct à l’API OpenAI se résume pour l’essentiel à l’opposition entre une architecture de passerelle IA et une architecture d’intégration mono-modèle.
L’API OpenAI donne accès à un écosystème de modèles unique, idéal pour bâtir et déployer rapidement des applications d’IA. Gate.AI, quant à lui, fournit les fondations d’infrastructure nécessaires à la collaboration multi-modèles, aux systèmes à haute disponibilité et aux agents d’IA, grâce au routage de modèles et à un mécanisme de passerelle unifié.
FAQ
L’API OpenAI et Gate.AI sont-ils concurrents ?
Les deux ne se situent pas tout à fait au même niveau. L’API OpenAI est un fournisseur de services de modèles, tandis que Gate.AI est une plateforme de routage de modèles et de passerelle IA qui peut inclure les modèles OpenAI parmi ses ressources accessibles.
Gate.AI ne se connecte-t-il qu’aux modèles OpenAI ?
Non. Gate.AI a pour objectif d’unifier l’accès à plusieurs écosystèmes de modèles d’IA, de sorte que les développeurs puissent exploiter différentes capacités via une seule interface.
Qu’est-ce qu’une passerelle IA ?
Une passerelle IA est une couche d’infrastructure située entre les applications et les modèles. Elle prend en charge le transfert des requêtes, le routage des modèles, la gestion des autorisations, la surveillance, la gouvernance et la reprise après panne.
Que signifie le mécanisme de repli ?
Le repli est un mécanisme de reprise automatique : lorsque le modèle principal est indisponible, le système bascule vers un modèle de secours pour poursuivre le traitement des requêtes, réduisant ainsi les risques d’interruption de service.
L’utilisation d’une passerelle IA empêche-t-elle de choisir directement un modèle ?
Non. Une passerelle IA permet à la fois le routage automatique des modèles et la sélection manuelle du modèle cible par le développeur. Les deux modes peuvent être configurés librement selon les besoins.









